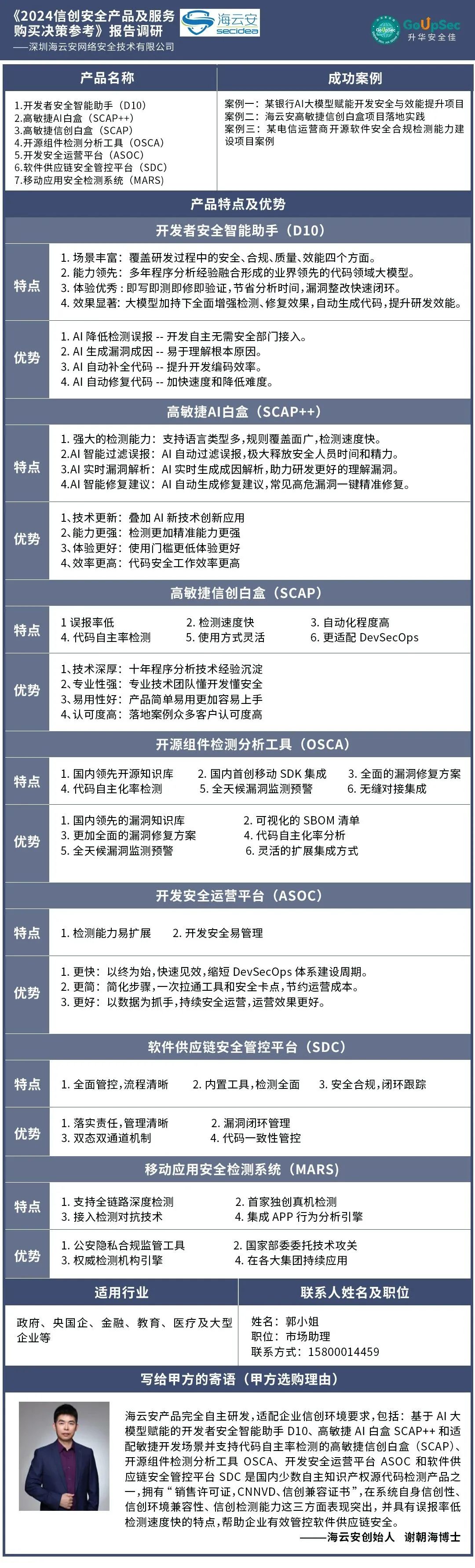
概述
在现代 Web 开发中,响应式设计至关重要,尤其是在处理复杂的布局和数据表格时。表格通常会受到多种因素的影响,如分页、合计行或动态内容,这可能导致表格高度的变化。本文将介绍一个基于 Vue.js 的方法 setMaxHeight,该方法动态计算和设置表格的最大高度,确保表格始终能在可视区域内显示,而不受其它元素的干扰。
目标
- 通过计算可用空间并自动调整表格高度,确保表格显示在合适的区域内。
- 动态处理不同布局和页面元素的高度变化,如分页、合计行等。
- 提供可维护、可扩展的解决方案,适应不同表格组件库(如
el-table和ivu-table)的要求。
代码分析
export default {data() {return {maxHeight: 0, // 表格最大高度};},methods: {/*** 动态计算表格最大高度* 1. 根据容器的总高度减去非表格元素的高度来计算表格的最大高度* 2. 支持分页、合计行等因素的动态变化* * @param {HTMLElement} e - 表格容器元素*/setMaxHeight(e) {if (!e) return; // 如果未传入容器元素,直接返回// 过滤掉表格本身(ivu-table-wrapper、el-table)以及v-resize生成的object节点const otherEle = Array.from(e.children).filter(item => !item.classList.contains('ivu-table-wrapper') && !item.classList.contains('el-table') && item.nodeName !== 'OBJECT');// 计算过滤后的其它元素的高度之和const otherHeight = otherEle.reduce((sum, item) => sum + item.clientHeight, 0);// 判断表格是否包含合计行const hasSummary = Array.from(e.children)[0].classList.contains('ivu-table-with-summary');// 计算表格最大高度this.maxHeight = e.clientHeight - otherHeight - (hasSummary ? 36 : 0);},},
};
代码逻辑
-
初始化数据: 在 Vue 组件的
data中,定义一个maxHeight属性来存储计算得到的最大表格高度。 -
setMaxHeight方法:- 参数说明:方法接受一个 DOM 元素
e,该元素通常是包含表格及其他子元素的容器。 - 判断空值:首先检查是否传入有效的容器元素
e,如果为空,直接返回。
- 参数说明:方法接受一个 DOM 元素
-
过滤非表格节点:
- 使用
Array.from将e.children转化为数组,并通过filter方法排除掉类名为ivu-table-wrapper或el-table的子元素,以及OBJECT类型的节点(可能是由v-resize或其他插件生成的用于调整大小的元素)。
- 使用
-
计算其它元素的总高度:
- 通过
reduce方法遍历所有非表格元素,并累加它们的clientHeight,即元素的可视高度。
- 通过
-
检查是否包含合计行:
- 检查表格容器的第一个子元素是否包含
ivu-table-with-summary类名来判断是否显示合计行。如果存在合计行,额外减去 36px。
- 检查表格容器的第一个子元素是否包含
-
计算最大高度:
- 最终,通过减去非表格元素的总高度以及合计行的高度(如果有的话),计算出表格的最大高度
maxHeight,并将其赋值给组件的数据属性maxHeight。
- 最终,通过减去非表格元素的总高度以及合计行的高度(如果有的话),计算出表格的最大高度
使用场景
此方法适用于需要动态调整表格高度的场景,尤其是在以下情况下:
- 页面布局中包含分页元素,且分页高度可能会动态变化。
- 表格中可能包含合计行或其他特殊行,需要在计算表格高度时考虑其额外占用的空间。
- 表格容器的高度是固定的,但内部内容可能会随时间或用户交互而变化,导致表格需要重新调整高度。
示例
假设你在 Vue 组件中使用了 el-table 或 ivu-table,并希望根据容器的高度动态设置表格的最大高度:
<template><div class="table-container" ref="tableContainer" @resize="setMaxHeight($refs.tableContainer)"><el-table :data="tableData" :max-height="maxHeight"><!-- 表格内容 --></el-table></div>
</template><script>
import { ref, onMounted } from 'vue';export default {setup() {const tableData = ref([]);const maxHeight = ref(0);onMounted(() => {// 在组件挂载完成后,初始化最大高度this.setMaxHeight(this.$refs.tableContainer);});return {tableData,maxHeight,setMaxHeight,};},
};
</script>
性能优化
-
减少不必要的 DOM 操作:
- 在每次页面大小或布局变化时调用
setMaxHeight方法时,确保只进行必要的 DOM 查询和计算。可以考虑节流(throttle)或防抖(debounce)技术,避免频繁执行。
- 在每次页面大小或布局变化时调用
-
缓存结果:
- 如果表格容器的大小变化不频繁,可以考虑缓存计算结果,避免重复计算。
总结
setMaxHeight 方法是一个实用的解决方案,帮助开发者动态调整表格的最大高度,确保表格在各种布局下都能自适应地显示。通过过滤非表格节点、计算其它元素的高度并考虑合计行的影响,能够灵活地处理复杂的布局和交互场景。
![[STM32 HAL库]串口空闲中断+DMA接收不定长数据](https://i-blog.csdnimg.cn/direct/854841aebeb042c8b0cb2ae16f53ad8b.png#pic_center)