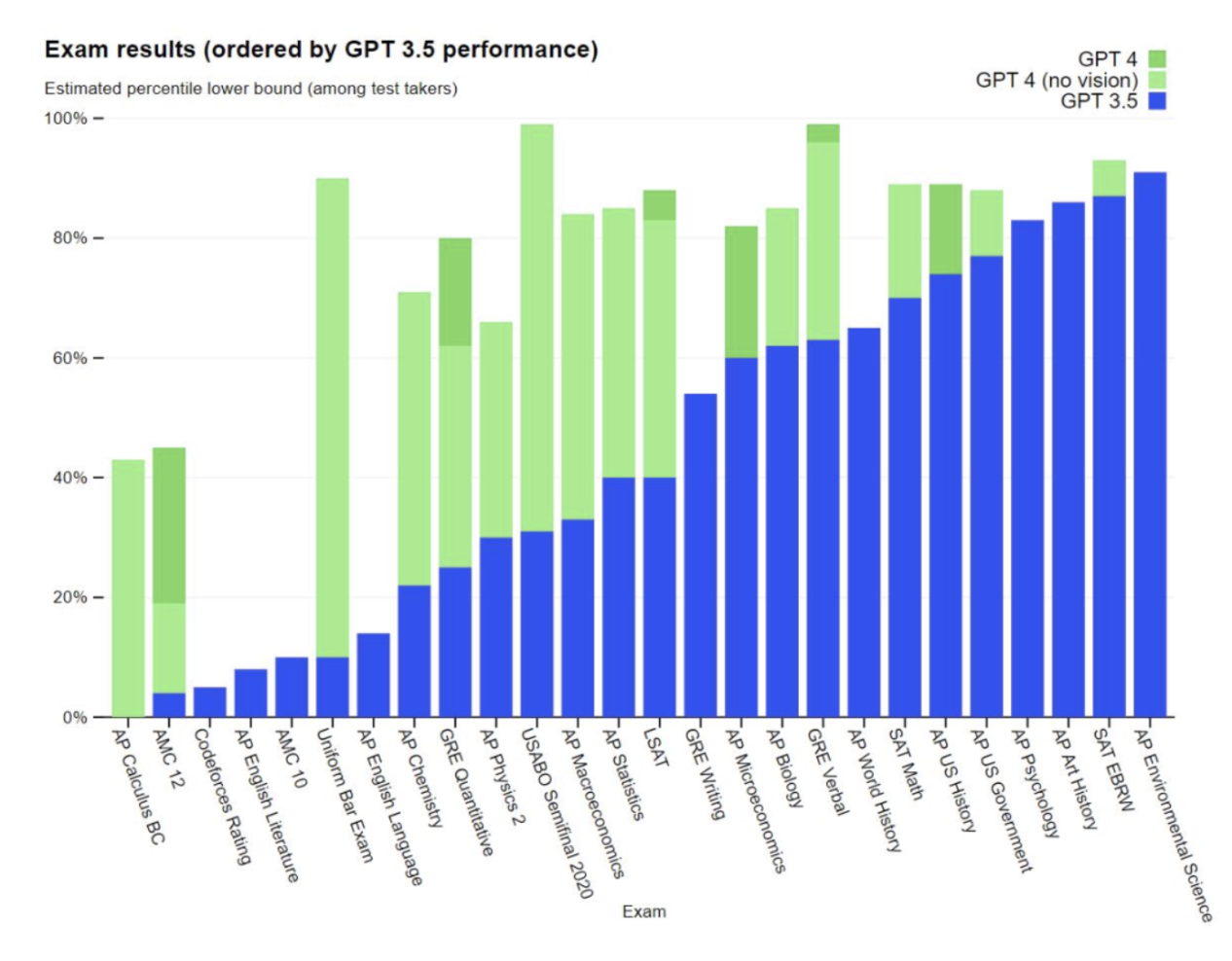
人工智能概念股有哪些? 人工智能芯片谁是龙头?
谷歌人工智能写作项目:小发猫

如何用Tensorflow 快速搭建神经网络
在MNIST数据集上,搭建一个简单神经网络结构,一个包含ReLU单元的非线性化处理的两层神经网络A8U神经网络。
在训练神经网络的时候,使用带指数衰减的学习率设置、使用正则化来避免过拟合、使用滑动平均模型来使得最终的模型更加健壮。
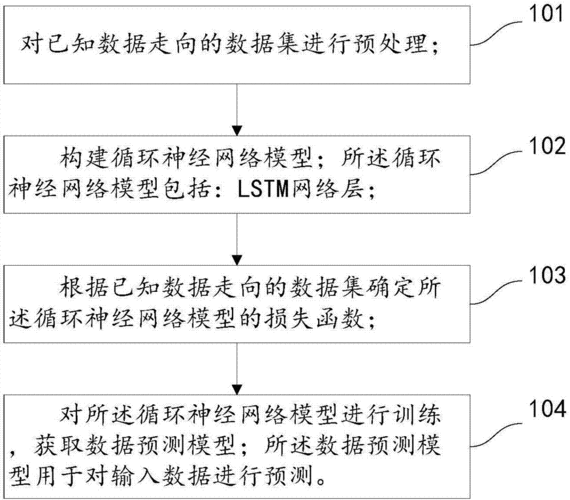
程序将计算神经网络前向传播的部分单独定义一个函数inference,训练部分定义一个train函数,再定义一个主函数main。
二、分析与改进设计1.程序分析改进第一,计算前向传播的函数inference中需要将所有的变量以参数的形式传入函数,当神经网络结构变得更加复杂、参数更多的时候,程序的可读性将变得非常差。
第二,在程序退出时,训练好的模型就无法再利用,且大型神经网络的训练时间都比较长,在训练过程中需要每隔一段时间保存一次模型训练的中间结果,这样如果在训练过程中程序死机,死机前的最新的模型参数仍能保留,杜绝了时间和资源的浪费。
第三,将训练和测试分成两个独立的程序,将训练和测试都会用到的前向传播的过程抽象成单独的库函数。这样就保证了在训练和预测两个过程中所调用的前向传播计算程序是一致的。
2.改进后程序设计该文件中定义了神经网络的前向传播过程,其中的多次用到的weights定义过程又单独定义成函数。
通过tf.get_variable函数来获取变量,在神经网络训练时创建这些变量,在测试时会通过保存的模型加载这些变量的取值,而且可以在变量加载时将滑动平均值重命名。
所以可以直接通过同样的名字在训练时使用变量自身,在测试时使用变量的滑动平均值。该程序给出了神经网络的完整训练过程。在滑动平均模型上做测试。
通过tf.train.get_checkpoint_state(mnist_train.MODEL_SAVE_PATH)获取最新模型的文件名,实际是获取checkpoint文件的所有内容。
在搭建神经网络的时候,如何选择合适的转移函数(
一般来说,神经网络的激励函数有以下几种:阶跃函数,准线性函数,双曲正切函数,Sigmoid函数等等,其中sigmoid函数就是你所说的S型函数。
以我看来,在你训练神经网络时,激励函数是不轻易换的,通常设置为S型函数。如果你的神经网络训练效果不好,应从你所选择的算法上和你的数据上找原因。
算法上BP神经网络主要有自适应学习速率动量梯度下降反向传播算法(traingdx),Levenberg-Marquardt反向传播算法(trainlm)等等,我列出的这两种是最常用的,其中BP默认的是后一种。
数据上,看看是不是有误差数据,如果有及其剔除,否则也会影响预测或识别的效果。
本人毕设题目是关于神经网络用于图像识别方面的,但是很没有头续~我很不理解神经网络作用的这一机理
。
我简单说一下,举个例子,比如说我们现在搭建一个识别苹果和橘子的网络模型:我们现在得需要两组数据,一组表示特征值,就是网络的输入(p),另一组是导师信号,告诉网络是橘子还是苹果(网络输出t):我们的样本这样子假设(就是):pt10312142这两组数据是这样子解释的:我们假设通过3个特征来识别一个水果是橘子还是苹果:形状,颜色,味道,第一组形状、颜色、味道分别为:103(当然这些数都是我随便乱编的,这个可以根据实际情况自己定义),有如上特征的水果就是苹果(t为1),而形状、颜色、味道为:214的表示这是一个橘子(t为2)。
好了,我们的网络模型差不多出来了,输入层节点数为3个(形状、颜色,味道),输出层节点为一个(1为苹果2为橘子),隐藏层我们设为一层,节点数先不管,因为这是一个经验值,还有另外的一些参数值可以在matlab里设定,比如训练函数,训练次数之类,我们现在开始训练网络了,首先要初始化权值,输入第一组输入:103,网络会输出一个值,我们假设为4,那么根据导师信号(正确的导师信号为1,表示这是一个苹果)计算误差4-1=3,误差传给bp神经网络,神经网络根据误差调整权值,然后进入第二轮循环,那么我们再次输入一组数据:204(当仍然你可以还输入103,而且如果你一直输入苹果的特征,这样子会让网络只识别苹果而不会识别橘子了,这回明白你的问题所在了吧),同理输出一个值,再次反馈给网络,这就是神经网络训练的基本流程,当然这两组数据肯定不够了,如果数据足够多,我们会让神经网络的权值调整到一个非常理想的状态,是什么状态呢,就是网络再次输出后误差很小,而且小于我们要求的那个误差值。
接下来就要进行仿真预测了t_1=sim(net,p),net就是你建立的那个网络,p是输入数据,由于网络的权值已经确定了,我们这时候就不需要知道t的值了,也就是说不需要知道他是苹果还是橘子了,而t_1就是网络预测的数据,它可能是1或者是2,也有可能是1.3,2.2之类的数(绝大部分都是这种数),那么你就看这个数十接近1还是2了,如果是1.5,我们就认为他是苹果和橘子的杂交,呵呵,开玩笑的,遇到x=2.5,我一般都是舍弃的,表示未知。
总之就是你需要找本资料系统的看下,鉴于我也是做图像处理的,我给你个关键的提醒,用神经网络做图像处理的话必须有好的样本空间,就是你的数据库必须是标准的。
至于网络的机理,训练的方法什么的,找及个例子用matlab仿真下,看看效果,自己琢磨去吧,这里面主要是你隐含层的设置,训练函数选择及其收敛速度以及误差精度就是神经网络的真谛了,想在这么小的空间给你介绍清楚是不可能的,关键是样本,提取的图像特征必须带有相关性,这样设置的各个阈值才有效。
OK,好好学习吧,资料去matlab中文论坛上找,在不行就去baudu文库上,你又不需要都用到,何必看一本书呢!祝你顺利毕业!
神经网络 的四个基本属性是什么?
神经网络的四个基本属性:(1)非线性:非线性是自然界的普遍特征。脑智能是一种非线性现象。人工神经元处于两种不同的激活或抑制状态,它们在数学上是非线性的。
由阈值神经元组成的网络具有更好的性能,可以提高网络的容错性和存储容量。(2)无限制性:神经网络通常由多个连接广泛的神经元组成。
一个系统的整体行为不仅取决于单个神经元的特性,而且还取决于单元之间的相互作用和互连。通过单元之间的大量连接来模拟大脑的非限制性。联想记忆是一个典型的无限制的例子。
(3)非常定性:人工神经网络具有自适应、自组织和自学习的能力。神经网络处理的信息不仅会发生变化,而且非线性动态系统本身也在发生变化。迭代过程通常用来描述动态系统的演化。
(4)非凸性:在一定条件下,系统的演化方向取决于特定的状态函数。例如,能量函数的极值对应于系统的相对稳定状态。非凸性是指函数具有多个极值,系统具有多个稳定平衡态,从而导致系统演化的多样性。
扩展资料:神经网络的特点优点:人工神经网络的特点和优越性,主要表现在三个方面:第一,具有自学习功能。
例如实现图像识别时,只在先把许多不同的图像样板和对应的应识别的结果输入人工神经网络,网络就会通过自学习功能,慢慢学会识别类似的图像。自学习功能对于预测有特别重要的意义。
预期未来的人工神经网络计算机将为人类提供经济预测、市场预测、效益预测,其应用前途是很远大的。第二,具有联想存储功能。用人工神经网络的反馈网络就可以实现这种联想。第三,具有高速寻找优化解的能力。
寻找一个复杂问题的优化解,往往需要很大的计算量,利用一个针对某问题而设计的反馈型人工神经网络,发挥计算机的高速运算能力,可能很快找到优化解。参考资料:百度百科——人工神经网络。
在tensorflow中搭建神经网络,为什么要建很多dense层?有什么作用?
dense层的目的,是将前面提取的特征,在dense经过非线性变化,提取这些特征之间的关联,最后映射到输出空间上。
理论上,一层dense足够,但这只是理论上,因为你不清楚这一层dense需要多少个节点的,也不知道需要多少次的训练,加更多的dense,能更快的收敛。