项目目标
- 开发一套基于YOLOv7的高精度实时人脸检测系统,适用于课堂场景。
- 实现对图片、视频、文件夹内的图像及摄像头流的实时人脸检测。
- 提供直观的图形界面,方便用户操作。
- 支持模型权重的灵活选择与加载,以及后处理参数的调整。
主要功能
-
模型加载与配置
- 支持加载多种格式的模型权重,如
.pt(PyTorch格式)、.onnx(ONNX格式)。 - 可以设置检测置信度阈值与后处理IoU阈值。
- 支持加载多种格式的模型权重,如
-
图像检测
- 导入单张图像并进行人脸检测。
- 检测结果的可视化,包括人脸位置的矩形框及标签。
- 统计图像中检测到的人脸数量。
-
视频检测
- 导入视频文件并逐帧进行人脸检测。
- 视频中检测结果的实时显示。
- 记录每帧的检测结果,统计视频中出现的人脸数量。
-
文件夹批量检测
- 批量导入文件夹中的所有图像进行人脸检测。
- 对每张图像的检测结果进行可视化。
- 提供整个文件夹中人脸数量的汇总统计。
-
摄像头实时检测
- 接入设备摄像头,进行实时的人脸检测。
- 实时显示检测结果,包括人脸的位置与数量。
- 支持多个摄像头的同时接入。
-
性能监控
- 展示单张图像、视频帧或摄像头流的推理时间。
- 提供平均检测速度的信息。
技术栈
- YOLOv7:作为核心的人脸检测算法。
- PySide6:用于构建图形用户界面。
- OpenCV:用于图像和视频处理。
- Python:主要编程语言。
- PyTorch:用于模型训练和推理。
- ONNX:用于模型的跨平台部署。
关键组件
- 数据预处理:清洗和整理人脸数据集。
- 模型训练:使用YOLOv7训练人脸检测模型。
- 模型部署:将训练好的模型转换为不同的格式以适应不同的部署需求。
- 用户界面:使用PySide6构建图形界面。
- 实时检测:开发实时检测逻辑,支持多种输入源。
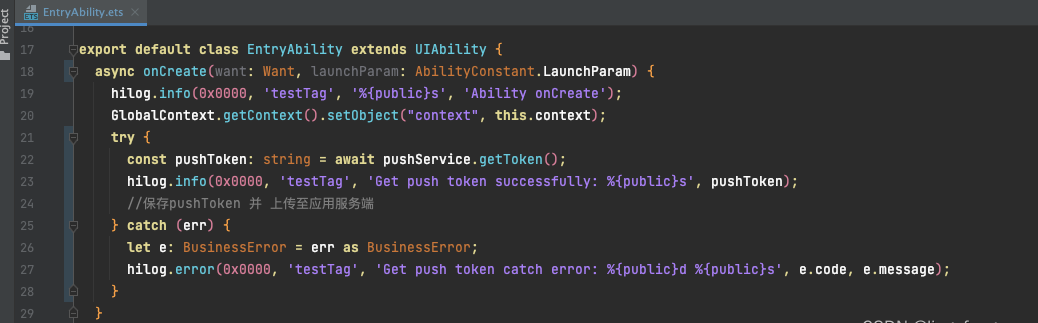
示例代码
这里给出一个简单的Python示例,展示如何使用YOLOv7进行人脸检测:
1import cv2
2import torch
3from models.experimental import attempt_load
4from utils.datasets import LoadImages, LoadStreams
5from utils.general import check_img_size, non_max_suppression, scale_coords
6from utils.plots import Annotator
7
8# 加载模型
9device = 'cuda' if torch.cuda.is_available() else 'cpu'
10model = attempt_load('weights/yolov7-face.pt', map_location=device)
11stride = int(model.stride.max())
12imgsz = check_img_size(640, s=stride) # 检查图像尺寸
13
14# 图像检测
15def detect_image(source):
16 dataset = LoadImages(source, img_size=imgsz, stride=stride)
17 for path, img, im0s, vid_cap in dataset:
18 img = torch.from_numpy(img).to(device)
19 img = img.float() # uint8 to fp16/32
20 img /= 255.0 # 0 - 255 to 0.0 - 1.0
21 if img.ndimension() == 3:
22 img = img.unsqueeze(0)
23
24 pred = model(img, augment=False)[0]
25 pred = non_max_suppression(pred, 0.4, 0.5, classes=0, agnostic=False)
26
27 for i, det in enumerate(pred): # detections per image
28 p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
29
30 annotator = Annotator(im0, line_width=3, example=str(names))
31 if len(det):
32 det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
33
34 for *xyxy, conf, cls in reversed(det):
35 c = int(cls) # integer class
36 label = f'{names[c]} {conf:.2f}'
37 annotator.box_label(xyxy, label, color=colors(c, True))
38
39 # 显示结果
40 cv2.imshow(p, im0)
41 if cv2.waitKey(1) == ord('q'): # q to quit
42 raise StopIteration
43
44# 视频检测
45def detect_video(source):
46 dataset = LoadImages(source, img_size=imgsz, stride=stride)
47 for path, img, im0s, vid_cap in dataset:
48 # ... (与图像检测类似)
49
50# 摄像头检测
51def detect_webcam():
52 dataset = LoadStreams('0', img_size=imgsz, stride=stride)
53 for path, img, im0s, vid_cap in dataset:
54 # ... (与图像检测类似)
55
56if __name__ == '__main__':
57 detect_image('path/to/image.jpg')
58 # 或者
59 # detect_video('path/to/video.mp4')
60 # 或者
61 # detect_webcam()用户界面
- 模型选择:允许用户选择不同的模型权重。
- 参数调整:提供滑块或输入框调整置信度和IoU阈值。
- 输入选择:可以选择图像、视频、文件夹或摄像头作为输入源。
- 结果展示:实时展示检测结果,并提供导出选项。
部署与维护
- 部署:确保系统能在不同操作系统上运行。
- 维护:定期更新模型和修复潜在的问题。
总结
该系统提供了一种易于使用且功能丰富的工具,可以实现在课堂场景下的人脸检测。无论是在学术研究还是实际应用中,这套系统都能提供必要的技术支持。