本文介绍一下在做微博特定话题情感分析中的做法,核心就是判断文本的情感极性,再根据这个极性来进行情感判定。
主要经过了以下几个步骤:
- 文本预处理
- 去乱码、去网络词
- 利用LTP获取分词、句子结构及成分等信息
- 情感信息提取
- 在同义词词林里面找单词编码
- 情感极性判断
- 在情感基准库里面寻找单词极性
- 用VSI 进行调整
- 用VBS分析主题词极性
- 计算句子极性
下面就按照这三部分分别介绍:
文本预处理
文本预处理中主要用了语言技术平台(Language Technology Platform,LTP),它是哈工大社会计算与信息检索研究中心历时十年研制的一整套开放中文自然语言处理系统。 LTP制定了基于XML的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富、高效、高精度的中文自然语言处理模块。主要包含以下9个模块:
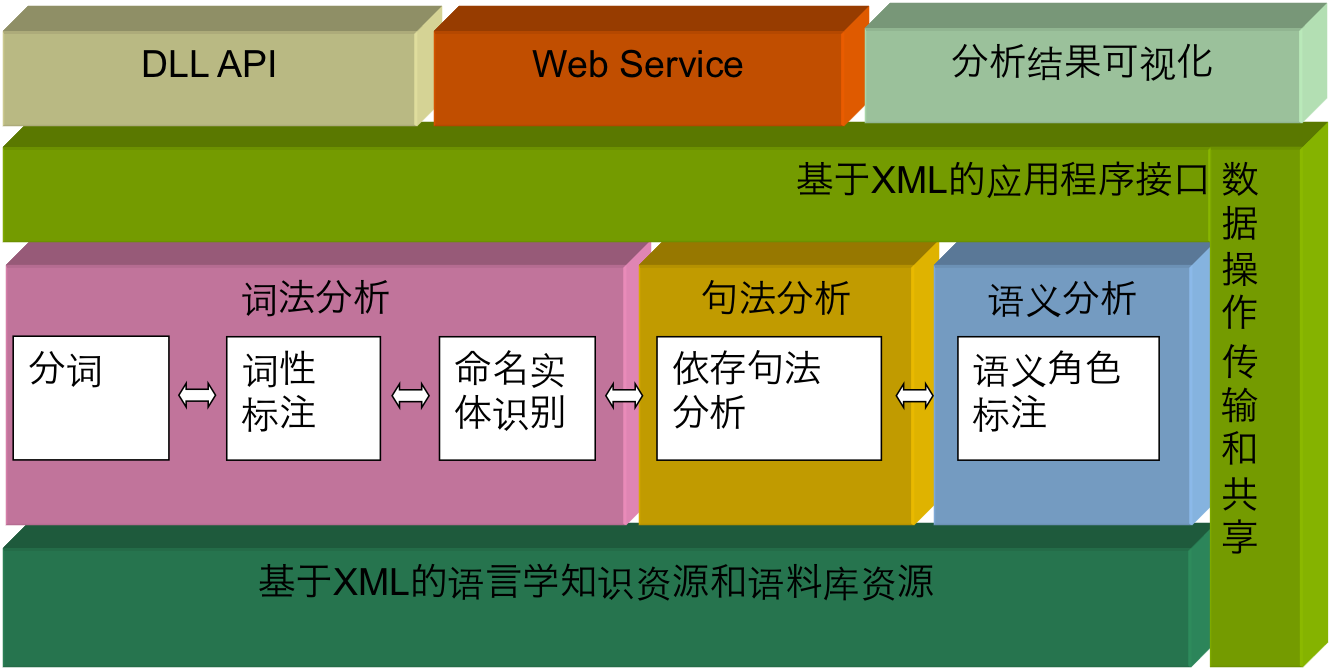
- 分句
- 分词:分词是基于字的序列标注问题,对于输入句子的字序列,模型给句子的每个字标注一个标识词边界的标记。
- 词性标注(Part-of-speech, POS):词性标注是给每个词一个词性类别(名词、动词、形容词等)的任务。
- 命名实体识别(Named Entity Recognition, NER):是在句子的词序列中定位并识别人名、地名、机构名等实体的任务,对于挖掘文本中的实体进而对其进行分类有很重要的意义。采用O-S-B-I-E标注形式。
- 词义消歧
- 依存句法分析(Dependency Parsing, DP):通过分析语言单位各成分之间的依存关系揭示句法结构,就是识别句子的“主谓宾”、“定状补”等语法成分。
- 语义角色标注(Semantic Role Labeling, SRL):标注句子中某些短语为给定谓词的论元。
- 单文档文摘
- 文本分类
- 共指消解
情感信息提取
在这里,由于对于每个词及其他的同义词都有一个编码,这个编码对应着这组词的极性,因此我们先在同义词林里面找这个词对应的组的编码,再根据这个编码在情感词库里面找极性,从而利用词的同义词来辅助判断极性;如果没有编码的话,就给这个词赋极性值为0。
《同义词词林》按照树状的层次结构把所有收录的词条组织到一起,把词汇分成大、中、小三类, 大类有 12 个,中类有 97 个,小类有1,400 个。每个小类里都有很多的词,这些词有根据词义的远近和相关性分成了若干个词群(段落)。每个段落中的词语有进一步分成了若干个行,同一行的词语要么词义相同(有的词义十分接近),要么词义有很强的相关性。
情感极性判断
情感倾向度是指主体对客体表达正面情感或负面情感时的强弱程度,不同的情感程度往往是通过不同的情感词或情感语气等来体现。例如:“敬爱”与“亲爱”都是表达正面情感,同为褒义词。但是“敬爱”远比“亲爱”在表达情感程度上要强烈。通常在情感倾向分析研究中,为了区分两者的程度差别,采取给每个情感词赋予不同的权值来体现。
目前,情感倾向分析的方法主要分为两类:一种是基于情感词典的方法;一种是基于机器学习的方法,如基于大规模语料库的机器学习。前者需要用到标注好的情感词典,英文的词典有很多,中文主要有知网整理的情感词典Hownet和台湾大学整理发布的NTUSD两个情感词典,还有哈工大信息检索研究室开源的《同义词词林》可以用于情感词典的扩充。基于机器学习的方法则需要大量的人工标注的语料作为训练集,通过提取文本特征,构建分类器来实现情感的分类。
在这里,我们用到的是HowNet的情感词库,构建一张情感词表,把编码放在词库里面找,读取相应的极性。
有时,情感描述项会与语句中否定成分结合一起从而形成相反极性的情况,它属于“配价移动指示符(Valence Shifter Indicator, VSI)”。即使VSI不具有极性,他们也能传递对应情感描述项极性总的量值的相反极性。因此,在决定最终极性前,需要用VSI进行极性调整。
对于一条微博来说,我们先发现句子的情感词,通过情感词的倾向和极性,来决定句子的情感,进而决定整个文本的情感。
在依存结构树里面可以发现,如果主干中心词包含有褒贬倾向的词汇时,离中心词越近的修饰结构,对整个句子的情感倾向影响较大,而离其较远的影响较小。因此将依存句法分析中的这种距离定义为依存语法距离,即自顶向上搜索依存树结构,获取具有语义倾向的词汇到主干中心词的距离,相应的有一个影响因子。因此,我们还要利用词语到语句中心词的距离来计算语句的极性。