文章目录
- 1.认识redis
- 1.1 mysql和redis 对比
- 1.2分布式系统
- 1.2.1单机架构与分布式架构
- 1.2.2数据库分离(应用服务器和存储服务器分离)与负载均衡
- 1.2.3负载均衡器
- 1.2.4 数据库读写分离
- 1.2.5 数据库服务器引入缓存
- 1.2.6数据库分库分表
- 1.2.7 引入微服务
- 2.常见概念解释
- 2.1 应用(Application)/系统(System)
- 2.2 模块(Module)/组件(Component)
- 2.3 分布式(Distributed)
- 2.4 集群(Cluster)
- 2.5 主(Master)/从(Slave)
- 2.6 中间件(Middleware)
- 2.7可用性(Availability)
- 2.8 响应时长(Response Time RT)
- 2.9吞吐(Throughput) vs 并发 (Concurrent)
- 3.总结
大家好,我是晓星航。今天为大家带来的是 初始redis 相关的讲解!😀
1.认识redis
Redis是一个 客户端-服务器 结构的程序。
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。
Redis 是在分布式系统中,才能发挥威力的~~
众所周知,进程是有隔离性的,进程间的通信要依赖网络。而我们的redis就是基于网络,可以把自己内存中的变量给别的进程使,甚至别的主机的进程进行使用。
如果只是单机程序,直接通过变量存储数据的方式是比使用 Redis 更优的选择
1.1 mysql和redis 对比
MySQL 最大的问题在于,访问速度比较慢~~
很多互联网产品中,对于性能要求是很高~~
但是redis访问速度很快,与mysql对比redis最大的劣势就是存储空间是很有限的。
那么怎么样可以使我们存储空间又大,访问速度又快呢?
典型的方案,可以把 Redis 和 MySQL 结合起来使用
引入的问题:系统的复杂程度大大提升了,而且如果数据发生修改,还涉及到redis和mysql之间的数据同步问题。
1.2分布式系统
1.2.1单机架构与分布式架构
单机架构:只有一台服务器,这个服务器负责所有的工作
假设这是一个电商网站
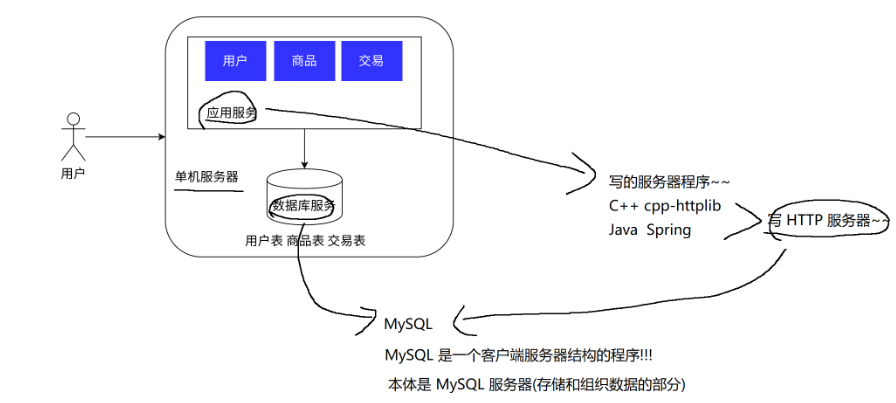
单机程序中,能不能把数据库服务器也去掉,光一个应用服务器又负责业务,又负责数据存储? (也不是不可以,但是就是会比较麻烦)
如果业务进一步增长,用户量和数据量都水涨船高,一台主机难以应付的时候,就需要引入更多的主机,引入更多的硬件资源
一台主机的硬件资源是有上线的!!!

如果我们真的遇到了这样的服务器不够用的场景,怎么处理呢?
1.开源 简单粗暴,增加更多的硬件资源 --> 一台主机拓展到极限了,但还是不够,那么就只能引入多台主机了(分布式)
2.节流 软件上优化。(各凭本事了,需要通过性能测试,找到是哪个环节出现了瓶颈,再去对症下药)
开源到上限引入多台主机(分布式),这是无奈之举,系统的复杂程度因此会大大提高 --> 出现bug的概率提高 --> 加班概率 & 丢失年终奖的概率 随之提高
1.2.2数据库分离(应用服务器和存储服务器分离)与负载均衡
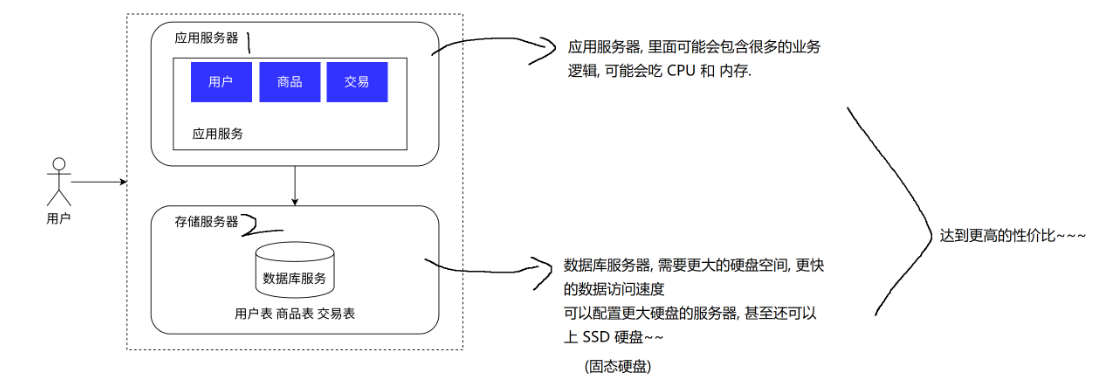
1.机械硬盘,便宜,慢
2.固态硬盘,贵,快
引入更多的应用服务器节点
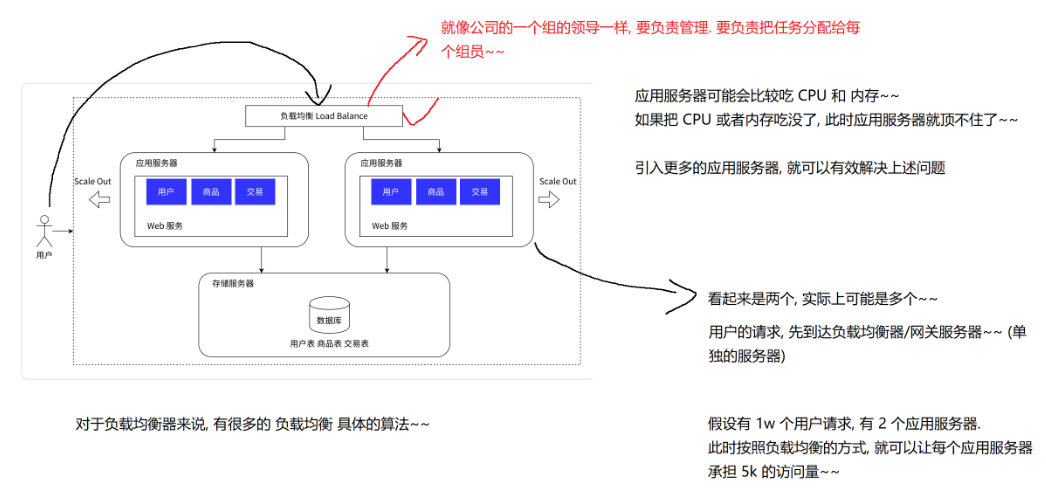
1.2.3负载均衡器
这里的负载均衡器,看起来承担了所有的请求,他能顶得住吗?
负载均衡器,对于请求量的承担能力,要远超于应用服务器。
负载均衡器,是领导,分配工作。
应用服务器,是组员,执行任务。
是否会出现,请求量大到负载均衡器也扛不住了呢?也是有可能的!!!
解决这个问题只需要引入更多的负载均衡器即可(引入多个机房)
我们这里的负载均衡器和应用服务器可以理解为学校的校长以及老师,校长类似于负载均衡器负责规划学校未来的发展,发布学校平时的活动。而老师就相当于应用服务器,实施校长发布的教学活动,并保证学生们的健康成长!
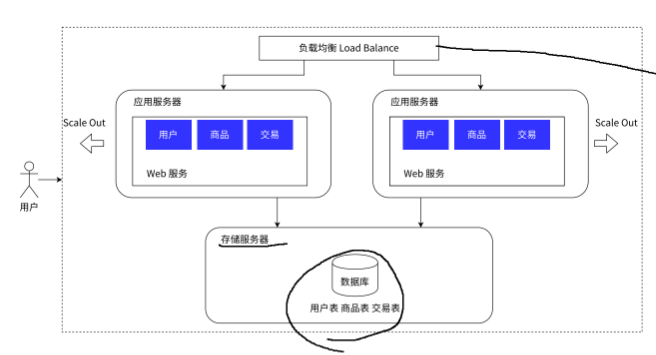
1.2.4 数据库读写分离
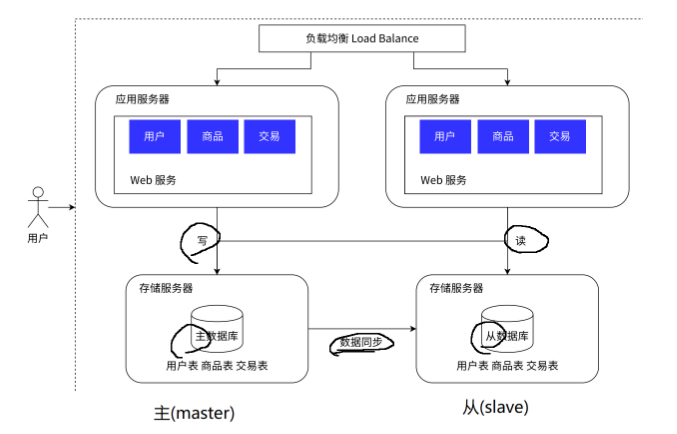
我们应用服务器变多了,那存储服务器只有一个会不会发生处理不过来呢?
答案是肯定的,因此我们把数据库服务器(存储服务器)也增加一个或者几个,并将读写分离开来,将他们分为主(master)数据库和从(slave)数据库。
我们之前数据库服务器只有一个,他既需要写入也需要读取操作。但现在我们拓展到两个数据库服务器,并把写操作和读操作分开到两个数据库服务器,这样我们数据库服务器的压力便会大大降低,从而达到可以处理更多数据的能力。
主服务器一般是一个,从服务器可以有多个(一主多从),同时从数据库通过负载均衡的方式,让应用服务器进行访问。
1.2.5 数据库服务器引入缓存
数据库天然有个问题,响应速度是更慢的!
把数据区分"冷热”,热点数据放到缓存中~缓存的访问速度往往比数据库要快很多了!
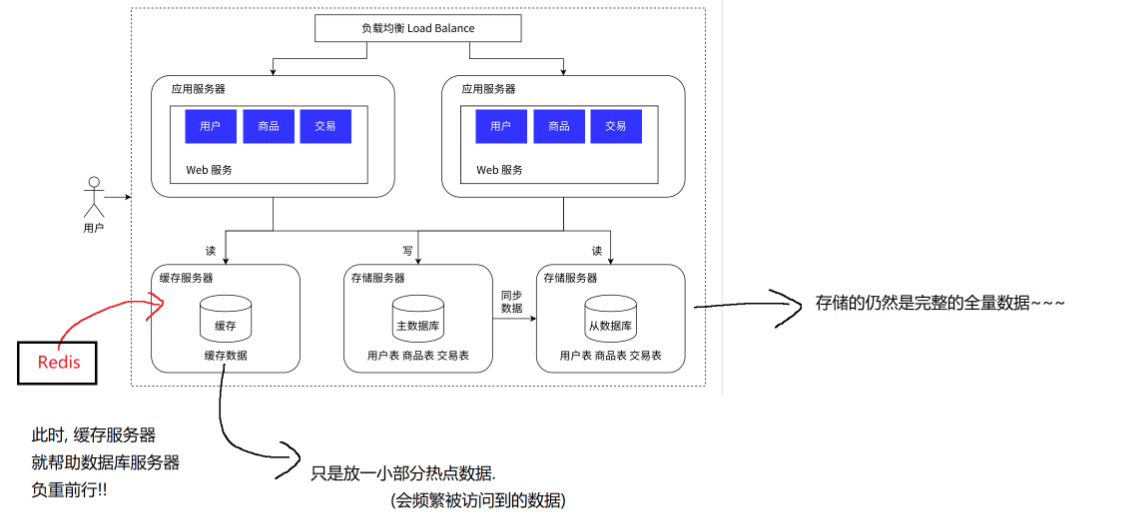
这里的缓存很小,因此他只能把频繁要访问的数据放进去
二八原则:20% 的人持有 80% 的财富~~~
计算机中的二八原则:

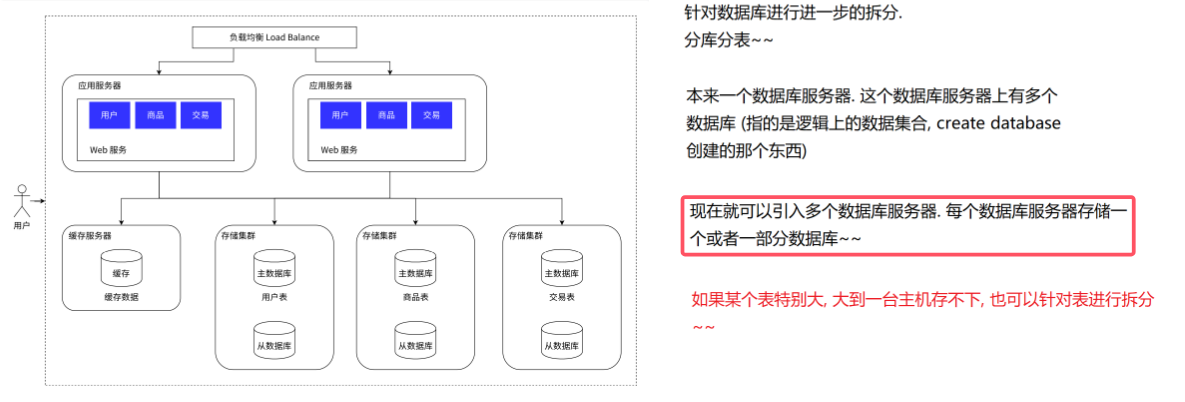
1.2.6数据库分库分表
引入分布式系统,不光要能够去应对更高的请求量(并发量),同时也要能应对更大的数据量
是否可能会出现,一台服务器已经存不下数据了呢?? 当然会存在!!!
虽然一个服务器, 存储的数据量可以达到 几十个 TB,即使如此也可能会存不下 短视频
一台主机存不下,就需要多台主机来存储
1.2.7 引入微服务
微服务架构
之前应用服务器,一个服务器程序里面做了很多的业务,这就可能会导致这一个服务器的代码变的越来越复杂
为了更方便于代码的维护,就可以把这样的一个复杂的服务器,拆分成更多的,功能更单一,但是更小的服务器

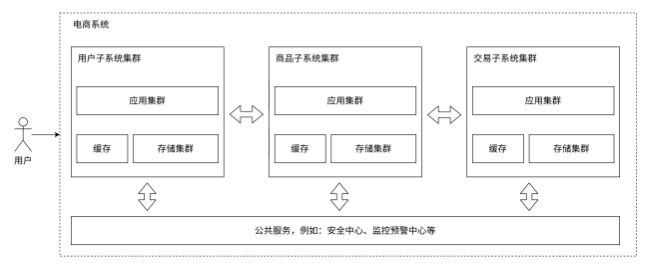
当应用服务器复杂了势必就需要更多的人来维护了,当人多了,就需要配套的管理,把这些人组织好
划分组织结构,分成多个组,每个组分别配备领导进行管理
分成多个组,就需要进行分工
引入微服务, 解决了人的问题,付出的代价?
1.系统的性能下降
(要想保证性能不下降太多,只能引入更多的机器,更多的硬件资源 => 充钱)
拆出来更多的服务,多个功能之间要更依赖 网络通信
网络通信的速度很可能是比硬盘还慢的!!!
2.系统复杂程度提高, 可用性收到影响
服务器更多了,出现问题的概率就更大了
这就需要一系列的手段,来保证系统的可用性
(更丰富的监控报警,以及配套的运维人员)
微服务的优势:
1.解决了人的问题
2.使用微服务,可以更方便于功能的复用
3.可以给不同的服务进行不同的部署
2.常见概念解释
2.1 应用(Application)/系统(System)
一个应用,就是一个/组 服务器程序
2.2 模块(Module)/组件(Component)
一个应用,里面有很多个功能. 每个独立的功能,就可以称为是一个 模块/组件
2.3 分布式(Distributed)
引入多个主机/服务器,协同配合完成一系列的工作.
物理上的多个主机
2.4 集群(Cluster)
引入多个主机/服务器,协同配合完成一系列的工作.
逻辑上的多个主机
2.5 主(Master)/从(Slave)
分布式系统中一种比较典型的结构
多个服务器节点,其中一个是主,另外的是从,从节点的数据要从主节点这里同步过来
2.6 中间件(Middleware)
和业务无关的服务(功能更通用的服务)
- 数据库
- 缓存
- 消息队列
2.7可用性(Availability)
系统整体可用的时间/总的时间
2.8 响应时长(Response Time RT)
衡量服务器的性能,越小越好
和具体服务器要做的业务密切相关
2.9吞吐(Throughput) vs 并发 (Concurrent)
衡量系统的处理请求的能力。衡量性能的一种方式
3.总结


8 响应时长(Response Time RT)
衡量服务器的性能,越小越好
和具体服务器要做的业务密切相关
感谢各位读者的阅读,本文章有任何错误都可以在评论区发表你们的意见,我会对文章进行改正的。如果本文章对你有帮助请动一动你们敏捷的小手点一点赞,你的每一次鼓励都是作者创作的动力哦!😘










![[HDCTF 2023]Welcome To HDCTF 2023](https://i-blog.csdnimg.cn/direct/0677a40a04a74f568a9ae0da4fa546fb.png)






