分析万篇途牛旅游游记为你挑选最佳旅游景点
- 数据采集
- 分析主页面
- 分析子页面
- 爬虫设计
- 主页面数据采集
- 子页面数据采集
- 合并数据集
- 数据分析及可视化
- 旅游热门地点TOP10
- 驴友出行特点
- 出行季节
- 热门地区出行时间
随着经济发展,人们收入越来越高,可支配的资金和时间也逐渐变多,在基本的生活需求的到满足后,人们变追求生活质量的提升和精神上的满足。而增长见识、陶冶情操、锻炼身体的最好方式就是旅游度假,有调查显示,接近67%的人在时间允许的的情况下选择出去旅游,随着旅游人数的增长,交通工具、出行方式、目的地也呈现多样化的趋势。
本文的目的就是分析当下旅游热门地区,以及人们旅游的特点及出行的时段等内容。话不多说,直接进入正题。
数据采集
分析主页面
打开途牛旅游网首页。
http://trips.tuniu.com/
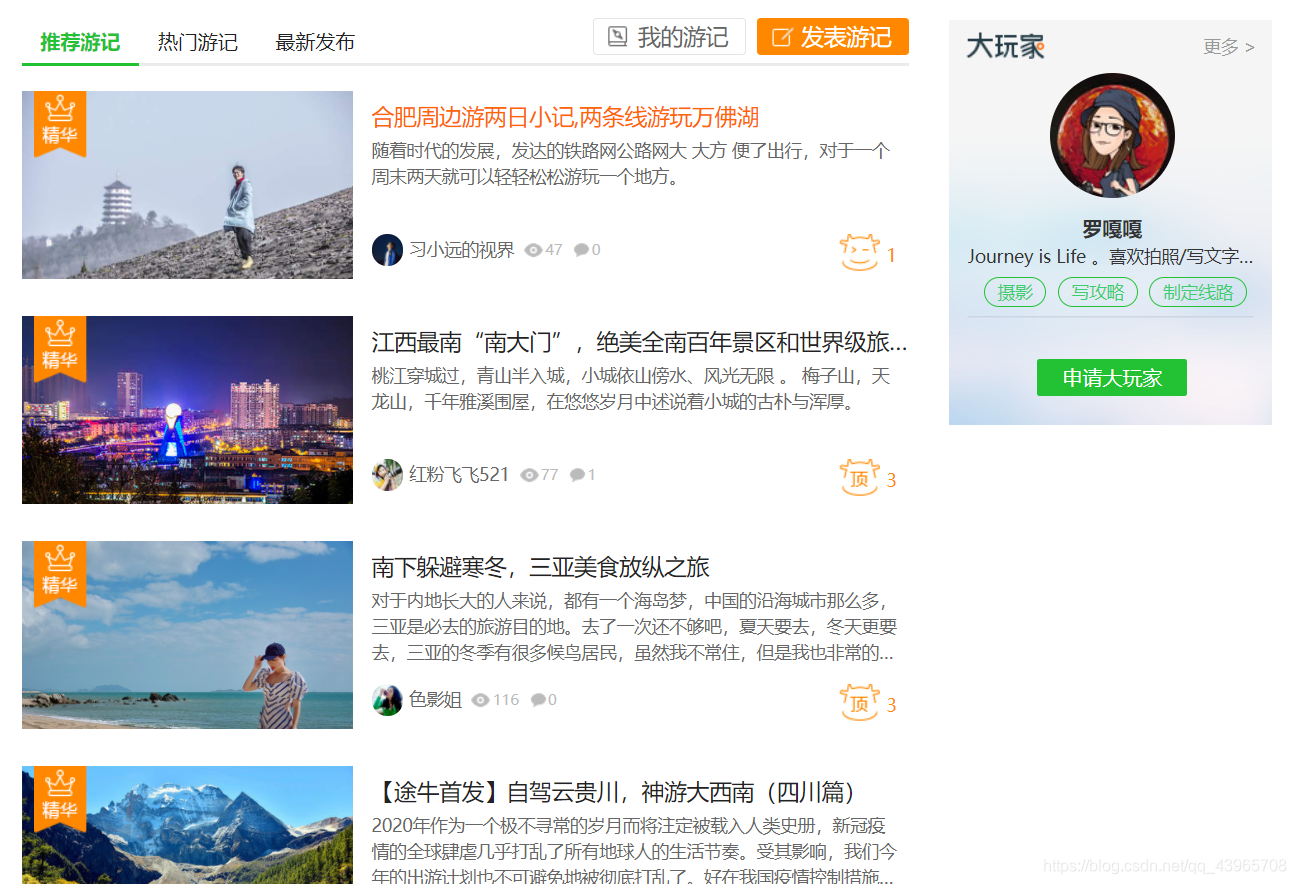
如图所示为各驴友旅游后写的游记,游记分为三类,推荐游记、热门游记、最新发布。这里我们需要爬取推荐游记中的10000篇游记用作数据分析。

当我们点击下一页时,可以看到每次页面切换都发起了新的Ajax请求。因此,我们可以尝试通过该请求地址爬取到游记的数据。首先打开开发者工具,点击第二页即可获得如下图所示的数据包。
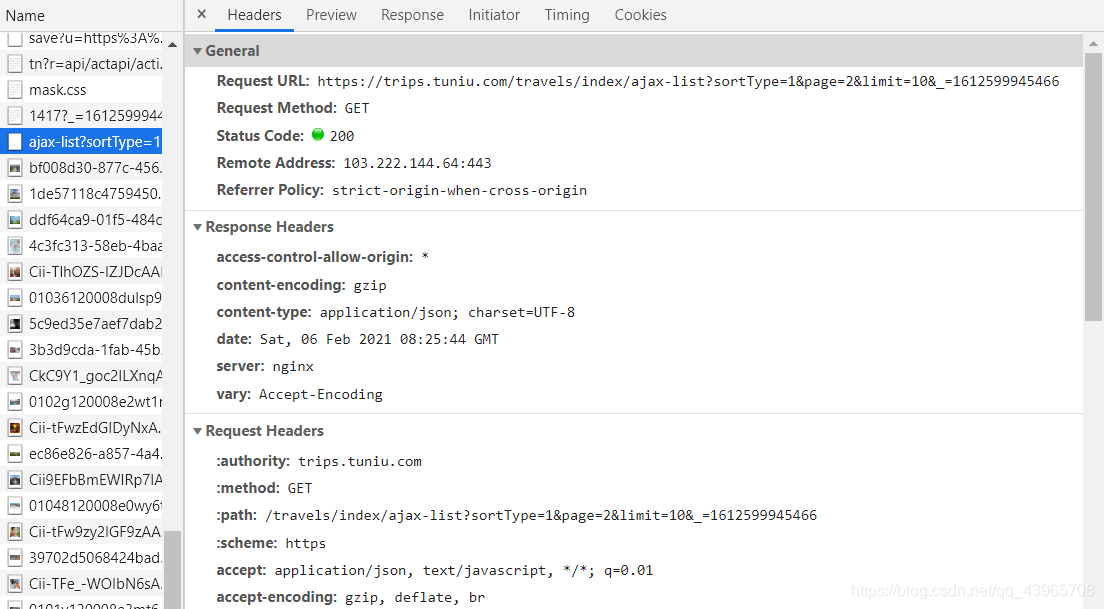
如下所示分别是二、三页的数据地址。
https://trips.tuniu.com/travels/index/ajax-list?sortType=1&page=2&limit=10&_ =1612599945466
https://trips.tuniu.com/travels/index/ajax-list?sortType=1&page=3&limit=10&_ =1612600065558
- sortType:游记分类编号,1代表推荐游记,2代表热门游记,3代表最新发布
- page:页数
- limit:每页中显示游记的篇数
- _:时间戳
将地址在新的标签页中打开,返回的数据如下图所示。

开发者工具中显示可能效果更好。

这些数据真正需要的可能并不多,我们先进入游记详情页,看看游记详情页的地址。
https://www.tuniu.com/trips/31327759
https://www.tuniu.com/trips/31327739
很容易发现末尾的数字其实就是json数据中的id。那么子页面的地址也能够得到了。
分析子页面
根据分析的需要我们需要爬去子页面的三个信息分别是tag(标签),img_count(游记图片数量),destination(目的地)。如下图所示。页面属于静态界面,减少了爬取的难度。
爬虫设计
先爬取主页面中各游记简介的json数据,将其保存为tuniu.csv文件,再读取tuniu.csv文件中的id,通过拼接网址前缀(https://www.tuniu.com/trips/)组成子页面的网址,根据分析需要爬取子页面中的部分信息,保存到tuniu_datail.csv中。之后将两个csv数据进行合并即可。两个爬取过程均采用异步协程的方式增加爬取效率。
主页面数据采集
获取url列表
根据指定的范围,格式化url并返回保存url的列表,实际爬取过程中不建议一次性添加大量url到协程的任务列表,asyncio库内部用到了select,而select就是系统打开文件数,它是有限度的,windows默认是509,所以设置范围时要注意这点,不然会报错。
def get_url_list():url_list = []url = 'https://trips.tuniu.com/travels/index/ajax-list?sortType=3&page=%d&limit=10&_=1611556898746'# 根据范围格式化url并添加到列表中for page in range(1, 510):url_list.append(url%page)return url_list
数据采集
爬虫采用aiohttp + asyncio协程,同时使用代理IP来爬取,防止被识别为爬虫。由于IP的稳定性有所差异,设置一个超时时间,如超时则更换IP继续采集数据。之后将获得数据进行格式化并进行保存。
async def get_page_text(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:while True:try:async with session.get(url=url, proxy='http://' + choice(proxy_list), headers=headers, timeout=5) as response:# 更改相应数据的编码格式response.encoding = 'utf-8'# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。page_text = await response.text()# 未成功获取数据时,更换ip继续请求if response.status != 200:continueprint(f"{url.split('&')[1]}爬取完成!")breakexcept Exception as e:print(e)# 捕获异常,继续请求continuereturn save_detail_url(page_text)
数据格式化并保存
将采集的数据有字符串格式转为字典,再获取字典中的值以附加的形式保存到csv中。
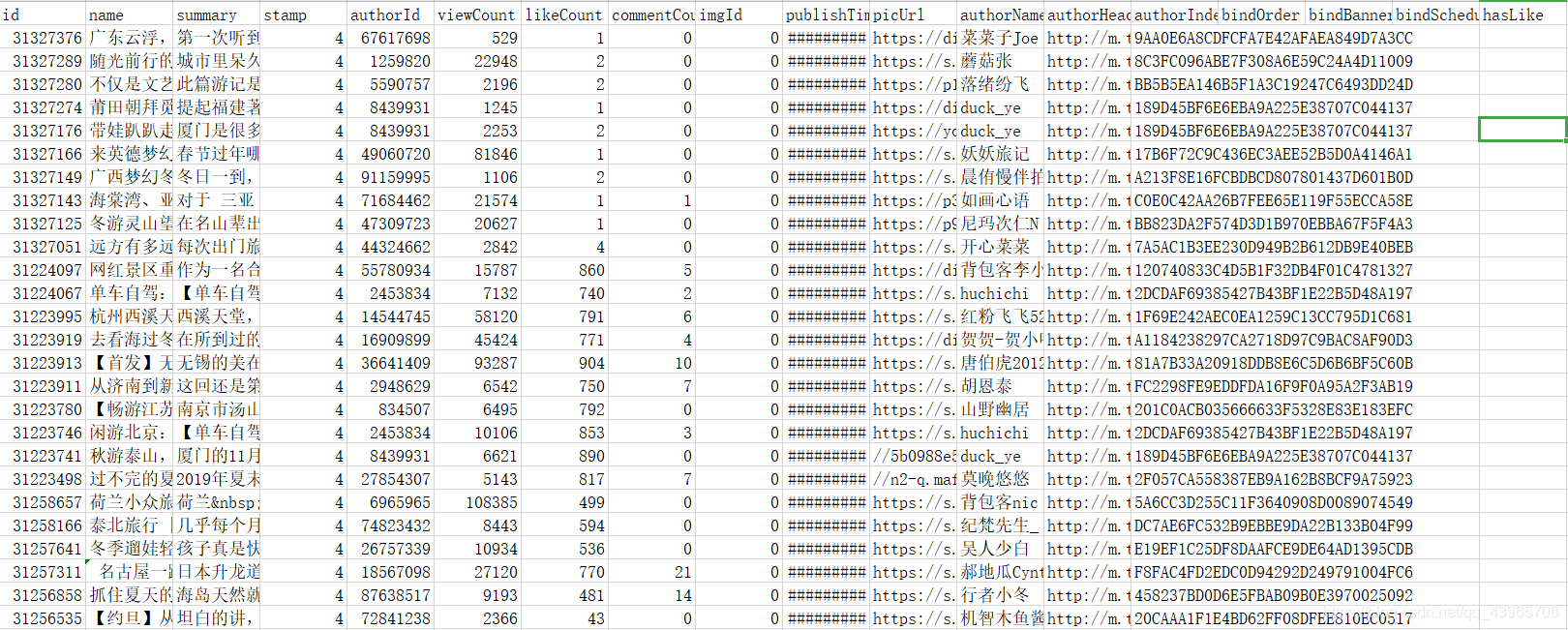
def save_detail_url(page_text):# 将字符串格式的数据转为字典类型page_data = json.loads(page_text)detail_data = page_data['data']['rows']# 新建DataFrame来保存爬取的数据df = pd.DataFrame(columns=['id', 'name', 'summary', 'stamp', 'authorId', 'viewCount', 'likeCount', 'commentCount','imgId', 'publishTime', 'picUrl', 'authorName', 'authorHeadImg', 'authorIndentity','bindOrder', 'bindBanner', 'bindSchedule', 'hasLike'])for dic in detail_data:df = df.append(dic, ignore_index=True)# 去除summary中的换行符回车符等df['summary'] = df['summary'].str.replace('\r|\n|\t', '')# 如果文件不存在那么要添加header行if os.path.exists(r'C:\Users\pc\Desktop\tuniu.csv'):df.to_csv(r'C:\Users\pc\Desktop\tuniu.csv', index=False, mode='a', header=False)else:df.to_csv(r'C:\Users\pc\Desktop\tuniu.csv', index=False, mode='a')
采集的数据如下:
子页面数据采集
获取url列表
通过pandas库读取csv文件中的id列,将其拼接成游记详情页面的url,并将保存url的列表返回。
def get_url_list(read_path):df = pd.read_csv(read_path, low_memory=False, usecols=['id'])df = df.loc[0: 500]url_list = ['https://www.tuniu.com/trips/%i'%i for i in df['id']]return url_list
数据采集
在数据采集时,相比于主页面,子页面爬取的过程中反爬措施更多。在爬取时要在headers中添加cookie值。
async def get_page_text(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36','Cookie': 'neplayer_deviceId=16120634344253296156275; HMF_CI=bcce9332d2b9ad654e2de3cda4383332fee6e4bc57730da2288c76539701c04387; tuniuuser_citycode=MTQxNw%3D%3D; p_phone_400=4007-999-999; p_phone_level=0; p_global_phone=%2B0086-25-8685-9999; _tact=ZTNjYzQ5Y2UtMGRiMy0xY2QzLTMxNWEtMmQ1YzQ0MWNkMmQy; _tacau=MCw5ODJkYWY0OC1jNDYwLTc3ODAtNmY3MC04ZjBkODU1NGU3MmIs; _ga=GA1.2.194120396.1611556211; smidV2=2021012514301137c2546dfefe7711b76addc3377d7ca40008610cce160d3e0; MOBILE_APP_SETTING_STATE-154=CLOSE; fp_ver=4.7.3; BSFIT_EXPIRATION=1612832819982; BSFIT_OkLJUJ=FHNOSa2QFDxX_g-d4-wiXsdQQS_XjKJA; BSFIT_DEVICEID=b9eKNxUNAaSRSbfrtJQKurX94BOm9rxZ8FvTVxxoUU-MSHeoud_w4bce-oauwaorx08Nnem10WiY-8EmwKC6yZNPD2ijv6lrpV30iqzC7fyee7eZN5YoGLaAyvuqmhATKOMfWUXkYkQQQi8AGZylEDuhjEqr68g1; _pzfxuvpc=1611556211175%7C5103748229141693861%7C4%7C1611816871145%7C2%7C6618115722561418861%7C2876772887322526570; _uab_collina=161181687117053189409514; _tacz2=taccsr%3Dwww.baidu.com%7Ctacccn%3D%28referral%29%7Ctaccmd%3D%28none%29%7Ctaccct%3D%28none%29%7Ctaccrt%3D%28none%29; __utmz=1.1611986681.4.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; tuniu_partner=MTAwLDAsLDI2OWJhMjJhNDAxOWQyNDRjYzNkMGU4ODZkMjQ1NGFk; __utma=1.194120396.1611556211.1611986681.1612004163.5; HOY_TR=CXHKLJSAWYZOUTEV,4CF672AEBD358901,Lliyqrjcbmaovksn,0; connect.sid=s%3APZcTo6mDU72tC-3TA_0cxd98UHpBb--0.jY%2B%2FHxhPuGCX8nuNzmfoodJTMLpt1ZjzJxhthVkqBAo; Hm_lvt_51d49a7cda10d5dd86537755f081cc02=1611982935,1612016009,1612018196,1612417130; PcHomeVisit=1; _tacc=1; _taca=1611556211132.1612428857142.1612430938123.21; _tacb=MzdmYzRhY2EtNjk3MS01MDA2LTQ1YjAtOTMxMjMxYzk5MzFl; acw_tc=2f624a7316124332791424370e684319bf21a2537a9bd999650063206c6d3e; acw_sc__v2=601bc7886e09eb430080463a897e5136136c9343; Hm_lpvt_51d49a7cda10d5dd86537755f081cc02=1612433290; ssxmod_itna=QqfxgiqYqxBAKGHD8D2eLDkffg7c7DCqDQbT+7DlarexA5D8D6DQeGTruT=mr3m7ifhYaeY=DT+Qf8mO4Lpfephm3L/Wex0aDbqGkd+nY4GGUxBYDQxAYDGDDPDoZPD1D3qDk0xYPGWCqGfDDoDYR=nDitD4qDB+EdDKqGgCdwxY264M32M+jUx3j+3CqDMIeGXYDcQkQcao2NaiqGyAPGuRMtyAdbDCg5ASY+jYkDaWA+bGAhzYTmtRBAFlE4TSA5bjKq+gIeDG8+oSzDxD; ssxmod_itna2=QqfxgiqYqxBAKGHD8D2eLDkffg7c7DCqDQbT+D6pRr40Huiq03qaau6UCcmgIMImOKxPuRQ75ExuDn+6O3RjqHTqgWAng6CTvBlM=HqkF2HPrUYjZlnfl7BRHOwTYBfE2RgiGX3T=lqjU0wEu8i0ZiqNZ73wn8+jc4jQRU82IAoN4EkI9C20szg6CiljCbuv0UMoNgevqdnc3ijcu7ZLuGnA7k3HtgPBOL=B3IGrvQ+FK5BflGu+ElraV7fQsRfjXjfIfy4vm3uSL4vvQoRNZAOGWD7jHD7=DeMPbikGr=TexD=='}async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:while True:try:async with session.get(url=url, headers=headers, timeout=5) as response:# 更改相应数据的编码格式response.encoding = 'utf-8'# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。page_text = await response.text()# 未成功获取数据时,更换ip继续请求if response.status != 200:print(response.status)continueid = url.split('/')[-1]print(f"{url.split('/')[-1]}爬取完成!")breakexcept Exception as e:# 捕获异常,继续请求continuereturn save_to_csv(page_text, id)
数据格式化并保存
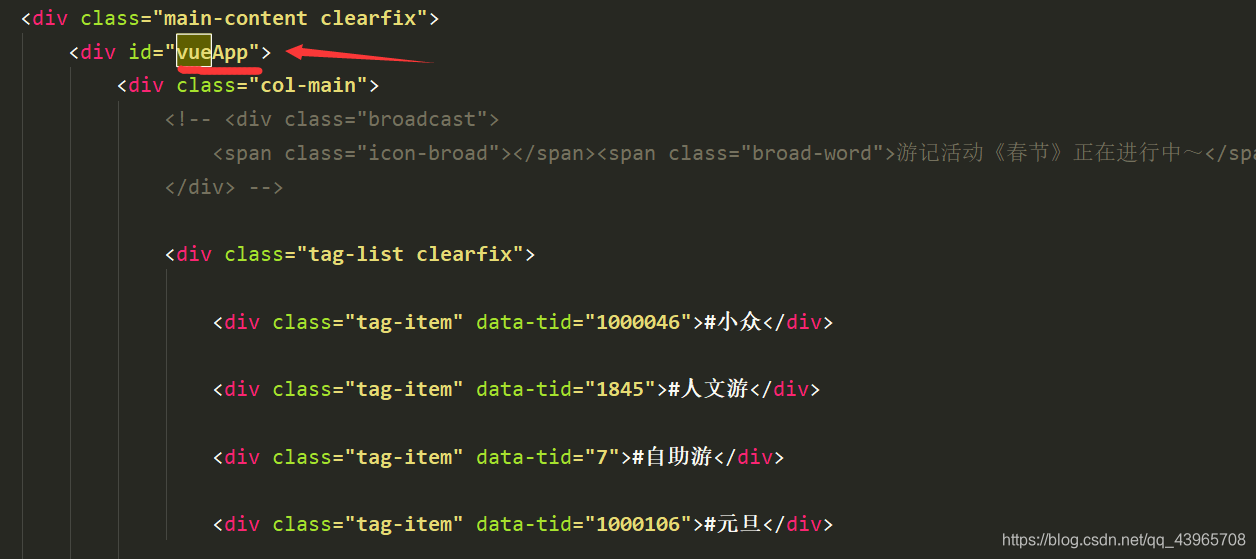
使用xpath定位标签的时候要注意,可以把页面数据保存到本地,再进行定位,因为实际爬取得页面数据和原页面本身是有区别的。如定位tag(游记标签)时,原页面的定位该标签xpath表达式和实际爬取时的并不一样,如下图。
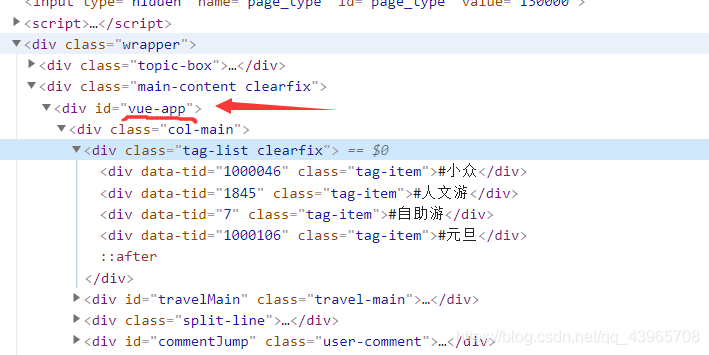
定位旅游地点时也需注意,直接在原页面copy的xpath表达式,在运行时获取的内容是空的。下图是原页面定位到的标签位置。

在本地保存的页面数据中查找div标签的class属性值“poi-title”,发现为空。于是只好在获得的页面源码中直接查询地点名,尝试通过定位别的标签来获得路由地点信息。下图为定位到的地点标签。

数据格式化及保存代码:
def save_to_csv(page_text, id):tree = etree.HTML(page_text)# with open('tuniuDetail.html', 'w', encoding='utf-8')as fp:# fp.write(page_text)tag_div_list = tree.xpath('//*[@id="vueApp"]/div[1]/div[1]/div')tag_list = []# 获取div中的游记标签信息for div in tag_div_list:tag_list.append(div.xpath('./text()')[0])# 统计图片数量img_count = len(tree.xpath('//div[@class="sdk-trips-image"]'))pattern = re.compile('(?<="poiIds":\[)(.*?)}')destination_data = tree.xpath('/html/body/script[4]/text() | /html/body/script[3]/text()')poiIds = pattern.search(destination_data[0]).group()# 判断poiIds中是否有值,否则置空if ']' in poiIds:poiIds = '{"name": ""}'destination = eval(poiIds)['name']df = pd.DataFrame(columns=['id', 'tag', 'img_count', 'destination'])df = df.append({'id': id, 'tag': ''.join(tag_list), 'img_count': img_count, 'destination': destination}, ignore_index=True)if os.path.exists(r'C:\Users\pc\Desktop\tuniu_detail.csv'):df.to_csv(r'C:\Users\pc\Desktop\tuniu_detail.csv', index=False, mode='a', header=False)else:df.to_csv(r'C:\Users\pc\Desktop\tuniu_detail.csv', index=False, mode='a')
采集的子页面数据如下:
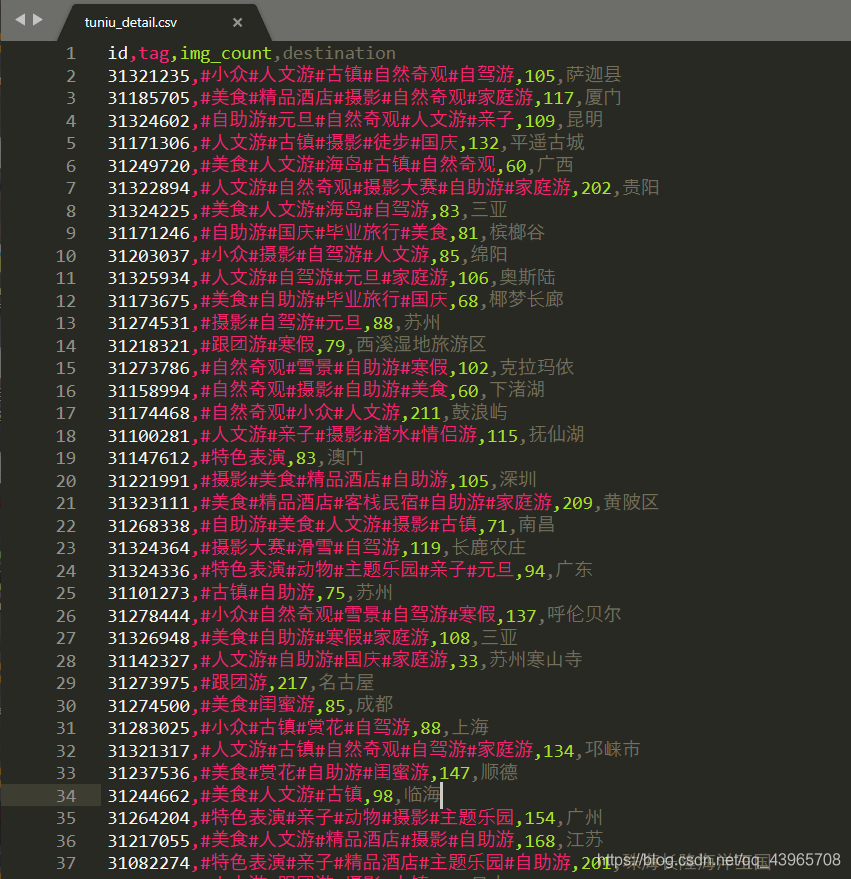
合并数据集
将tuniu.csv文件和tuniu_detail.csv文件按照id列进行合并。
def merge():df1 = pd.read_csv(r'C:\Users\pc\Desktop\tuniu_test.csv')df2 = pd.read_csv(r'C:\Users\pc\Desktop\tuniu_detail.csv')df1['summary'] = df1['summary'].str.replace('\r|\n|\t', '')merge_df = pd.merge(df1, df2, on='id', how="inner")merge_df.to_csv(r'C:\Users\pc\Desktop\tuniu_info.csv', index=False)
合并后数据:
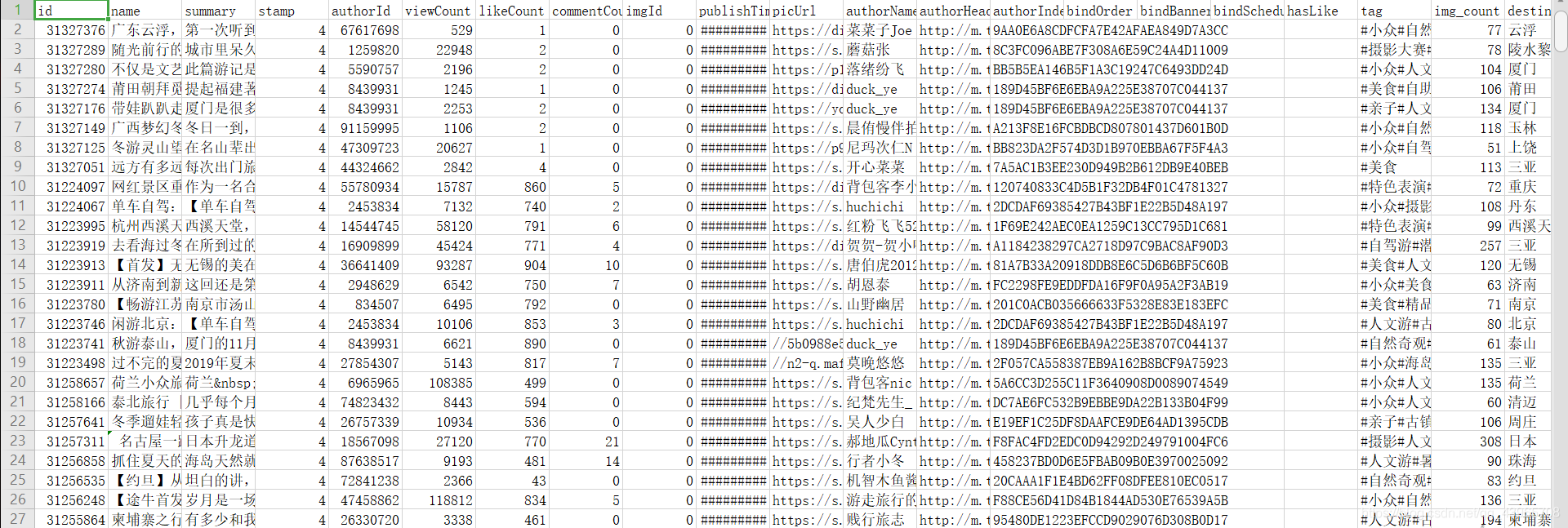
数据分析及可视化
旅游热门地点TOP10
我们通过分析采集的数据中destination信息,来看看驴友们普遍去了哪些地方。
# 设置背景及中文显示
sns.set_style('darkgrid',{'font.sans-serif': ['simhei','FangSong']})def tuniu_destination(read_path):df = pd.read_csv(read_path, low_memory=False, usecols=['destination'])# 统计出现次数最多的十个地点和出现的次数des_count = df['destination'].value_counts().head(10)des, count = list(des_count.index), list(des_count.values)new_df = pd.DataFrame(columns=['destination', 'count'])new_df['destination'], new_df['count'] = des, countsns_plot = sns.barplot(x='destination', y='count', palette='ch:.25', data=new_df)plt.xlabel('地点')plt.ylabel('次数')plt.show()# 保存图片# sns_plot.figure.savefig(r'C:\Users\pc\Desktop\des_count.jpg', dpi=1000)
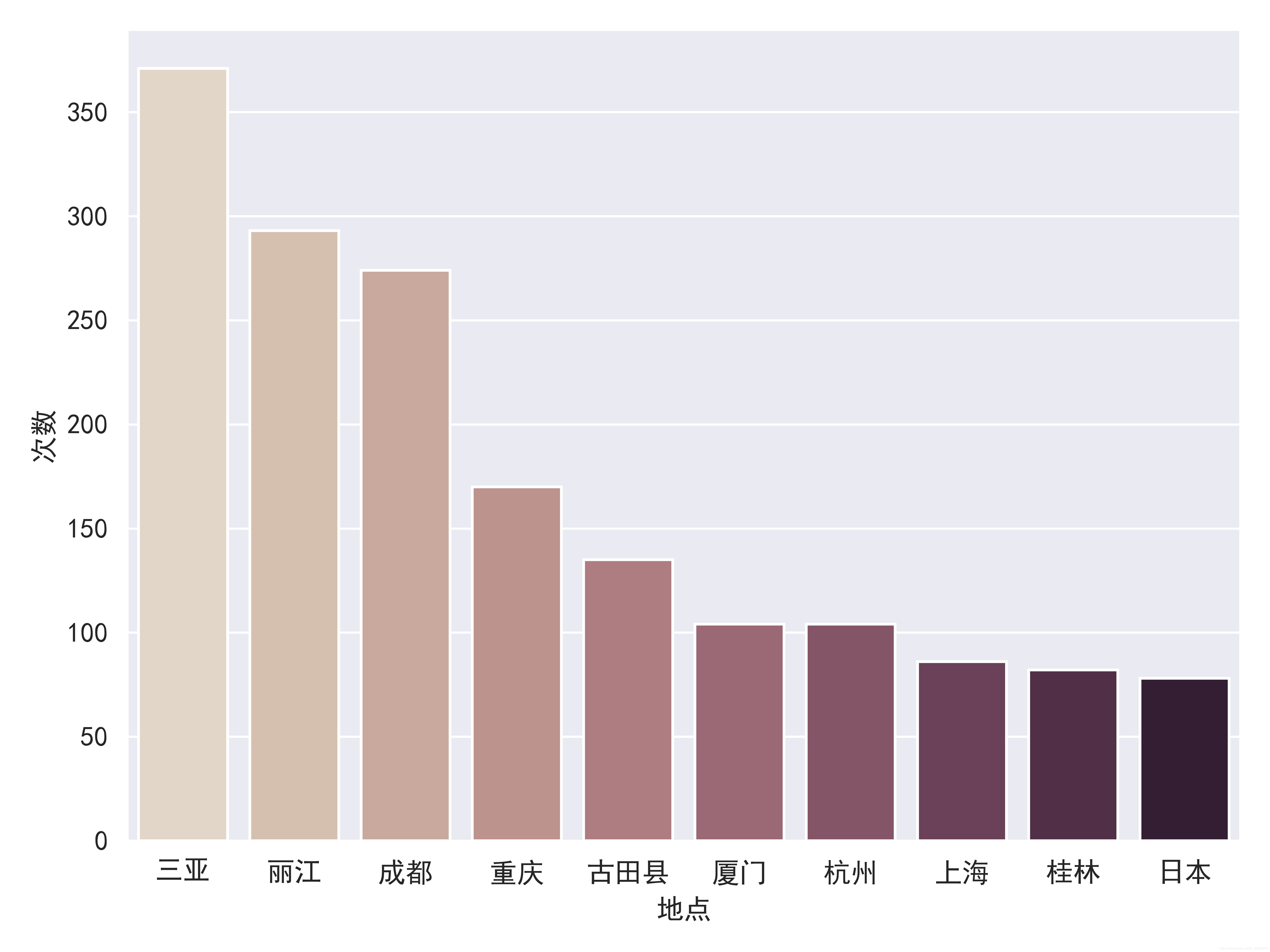
从图中可以看到,前三名三亚、丽江、成都应该都是我们耳熟能详的一些旅游地点,每年都会有很多外地游客到来,而这些游客在一定程度上促进当地经济的发展,同时也不断的吸引着更多驴友的到访。
驴友出行特点
根据获取的游记标签信息,我们分析一下驴友们出行的一些特点。
def tuniu_tag(read_path):df = pd.read_csv(read_path, low_memory=False, usecols=['tag'])all_tag = []for lst in df['tag']:tag_list = lst.split('#')for i in range(1, len(tag_list)):all_tag.append(tag_list[i])tag_str = ' '.join(all_tag)# 绘制词云图word = WordCloud(max_words=100,max_font_size=200,width=1000,height=800,font_path='C:\Windows\Fonts\simhei.ttf').generate(tag_str)word.to_file(r"C:\Users\pc\Desktop\tag.jpg")

通过上图中的标签词云图,我们可以看到,出现次数最多有自驾游、人文游、自然奇观、摄影、美食、客栈民宿等,而这些标签,恰恰是大多数驴友出行的特点,而近年在民宿方面,很多乡村也加入其中,使驴友在旅游的同时也可以体会当地的风土人情。
出行季节
根据游记发布时间,大致推测驴友的出行时间,看看出行时间有什么特点。
def tuniu_season(read_path):df = pd.read_csv(read_path, low_memory=False, usecols=['publishTime'])season_dic = {'春季': 0, '夏季':0, '秋季': 0, '冬季': 0}for publishTime in df['publishTime']:time = publishTime.split('-')[1]if time in ['01','02','03']:season_dic['春季'] += 1elif time in ['04','05','06']:season_dic['夏季'] += 1elif time in ['07','08','09']:season_dic['秋季'] += 1elif time in ['10','11','12']:season_dic['冬季'] += 1# 绘制饼图colors = ['#81ecec','#ff7675','#6c5ce7', '#F5F6CE']plt.pie(list(season_dic.values()), labels=list(season_dic.keys()), autopct = '%.1f%%', colors = colors, startangle = 90, counterclock = False)plt.legend(loc='upper right', bbox_to_anchor=(1.2, 0.2))plt.savefig(r'C:/Users/pc/Desktop/season.jpg', dpi=1000)plt.show()
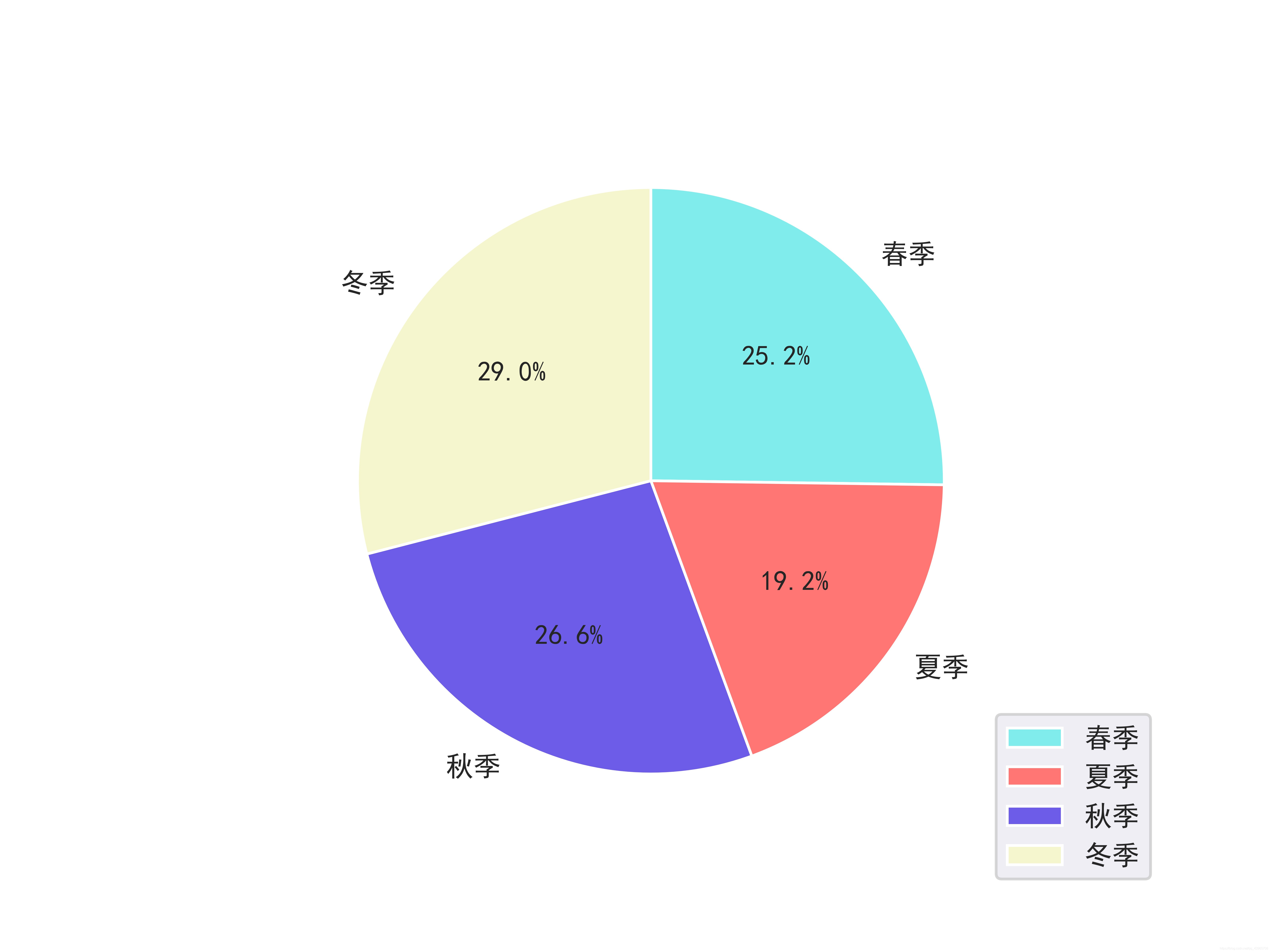
从图中可以看出,春秋季出行人数大致持平,处于平均水平,冬季最多,夏季最少。
热门地区出行时间
考虑到各个景点处于不同地区,气候可能有所差异。接下来我们通过三个热门地区(三亚、丽江、成都)的各个月份出行人数来分析一下,各地区出行人数与时间的关系。
def des_season(read_path):df = pd.read_csv(read_path, low_memory=False, usecols=['destination', 'publishTime'])new_df = pd.DataFrame(columns=['des', 'month'])dic = {'三亚': 0, '丽江': 0, '成都': 0}for i in range(len(df)):if df['destination'][i] in ['三亚', '丽江', '成都']:if dic[df['destination'][i]] < 200:dic[df['destination'][i]] += 1new_df = new_df.append({'des': df['destination'][i], 'month': int(df['publishTime'][i].split('-')[1])}, ignore_index=True)s1 = new_df.loc[new_df['des']=='三亚']['month'].value_counts()s1.sort_index(inplace=True)s2 = new_df.loc[new_df['des'] == '丽江']['month'].value_counts()s2.sort_index(inplace=True)s3 = new_df.loc[new_df['des'] == '成都']['month'].value_counts()s3.sort_index(inplace=True)df_1 = pd.DataFrame({'des': '三亚', 'month': s1.index, 'count': s1.values})df_2 = pd.DataFrame({'des': '丽江', 'month': s2.index, 'count': s2.values})df_3 = pd.DataFrame({'des': '成都', 'month': s3.index, 'count': s3.values})# 合并三个地区的DataFrameres_df = pd.concat([df_1, df_2, df_3], ignore_index=True)# 绘制线图fig = sns.relplot(x=res_df['month'], y=res_df['count'], hue=res_df['des'], height=3, kind='line', estimator=None, data=new_df)plt.show()fig.savefig(r'C:\Users\pc\Desktop\des_season.jpg', dpi=1000)
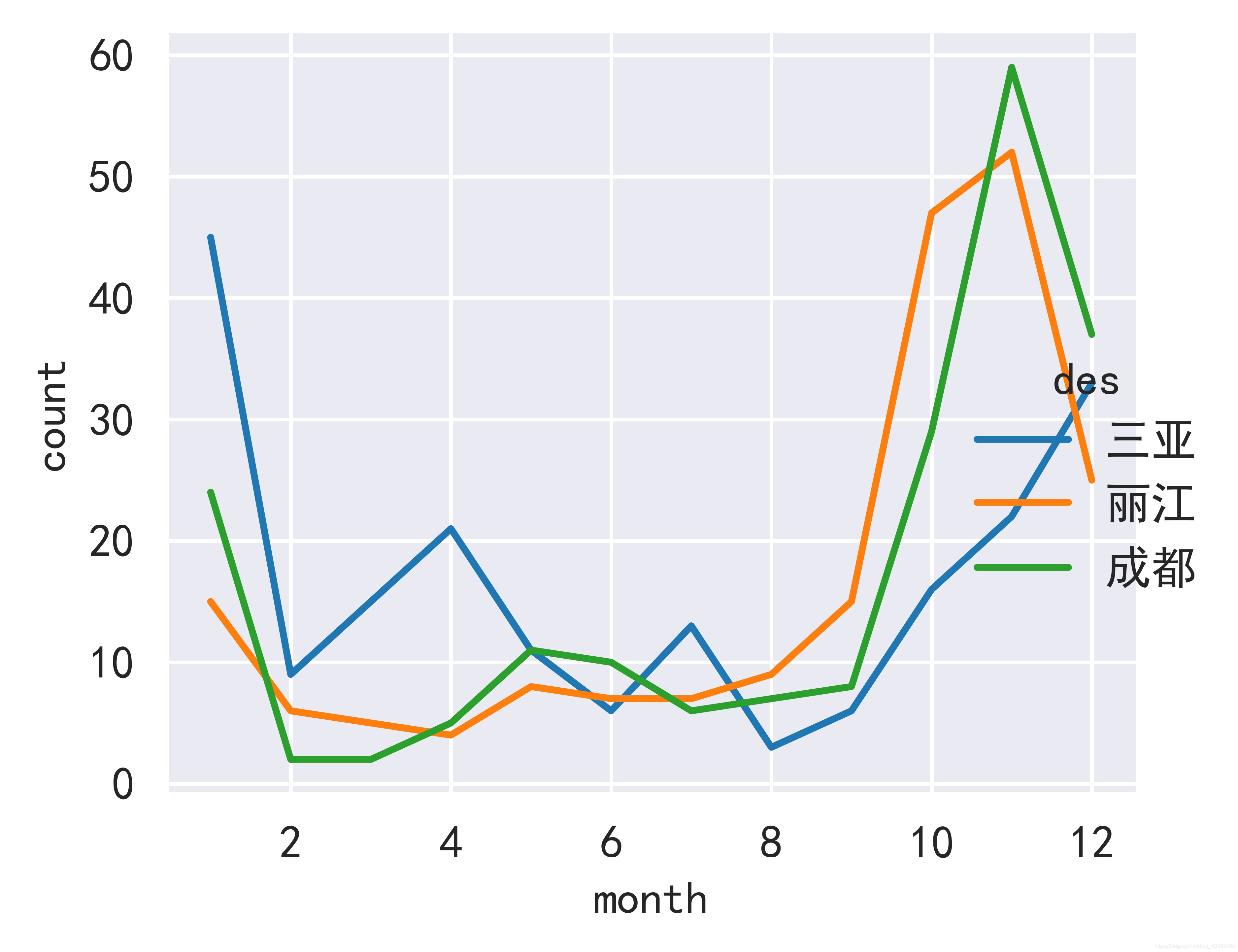
观察上图可知,这三个热门城市的出行时间还是有部分差异的。三亚十二月和一月旅游人数较多,丽江和成都的出行峰值都出现在11月。根据这些信息可以根据情况合理安排出行时间。
结语
这次感觉最浪费时间的还是子页面数据的获取,开始时使用的是代理IP爬取,中途有事耽搁了一段时间,过几天再运行时,发现只要使用代理IP就会被检测到,返回的数据总是错误的,迫不得已只能放弃使用代理,使用本机IP爬取,效率上还是要低一些。