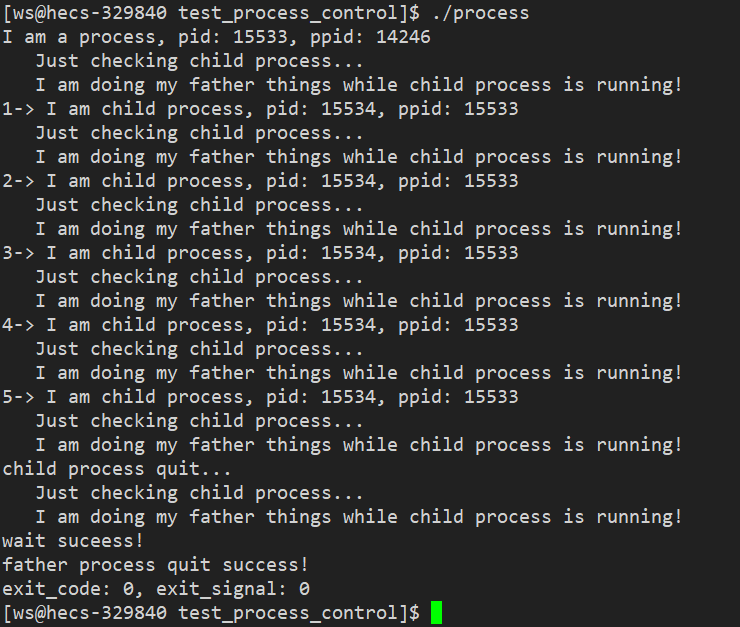
ANSI简介
ANSI Compliance通常指的是遵循美国国家标准学会(American National Standards Institute, ANSI)制定的标准。在计算机科学和技术领域,这通常涉及到数据库管理系统(DBMS)对于SQL语言的支持程度。
ANSI为SQL(Structured Query Language)制定了多个标准,这些标准定义了如何以一致的方式编写SQL查询和程序。这些标准旨在提高不同数据库系统之间的兼容性,使得基于标准的SQL代码可以在多种不同的数据库平台上运行。
ANSI相关的两个配置
- spark.sql.ansi.enabled
这个配置决定了Spark SQL是否遵循ANSI SQL标准。当设置为 true 时,Spark SQL将使用一种更接近ANSI SQL标准的方言进行查询处理。这意味着,在遇到无效的输入时,Spark会抛出异常,而不是简单地返回 null 结果。 - spark.sql.storeAssignmentPolicy
这个配置控制着在向表中插入数据时的隐式类型转换行为。当这个配置设置为 ANSI 时,Spark SQL会按照ANSI存储分配规则来进行数据类型转换。
ANSI兼容性与Hive兼容性的区别:
- ANSI兼容性:更加严格地遵循SQL标准,例如对于无效输入抛出异常。
- Hive兼容性:通常更宽松,可能会返回 null 而不是抛出异常。
官方详解
| 参数名 | 默认值 | 解释 | 开始版本 |
|---|---|---|---|
| spark.sql.ansi.enabled | false | 如果为true,Spark会尝试符合ANSI SQL规范:Spark SQL会对无效操作抛出运行时异常,包括整数溢出错误、字符串解析错误等。Spark将使用不同的类型强制规则来解决数据类型之间的冲突。这些规则始终基于数据类型优先级。 | 3.0.0 |
| spark.sql.storeAssignmentPolicy | ANSI | 当将值插入到具有不同数据类型的列中时,Spark将执行类型转换。目前,我们支持3种类型强制规则策略:ANSI、遗留和严格。使用ANSI策略,Spark按照ANSI SQL执行类型强制。在实践中,行为与PostgreSQL基本相同。它不允许某些不合理的类型转换,例如将字符串转换为int或将double转换为boolean。插入数值类型列时,如果值超出目标数据类型的范围,将抛出溢出错误。用遗留策略,Spark允许类型强制,只要它是有效的Cast,这是非常宽松的。例如,允许将字符串转换为int或将double转换为boolean。这也是Spark 2.x中唯一的行为,它与Hive兼容。在严格的政策下,Spark不允许在类型强制中出现任何可能的精度损失或数据截断,例如不允许将double转换为int或decimal转换为double。 | 3.0.0 |
算术运算
在Spark SQL中,默认情况下,对数值类型(除了decimal类型)进行的算术运算不会检查溢出。这意味着,如果一个操作导致溢出,其结果与在Java/Scala程序中相应的操作相同(例如,如果两个整数的和超过了可表示的最大值,则结果是一个负数)。另一方面,Spark SQL对于decimal类型的溢出会返回 null。当 spark.sql.ansi.enabled 设置为 true 并且在数值和区间算术运算中发生溢出时,它会在运行时抛出算术异常。
-- `spark.sql.ansi.enabled=true`
SELECT 2147483647 + 1;
org.apache.spark.SparkArithmeticException: [ARITHMETIC_OVERFLOW] integer overflow. Use 'try_add' to tolerate overflow and return NULL instead. If necessary set spark.sql.ansi.enabled to "false" to bypass this error.
== SQL(line 1, position 8) ==
SELECT 2147483647 + 1^^^^^^^^^^^^^^SELECT abs(-2147483648);
org.apache.spark.SparkArithmeticException: [ARITHMETIC_OVERFLOW] integer overflow. If necessary set spark.sql.ansi.enabled to "false" to bypass this error.-- `spark.sql.ansi.enabled=false`
SELECT 2147483647 + 1;
+----------------+
|(2147483647 + 1)|
+----------------+
| -2147483648|
+----------------+SELECT abs(-2147483648);
+----------------+
|abs(-2147483648)|
+----------------+
| -2147483648|
+----------------+
类型转换
当 spark.sql.ansi.enabled 设置为 true 时,使用 CAST 语法进行显式类型转换时,如果遇到标准中定义的非法类型转换模式(例如从字符串类型转换到整型),将会在运行时抛出异常。
此外,在ANSI SQL模式下,不允许进行以下类型的转换,而在关闭ANSI模式时这些转换是允许的:
- Numeric <=> Binary
- Date <=> Boolean
- Timestamp <=> Boolean
- Date => Numeric
CAST表达式中源数据类型和目标数据类型的有效组合如下表所示。“Y”表示组合在语法上有效,没有限制,“N”表示组合无效。

在上表中,所有具有新语法的CAST都标记为红色Y:
- CAST(Numeric AS Numeric):如果值超出目标数据类型的范围,则引发溢出异常。
- CAST(String AS (Numeric/Date/Timestamp/Timestamp_NTZ/Interval/Boolean)):如果值无法解析为目标数据类型,则引发运行时异常。
- CAST(Timestamp AS Numeric):如果自纪元以来的秒数超出目标数据类型的范围,则引发溢出异常。
- CAST(Numeric AS Timestamp):如果数值乘以1000000(微秒每秒)超出Long类型的范围,则引发溢出异常。
- CAST(Array AS Array):如果元素转换时出现异常,则引发异常。
- CAST(Map AS Map):如果键和值的转换有任何异常,则引发异常。
- CAST(Struct AS Struct):如果在结构字段的转换过程中出现异常,则引发异常。
- CAST(Numeric AS String):在将十进制值转换为字符串时,始终使用纯字符串表示法,如果需要指数,则不使用科学记数法。CAST(Interval AS Numerical):如果日时间间隔或年月间隔的微秒数超出目标数据类型的范围,则引发溢出异常。
- CAST(Numeric AS Interval):如果目标区间结束单位的数值时间超出Int类型(表示年月区间)或Long类型(表示日时间区间)的范围,则引发溢出异常。
-- Examples of explicit casting-- `spark.sql.ansi.enabled=true`
SELECT CAST('a' AS INT);
org.apache.spark.SparkNumberFormatException: [CAST_INVALID_INPUT] The value 'a' of the type "STRING" cannot be cast to "INT" because it is malformed. Correct the value as per the syntax, or change its target type. Use `try_cast` to tolerate malformed input and return NULL instead. If necessary set "spark.sql.ansi.enabled" to "false" to bypass this error.
== SQL(line 1, position 8) ==
SELECT CAST('a' AS INT)^^^^^^^^^^^^^^^^SELECT CAST(2147483648L AS INT);
org.apache.spark.SparkArithmeticException: [CAST_OVERFLOW] The value 2147483648L of the type "BIGINT" cannot be cast to "INT" due to an overflow. Use `try_cast` to tolerate overflow and return NULL instead. If necessary set "spark.sql.ansi.enabled" to "false" to bypass this error.SELECT CAST(DATE'2020-01-01' AS INT);
org.apache.spark.sql.AnalysisException: cannot resolve 'CAST(DATE '2020-01-01' AS INT)' due to data type mismatch: cannot cast date to int.
To convert values from date to int, you can use function UNIX_DATE instead.-- `spark.sql.ansi.enabled=false` (This is a default behaviour)
SELECT CAST('a' AS INT);
+--------------+
|CAST(a AS INT)|
+--------------+
| null|
+--------------+SELECT CAST(2147483648L AS INT);
+-----------------------+
|CAST(2147483648 AS INT)|
+-----------------------+
| -2147483648|
+-----------------------+SELECT CAST(DATE'2020-01-01' AS INT)
+------------------------------+
|CAST(DATE '2020-01-01' AS INT)|
+------------------------------+
| null|
+------------------------------+-- Examples of store assignment rules
CREATE TABLE t (v INT);-- `spark.sql.storeAssignmentPolicy=ANSI`
INSERT INTO t VALUES ('1');
org.apache.spark.sql.AnalysisException: [INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST] Cannot write incompatible data for table `spark_catalog`.`default`.`t`: Cannot safely cast `v`: "STRING" to "INT".-- `spark.sql.storeAssignmentPolicy=LEGACY` (This is a legacy behaviour until Spark 2.x)
INSERT INTO t VALUES ('1');
SELECT * FROM t;
+---+
| v|
+---+
| 1|
+---+
类型转换时四舍五入规则
- 规则如下
-
当你将一个包含小数部分的
decimal类型值转换为一个以SECOND结尾的interval类型时(例如,INTERVAL HOUR TO SECOND),Spark SQL 会对小数部分进行舍入处理。 -
最近邻舍入 (
nearest neighbor): 如果小数部分离两个相邻整数的距离不相等,Spark SQL 会将其舍入到最近的整数。 -
向上舍入 (
round up): 如果小数部分离两个相邻整数的距离相等,则向上舍入到较大的整数。
- 示例
假设我们有一个decimal类型的值3.5,我们需要将其转换为INTERVAL HOUR TO SECOND类型。
- 最近邻舍入: 因为
3.5离3和4的距离相等,所以根据舍入规则,我们会将3.5向上舍入到4。 - 向上舍入: 如果
3.5被转换成INTERVAL HOUR TO SECOND类型,那么它会被舍入为4秒。
存储分配
如开头所述,当spark.sql.storeAssignmentPolicy设置为ANSI(默认值)时,spark sql在插入表时符合ANSI存储分配规则。下表给出了表插入中源数据类型和目标数据类型的有效组合。

- Spark不支持区间类型的表列。
- 对于Array/Map/Struct类型,数据类型检查规则递归应用于其组成元素。
在表插入过程中,Spark将在数值溢出时抛出异常。
CREATE TABLE test(i INT);INSERT INTO test VALUES (2147483648L);
org.apache.spark.SparkArithmeticException: [CAST_OVERFLOW_IN_TABLE_INSERT] Fail to insert a value of "BIGINT" type into the "INT" type column `i` due to an overflow. Use `try_cast` on the input value to tolerate overflow and return NULL instead.强制类型转换
当 spark.sql.ansi.enabled 设置为 true 时,Spark SQL采用了一系列规则来解决数据类型冲突。在这类冲突解决的核心是类型优先级列表,该列表定义了给定数据类型的值是否可以被隐式提升到另一种数据类型。

- 对于最不常见的类型,跳过浮点数以避免精度损失。
- 字符串可以升级为多种数据类型。请注意,字节/短/整数/十进制/浮点不在此先例列表中。Byte/Short/Int和String之间最不常见的类型是Long,而Decimal/Float之间最不常用的类型是Double。
- 对于复杂类型,优先级规则递归应用于其组成元素。
特殊规则适用于非类型化NULL。NULL可以升级为任何其他类型。
这是优先级列表作为有向树的图形描述:

最小公共类型解析
最小公共类型是从一组给定类型中找到的能够被所有类型共同转换到的最窄类型。这里的“窄”通常意味着转换的目标类型尽可能保持原始数据的特性和精度。
类型优先级列表定义了从一种类型转换到另一种类型的顺序。
- 用途
- 函数参数类型推导:对于期望多个参数具有相同类型的函数(如 coalesce, least, 或 greatest),最小公共类型解析用于确定这些参数的类型。
- 操作数类型推导:对于算术运算或比较操作,最小公共类型解析用于确定参与运算的操作数的类型。
- 表达式结果类型推导:对于如 case 表达式这样的复合表达式,最小公共类型解析用于确定最终结果的类型。
- 数组和映射构造器类型推导:对于数组和映射构造器,最小公共类型解析用于确定元素、键或值的类型。
- FLOAT 类型的特殊规则
- 如果最小公共类型解析为 FLOAT 类型,那么对于 float 类型值,如果其中任何类型是 INT, BIGINT, 或 DECIMAL,最小公共类型会被提升至 DOUBLE 类型。
- 这样做是为了避免由于 FLOAT 类型的精度限制而导致的潜在数字丢失,确保数据转换过程中不会损失重要的数值信息。
通过这种方式,Spark SQL能够确保在处理不同类型数据的交互时,能够根据ANSI SQL标准进行合理的类型转换和数据处理,从而保证数据处理的准确性和一致性。
-- The coalesce function accepts any set of argument types as long as they share a least common type.
-- The result type is the least common type of the arguments.
> SET spark.sql.ansi.enabled=true;
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: Incompatible types [INT, DATE]> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)));
ARRAY<BIGINT>
> SELECT typeof(coalesce(1, 1F));
DOUBLE
> SELECT typeof(coalesce(1L, 1F));
DOUBLE
> SELECT (typeof(coalesce(1BD, 1F)));
DOUBLE> SELECT typeof(coalesce(1, '2147483648'))
BIGINT
> SELECT typeof(coalesce(1.0, '2147483648'))
DOUBLE
> SELECT typeof(coalesce(DATE'2021-01-01', '2022-01-01'))
DATE
SQL函数
- 函数调用的一般规则
- 在启用ANSI模式时,Spark SQL中的函数调用会遵循存储分配规则,这意味着函数的输入值会被转换为函数参数声明的类型。
- 这意味着如果函数参数声明了一个特定的数据类型,那么传递给函数的输入值将被尝试转换为该类型。
- 未指定类型的 NULL 值的特殊规则
- 对于未指定类型的 NULL 值,存在特殊的处理规则。在这种情况下,NULL 值可以被提升为任何其他类型。
- 这意味着如果一个参数是 NULL 并且没有指定类型,那么它可以在函数调用中被当作任何类型的值来处理。
- 这种灵活性有助于处理在函数调用中可能出现的不同类型的 NULL 值,从而使得函数调用更加灵活和通用。
通过这种方式,Spark SQL在启用ANSI兼容性模式时,能够更加严格地遵循SQL标准,并在处理函数调用时确保数据类型的正确性和一致性。这有助于在处理复杂的数据转换和函数调用时避免潜在的问题。
> SET spark.sql.ansi.enabled=true;
-- implicitly cast Int to String type
> SELECT concat('total number: ', 1);
total number: 1
-- implicitly cast Timestamp to Date type
> select datediff(now(), current_date);
0-- implicitly cast String to Double type
> SELECT ceil('0.1');
1
-- special rule: implicitly cast NULL to Date type
> SELECT year(null);
NULL> CREATE TABLE t(s string);
-- Can't store String column as Numeric types.
> SELECT ceil(s) from t;
Error in query: cannot resolve 'CEIL(spark_catalog.default.t.s)' due to data type mismatch
-- Can't store String column as Date type.
> select year(s) from t;
Error in query: cannot resolve 'year(spark_catalog.default.t.s)' due to data type mismatch
参考文献
https://spark.apache.org/docs/latest/sql-ref-ansi-compliance.html