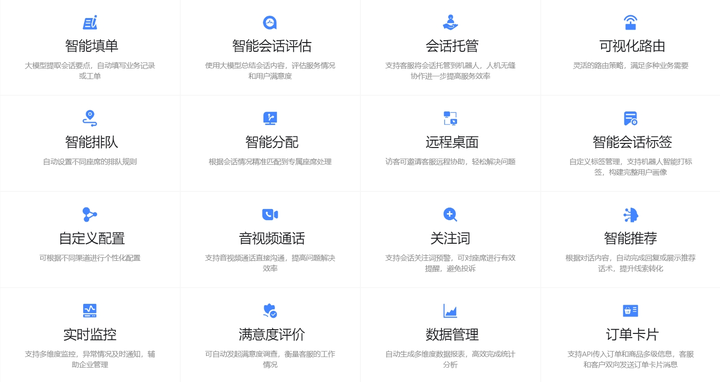
目录
一、Diffusion的基本概念和运作方法
1.Diffusion Model是如何运作的?
2.Denoise模块内部正在做的事情
如何训练Noise predictor?
1)Forward Process (Diffusion Process)
2)noise predictor
3.Text-to-Image
4.两个Algorithm
二、Diffusion Framework
1.Framework
①Text Encoder:将文字输入encoder为向量
FID:Frechet Inception Distance ↓
CLIP:Contrastive Language-Image Pre-Training
②Generation Model:输入一个噪声,得到图片的压缩版本
③Decoder:压缩的版本还原为原来的图片
Small pic
Auto-Encoder
2. Stable Diffusion
3.DALL-E series
4.Imagen (Google)
三、Diffusion Model数学原理剖析(1)
Algorithm1 Training
Algorithm2 Sampling
四、Diffusion Model数学原理剖析(2)
1.影像生成模型本质上的共同目标
2.Maximum Likelihood Estimation
视频链接:【生成式AI】Diffusion Model 概念讲解 (2/2)_哔哩哔哩_bilibili
原视频:【生成式AI】Diffusion Model 原理剖析 (1/4) (optional) (youtube.com)
课件链接:ML 2023 Spring (ntu.edu.tw)
一、Diffusion的基本概念和运作方法
1.Diffusion Model是如何运作的?
 Denoise Model 是同一个Model,但是由于每次输入的噪声严重程度不同,因此除了输入图片外,还引入一个数字,用来表示当前输入图片噪声的严重程度,比如 ”1“ 代表Denoise步骤快结束了
Denoise Model 是同一个Model,但是由于每次输入的噪声严重程度不同,因此除了输入图片外,还引入一个数字,用来表示当前输入图片噪声的严重程度,比如 ”1“ 代表Denoise步骤快结束了

2.Denoise模块内部正在做的事情

为什么不直接生成一个带噪音的猫?因为 noise predictor 的输出分布是简单的,而直接生成各种图片的分布是复杂的,所以 noise predictor 更容易训练,也就是说生成一张图片的噪音相对来说更容易
如何训练Noise predictor?

我们需要一个ground truth 来生成noise:


1)Forward Process (Diffusion Process)
通过一步步的加噪声,得到最终的噪音图,而每一步的step x 就代表在训练过程的第二个输入,每一步得到的加了噪音的图,就是训练过程的第一个输入(相当于反向过来看)
2)noise predictor
根据输入的step x和输入的噪音图,得到该张图片的噪声预测,减掉噪声得到最终results
3.Text-to-Image
文字输入作为noise predictor的额外的输入,描述当前图片



4.两个Algorithm

二、Diffusion Framework
1.Framework
:三个Model分开训练,然后再组合起来,且市面上大多数diffusion都是采用的这三个Model

①Text Encoder:将文字输入encoder为向量

图(a)表示测试不同Encoder对于实验结果的影响,FID越小越好,CLIP Score越大越好,即越往右下角越好,随着T5的size逐渐增大,实验结果越来越好
图(b)表示测试不同Diffusion Model对于实验结果的影响,可以看到增大Diffusion Model对于实验结果的帮助是有限的
FID和CLIP为衡量模型生成图片质量的指标,上述结论得出Encoder的重要性
FID:Frechet Inception Distance ↓
FID 是生成图像和真实图像在特征空间中的分布距离,FID 假设生成图像和真实图像在特征空间的分布都是高斯分布,然后计算这两个高斯分布的距离
首先有一个预训练好的CNN Model 影像分类模型,然后把所有图片(无论是真实还是生成数据)全部丢到CNN Model里面,然后得到真实影像和生成影像产生的representation,两组representation越接近就说明生成的数据越接近真实数据,反之亦然。
那么如何计算距离呢?: 直接计算Gaussians之间的idstance

CLIP:Contrastive Language-Image Pre-Training

可以用来测试输入的图片和文字的对应关系是否紧密
如果text 和 image 是成对的,那么他们encoder出来的向量 要越近越好;否则就要越远越好
②Generation Model:输入一个噪声,得到图片的压缩版本
Noise要加在中间产物或者latent representation上,而不是直接加在图片上
训练Decoder的时候不需要 图片和文字对应的训练数据,而训练Difussion Model的时候是需要的



③Decoder:压缩的版本还原为原来的图片
Small pic
- Decoder的输入是小图,输出是原始图片
- 所以我们可以对原始图片进行下采样,变成小图,然后小图和原始图片组成成对的数据集去训练Decoder即可。
- Imagen采用的Decoder就是小图还原为大图,做一个downsampling

Auto-Encoder
Diffusion和DALL采用的Decoder是Latent Representation,之前在讲Diffussion Model的时候,nosie是加到图片上面的,而现在我们的Framework里面扩散模型产生的是中间产物,他可能不是图片了,所以我们在diffusion process这一部分,把nosie加到中间产物(eg.latent representation)上面.
- 如果中间产物不是小图,而是Latent Reoresentation,那就要训练一个Auto-encoder
- 这个Auto-encoder要做的事情,就是将图片输入到encoder中,得到图片的潜在表示,然后将潜在表示输入到Decoder中,得到图片,让得到的图片与输入的图片越相近越好。
- 训练完,把这个Auto-encoder 中的Decoder拿出来用就好了

也可以通过downsampling进行小图+latent representation的训练

2. Stable Diffusion

3.DALL-E series

4.Imagen (Google)

三、Diffusion Model数学原理剖析(1)



Algorithm1 Training

如果T越大 则α_T 就越小,对应着原始图片占的比例越小,噪声占的比例越大


想象中,nosie 是一点一点加进去的
然后denoise 的时候也是一点一点去掉的
但是实际上,noise是一次直接加进去,denoise也是一次出去
Algorithm2 Sampling

一开始先sample 一个全都是noise的图片
步骤2 那里就是在跑 resverse process
本来以为得到了去除noise的结果就是最终结果,但实际操作过程中还要再加一张noise?
四、Diffusion Model数学原理剖析(2)
1.影像生成模型本质上的共同目标


加上文字的Condition并没有造成太大的差别,对算法影响不会太多
2.Maximum Likelihood Estimation