livandata
数据EDTA创始人,没有之一
现担任数据EDTA个人公众号董事长兼CEO兼财务兼创作人
口号:让大数据赋能每一个人
前言
数据EDTA的读者们,大家好~
国庆将至大家有没有安排出行呢?
有没有翻遍了网站,为出行计划焦头烂额呢?
哈哈
不要着急~
今天,笔者与大家分享,身为一个python技术员是一件多么幸福的事情,因为:假期苦短,要用python~
笔者也是一个经常会为各种规划焦头烂额的人,出行一个礼拜,地点各不相同,一不小心就会多走几公里路,多花几个小时时间,那么,如何才能找到旅游地点之间的最短距离呢?
为了解决出行问题,笔者爬取了携程的热门酒店名称,然后调用高德地图的api,循环遍历找到了各个酒店的经纬度,而后根据酒店位置聚类定位景区的位置,再通过路径优化找到最便捷的出行顺序,如此,旅游可期了~
在这里笔者介绍一下为什么爬取热门酒店的位置?
如果要分析一个景区的热门程度,最好的方法是获取这个地方的人流量,即每个人的坐标以及活动轨迹,但是在平时的操作中,由于人是不停移动的,不仅很难获取对应的位置信息,而且涉及到个人隐私问题,我们无法进行单个人群的路径分析,退而求其次,我们选择分析热门的酒店情况,热门的景区周围总是伴随着大批酒店的,那么,我们可以根据酒店的数量间接的获取热门景区的位置,进而进行景区位置定位。
那么,我们的问题来了:
如何获取携程的酒店信息
笔者仔细分析了携程的网站信息,感谢携程对数据的宽容,携程的反爬手段并没有太严苛:
或许是我们获取数据太少的原因,我们只需要获取到携程某个地区的酒店名称即可,数据量不大,再加上所需字段较少,我们也就轻松的获取到了携程酒店名称。
def post_json_data(url, formdata):time.sleep(1)headers = {'accept': '*/*','accept-encoding': 'gzip, deflate, br','Content-Type': 'application/x-www-form-urlencoded','Cookie': cookie,'User-Agent': ua.get_useragent()}# , proxies = proxydata = requests.post(url, proxies = proxy, data=formdata, headers=headers)# print(data)return data.json()
Python学习qq群:10667510,送全套爬虫学习资料与教程~(国庆给大家一个轻松的阅读,为保证阅读流畅性,尽量减少了代码的数量,如有需要,请关注公众号并回复“国庆节快乐”,完整代码就会出来了~)
酒店名称获取到之后,我们就可以打开高德地图的免费api,循环遍历出每个酒店的经纬度了。
如何获取各个酒店的经纬度
获取各个酒店的经纬度是需要调用高德地图的api接口的,这一过程看似高大上,但是实际操作起来却是异常的简单,此处应该给出一些掌声的,不是给我,而是给马云,开源的数据和工具挽救了多少程序员的头发,真心太感谢了~
使用高德主要有两个步骤:
1)注册高德开发平台,获取到代码需要的key值:
至于如何注册,麻烦各位看官百度一下,此处也算是提供了一个和百度建立战略合作关系的机会:有事不会用百度,有问必答~
笔者对于上图的高端黑没有免疫力,让我先沉醉一会~
…………此处省略5万字赞美…………
注册成功后,我们需要在平台上构建一个应用:
应用构建完成了,对应的key值就产生了~
是不是很简单?
得到key值后,我们就开始获取对应的经纬度了。
2)经纬度的获取:
我们将上文中的酒店名称提取出来,用python逐个遍历,就能得到对应的酒店经纬度:
#!/usr/bin/env python
# _*_ UTF-8 _*_
# author:livan
import requests
import json
def coords(city):
# 输入API问号前固定不变的部分
url = 'https://restapi.amap.com/v3/geocode/geo'
# 将两个参数放入字典
params = {'key': 你的key值,
'address': city}
res = requests.get(url, params)
jd = json.loads(res.text)
return jd['geocodes'][0]['location']
city = '*华'
attr = coords(city)
print(attr)
确定景点位置
上文我们也提到过,景点的位置是通过酒店位置来确定的,细想这一思路有其可取之处:
1)各个景区非常庞大,如果我们按照景区的固有位置推荐,得到的未必便捷,如果我们定位到大山深处,各位游客恐怕要寄刀片了~
2)大家旅游首先会选择落脚的地方,于是笔者推荐距离各个酒店较近的地方,方便游客落脚休息。
那么聚类的代码是什么样子呢:
# k均值聚类
def KMeans(dataSet, k):
m = np.shape(dataSet)[0] # 行的数目
# 第一列存样本属于哪一簇
# 第二列存样本的到簇的中心点的误差.
# np.mat()行列转换。
clusterAssment = np.mat(np.zeros((m, 2)))
clusterChange = True
# 第1步 初始化centroids
centroids = randCent(dataSet, k)
while clusterChange:
clusterChange = False
# 遍历所有的样本(行数)
for i in range(m):
minDist = 100000.0
minIndex = -1
# 遍历所有的质心
# 第2步 找出最近的质心
for j in range(k):
# 计算该样本到质心的欧式距离
print('--------------------------------------')
print(centroids[j, :])
print(dataSet[i, :])
distance = distEclud(centroids[j, :], dataSet[i, :])
if distance < minDist:
minDist = distance
minIndex = j
# 第 3 步:更新每一行样本所属的簇
if clusterAssment[i, 0] != minIndex:
clusterChange = True
clusterAssment[i, :] = minIndex, minDist ** 2
# 第 4 步:更新质心
for j in range(k):
pointsInCluster = dataSet[np.nonzero(clusterAssment[:, 0].A == j)[0]] # 获取簇类所有的点
centroids[j, :] = np.mean(pointsInCluster, axis=0) # 对矩阵的行求均值
print("Congratulations,cluster complete!")
return centroids, clusterAssment
是不是很贴心~
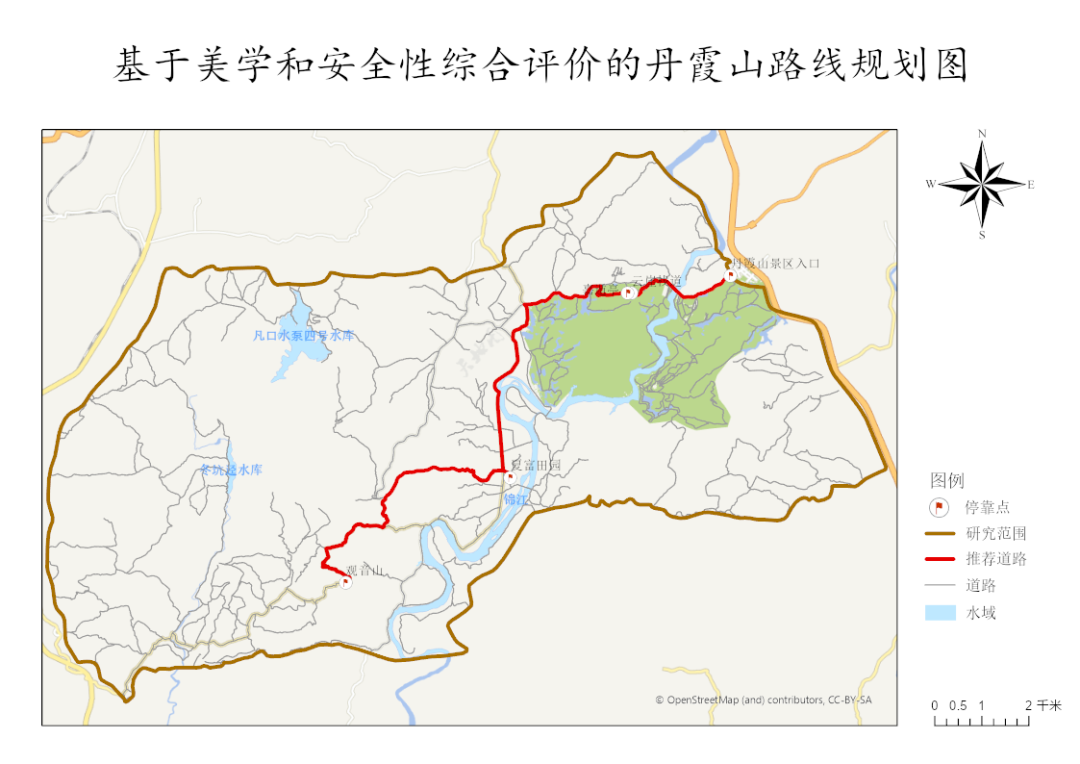
基于上面的思考,我们得到了各个酒店的景区位置图:
哇~
有没有感觉好多色彩~
傻了吧?
都不知道在哪里落脚了~
作为一个资深的数据分析师,笔者自然不能交这样的作业,于是,笔者给出了各个景区的质心点,就是距离各个类别酒店最近的位置:
是不是瞬间清凉了很多,旅游的兴趣瞬间又被拉了回来~
但是,就算是这样的图形,该怎么旅行呢?
依然是没有思路的~
不要着急~且往下看~
确定最短路径
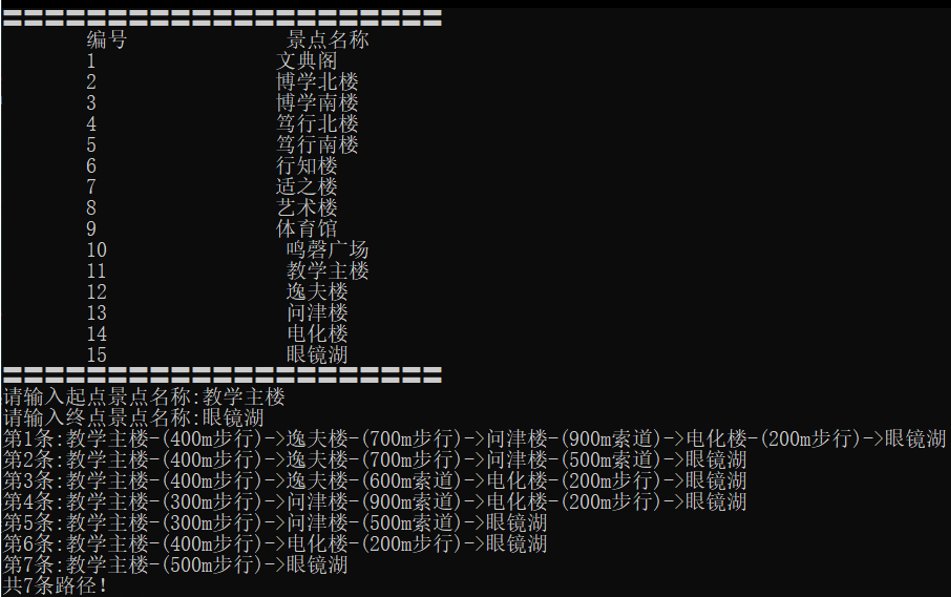
见到了上面的景区位置,那么,如何确定哪条路线是最短路线呢?
笔者的思路是这样的:
1)先确定起始点,并计算起始点距离其他各个点的距离;
2)找到距离起始点最近的点,连接两个点,并将最近的点作为新的起始点;
3)过滤掉旧的起始点,然后用新的起始点在重新计算各个点之间的距离,并连接距离最近的两个点;
4)循环计算,直到所有点都连在了一起;
经过上面的运算,是不是对于出行计划有感觉了呢?
我们看一下图形:
天啊~
这不是北斗七星吗?
错~
这是出行路线~
图形虽简洁,但是基本的出行计划已经勾勒出来了,是不是很简单呢?
后续
如果你认为这是路程规划的全部,那遗憾的告诉你,你把问题想简单了,本文选择的算法是常用的:k-meaning聚类和欧氏距离路径优化,这两个算法在思路讲解方面有其独到之处,但是在实践中却是需要更多的条件。
各个领域路径优化的案例算法也非常成熟,比如:邮局选择、物流最优路径等,如果大家有兴趣,欢迎大家关注沟通~
实例分享
技术是需要沟通的,笔者也是一个喜欢交朋友的程序猿,欢迎大家 关注 公众号: livandata,沟通路径优化的常用算法。
如果大家需要上面案例的源码,请关注公众号,回复“国庆节快乐”即可。
代码为原创,仅供学习交流,请勿用于商业应用,谢谢大家~