Diffusion 模型生成图片太慢了?用 AE(AutoEncoder) 和 VAE(Variational AutoEncoder) 压缩图片加速一波!
本文分为两个部分:理论学习和代码实践。
先预览一下 AE 和 VAE 模型的效果:

理论学习
本文价值
Diffusion 模型生成图片的效果堪称惊艳,但是推理速度慢的问题被广泛吐槽。本文介绍 Diffusion 模型推理加速的一种常见方式:用 AE(AutoEncoder) 和 VAE(Variational AutoEncoder) 进行图片压缩/反压缩。理论部分学完之后立即用代码进行实践,彻底掌握 AE/VAE。
AE 基础知识
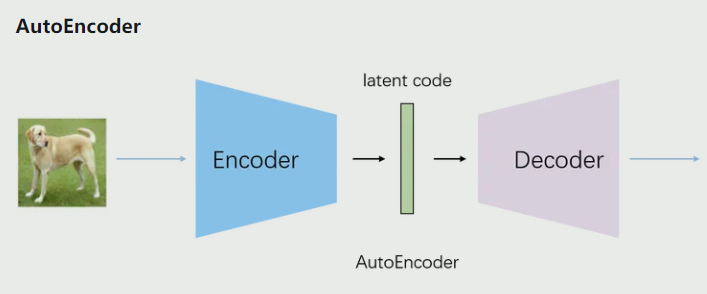
自编码器(AutoEncoder,AE)是一种无监督学习的神经网络模型,主要用于数据压缩和特征学习。它的核心结构包括两个主要部分:编码器和解码器。
编码器负责将输入数据压缩到一个低维的潜在空间,这个过程可以看作是提取输入数据的关键特征。解码器则尝试从这个压缩的表示重构原始输入,目标是使重构的输出尽可能接近原始输入。
AE 通过最小化重构误差来训练,这促使网络学习输入数据的最重要特征。训练完成后,编码器可以用于降维、特征提取或数据压缩,而完整的 AE 可以用于去噪或异常检测等任务。
AE 的优点包括结构简单、训练相对快速,以及可以学习紧凑的特征表示。然而,它也存在一些局限性,如生成能力有限,难以生成新的、有意义的样本。
VAE 基础知识

变分自编码器(VAE)是自编码器的一种概率变体,它结合了变分推断和神经网络,用于生成模型和表示学习。VAE 的核心思想是将输入数据编码为概率分布,而不是固定的向量。
VAE 的结构包括编码器、采样层和解码器。编码器将输入映射到潜在空间的均值和方差,采样层从这个分布中采样,解码器则从采样的潜在向量重构输入。
VAE 的训练目标包括两部分:重构损失和 KL 散度。重构损失确保模型能够准确重建输入,而 KL 散度则作为正则化项,使潜在空间的分布接近标准正态分布。
相比传统的自编码器,VAE 具有更强的生成能力,可以生成新的、合理的样本。它的潜在空间是连续的,便于插值,并且具有一定的正则化效果,有助于减少过拟合。
VAE 广泛应用于图像生成、异常检测、数据增强等领域。然而,它的训练过程可能较为复杂和不稳定,且 KL 散度项可能导致模型忽视部分输入信息。
对比 AE 和 VAE
| 特性 | AutoEncoder (AE) | Variational AutoEncoder (VAE) |
|---|---|---|
| 模型结构 | • 编码器:将输入压缩到潜在空间 • 解码器:从潜在空间重构输入 • 通常是确定性的 | • 编码器:将输入映射到潜在空间的均值和方差 • 采样层:从编码器输出的分布中采样 • 解码器:从采样的潜在向量重构输入 |
| 潜在空间 | 离散的点 | 连续的概率分布 |
| 损失函数 | 重构损失(如 MSE) | 重构损失 + KL 散度(正则化项) |
| 训练过程 | 1. 前向传播 2. 计算重构误差 3. 反向传播 4. 更新参数 | 1. 前向传播(包括采样步骤) 2. 计算重构误差和 KL 散度 3. 反向传播 4. 更新参数 |
| 推理过程 | 1. 输入通过编码器 2. 潜在向量通过解码器 | 1. 输入通过编码器得到分布参数 2. 从分布中采样 3. 采样的向量通过解码器 |
| 优点 | • 结构简单,易于理解和实现 • 训练相对快速 • 可以学习紧凑的特征表示 | • 生成能力强 • 潜在空间连续,便于插值 • 可以生成新的、合理的样本 • 具有正则化效果,减少过拟合 |
| 缺点 | • 生成能力有限 • 潜在空间可能不连续 • 难以生成新的、有意义的样本 • 可能过拟合训练数据 | • 结构和训练过程较复杂 • 训练可能更慢且不稳定 • KL 散度项可能导致模型忽视部分输入 |
| 应用场景 | • 数据压缩 • 降噪 • 特征提取 | • 图像生成 • 异常检测 • 数据增强 • 条件生成 |
| 潜在空间特性 | • 不保证平滑或有意义的插值 • 可能存在"空洞" | • 通常呈现高斯分布 • 允许平滑插值 • 潜在空间更加结构化 |
| 生成新样本 | 困难,通常需要额外的技巧 | 容易,直接从先验分布采样即可 |
| 对异常值的敏感度 | 较高,可能过度拟合异常值 | 较低,由于正则化效果而更鲁棒 |
| 可解释性 | 潜在表示可能难以解释 | 潜在空间通常更有结构,便于解释 |
代码实践
为了深刻理解 AE 和 VAE 的模型结构和训练/评测流程,我们自己动手实现在 MNIST 数据集上训练和评测 AE 和 VAE 模型。先看一下最终 AE 和 VAE 的重构效果:

我们先实现最简单的 Baseline 版本,这个版本的效果比较一般,主要是因为 latent space 维度为 3;然后我们改进 Baseline 版本,改进点包括:
-
将 latent space 维度从 3 --> 16; -
增加了网络深度和宽度; -
使用了 LeakyReLU 激活函数; -
添加了批归一化; -
使用了 AdamW 优化器和学习率调度器; -
增加了训练轮数到 500; -
添加了简单的数据增强(随机旋转和噪声); -
对 VAE 的 KL 散度使用了 β 参数(设为 0.5)来平衡重构质量和潜在空间的规则性。
Baseline 版本
先看效果图,再看代码:

完整的代码如下:
import torch,os
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
# 准备MNIST数据集
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 创建数据加载器
# batch_size: 每批处理的样本数
# shuffle: 是否在每个epoch打乱数据
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False)
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
# 编码器:将28x28的输入压缩到3维潜在空间
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3)
)
# 解码器:将3维潜在空间重构为28x28的输出
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28*28),
nn.Sigmoid() # 使用Sigmoid确保输出在[0,1]范围内
)
def forward(self, x):
"""
前向传播函数
参数:
x (torch.Tensor): 输入图像张量,形状为 (batch_size, 1, 28, 28)
返回:
torch.Tensor: 重构后的图像张量,形状为 (batch_size, 1, 28, 28)
"""
x = x.view(-1, 28*28) # 将输入展平
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded.view(-1, 1, 28, 28) # 重塑为原始图像形状
# 初始化AE模型
ae_model = AE()
ae_optimizer = optim.Adam(
ae_model.parameters(),
lr=0.0001
)
ae_criterion = nn.MSELoss() # 使用均方误差作为重构损失
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU()
)
# 均值和对数方差的全连接层
self.fc_mu = nn.Linear(64, 3)
self.fc_logvar = nn.Linear(64, 3)
# 解码器
self.decoder = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28*28),
nn.Sigmoid()
)
def encode(self, x):
"""
编码函数
参数:
x (torch.Tensor): 输入图像张量,形状为 (batch_size, 784)
返回:
tuple(torch.Tensor, torch.Tensor): 均值和对数方差,每个的形状为 (batch_size, 3)
"""
h = self.encoder(x)
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
"""
重参数化技巧
参数:
mu (torch.Tensor): 均值,形状为 (batch_size, 3)
logvar (torch.Tensor): 对数方差,形状为 (batch_size, 3)
返回:
torch.Tensor: 采样得到的潜在变量,形状为 (batch_size, 3)
"""
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
"""
解码函数
参数:
z (torch.Tensor): 潜在变量,形状为 (batch_size, 3)
返回:
torch.Tensor: 重构的图像,形状为 (batch_size, 784)
"""
return self.decoder(z)
def forward(self, x):
"""
前向传播函数
参数:
x (torch.Tensor): 输入图像张量,形状为 (batch_size, 1, 28, 28)
返回:
tuple: (重构图像, 均值, 对数方差)
- 重构图像 (torch.Tensor): 形状为 (batch_size, 1, 28, 28)
- 均值 (torch.Tensor): 形状为 (batch_size, 3)
- 对数方差 (torch.Tensor): 形状为 (batch_size, 3)
"""
x = x.view(-1, 28*28)
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z).view(-1, 1, 28, 28), mu, logvar
# 初始化VAE模型
vae_model = VAE()
vae_optimizer = optim.Adam(
vae_model.parameters(),
lr=0.0001
)
def vae_loss(recon_x, x, mu, logvar):
"""
VAE损失函数:重构损失 + KL散度
参数:
recon_x (torch.Tensor): 重构的图像,形状为 (batch_size, 784)
x (torch.Tensor): 原始图像,形状为 (batch_size, 784)
mu (torch.Tensor): 均值,形状为 (batch_size, 3)
logvar (torch.Tensor): 对数方差,形状为 (batch_size, 3)
返回:
torch.Tensor: 标量,表示总损失
"""
BCE = nn.functional.binary_cross_entropy(recon_x.view(-1, 28*28), x.view(-1, 28*28), reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
def train(epoch, model, optimizer, criterion, is_vae=False):
"""
训练函数
参数:
epoch (int): 当前训练的轮数
model (nn.Module): 要训练的模型(AE或VAE)
optimizer (torch.optim.Optimizer): 优化器
criterion (callable): 损失函数(仅用于AE)
is_vae (bool): 是否为VAE模型
返回:
None
"""
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
optimizer.zero_grad()
if is_vae:
recon_batch, mu, logvar = model(data)
loss = vae_loss(recon_batch, data, mu, logvar)
else:
recon_batch = model(data)
loss = criterion(recon_batch, data)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f'====> Epoch: {epoch} Average loss: {train_loss / len(train_loader.dataset):.4f}')
# 训练AE和VAE模型
num_epochs = 200
def compare_reconstructions(ae_model, vae_model):
"""
比较AE和VAE模型的重构效果
参数:
ae_model (nn.Module): 训练好的AE模型
vae_model (nn.Module): 训练好的VAE模型
返回:
None (显示图像)
"""
ae_model.eval()
vae_model.eval()
with torch.no_grad():
data = next(iter(test_loader))[0][:8] # 获取8个测试样本
ae_recon = ae_model(data)
vae_recon, _, _ = vae_model(data)
# 将原始图像、AE重构和VAE重构拼接在一起
comparison = torch.cat([data, ae_recon, vae_recon])
plt.figure(figsize=(12, 4))
for i in range(24):
plt.subplot(3, 8, i+1)
plt.imshow(comparison[i].squeeze().numpy(), cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.show()
# 创建保存路径
save_dir = "/root/autodl-tmp/projects/diffuser/handwritten_algos/ldm/res_images"
os.makedirs(save_dir, exist_ok=True)
# 保存图像
save_path = os.path.join(save_dir, f"{epoch}.png")
plt.savefig(save_path)
print(f"=> saved to {save_path}")
plt.close() # 关闭图像,防止内存泄漏
for epoch in range(1, num_epochs + 1):
train(epoch, ae_model, ae_optimizer, ae_criterion)
train(epoch, vae_model, vae_optimizer, None, is_vae=True)
# 比较重构效果
compare_reconstructions(ae_model, vae_model)
改进版本
先看最终效果,再看代码:

可以看出只要训练得当,AE 和 VAE 都能很好的压缩/反压缩图片,重构的效果很棒,肉眼看不出显著的差异!
完整代码如下:
import torch
import os
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 设置随机种子
torch.manual_seed(42)
# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 数据预处理和加载
transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.ToTensor(),
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128*8, num_workers=8, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=128*8, num_workers=8, shuffle=False)
class ImprovedAE(nn.Module):
def __init__(self):
super(ImprovedAE, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU(),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.LeakyReLU(),
nn.Linear(64, 16)
)
self.decoder = nn.Sequential(
nn.Linear(16, 64),
nn.BatchNorm1d(64),
nn.LeakyReLU(),
nn.Linear(64, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU(),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(),
nn.Linear(256, 28*28),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(-1, 28*28)
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded.view(-1, 1, 28, 28)
class ImprovedVAE(nn.Module):
def __init__(self):
super(ImprovedVAE, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU()
)
self.fc_mu = nn.Linear(128, 16)
self.fc_logvar = nn.Linear(128, 16)
self.decoder = nn.Sequential(
nn.Linear(16, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU(),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(),
nn.Linear(256, 28*28),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
x = x.view(-1, 28*28)
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z).view(-1, 1, 28, 28), mu, logvar
# 初始化改进后的模型并移动到 GPU
ae_model = ImprovedAE().to(device)
vae_model = ImprovedVAE().to(device)
# 使用 AdamW 优化器
ae_optimizer = optim.AdamW(ae_model.parameters(), lr=0.001, weight_decay=1e-5)
vae_optimizer = optim.AdamW(vae_model.parameters(), lr=0.001, weight_decay=1e-5)
# 学习率调度器
ae_scheduler = optim.lr_scheduler.ReduceLROnPlateau(ae_optimizer, patience=10, factor=0.5, verbose=True)
vae_scheduler = optim.lr_scheduler.ReduceLROnPlateau(vae_optimizer, patience=10, factor=0.5, verbose=True)
ae_criterion = nn.MSELoss()
def vae_loss(recon_x, x, mu, logvar, beta=1.0):
BCE = nn.functional.binary_cross_entropy(recon_x.view(-1, 28*28), x.view(-1, 28*28), reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + beta * KLD
def train(epoch, model, optimizer, scheduler, criterion, is_vae=False):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.to(device) # 将数据移动到 GPU
optimizer.zero_grad()
if is_vae:
recon_batch, mu, logvar = model(data)
loss = vae_loss(recon_batch, data, mu, logvar, beta=0.5)
else:
recon_batch = model(data)
loss = criterion(recon_batch, data)
loss.backward()
train_loss += loss.item()
optimizer.step()
avg_loss = train_loss / len(train_loader.dataset)
print(f'====> Epoch: {epoch} Average loss: {avg_loss:.4f}')
scheduler.step(avg_loss)
return avg_loss
def compare_reconstructions(ae_model, vae_model, epoch):
ae_model.eval()
vae_model.eval()
with torch.no_grad():
data = next(iter(test_loader))[0][:8].to(device) # 将数据移动到 GPU
ae_recon = ae_model(data)
vae_recon, _, _ = vae_model(data)
# 将重构结果移回 CPU 以进行可视化
data = data.cpu()
ae_recon = ae_recon.cpu()
vae_recon = vae_recon.cpu()
comparison = torch.cat([data, ae_recon, vae_recon])
plt.figure(figsize=(12, 4))
for i in range(24):
plt.subplot(3, 8, i+1)
plt.imshow(comparison[i].squeeze().numpy(), cmap='gray')
plt.axis('off')
plt.tight_layout()
# 创建保存路径
save_dir = "/root/autodl-tmp/projects/diffuser/handwritten_algos/ldm/res_images_v2"
os.makedirs(save_dir, exist_ok=True)
# 保存图像
save_path = os.path.join(save_dir, f"epoch_{epoch}.png")
plt.savefig(save_path)
print(f"=> saved to {save_path}")
plt.close() # 关闭图像,防止内存泄漏
# 训练循环
num_epochs = 500
for epoch in range(1, num_epochs + 1):
ae_loss = train(epoch, ae_model, ae_optimizer, ae_scheduler, ae_criterion)
vae_loss_val = train(epoch, vae_model, vae_optimizer, vae_scheduler, None, is_vae=True)
if epoch % 2 == 0:
print(f"Epoch {epoch}/{num_epochs}")
print(f"AE Loss: {ae_loss:.4f}, VAE Loss: {vae_loss_val:.4f}")
compare_reconstructions(ae_model, vae_model, epoch)
# save the model
save_ae_path = '/root/autodl-tmp/projects/diffuser/ckpts/custom/ae_vae/ae.pth'
save_vae_path = '/root/autodl-tmp/projects/diffuser/ckpts/custom/ae_vae/vae.pth'
torch.save(ae_model, save_ae_path); print(f"=> saved model to {save_ae_path}")
torch.save(vae_model, save_vae_path); print(f"=> saved model to {save_vae_path}")
print("Training complete!")
总结
至此我们学习了 AE/VAE 的理论,并亲自动手训练/推理了两种模型并比较了效果,并得出如下结论:
[!TIP] 只要训练得当,AE 和 VAE 都能很好的压缩/反压缩图片,重构的效果很棒,肉眼看不出显著的差异!
想学习更多 AIGC 技术干货?关注公众号立即获取!

本文由 mdnice 多平台发布



















