先看一篇论文
2311.18636 (arxiv.org)
这篇论文里有一个非常好的图
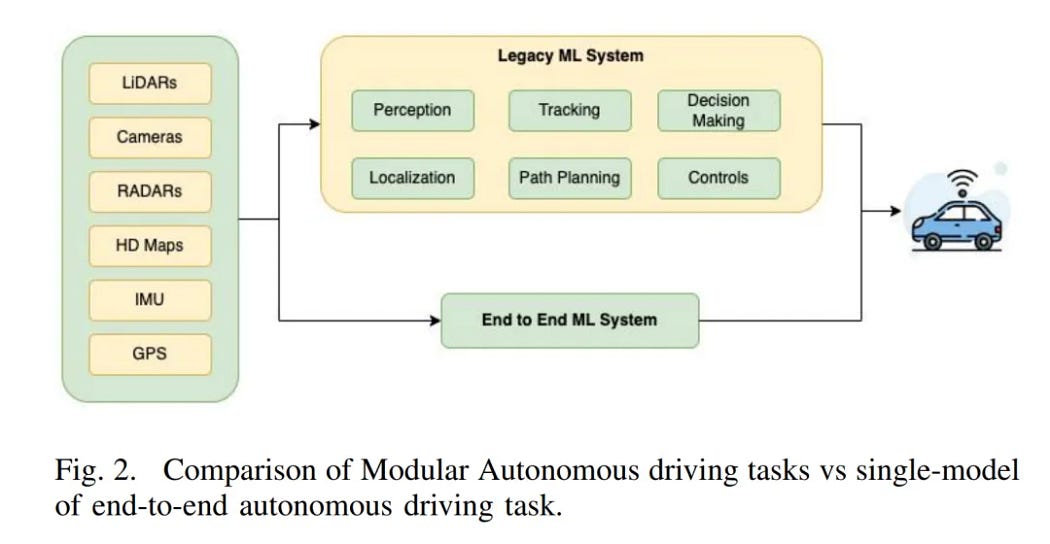
比较了一下模块化任务(级联任务)和端到端自动驾驶的区别
首先什么叫模块化任务(级联)
如上图所示,左边的方块中的子方块,是展示了自动驾驶获取数据的途径,这里包括:
- LiDARs(激光雷达):使用激光束创建周围环境的高分辨率3D地图。它们对于检测障碍物、测量距离和提供详细的空间信息至关重要。
- Cameras(摄像头):用于视觉感知,帮助系统识别交通信号、道路标志、车道标记以及其他车辆和行人。摄像头提供的高分辨率图像对于目标检测和分类非常重要。
- RADARs(雷达):使用无线电波检测物体并测量其距离和速度。雷达在恶劣天气条件下(如雾或大雨)尤其有用,因为在这些条件下摄像头和激光雷达可能表现不佳。
- HD Maps(高精度地图):提供详细的道路信息,包括车道结构、交通标志和地理特征,帮助车辆准确定位和导航。
- IMU(惯性测量单元):使用加速度计和陀螺仪测量车辆的加速度和角速度,提供精确的运动信息,有助于定位和稳定控制。
- GPS(全球定位系统):提供车辆的地理位置信息,结合其他传感器数据,实现厘米级的精确定位。
以上的各种sensor其实可以看出来大部分的自动驾驶的输入其实天生就是多模态的,但是可以任务比如纯视觉方案(特斯拉)它就不是多模态的吗?
这是一个错误的理解,特斯拉的纯视觉方案在训练时有text指令的输入,所以它也是多模态的。
或者目前可了解到的,只有特斯拉实现了端到端的模型,是不是只有纯视觉方案才有资格称得上端到端?这些概念都是错误的。
这个也是不正确的理解,那让我们看一下怎么定义端到端。
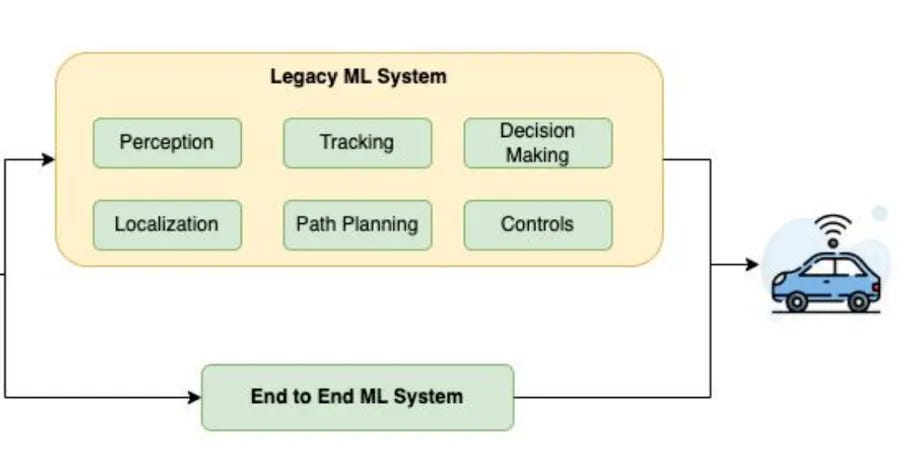
如图所示,传统的自动驾驶的流程是由多个模型组成的(有些模块甚至不能严格成为模型),比如上面的一个概述:
- Perception(感知):感知模块负责处理来自各种传感器的数据(如摄像头、雷达和激光雷达),识别并理解车辆周围的环境。这包括检测其他车辆、行人、道路标志、交通信号灯等。
- Localization(定位):定位模块通过融合GPS、高精度地图、IMU(惯性测量单元)等数据,确定车辆在环境中的准确位置。这是确保车辆能够正确导航和执行路径规划的基础。
- Tracking(跟踪):跟踪模块持续监控并预测周围移动物体的位置和速度,例如其他车辆和行人,以便系统能够做出及时和准确的反应,避免碰撞。
- Path Planning(路径规划):路径规划模块基于感知和定位信息,计算车辆从当前地点到目的地的最优路径。该路径需要考虑道路状况、交通法规和动态障碍物等因素。
- Decision Making(决策):决策模块根据感知、定位和路径规划的信息,决定车辆的具体行动。例如,选择何时变道、超车或停车等待,这些决策都需要综合考虑安全性和效率。
- Controls(控制):控制模块将决策模块的输出转换为具体的车辆操作指令,如转向、加速、制动等。确保车辆按照规划的路径和速度安全行驶。
这些模块协同工作,构成了一个完整的自动驾驶系统,能够感知环境、确定位置、规划路径、做出决策并执行控制指令,实现自动驾驶的功能。
这些模块,各自有各自的训练任务,而且后一个模块,一般依赖于前一个模块的输出质量。
比如如果你感知做的很垃圾,那么很不幸的是,你的跟踪,路径规划,决策啥的,都会受到影响。
另外对于开发模式来讲,传统的自动驾驶,感知肯定是感知组,拿CV模型做一些工作。
那么决策组里面,很多根本和大模型是不沾边的,是基于非常多人的一个team。来写各种驾驶情况下的policy,通过tree或者其他的可解释的算法来对感知送过来的output来进行决策。
那么对于端到端的自动驾驶来讲,这些以上的模块绝大多数都集成在一个模型里,大概这样
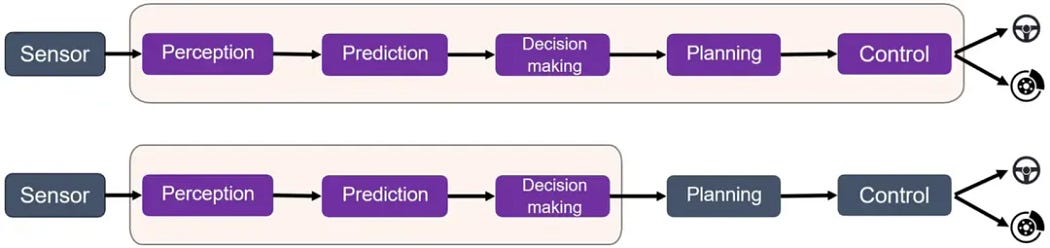
一般来讲目前能做到纯粹上面的那种模式,直接sensor拿到input,进一个端到端的模型,最后直接出控制信号,让比如方向盘刹车来觉得的这种少之又少,相当于你直接拿encoder的各种模态的外界信息,去做一个loss function为控制信号的模型,这个多少还有点那个的,至少损失函数不是特别好定义(你整个车多少控制单元呢)。
相当而言,下面的这个方式,比较好容易被接受,就是把感知,预测,决策这些模块在一个模型了,planning和control这些不用放在模型里执行,在模型外,可以写一些兜底的策略,比如紧急避障,紧急刹车,限速啥的。(据传闻,特斯拉的FSD12,现在主要是这个模式,应该也没做到第一种形态)
我刚到西安,我估计这个内容很多人感兴趣,但是确实写着写着有点累了,先写到这吧,当个连载来更,萝卜快跑,fsd12啥的后面写