LLM Agent部署框架
围绕 ChatGPT 的讨论,现在已经演变为AI 代理。
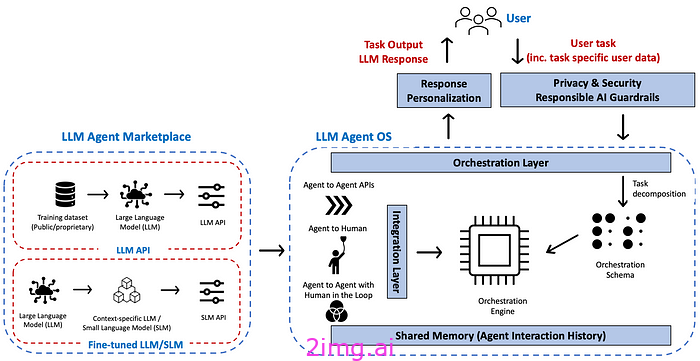
图:AI代理平台参考架构
比尔盖茨最近设想(CNBC 采访:链接)未来我们将拥有一个能够处理和响应自然语言并完成许多不同任务的AI 代理。盖茨以计划旅行为例。通常,这将涉及您自己预订酒店、航班、餐厅等。但 AI 代理将能够利用其对您的偏好的了解来代表您预订和购买这些东西。
据报道,OpenAI 还在开发能够自主为用户执行任务的 AI 代理(链接)。OpenAI 正在开发的一种代理软件可以有效地接管用户的设备,以自动执行工作等环境中的复杂任务。
然而,设计和部署人工智能代理在实践中仍然具有挑战性。
在本文中,我尝试围绕实现这种 AI 代理平台所需的基本组件 / 框架整理一些初步想法:
给定一个用户任务, AI 代理平台的目标是识别(组成)能够执行给定任务的代理(代理组)。
- 编排层(任务分解到编排引擎中,由编排引擎执行)
AI 代理在围绕 #Autonomous 代理(尤其是面向目标的代理)的研究方面有着悠久的历史。解决此类复杂任务的高级方法包括:(a) 将给定的复杂任务分解为(层次结构或工作流)简单任务,然后 (b) 组合能够执行简单任务的代理。这可以以动态或静态方式实现。
在动态方法中,给定一个复杂的用户任务,系统会根据运行时可用代理的功能制定一个计划来满足请求。在静态方法中,给定一组代理,在设计时手动定义复合代理,结合它们的功能。
- 代理市场:这意味着存在一个代理市场/注册中心——对代理能力和约束有明确的描述。我们在[1]中详细研究了代理的发现方面。
- 集成层支持不同的代理交互模式,例如代理到代理 API、代理 API 提供输出供人类使用、人类触发 AI 代理、AI 代理到代理(人类参与其中)。集成模式需要底层 #LLMOps [2] 平台的支持。
Andrew Ng 最近从性能角度谈到了这方面(来源文章:Pop Song Generators, 3D Mesh Generators, Real-World Benchmarks, and more):
如今,许多 LLM 输出都是供人类使用的。但在代理工作流中,LLM 可能会被反复提示反思和改进其输出、使用工具、计划和执行多个步骤,或实现多个协作的代理。因此,在向用户显示任何输出之前,我们可能会生成数十万个或更多的 token。这使得快速 token 生成非常可取,而较慢的生成速度则成为充分利用现有模型的瓶颈。
- 共享内存层支持代理之间的数据传输,存储交互数据,以便用于个性化未来的交互。
- 隐私与安全:确保用户共享的特定于此任务的数据或跨任务的用户配置文件数据仅与相关代理共享(身份验证和访问控制)。有关从隐私角度对 AI 代理/对话代理的详细讨论,请参阅 [3、4]。
 欢迎前往我们的公众号,资讯
欢迎前往我们的公众号,资讯
创作不易,觉得不错的话,点个赞吧!!!













![[HDCTF 2023]Welcome To HDCTF 2023](https://i-blog.csdnimg.cn/direct/0677a40a04a74f568a9ae0da4fa546fb.png)


