实践结论写在前面:
- github codespace很好用,丝滑、快速
- huggingface的space管理代码也很好用,自动编译、容器打包、发布一气呵成
- mindsearch很好用,效果超出预想。planner和searcher的交互丝滑、有效率。
- mindsearch内置搜索可解决很多通用问题,让agent的外挂API可以聚焦特定场景不重复造轮子
- 效果于远远超出以前试用的各种开源Agent,具备实用价值
0.MindSearch是什么
MindSearch 是一个开源的 AI 搜索引擎框架,具有与 Perplexity.ai Pro 相同的性能。您可以轻松部署它来构建您自己的搜索引擎,可以使用闭源 LLM(如 GPT、Claude)或开源 LLM(InternLM2.5 )系列模型经过专门优化,能够在 MindSearch 框架中提供卓越的性能;其他开源模型没做过具体测试)。其拥有以下特性:
- 🤔 任何想知道的问题:MindSearch 通过搜索解决你在生活中遇到的各种问题
- 📚 深度知识探索:MindSearch 通过数百网页的浏览,提供更广泛、深层次的答案
- 🔍 透明的解决方案路径:MindSearch 提供了思考路径、搜索关键词等完整的内容,提高回复的可信度和可用性。
- 💻 多种用户界面:为用户提供各种接口,包括 React、Gradio、Streamlit和本地调试。选择任意。
- 🧠 动态图构建过程:MindSearch 将用户查询分解为图中的子问题节点,并根据 WebSearcher 的搜索结果逐步扩展图。
MindSearch 采用多智能体框架模拟人类思维过程。它包含两个关键组件:WebPlanner(思考者)和 WebSearcher(执行者)。WebPlanner负责将用户查询分解为多个子问题,并构建有向无环图(DAG)来引导搜索;WebSearcher则负责分层检索策略,从互联网上检索并汇总有价值的信息。
随着硅基流动提供了免费的 InternLM2.5-7B-Chat 服务(免费的 InternLM2.5-7B-Chat 真的很香),MindSearch 的部署与使用也就迎来了纯 CPU 版本,进一步降低了部署门槛。那就让我们来一起看看如何使用硅基流动的 API 来部署 MindSearch 吧。
1. 创建开发机 & 环境配置
打开codespace主页,选择blank template。
浏览器会自动在新的页面打开一个web版的vscode。
接下来的操作就和我们使用vscode基本没差别了。
然后我们新建一个目录用于存放 MindSearch 的相关代码,并把 MindSearch 仓库 clone 下来。在终端中运行下面的命令:
mkdir -p /workspaces/mindsearch
cd /workspaces/mindsearch
git clone https://github.com/InternLM/MindSearch.git
cd MindSearch && git checkout b832275 && cd ..
接下来,我们创建一个 conda 环境来安装相关依赖。
# 创建环境
conda create -n mindsearch python=3.10 -y
# 激活环境
conda activate mindsearch
# 安装依赖
pip install -r /workspaces/mindsearch/MindSearch/requirements.txt
2. 获取硅基流动 API Key
因为要使用硅基流动的 API Key,所以接下来便是注册并获取 API Key 了。
首先,我们打开 https://account.siliconflow.cn/login 来注册硅基流动的账号(如果注册过,则直接登录即可)。
在完成注册后,打开 https://cloud.siliconflow.cn/account/ak 来准备 API Key。首先创建新 API 密钥,然后点击密钥进行复制,以备后续使用。
3. 启动 MindSearch
3.1 启动后端
由于硅基流动 API 的相关配置已经集成在了 MindSearch 中,所以我们可以直接执行下面的代码来启动 MindSearch 的后端。
export SILICON_API_KEY=第二步中复制的密钥
conda activate mindsearch
cd /workspaces/mindsearch/MindSearch
python -m mindsearch.app --lang cn --model_format internlm_silicon --search_engine DuckDuckGoSearch
3.2 启动前端
在后端启动完成后,我们打开新终端运行如下命令来启动 MindSearch 的前端。
conda activate mindsearch
cd /workspaces/mindsearch/MindSearch
python frontend/mindsearch_gradio.py
前后端都启动后,我们应该可以看到github自动为这两个进程做端口转发。

由于使用codespace,这里我们不需要使用ssh端口转发了,github会自动提示我们打开一个在公网的前端地址。
然后就可以即刻体验啦。如果遇到了 timeout 的问题,可以按照 文档 换用 Bing 的搜索接口。
3.3 验证
提问了一个问题,【请分析中国在巴黎奥运会和上届奥运会所获取奖牌情况的差异】
Planner负责将用户查询分解为多个子问题,并构建有向无环图(DAG)来引导搜索;Searcher则负责分层检索策略,从互联网上检索并汇总有价值的信息边规划边查询,结果超过预期,很智能的Agent。
3.4 全流程记录
下面是planner和searcher的回答的全流程:
planner
为了回答这个问题,我们需要首先获取中国在巴黎奥运会和上届奥运会(东京奥运会)的奖牌情况。
然后,我们将比较这两个数据集,找出差异。from ilagent.agents.python_web import WebSearchGraph
graph = WebSearchGraph()
graph.add_root_node(node_content="请分析中国在巴黎奥运会和上届奥运会所获取奖牌情况的差异", node_name="root")# 添加节点查询中国在巴黎奥运会的奖牌情况
graph.add_node(node_name="Paris_2024_medals",node_content="中国在2024年巴黎奥运会上获得了哪些奖牌?")
graph.add_edge(start_node="root", end_node="Paris_2024_medals")# 添加节点查询中国在上届东京奥运会的奖牌情况
graph.add_node(node_name="Tokyo_2020_medals",node_content="中国在2021年东京奥运会上获得了哪些奖牌?")
graph.add_edge(start_node="root", end_node="Tokyo_2020_medals")# 请求节点信息以查看当前状态
graph.node("Paris_2024_medals"), graph.node("Tokyo_2020_medals")
现在我们已经获取了关于中国在巴黎奥运会和东京奥运会的奖牌情况,
接下来我们将比较这两个数据集,找出差异。# 添加节点比较两个奥运会的奖牌情况
graph.add_node(node_name="medal_comparison",node_content="中国在2024年巴黎奥运会和2021年东京奥运会上的奖牌数量有何差异?")
graph.add_edge(start_node="Paris_2024_medals", end_node="medal_comparison")
graph.add_edge(start_node="Tokyo_2020_medals", end_node="medal_comparison")# 请求节点信息以查看当前状态
graph.node("medal_comparison")
现在我们已经详细比较了2024年巴黎奥运会和2021年东京奥运会上中国代表团的奖牌情况,并总结了其中的差异。
接下来,我们将添加一个回复节点来总结整个查询过程。graph.add_response_node(node_name="response")
graph.add_edge(start_node="medal_comparison", end_node="response")
在2024年巴黎奥运会和2021年东京奥运会上,中国代表团的奖牌情况存在显著差异。以下是对这两个奥运会的详细比较分析。### 2021年东京奥运会
在2021年东京奥运会上,中国代表团共获得了38枚金牌、32枚银牌和18枚铜牌,总计88枚奖牌[[11]][[14]][[15]]。这些奖牌分布在多个项目中,以下是一些主要项目的金牌情况:1. **射击**:中国队在射击项目上获得了4枚金牌、1枚银牌和6枚铜牌[[11]]。
2. **举重**:举重是中国代表团的传统强项之一,共获得7枚金牌(女子49公斤级侯志慧、男子61公斤级李发彬、男子67公斤级谌利军、男子73公斤级石智勇、男子81公斤级吕小军、女子87公斤级汪周雨以及女子87公斤以上级李雯雯)和1枚银牌(女子55公斤级廖秋云)[[11]]。
3. **游泳**:在游泳项目上,中国队表现出色,特别是杨浚瑄、汤慕涵、张雨霏和李冰洁组成的女子4x200米自由泳接力队以7分40秒33的成绩打破世界纪录并获得金牌[[11]]。此外,中国代表团还在其他多个项目中取得了优异成绩,包括乒乓球(5金3银2铜)、羽毛球(2金2银1铜)等[[11]][[14]]。总体而言,中国在2021年东京奥运会上的表现非常出色,总奖牌数位居第二位[[12]][[14]]。### 2024年巴黎奥运会
相比之下,在2024年巴黎奥运会上,中国代表团的表现更加出色。他们共获得了40枚金牌、27枚银牌和24枚铜牌,总计91枚奖牌[[0]][[1]][[8]]。这一成绩不仅使中国队在金牌榜上与美国队并列第一[[24]],而且在总奖牌数上也超过了东京奥运会的表现[[23]]。具体来看:
- **射击**:中国射击队在步枪项目上表现突出,共获得5枚金牌[[1]];
- **跳水**:跳水是中国的传统强项之一,本届奥运会摘得4金,再次展现了强大的实力 [[7];
- **举重**: 举重是中国的另一大优势项目,本届赛事中共获得6金 [[9];
- **羽毛球**: 羽毛球是中国的国球之一,本届赛事中赢得3金 [[10];此外,其他项目的优秀表现也为中国代表团的总奖牌数做出了贡献:
- 女子4x100米自由泳接力决赛斩获铜牌并打破亚洲纪录 [[7];
- 女子双人3米板跳水获得金牌等成绩 [[7]; 总体而言,从上述数据可以看出:
- 从38金增加到40金;
- 从32银增加到27银;
- 从18铜增加到24铜;
- 从88增至91;这些变化表明了中国体育代表团备战比赛中的进步与提升,尤其是在射击跳水和举重等传统优势项目的持续卓越表现.###总结差异:
通过对比两个奥运会的成绩可以发现:##### 一. 数量上的变化:
##### 二. 具体项目的变动:综上所述,
中国的体育实力在全球范围内持续提升,
并在竞技地位方面进一步巩固.
4. MindSearch部署到 HuggingFace Space
HuggingFace Space被墙了,需要使用VPN。
最后,我们来将 MindSearch 部署到 HuggingFace Space。
我们首先注册用户,然后打开 https://huggingface.co/spaces ,并点击 Create new Space,如下图所示。
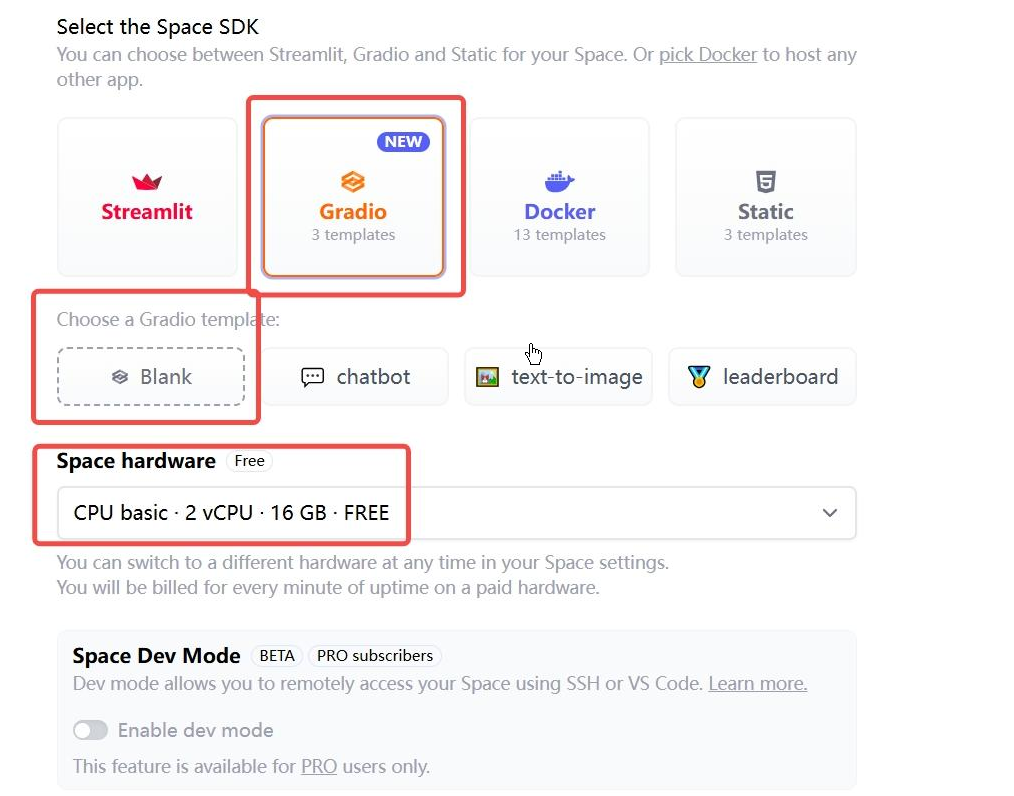
在输入 Space name 并选择 License(选MIT或者Aapche都可以) 后,选择配置如下所示。
然后,我们进入 Settings,配置硅基流动的 API Key。如下图所示。
选择 New secrets,name 一栏输入 SILICON_API_KEY,value 一栏输入你的 API Key 的内容。
最后,我们先新建一个目录,准备提交到 HuggingFace Space 的全部文件。(在github的codespace上操作)
# 创建新目录
mkdir -p /workspaces/mindsearch/mindsearch_deploy
# 准备复制文件
cd /workspaces/mindsearch
cp -r /workspaces/mindsearch/MindSearch/mindsearch /workspaces/mindsearch/mindsearch_deploy
cp /workspaces/mindsearch/MindSearch/requirements.txt /workspaces/mindsearch/mindsearch_deploy
# 创建 app.py 作为程序入口
touch /workspaces/mindsearch/mindsearch_deploy/app.py
其中,app.py 的内容如下(即demo的实现):
import json
import osimport gradio as gr
import requests
from lagent.schema import AgentStatusCodeos.system("python -m mindsearch.app --lang cn --model_format internlm_silicon &")PLANNER_HISTORY = []
SEARCHER_HISTORY = []def rst_mem(history_planner: list, history_searcher: list):'''Reset the chatbot memory.'''history_planner = []history_searcher = []if PLANNER_HISTORY:PLANNER_HISTORY.clear()return history_planner, history_searcherdef format_response(gr_history, agent_return):if agent_return['state'] in [AgentStatusCode.STREAM_ING, AgentStatusCode.ANSWER_ING]:gr_history[-1][1] = agent_return['response']elif agent_return['state'] == AgentStatusCode.PLUGIN_START:thought = gr_history[-1][1].split('```')[0]if agent_return['response'].startswith('```'):gr_history[-1][1] = thought + '\n' + agent_return['response']elif agent_return['state'] == AgentStatusCode.PLUGIN_END:thought = gr_history[-1][1].split('```')[0]if isinstance(agent_return['response'], dict):gr_history[-1][1] = thought + '\n' + f'```json\n{json.dumps(agent_return["response"], ensure_ascii=False, indent=4)}\n```' # noqa: E501elif agent_return['state'] == AgentStatusCode.PLUGIN_RETURN:assert agent_return['inner_steps'][-1]['role'] == 'environment'item = agent_return['inner_steps'][-1]gr_history.append([None,f"```json\n{json.dumps(item['content'], ensure_ascii=False, indent=4)}\n```"])gr_history.append([None, ''])returndef predict(history_planner, history_searcher):def streaming(raw_response):for chunk in raw_response.iter_lines(chunk_size=8192,decode_unicode=False,delimiter=b'\n'):if chunk:decoded = chunk.decode('utf-8')if decoded == '\r':continueif decoded[:6] == 'data: ':decoded = decoded[6:]elif decoded.startswith(': ping - '):continueresponse = json.loads(decoded)yield (response['response'], response['current_node'])global PLANNER_HISTORYPLANNER_HISTORY.append(dict(role='user', content=history_planner[-1][0]))new_search_turn = Trueurl = 'http://localhost:8002/solve'headers = {'Content-Type': 'application/json'}data = {'inputs': PLANNER_HISTORY}raw_response = requests.post(url,headers=headers,data=json.dumps(data),timeout=20,stream=True)for resp in streaming(raw_response):agent_return, node_name = respif node_name:if node_name in ['root', 'response']:continueagent_return = agent_return['nodes'][node_name]['detail']if new_search_turn:history_searcher.append([agent_return['content'], ''])new_search_turn = Falseformat_response(history_searcher, agent_return)if agent_return['state'] == AgentStatusCode.END:new_search_turn = Trueyield history_planner, history_searcherelse:new_search_turn = Trueformat_response(history_planner, agent_return)if agent_return['state'] == AgentStatusCode.END:PLANNER_HISTORY = agent_return['inner_steps']yield history_planner, history_searcherreturn history_planner, history_searcherwith gr.Blocks() as demo:gr.HTML("""<h1 align="center">MindSearch Gradio Demo</h1>""")gr.HTML("""<p style="text-align: center; font-family: Arial, sans-serif;">MindSearch is an open-source AI Search Engine Framework with Perplexity.ai Pro performance. You can deploy your own Perplexity.ai-style search engine using either closed-source LLMs (GPT, Claude) or open-source LLMs (InternLM2.5-7b-chat).</p>""")gr.HTML("""<div style="text-align: center; font-size: 16px;"><a href="https://github.com/InternLM/MindSearch" style="margin-right: 15px; text-decoration: none; color: #4A90E2;">🔗 GitHub</a><a href="https://arxiv.org/abs/2407.20183" style="margin-right: 15px; text-decoration: none; color: #4A90E2;">📄 Arxiv</a><a href="https://huggingface.co/papers/2407.20183" style="margin-right: 15px; text-decoration: none; color: #4A90E2;">📚 Hugging Face Papers</a><a href="https://huggingface.co/spaces/internlm/MindSearch" style="text-decoration: none; color: #4A90E2;">🤗 Hugging Face Demo</a></div>""")with gr.Row():with gr.Column(scale=10):with gr.Row():with gr.Column():planner = gr.Chatbot(label='planner',height=700,show_label=True,show_copy_button=True,bubble_full_width=False,render_markdown=True)with gr.Column():searcher = gr.Chatbot(label='searcher',height=700,show_label=True,show_copy_button=True,bubble_full_width=False,render_markdown=True)with gr.Row():user_input = gr.Textbox(show_label=False,placeholder='帮我搜索一下 InternLM 开源体系',lines=5,container=False)with gr.Row():with gr.Column(scale=2):submitBtn = gr.Button('Submit')with gr.Column(scale=1, min_width=20):emptyBtn = gr.Button('Clear History')def user(query, history):return '', history + [[query, '']]submitBtn.click(user, [user_input, planner], [user_input, planner],queue=False).then(predict, [planner, searcher],[planner, searcher])emptyBtn.click(rst_mem, [planner, searcher], [planner, searcher],queue=False)demo.queue()
demo.launch(server_name='0.0.0.0',server_port=7860,inbrowser=True,share=True)
在最后,将 /root/mindsearch/mindsearch_deploy 目录下的文件(使用 git)提交到 HuggingFace Space 即可完成部署了。注意将代码提交到huggingface space中需要配置hugginface的token。
提交到huggingface space的命令行,因为配置hugginface的token,需要修改一下git repo的地址。
#修改url增加用户名和token
#原来 https://huggingface.co/spaces/ydogg/mindsearch_deploy
#改为 https://ydogg:<token>@huggingface.co/spaces/ydogg/mindsearch_deploygit remote set-url origin https://ydogg:<token>@huggingface.co/spaces/ydogg/mindsearch_deploy
git pull origin
git add .
git commit -m "mindsearch"
git push origin
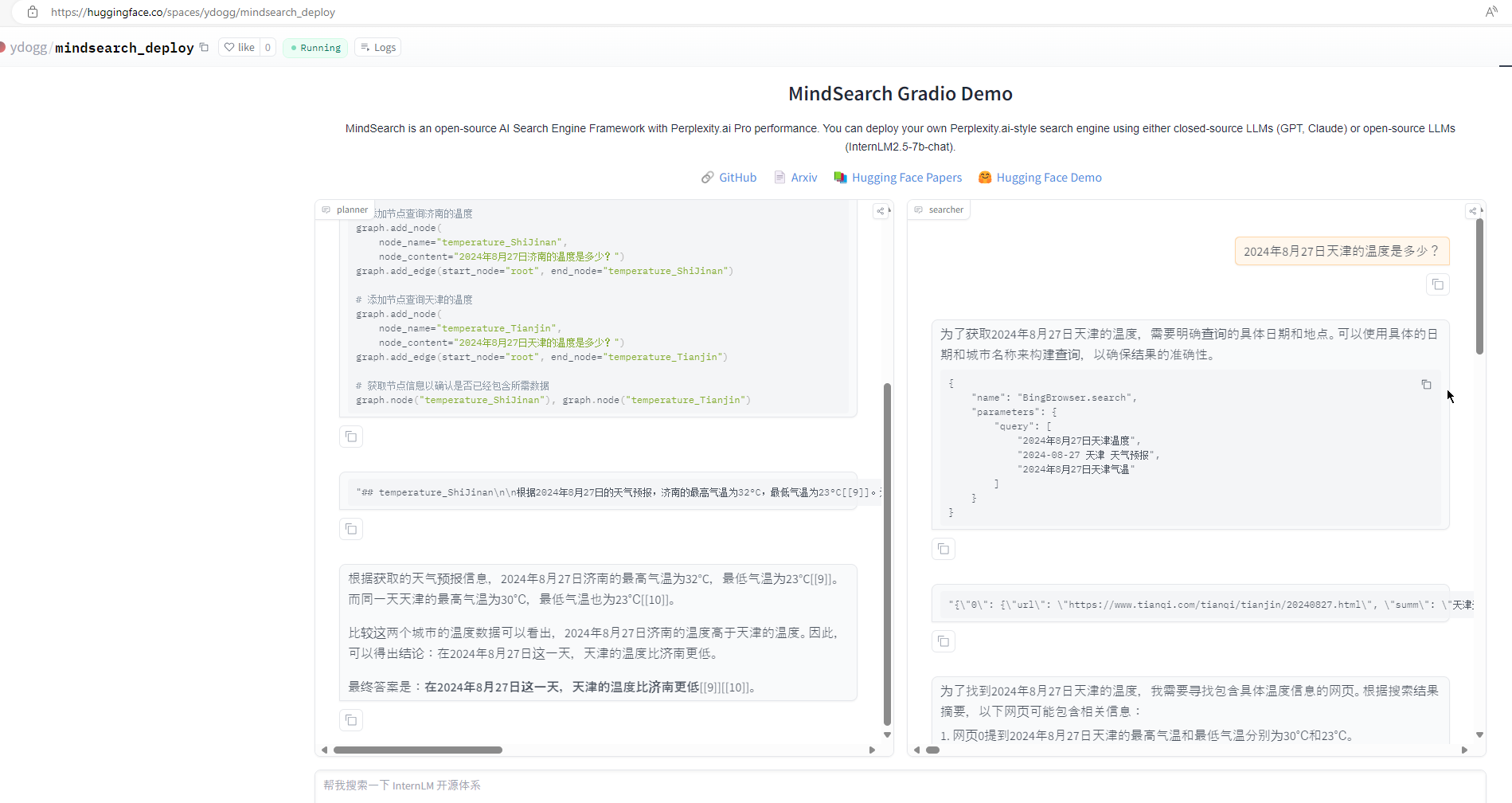
部署效果
提交后即可看到huggingface上自动开始部署,一键打包部署运行,还是很丝滑爽快的。可惜国内不能直接访问需要VPN。
询问的问题:请告诉我2024/08/27济南和天津哪边温度更低?可以看到planner的规划逻辑很清晰,并得出了正确结果。
为了回答这个问题,我们需要获取2024年8月27日济南和天津的温度信息。
这可以通过查询两个城市的天气预报来实现。
我们将分别查询济南和天津在2024年8月27日的温度,然后比较这两个温度以确定哪个城市的温度更低。from ilagent.agents.python_web import WebSearchGraph
graph = WebSearchGraph()
graph.add_root_node(node_content="2024/08/27济南和天津哪边温度更低?", node_name="root")# 添加节点查询济南的温度
graph.add_node(node_name="temperature_ShiJinan",node_content="2024年8月27日济南的温度是多少?")
graph.add_edge(start_node="root", end_node="temperature_ShiJinan")# 添加节点查询天津的温度
graph.add_node(node_name="temperature_Tianjin",node_content="2024年8月27日天津的温度是多少?")
graph.add_edge(start_node="root", end_node="temperature_Tianjin")# 获取节点信息以确认是否已经包含所需数据
graph.node("temperature_ShiJinan"), graph.node("temperature_Tianjin")