1.K-means 与 DBSCAN 的比较
K-means 和 DBSCAN 都是聚类算法,但它们之间有显著的区别:
-
K-means:
- 基于中心点的方法,要求用户提前指定簇的数量。
- 适用于球形簇,且簇大小相近。
- 无法处理噪声数据和任意形状的簇。
-
DBSCAN:
- 基于密度的方法,无需提前指定簇的数量。
- 可以发现任意形状的簇,并能识别噪声点。
- 适合处理含有噪声的数据集和不规则形状的簇。
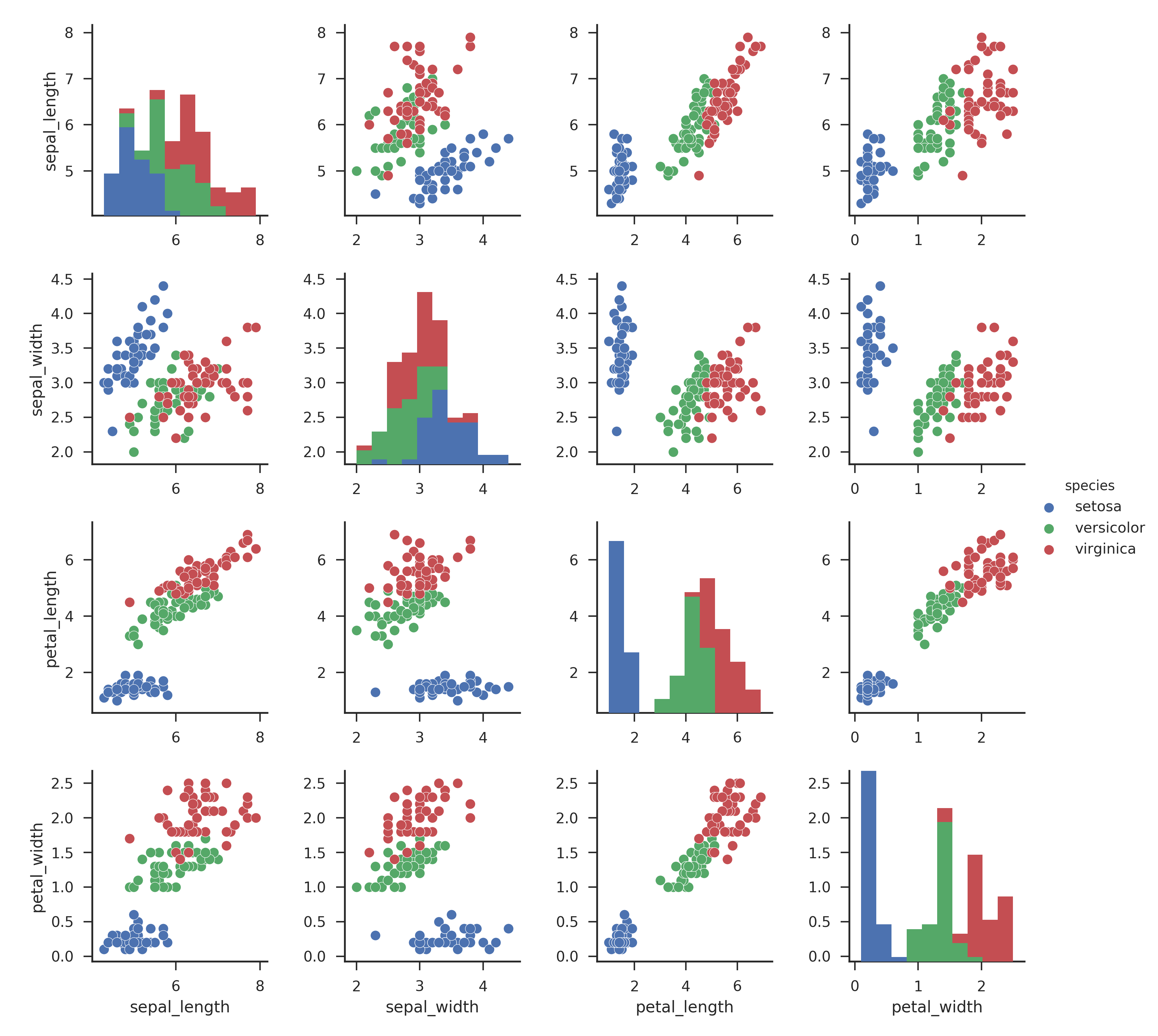
以下图中的数据为例,相比K-means,DBSCAN更适合作为数据的聚类算法。

2.DBSCAN 算法原理
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 是一种基于密度的聚类算法,其核心概念是通过密度来定义簇。DBSCAN 定义了一个点为核心点(Core Point),如果这个点周围半径 eps 内至少有 min_samples 个邻近点。如果一个点周围没有足够的邻近点,则被视为边界点(Border Point)。此外,任何不属于核心点或边界点的点都被视为噪声点。


3.实验代码详解
实验数据
data.txt 文件包含了多种啤酒的相关信息,具体来说,每一行代表了一种啤酒,并记录了四个属性:
- 名称 (
name): 啤酒的品牌名称。 - 卡路里 (
calories): 每份啤酒的卡路里含量。 - 钠含量 (
sodium): 每份啤酒的钠含量。 - 酒精度 (
alcohol): 啤酒的酒精百分比。 - 成本 (
cost): 啤酒的成本或价格。

导入库和数据
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn import metrics# 读取文件
beer = pd.read_table("data.txt", sep=' ', encoding='utf8', engine='python')# 传入变量(列名)
X = beer[["calories", "sodium", "alcohol", "cost"]]DBSCAN 聚类分析
db = DBSCAN(eps=20, min_samples=2).fit(X)
labels = db.labels_解释:
- 我们使用
DBSCAN类进行聚类分析。 eps参数定义了邻域的半径,即每个核心点周围必须有足够多的点才能成为核心点。min_samples参数定义了核心点周围必须有的最少邻近点数。labels是 DBSCAN 分配给每个样本的簇标签。标记-1表示该点被认为是噪声点。
添加结果至原始数据框
beer['cluster_db'] = labels
beer.sort_values('cluster_db')解释:
- 将 DBSCAN 的聚类结果添加到原始数据框
beer中的新列cluster_db。 - 使用
sort_values方法按簇标签排序,这一步虽然不会改变数据框的内容(因为默认情况下它返回排序后的副本),但可以方便查看输出。
对聚类结果进行评分
score = metrics.silhouette_score(X, beer.cluster_db)
print(score)解释:
- 使用
metrics.silhouette_score计算轮廓系数得分,该得分越高表示簇内的数据点越相似,簇间差异越大。 - 输出得分以评估聚类的效果。
4.总结
通过上述步骤,我们完成了 DBSCAN 聚类分析的过程。与 K-means 相比,DBSCAN 具有以下优势:
- 灵活性:DBSCAN 不需要预先知道簇的数量。
- 噪声处理:DBSCAN 能够有效地识别和排除噪声点。
- 任意形状簇:DBSCAN 能够发现任意形状的簇。
在本实验中,我们不仅实现了 DBSCAN 算法,还通过轮廓系数得分来评估聚类结果的质量。DBSCAN 的这些特性使其在处理复杂数据集时特别有用,尤其是在需要识别噪声和发现不规则簇形状的情况下。