w这套题,侧重模拟和题目理解,只要按照题目描述正常复现整体分数应该不错
一、数据重删
数据重删是一种节约存储空间的技术,通常情况下,在数据存储池内是有很多重复的数据库。重删则是将这些重复的数据块找出并处理的技术。简单地说重删,就是将NN份重复的数据快仅保留11份,并将N−1N−1份数据的地址指针指向唯一的那一份。
我们输入一串存储的数据,用NN表示数据个数,用KK标识号数据库的大小,设计一个方法判断当前数据块是否和前面的数据库有重复,两个数据库内容完全一样则表示重复。如果重复则将这个数据库删除,并且在第一个出现数据库的后面增加重复数据的计数,输出经过重复之后的内容。
解答要求
时间限制:C/C++1000msC/C++1000ms,其他语言 2000ms2000ms
内存限制:C/C++256MBC/C++256MB, 其他语言512MB512MB
输入
8输入数据的个数
2数据块的大小
1 2 3 4 1 2 3 4依次是数据值
输出
1 2 2 3 4 2输出结果为去除重复数据后的结果,输出结果最后没有空格,以数字结尾,输出内容不改变输入数据库的顺序
样例1
输入
8
2
1 2 3 4 1 2 3 4
输出
1 2 2 3 4 2
解释
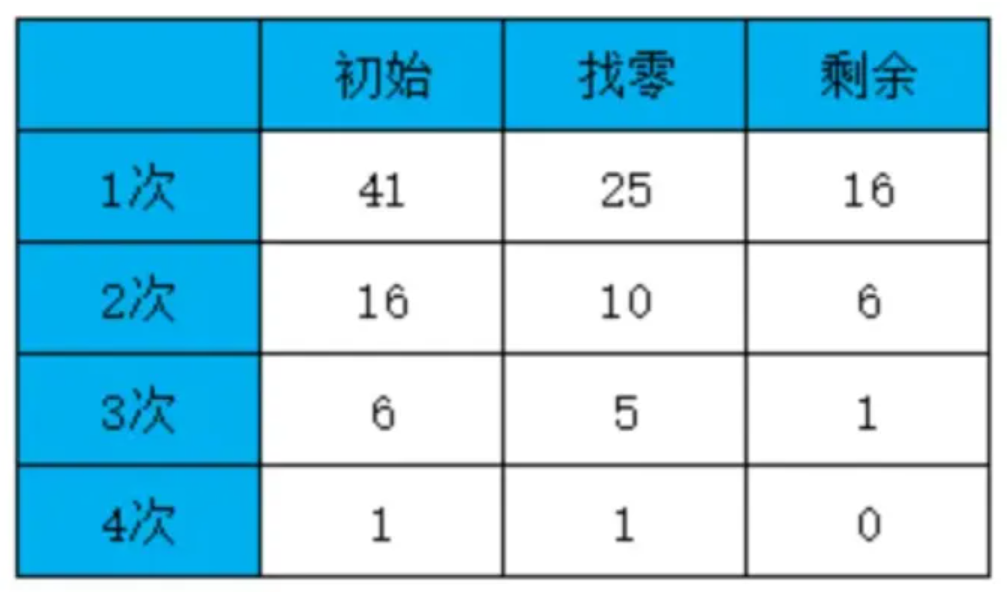
总共8个数据,数据库的大小为2,按新窗口进行切片表示一个数据块,分别得到数据库为[1,2],[3,4],
[1,2],[3,4]其中第一个数据块和第三个数据块相同,第二个数据块和第四个数据块相同,可以分别进行重测,重测之后数据库[1,2]的计数变为2,表示有两个相同的数据块[1,2],同理[3,4]d的数据块计数性变为2
题目分析:
【题目类型:模拟】
这道题就按照题目描述模拟即可,处理输入的时候可能稍微麻烦点。
代码:
n = int(input())
data_size = list(range(int(input())))
DataBase = {}temp_in = input().split()
idx = -1
while idx < n:data_block = ""for j in data_size:idx += 1if idx < n:data_block += " " + temp_in[idx]data_block = data_block[1:]if len(data_block) > 0:if data_block not in DataBase.keys():DataBase[data_block] = 1else:DataBase[data_block] +=1ans = ""
for data in DataBase.keys():ans += data + " " + str(DataBase[data]) + " "
print(ans[:-1])
二、任务调度
题目内容
1.某Devops系统有一批并发任务需要匹配合适的执行机调度执行,任务和执行机都具有CPU型(用0表示)和IO型(用1表示)的区别,此外还有一种通用型执行机(用2表示),一批任务和执行机的类型分别用数组tasks、machines表示,tasks[i]表示第i个任务,machines[i]表示执行机的类型。每台CPU型、IO型执行机只能执行一个对应类型的任务,而通用型执行机既能执行CPU类型任务也能执行IO类型任务。
2.假设现有的匹配策略如下:任务需要按照优先级从高到低依次匹配执行机(i=0优先级最高),因此每一轮选择任务数组头部(i=0)的任务去匹配空置执行机数组头部(i=0)的执行机,若任务与执行机类型匹配,则代表该任务调度成功,把该执行机从空置执行机数组中移除。若任务与执行机的类型不匹配,则将执行机放到执行机数组尾部,循环该过程直到任务全部匹配成功或当前任务无法被所有剩余空置执行机匹配。
3.现规定任意时刻都可以选择使用通用执行机,但一旦选择将某个类型的任务匹配通用型执行机,则所有通用型机器都只能用于执行该类型的任务,为了避免任务排队阻塞,请返回现有匹配策略下剩下的最小空置执行机数量。
解答要求
输入
输入共3行 首行是一个正整数n,表示任务数量以及执行机数量
第2行包含n个整数,以空格分隔,表示为任务数组tasks
第3行包含n个整数,以空格分隔,表示为空置执行机数组machines
数据范围:1≤n≤100,0≤tasks[i]≤1,0≤machines[i]≤2.1≤n≤100,0≤tasks[i]≤1,0≤machines[i]≤2.
输出
一行一个整数,代表当前匹配策略下剩下的最小空置执行机数量。
样例1
输入
3
1 0 1
1 2 0
输出
0
题目分析:
【题目类型:模拟】
n的数量级不是很大,根据题目直接模拟即可,需要注意确认好循环终止的条件。
代码:
import copyn = int(input())
tasks = [int(i) for i in input().split()]
machines = [int(i) for i in input().split()]
machines_cnt = {0:0, 1:0, 2:0}
for i in machines:machines_cnt[i] += 1def calc(exchange):tasks_copy = copy.deepcopy(tasks)machines_copy = copy.deepcopy(machines)for idx in range(len(machines_copy)):if machines_copy[idx] == 2:machines_copy[idx] = exchangemachines_cnt_copy = copy.deepcopy(machines_cnt)machines_cnt_copy[exchange] += machines_cnt_copy[2]while len(tasks_copy) > 0:if tasks_copy[0] == machines_copy[0]:machines_cnt_copy[tasks_copy[0]] -= 1tasks_copy.pop(0)machines_copy.pop(0)else:if machines_cnt_copy[tasks_copy[0]] == 0:return len(machines_copy)else:while tasks_copy[0] != machines_copy[0]:machines_copy.append(machines_copy.pop(0))return 0print(min(calc(0), calc(1)))三、亲和调度
题目内容
调度器上有一组将调度的任务(job),大部分任务之间存在亲和关系,需要优先把具有亲和关系的任务调度到同一个核上面,不亲和的任务不能运行在同一个核上面;
现在给定一组待调度的任务(任务编号和任务执行时间),同时会给出任务之间不存在亲和关系的列表(未给出的默认是亲和关系)。请设计一个调度器,按照如下要求:
1、找出一组包含亲和任务数量最多的亲和调度任务组;
2、如果规则1有多个解,给出所有任务执行时间之和最小的。并输出该亲和调度任务组的所有任务执行时间之和。
亲和调度任务组定义:一组可以在同一核上面执行的亲和任务集合
输入
首行是一个整数jobNum,表示任务数量,任务编号[1,jobNum],取值范围[1,30]
第二行jobNum个整数,表示每个任务的执行时间
第三行是一个整数mutexNum,表示不存在亲和关系的列表个数
接下来mutexNum行,每一行表示11对不亲和的任务编号,任务编号范围[1,jobNum]
输出
一个整数,表示所有任务的最短执行时间。
样例1
输入
3
2 3 10
1
1 2
输出
12
解释:有3个待调度任务,任务1和任务2不亲和,不能在一个核上执行;
1.亲和调度任务组有:“任务1”“任务2”“任务3”,“任务1+任务3”,“任务2+任务3”;
2.包含任务数量最参的亲和调度任务组合有两种:“任务1+任务3”,或“任务2+任务3”;
3.两个任务的执行时间分别为12和13,选样执行时间较小的“任务1+任务3”,输出12。
样例2
输入
1
1
0
输出
1
解释:只有一个任务,返回这个任务的执行时间。
样例3
输入
3
2 3 10
3
1 2
2 3
1 3
输出
2
解释:有3个待调度任务,任务1和任务2、任务2和任务3、任务1和任务3不亲和,不能在一个核上执行;
1、亲和调度任务组有:“任务1”,“任务2”,“任务3”;
2、包含任务数量最多的亲和调度任务组合有33种:“任务1”,“任务2”,“任务3”;
3、3个场景的执行时间分别为2、3、10,选择执行时间较小的“任务1”,输出2。
题目分析
【题目类型:模拟、最大团、回溯法】
这个题目是个标准的最大团问题,有标准解法,即:Bron–Kerbosch 算法。但是如果之前没有了解过标准的解法,在考场上很难一下子写出标程,推荐用优化大模拟的方式拿尽量多的分数。
【模拟】
1)这道题模拟的方式也有很多种,最朴素的就是我们有n种任务,那么就存在种组合,对于每种组合我们需要用O(
)的时间复杂度检验其是否是全联通的。
2)下面给出的模拟代码的逻辑是伴随着数据的输入,构造出m个约束下的所有可能性,同时计算每种行方法中,job的数量(time_list[-2])和时间花费time_list[-1]。这种方法最差情况下的时间复杂度是O()
【最大团回溯】
所谓团,就是一个完全图(图中任意两个节点都是联通的),题目所描述的目标就是找当前图中的最大团。
我们采用回溯的思想来实现本算法,输入两个形参R、P,R表示当前的团,P表示候选的点。在回溯过程中,我们只需要遍历候选点v,如果该点可以和R组成团,那么我们就把该点加入R中,并且从P中去除。当P中为空的时候,表明当前的R是个极大团,再判断他是否为最大团即可。
此外,还存在一些加速手段:在下一次回溯时,1)可以去除P中与当前候选v不联通的点;2)可以去除v之前的点(因为已经计算过了);3)如果R+P已经小于当前的最大团,就没有回溯的必要了。这种方法最差情况下的时间复杂度是O()
代码:
# 模拟
import copy
n = int(input())
time_list = [int(i) for i in input().split()]
time_list.append(n)
time_list.append(sum(time_list)-n)time_table = []
time_table.append(time_list)m = int(input())
for _ in range(m):i, j = map(int, input().split())i -= 1j -= 1idx = 0length = len(time_table)while idx < length:if time_table[idx][i] and time_table[idx][j]:time_table[idx][-2] -= 1temp = copy.deepcopy(time_table[idx])temp[-1] -= temp[j]temp[j] = 0time_table[idx][-1] -= time_table[idx][i]time_table[idx][i] = 0time_table.append(temp)idx += 1ans = [0, 0]
for tl in time_table:print(tl)if tl[-2] > ans[0] or (tl[-2] == ans[0] and tl[-1] < ans[1]):ans[0] = tl[-2]ans[1] = tl[-1]
print(ans[1])# 最大团回溯
n = int(input())
G_Nodes = [int(i) for i in input().split()]# 构建有向图
G_Edges = [[True for _ in range(n)] for __ in range(n) ]
for i in range(n):G_Edges[i][i] = False
m = int(input())
for _ in range(m):i, j = map(int, input().split())i -= 1j -= 1G_Edges[i][j] = FalseG_Edges[j][i] = FalseCliqueCnt = 0
CliqueSum = 0
# 判断当前v加入clique后能否组成新的团
def checkClique(clique, v):# O(n)for c in clique:if not G_Edges[v][c]:return Falsereturn True# 构造新的候选集合P
def get_newP(P, v):# O(n)new_P = []for p in P:if G_Edges[v][p]:new_P.append(p)return new_Pdef maxClique(R, P):global CliqueCntglobal CliqueSum# 右 剪枝 1:不可能组和出现更大的团了if len(P) + len(R) < CliqueCnt:return# 终止条件 1if len(P) == 0:if len(R) > CliqueCnt:CliqueCnt = len(R)CliqueSum = sum(G_Nodes[idx] for idx in R)elif len(R) == CliqueCnt:temp = sum(G_Nodes[idx] for idx in R)if temp < CliqueSum:CliqueSum = tempreturnfor P_idx in range(len(P)):if checkClique(R, P[P_idx]): # 如果 P[P_idx] 和 R 可以组成一个团new_R = R + [P[P_idx]]new_P = get_newP(P[P_idx:], P[P_idx]) # 右 剪纸 2:1)之前用的点不能作为候选点;2)当前点的不联通点不能作为候选点maxClique(new_R, new_P)returnmaxClique([], list(range(n)))
print(CliqueSum)