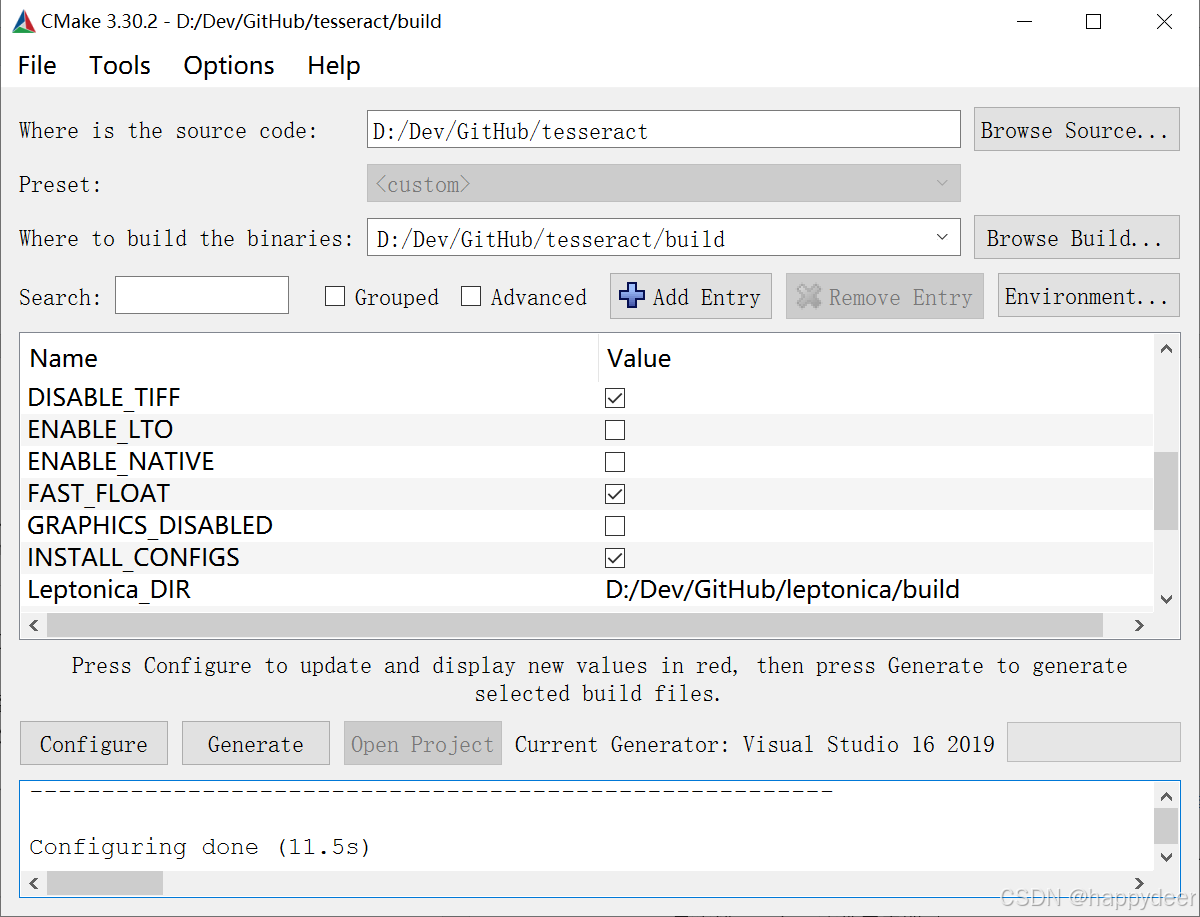
目录
一、知识抽取
1、实体命名识别(Name Entity Recognition)
2、关系抽取(Relation Extraction)
3、实体统一(Entity Resolution)
4、指代消解(Coreference Resolution)
二、知识图谱的存储
一、知识抽取
知识图谱的构建是后续应用的基础,而且构建的前提是需要把数据从不同的数据源中抽取出来。对于垂直领域的知识图谱来说,它们的数据源主要来自两种渠道:一种是业务本身的数据,这部分数据通常包含在公司内的数据库表并以结构化的方式存储;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在所以是非结构化的数据。
前者一般只需要简单预处理即可以作为后续AI系统的输入,但后者一般需要借助于自然语言处理等技术来提取出结构化信息。比如在上面的搜索例子里,Bill Gates和Malinda Gate的关系就可以从非结构化数据中提炼出来,比如维基百科等数据源。
信息抽取的难点在于处理非结构化数据。在构建图谱的过程当中,主要涉及以下几个方面的自然语言处理技术:
a. 实体命名识别(Name Entity Recognition)
b. 关系抽取(Relation Extraction)
c. 实体统一(Entity Resolution)
d. 指代消解(Coreference Resolution)
1、实体命名识别(Name Entity Recognition)
实体命名识别,就是从文本里提取出实体并对每个实体做分类/打标签;
2、关系抽取(Relation Extraction)
通过关系抽取技术,把实体间的关系从文本中提取出来,比如实体“hotel”和“Hilton property”之间的关系为“in”;“hotel”和“Time Square”的关系为“near”等等。

3、实体统一(Entity Resolution)
在实体命名识别和关系抽取过程中,有两个比较棘手的问题:一个是实体统一,也就是说有些实体写法上不一样,但其实是指向同一个实体。比如“NYC”和“New York”表面上是不同的字符串,但其实指的都是纽约这个城市,需要合并。实体统一不仅可以减少实体的种类,也可以降低图谱的稀疏性(Sparsity);
4、指代消解(Coreference Resolution)
另一个问题是指代消解,也是文本中出现的“it”, “he”, “she”这些词到底指向哪个实体,比如在本文里两个被标记出来的“it”都指向“hotel”这个实体。

二、知识图谱的存储
知识图谱主要有两种存储方式:一种是基于RDF的存储;另一种是基于图数据库的存储。它们之间的区别如下图所示。
RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。
其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。

其中Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式。相反,OrientDB和JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃,这也就意味着使用过程当中不可避免地会遇到一些刺手的问题。如果选择使用RDF的存储系统,Jena或许一个比较不错的选择。

部分参考自:这是一份通俗易懂的知识图谱技术与应用指南 | 机器之心 (jiqizhixin.com)
一个完整的知识图谱的构建包含以下几个步骤:1. 定义具体的业务问题 2. 数据的收集 & 预处理 3. 知识图谱的设计 4. 把数据存入知识图谱 5. 上层应用的开发,以及系统的评估。下面我们就按照这个流程来讲一下每个步骤所需要做的事情以及需要思考的问题。