一、缓冲区大小对 I/O 系统调用性能的影响
-
总之,如果与文件发生大量的数据传输,通过采用大块空间缓冲数据,以及执行更少的 系统调用,可以极大地提高 I / O 性能
二、stdio 库的缓冲
-
当操作磁盘文件时,缓冲大块数据以减少系统调用,C 语言函数库的 I/O 函数(比如, fprintf()、fscanf()、fgets()、fputs()、fputc()、fgetc())正是这么做的。因此,使用 stdio 库可以 使编程者免于自行处理对数据的缓冲。
三、设置一个stdio流的缓冲模式
-
调用 setvbuf()函数,可以控制 stdio 库使用缓冲的形式
![]()
添加图片注释,不超过 140 字(可选)
2. 参数 stream 标识将要修改哪个文件流的缓冲。打开流后,必须在调用任何其他 stdio 函数 之前先调用 setvbuf()。setvbuf()调用将影响后续在指定流上进行的所有 stdio 操作。
3. 参数 buf 和 size 则针对参数 stream 要使用的缓冲区,指定这些参数有如下两种方式。
-
如果参数 buf 不为 NULL,那么其指向 size 大小的内存块以作为 stream 的缓冲区。因 为 stdio 库将要使用 buf 指向的缓冲区,所以应该以动态或静态在堆中为该缓冲区分配 一块空间(使用 malloc()或类似函数),而不应是分配在栈上的函数本地变量。否则,函 数返回时将销毁其栈帧,从而导致混乱。
-
若 buf 为 NULL,那么 stdio 库会为 stream 自动分配一个缓冲区(除非选择非缓冲的 I/O,如下所述)
4. 参数 mode 指定了缓冲类型,并具有下列值之一

5. setbuf()函数构建于setvbuf()之上,执行了类似任务
#include <stdio.h>
int setvbuf(FILE *stream, char *buf, int mode, size_t size);-
setbuf(fp,buf)调用除了不返回函数结果外,就相当于:
setvbuf(fp, buf, ()buf!=NULL)? _IOFBF:_IONBUF, BUF_SIZE);-
BUFSIZ 定义于<stdio.h>头文件中。
6. setbuffer()函数类似于 setbuf()函数,但允许调用者指定 buf 缓冲区大小。
#define _BSD_SOURCE
#include <stdio.h>
void setbuffer(FILE* stream,char* buf,size_T size);三、同步 I/O 数据完整性和同步 I/O 文件完整性
-
SUSv3 定义的第一种同步 I/O 完成类型是 synchronized I/O data integrity completion,旨在 确保针对文件的一次更新传递了足够的信息(到磁盘),以便于之后对数据的获取。
-
Synchronized I/O file integrity completion 是 SUSv3 定义的另一种同步 I/O 完成,也是上述 synchronized I/O data integrity completion 的超集。该 I/O 完成模式的区别在于在对文件的一次 更新过程中,要将所有发生更新的文件元数据都传递到磁盘上,即使有些在后续对文件数据 的读操作中并不需要。
四、刷新缓冲区
-
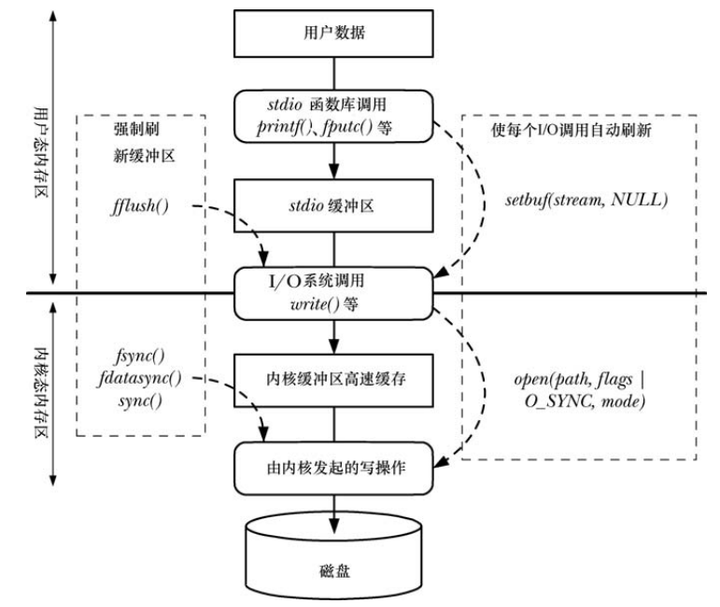
无论当前采用何种缓冲区模式,在任何时候,都可以使用 fflush()库函数强制将 stdio 输出流中的数据(即通过 write())刷新到内核缓冲区中
#include <stdio.h>
int fflush(FILE *stream);-
若参数 stream 为 NULL,则 fflush()将刷新所有的 stdio 缓冲区。
-
也能将 fflush()函数应用于输入流,这将丢弃业已缓冲的输入数据。(当程序下一次尝试从 流中读取数据时,将重新装满缓冲区。)
-
当关闭相应流时,将自动刷新其 stdio 缓冲区。
-
若打开一个流同时用于输入和输出,则 C99 标准中提出了两项要求。首先,一个输出操作不能紧跟一个输入操作,必须在二者之间调用 fflush()函数或是一个文件定位函数 (fseek()、fsetpos()或者 rewind())。其次,一个输入操作不能紧跟一个输出操作,必须在二者之间调用一个文件定位函数,除非输入操作遭遇文件结尾。
四、控制文件 I/O 的内核缓冲
-
用于控制文件 I/O 内核缓冲的系统调用
-
fsync()系统调用将使缓冲数据和与打开文件描述符 fd 相关的所有元数据都刷新到磁盘 上。
#include <unistd.h>
int fsync(int fd);2. 仅在对磁盘设备(或者至少是其高速缓存)的传递完成后,fsync()调用才会返回。
3. fdatasync()系统调用的运作类似于 fsync(),只是强制文件处于 synchronized I/O data integrity completion 的状态。
#include <unistd.h>int fdatasync(int fd);
4. fdatasync()可能会减少对磁盘操作的次数,由 fsync()调用请求的两次变为一次。例如,若 修改了文件数据,而文件大小不变,那么调用 fdatasync()只强制进行了数据更新。
5. 在 Linux 实现中,sync()调用仅在所有数据已传递到磁盘上(或者至少高速缓存)时返回。
| #include <unistd.h>void sync(void); |
|---|
五、使所有写入同步:O_SYNC
-
调用 open()函数时如指定 O_SYNC 标志,则会使所有后续输出同步(synchronous)。
fd = open(pathname,O_WRONLY|O_SYNC)
2. 调用 open()后,每个 write()调用会自动将文件数据和元数据刷新到磁盘上(即,按照 Synchronized I/O file integrity completion 的要求执行写操作)。
3. 总之,如果需要强制刷新内核缓冲区,那么在设计应用程序时就应考虑是否可以使用大 尺寸的 write()缓冲区,或者在调用 fsync()或 fdatasync()时谨慎行事,而不是在打开文件时就使用 O_SYNC 标志。
六、O_DSYNC 标志
-
O_DSYNC 标志要求写操作按照 synchronized I/O data integrity completion 来执行(类似于 fdatasync())。与之相映成趣的是 O_SYNC 标志,遵从 synchronized I/O file integrity completion (类似于 fsync()函数)。
七、I/O缓冲小结
-
首先是通过 stdio 库将用户数据传递到 stdio 缓冲区,该缓冲区 位于用户态内存区。当缓冲区填满时,stdio 库会调用 write()系统调用,将数据传递到内核高 速缓冲区(位于内核态内存区)。最终,内核发起磁盘操作,将数据传递到磁盘。
添加图片注释,不超过 140 字(可选)
八、就I/O模式向内核提出建议
-
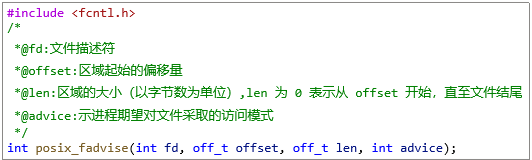
posix_fadvise()系统调用允许进程就自身访问文件数据时可能采取的模式通知内核
添加图片注释,不超过 140 字(可选)
| advice | 含义 |
|---|---|
| POSIX_FADV_NORMAL | 进程对访问模式并无特别建议。如果没有建议,这就是默认行为。在 Linux 中,该操作将文件预读窗口大小置为默认值(128KB)。 |
| POSIX_FADV_SEQUENTIAL | 进程预计会从低偏移量到高偏移量顺序读取数据。在 Linux 中,该操作将文件预读窗口大小置为默认值的两倍。 |
| POSIX_FADV_RANDOM | 进程预计以随机顺序访问数据。在 Linux 中,该选项会禁用文件预读。 |
| POSIX_FADV_WILLNEED | 进程预计会在不久的将来访问指定的文件区域。内核将由 offset 和 len 指定区域的文件数 据预先填充到缓冲区高速缓存中。后续对该文件的 read()调用将不会阻塞磁盘 I/O,只需从缓 冲区高速缓存中抓取数据即可。 |
| POSIX_FADV_DONTNEED | 进程预计在不久的将来将不会访问指定的文件区域。这一操作给内核的建议是释放相关的高速缓存页面(如果存在的话)。 |
| POSIX_FADV_NOREUSE | 进程预计会一次性地访问指定文件区域,不再复用。这等于提示内核对指定区域访问一 次后即可释放页面。在 Linux 中,该操作目前不起作用 |
九、绕过缓冲区高速缓存:直接 I/O
-
Linux 允许应用程序在执行磁盘 I/O 时绕过缓冲区高速缓存,从用户空间直 接将数据传递到文件或磁盘设备。有时也称此为直接 I/O(direct I/O)或者裸 I/O(raw I/O)。
-
直接 I/O 只适用于有特定 I/O 需求的应用。例如数据库系统,其高速缓存和 I/O 优化机制均自成一体,无需内核消耗 CPU 时间和内存去完成相同任务。
可针对一个单独文件或块设备(比如,一块磁盘)执行直接 I/O。要做到这点,需要在调 用 open()打开文件或设备时指定 O_DIRECT 标志。
-
若一进程以 O_DIRECT 标志打开某文件,而另一进程以普通方式(即使用了高速缓存 缓冲区)打开同一文件,则由直接 I/O 所读写的数据与缓冲区高速缓存中内容之间不存在 一致性。应尽量避免这一场景。
十、直接 I/O 的对齐限制
-
因为直接 I/O(针对磁盘设备和文件)涉及对磁盘的直接访问,所以在执行 I/O 时,必须 遵守一些限制。
-
用于传递数据的缓冲区,其内存边界必须对齐为块大小的整数倍。
-
数据传输的开始点,亦即文件和设备的偏移量,必须是块大小的整数倍。
-
待传递数据的长度必须是块大小的整数倍。
十一、混合使用库函数和系统调用进行文件 I/O
-
在同一文件上执行 I/O 操作时,还可以将系统调用和标准 C 语言库函数混合使用。fileno() 和 fdopen()函数有助于完成这一工作。
#include <stdio.h>
fileno(FILE *stream);
FILE *fdopen(int fd, const char *mode);-
fdopen()函数对非常规文件描述符特别有用。正如后续章节将提及的,创建套接字和管道 的系统调用总是返回文件描述符。为了在这些文件类型上使用 stdio 库函数,必须使用 fdopen() 函数来创建相应文件流。
-
当使用 stdio 库函数,并结合系统 I/O 调用来实现对磁盘文件的 I/O 操作时,必须将缓冲问题牢记于心。I/O 系统调用会直接将数据传递到内核缓冲区高速缓存,而 stdio 库函数会等 到用户空间的流缓冲区填满,再调用 write()将其传递到内核缓冲区高速缓存。
#include <stdio.h>
#include <unistd.h>
int main()
{printf("To man the world is twofold, "); //fflush(stdout);setbuf(stdout,NULL);write(STDOUT_FILENO,"in accordance with his twofold attitude.\n",41);
}