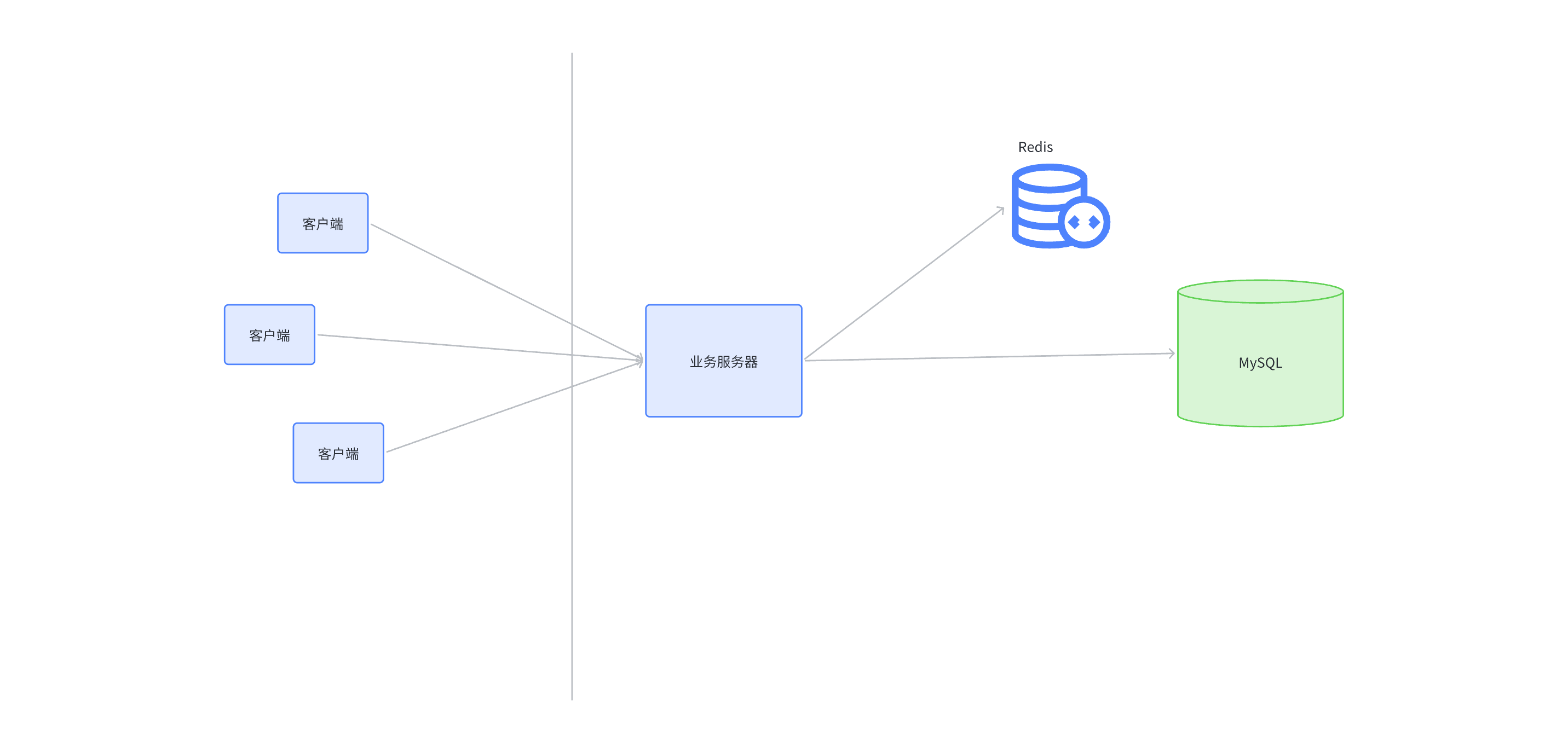
导航:
【Java笔记+踩坑汇总】Java基础+JavaWeb+SSM+SpringBoot+SpringCloud+瑞吉外卖/谷粒商城/学成在线+设计模式+面试题汇总+性能调优/架构设计+源码解析
推荐视频:
黑马程序员全套Java教程_哔哩哔哩
尚硅谷Java入门视频教程_哔哩哔哩
推荐书籍:
《Java编程思想 (第4版)》
《Java核心技术·卷I(原书第12版) : 开发基础》
目录
六、异常
6.1 基本介绍
6.2 详细介绍
6.2.1 Throwable类
6.2.2 知识加油站
6.2.2.1 异常的追踪栈
6.2.2.2 日志规范:不建议使用e.printStackTrace()
6.2.3 Error类
6.2.4 Exception类
6.3 异常的两种处理方式
6.3.1 抛出异常
6.3.2 捕获异常(推荐)
6.4 自定义异常:继承异常类
七、集合
7.1 集合体系
7.1.1 集合和映射
7.1.2 思考:Map是不是集合?
7.1.3 常见集合的底层和性能对比
7.1.4 知识加油站:
7.1.4.1 集合的线程安全性
7.1.4.2 思考:什么是线程不安全?
7.1.2 常用API
7.1.2.1 Collection:
7.1.2.2 Map
7.1.3 常用工具类
7.1.3.1 集合工具类Collections
7.1.3.2 数组工具类Arrays
7.2 ArrayList
7.2.1 基本介绍
7.2.2 底层源码和扩容机制
7.2.3 线程不安全问题和解决方案
7.2.4 六种遍历方法
7.2.4.1. 常规 for 循环
7.2.4.2. 增强 for 循环(只遍历不修改)
7.2.4.3. 迭代器 Iterator(遍历并修改)
7.2.4.4. 迭代器 ListIterator (双向遍历并修改)
7.2.4.5. forEach + Lambda 表达式(只遍历不修改)
7.2.4.6. Stream API 遍历(推荐,并发遍历并修改)
7.2.4.7 小结:六种遍历方法的适用场景
7.3 List接口
7.3.1 主要实现类
7.3.2 特点
7.3.3 常用方法
7.3.4 代码示例
7.3.5 面向接口编程
7.4 LinkedList
7.4.1 基本介绍
7.4.2 ArrayList和LinkedList的区别
7.5 Hashset
7.5.1 基本介绍
7.5.2 去重原理:hashCode值
7.5.3 知识加油站
7.5.3.1 equals()和hashcode()的关系
7.5.3.2 ==与equals()的区别
7.6 HashMap
7.6.1 基本介绍
7.6.2 HashMap和HashSet区别
7.6.3 知识加油站:HashMap的底层原理
7.6.3.1 线程不安全
7.6.3.2 底层数据结构
7.6.3.3 扩容机制
7.6.3.4 put()流程
7.6.3.5 HashMap容量为什么是2的n次方?
7.6.3.6 JDK7扩容时死循环问题
7.6.3.7 JDK8 put时数据覆盖问题:
7.6.3.8 modCount非原子性自增问题
7.7 TreeSet
7.7.1 基本介绍
7.7.2 HashSet和TreeSet的区别
八、泛型
8.1 基本介绍
8.2 格式
8.2.1 泛型参数类型
8.2.2 泛型类
8.2.3 泛型接口
8.2.4 泛型方法
8.3 类型通配符
8.4 可变参数
8.5 知识加油站
8.5.1 泛型的向上转型
8.5.2 泛型擦除
九、JDK8新特性
9.1 基本介绍
9.2 Lambda表达式
9.3 Stream流
9.3.1 基本介绍
9.3.2 生成
9.3.3 中间操作
9.3.4 终结和收集
9.3 函数式接口
9.3.1 基本介绍
9.3.2 生产者接口Supplier
9.3.3 函数式接口Consumer
9.3.4 函数式接口Predicate
9.4 方法引用
9.4.1 概念
9.4.2 引用实例方法
9.4.4 引用构造器
9.5 接口组成更新
9.5.1 接口默认方法
9.5.2 接口静态方法
9.5.3 知识加油站:JDK9接口私有方法
十、I/O流
10.1 基本介绍
10.2 File类
10.3 字节流的超类
10.3.1 字节输出流OutputStream
10.3.2 字节输入流InputStream
10.4 字节文件流
10.4.1 文件输出流FileOutputStream
10.4.2 文件输入流 FileInputStream
10.5 字节缓冲流(推荐)
10.5.1 字节缓冲输出流BufferedOutputStream
10.5.2 字节缓冲输入流BufferedInputStream
10.6 字符流
10.6.1 继承关系
10.6.2 字符流的编码和解码
10.6.3 字符输入输出流
10.6.3.1 字符输出流OutputStreamWriter
10.6.3.2 字符输入流InputStreamReader
10.6.4 FileWriter和FileReader:简化字符流
10.6.5 字符缓冲流(推荐)
10.7 知识加油站:I/O流JDK7异常处理
10.8 特殊操作流
10.8.1 标准输入输出流:System.in和System.out
10.8.1.1 标准输出流
基本介绍
常用格式化符号
10.8.1.2 标准输入流
基本介绍
Scanner类
10.8.2 打印流
10.8.2.1 字节打印流:PrintStream
10.8.2.2 字符打印流:PrintWriter
10.8.3 序列号流和反序列化流
10.8.3.1 Serializable 接口和serialVersionUID变量
10.8.3.2 对象序列化流:ObjectOutputStream
10.8.3.3 对象反序列化流:ObjectInputStream
六、异常
6.1 基本介绍
什么是异常?
在Java中,异常(Exception)是指在程序执行过程中出现问题的一种情况,它可以中断程序的正常执行。
异常通常是指由于错误、非法操作或意外情况导致的问题,比如文件未找到、数组越界、空指针引用等等。
异常的分类:
-
Error:错误类,无法通过代码解决,所以也不能处理。通常是由于系统资源不足或者JVM内部错误等导致的,需要通过修改环境或者配置等方式来解决。例如系统内存不够时抛出的内存溢出错误OutOfMemoryError,递归栈太深时抛出栈溢出错误StackOverflowError,这些通过代码没法解决,需要提升服务器配置,或者完全重构代码,换一种时间、空间复杂度更低的方案。

-
Exception:异常类,程序可以处理的问题。它是一个类的实例,用于表示程序在运行过程中出现的意外情况。Java中所有的异常都是Throwable类的子类。Exception分为两种主要类型:运行时异常(RuntimeException及其子类)和非运行时异常。当一段代码有异常风险时应该通过try-catch或者throws进行处理,防止程序出现问题。例如往数据库插入记录时要捕获并打日志,从而对违反主键约束之类等问题进行排查。

-
RuntimeException:运行时异常,编译不出错,运行出错,要try-catch处理。这类异常通常是由程序错误或者逻辑错误导致的,例如空指针引用、数组越界等。由于RuntimeException在编译时不受检查,所以需要在代码编写阶段考虑如何处理这类异常,以确保程序的健壮性。

-
非RuntimeException:编译时异常,编译时出错使程序不能运行,要try-catch处理或者throws抛出去。它是在编译时必须处理的异常类型,否则程序无法通过编译。这类异常通常表示程序运行环境出现的异常情况,例如IO异常IOException、数据库操作异常等。
-
异常继承体系 :

异常:

6.2 详细介绍
6.2.1 Throwable类
Throwable:
Throwable 是所有异常和错误(Exception 和 Error)的基类。也就是说,所有的异常、错误都是Throwable类的子类。

Throwable译为可抛出的。
Throwable类实现了Serializable,定义了serialVersionUID成员变量,这个接口和变量是用于序列化的,具体在后文的I/O流那块会详细讲。
Throwable 最重要的三个方法:
-
getMessage():返回此 throwable 的详细信息字符串。
-
printStackTrace():控制台打印异常跟踪栈详细信息。它包含 throwable 的类名、消息,以及每个方法的调用序列。
-
toString():返回此 Throwable 的简短描述。
程序运行出错,JVM会将异常的名称、原因、位置输出到控制台,并让程序停止运行。
6.2.2 知识加油站
6.2.2.1 异常的追踪栈
程序出现异常后会打印异常的跟踪栈信息,根据跟踪栈信息我们可以找到异常的位置,并跟踪异常一路向上层方法传播的过程。
异常传播的顺序与方法的调用顺序相反,是从发生异常的方法开始,不断向调用它的上层方法传播,最终传到main方法。若依然没有得到处理,则JVM终止程序,打印异常跟踪栈的信息。
代码示例:主方法调用a方法,a方法调用b方法,b方法抛出异常,运行后将在控制台打印异常调用栈:b方法->a方法->main方法,和方法调用顺序正好相反。
/*** @Author: vincewm* @CreateTime: 2024/05/20* @Description: 测试类* @Version: 1.0*/
public class Demo {/*** aFun方法调用bFun方法*/public static void aFun() {bFun();}/*** bFun方法一定会抛出异常*/public static void bFun(){throw new RuntimeException("这里一定会抛出一个运行时异常");}public static void main(String[] args) {// main方法调用aFun方法aFun();}
}
6.2.2.2 日志规范:不建议使用e.printStackTrace()
在catch块中,不建议用e.printStackTrace(),建议改成log.error("你的程序有异常啦",e);
e.printStackTrace()缺点:
- 日志混乱:e.printStackTrace()打印出的堆栈日志跟业务代码日志是交错混合在一起的,通常排查异常日志不太方便。
- 性能问题:printStackTrace()方法会生成大量的字符串对象,对系统性能有一定的影响。
代码示例:捕获空指针异常并打印错误日志
/*** @Author: vincewm* @CreateTime: 2024/05/20* @Description: 测试类* @Version: 1.0*/
public class Demo {/*** 获取 Logger 实例*/private static final Logger logger = Logger.getLogger(Demo.class.getName());public static void main(String[] args) {try {// 可能会引发空指针异常的代码String str = null;System.out.println(str.length());} catch (NullPointerException e) {// 异常处理代码,使用 log.error 记录异常信息logger.log(Level.SEVERE, "发生空指针异常", e);// 不建议使用System.out.println,因为它无法看出是哪个类的日志// System.out.println("发生空指针异常");// 不建议使用e.printStackTrace(),因为它会打印到控制台,不符合日志规范// e.printStackTrace();} finally {// 无论是否发生异常都会执行的代码System.out.println("这一行一定会执行");}}
}可以看到错误发生的时间、类的全路径名、方法名、具体的异常名、异常错误帧信息、出问题的具体行数,在生产环境将可以更快的排查出问题:

6.2.3 Error类
Java中的Error类表示严重的错误情况,通常由虚拟机或其他底层自身的失效造成的,例如内存溢出、栈溢出,会导致应用程序终止。
通常程序不应该捕获Error,特定情境下可以捕获OutOfMemoryError处理内存溢出问题。使用try-catch-finally块捕获异常,并在finally块中进行资源清理、销毁、报告错误、终止应用程序等操作。
常见的错误包括:
- OutOfMemoryError:内存溢出错误,通常是由于应用程序试图分配比可用内存更多的内存而导致。
- StackOverflowError:堆栈溢出错误,发生在方法递归调用所需的堆栈空间已经用完的情况下。
- NoClassDefFoundError:类未找到错误,通常是由于JVM无法找到应用程序尝试使用的某个类而导致。
- UnsatisfiedLinkError:链接未满足错误,通常是由于调用本地方法时出现的链接问题而导致。
模拟栈溢出错误:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/public class Test {/*** 逆序打印正整数* @param i*/public static void printNumber(int i){if(i==0){return;}// 下面错误的把i-1,写成i,会导致无限递归// printNumber(i-1);printNumber(i);}public static void main(String[] args) {// 打印100,99...,1printNumber(100);} }

6.2.4 Exception类
Exception的子类包括编译时异常和运行时异常:
-
编译时异常:在编译阶段就能检查出来的异常。例如FileNotFoundException、ClassNotFoundException、NoSuchFieldException、NoSuchMethodException、SQLException、ParseException(解析异常)等。如果程序要去处理这些异常,必须显式地使用try-catch语句块或者在方法定义中使用throws子句声明异常。
-
运行时异常:在运行时才会出现的异常。例如,NullPointerException、ArrayIndexOutOfBoundsException等。这些异常通常是由程序代码中的逻辑错误引起的,在编程时不会提示,运行时才报错。 因此,在编写程序时,通常无法处理这些异常,但是在程序开发完毕后,需要对这些异常进行一些处理,以防程序运行时崩溃。
- NullPointerException 空指针异常;出现原因:访问未初始化的对象或不存在的对象。
- ClassNotFoundException 类找不到异常;出现原因:类的名称和路径加载错误;
- NumberFormatException 数字格式化异常;出现原因:转数字的字符型中包含非数字型字符。
- IndexOutOfBoundsException 索引超出边界异常;出现原因:访问数组越界元素
- IllegalArgumentException 不合法参数异常。出现原因:传递了不合法参数
- MethodArgumentNotValidException 方法参数无效异常。出现原因:JSR303校验不通过
- ClassCastException 类转换异常。出现原因:把对象强制转为没继承关系对象时报错。这个异常是在类加载过程的元数据验证阶段验证继承关系时报错。
- ArithmeticException 算术异常。出现原因:除以0时。
6.3 异常的两种处理方式
6.3.1 抛出异常
抛出异常的方式:
- throws:
- 位置:在方法签名中使用,其后跟着异常类名。
- 特点:它表示方法可能会抛出异常,但并不保证一定会发生这个异常。
- 数量:可以声明抛出多个异常,多个一场之间用逗号隔开
- 处理异常:异常会传递给该方法的调用者来处理。
- throw:
- 位置:在方法体内使用,其后跟着异常对象名。
- 特点:它表示方法内部一定已经发生了某种异常情况,并将这个异常抛出。
- 数量:throw语句抛出的是一个异常实例,不是一个异常类,而且每次只能抛出一个异常实例
- 处理异常:执行该关键字必定会抛出异常。异常由方法体内的语句来处理。
代码示例:
/*** @Author: vincewm* @CreateTime: 2024/05/20* @Description: 测试类* @Version: 1.0*/ public class Demo {/*** throws可能会抛出异常* @throws Exception 抛出异常*/public void possibleException() throws Exception {// 可能会引发空指针异常的代码}/*** throw一定会抛出指定的异常*/public void throwException(){throw new RuntimeException("这里一定会抛出一个运行时异常");} }
6.3.2 捕获异常(推荐)
使用 try 和 catch 关键字可以捕获异常,需要将try/catch 包围在异常可能发生的地方。
try/catch语法:
try{// 可能会引发空指针异常的代码
}catch(Exception e){// 异常处理代码
}try/catch/finally语法:
try{// 可能会引发空指针异常的代码
}catch(Exception e){// 异常处理代码
}finally{ // 只要程序不崩溃,不管catch里有没有捕获到异常,finally块中的代码都会在最后执行
}finally块最终执行:
- 只要程序不崩溃,finally块的代码都最终执行:即使try块、catch块中有return或throw语句,程序也会在执行finally块的代码后再return或throw。这里需要注意,禁止在finally块中使用return或throw。因为如果finally块里也使用了return或throw等语句,finally块会终止方法,系统将不会跳回去执行try块、catch块里的任何代码。这将会导致try块、catch块中的return、throw语句失效
- 如果程序终止,finally代码块不执行:
- 线程终止:如果一个线程在执行 try 语句块或者catch语句块时被打断interrupted,或者被终止killed,与其相对应的 finally 语句块可能不会执行。
- 退出虚拟机:如果在try块或catch块中使用 `System.exit(1);` 来退出虚拟机,则finally块将失去执行的机会。
代码示例:捕获数组越界异常
public static void main(String[] args) throws ParseException {// 测试数组越界异常int[] arr = {1, 2, 3};try {// 访问越界的数组元素System.out.println(arr[10]);// 捕获数组越界异常} catch (ArrayIndexOutOfBoundsException e) {System.out.println("捕获数组下标越界异常"+e);}System.out.println("异常被捕获、处理后,程序将不再被终止,而是继续执行");}运行结果:

6.4 自定义异常:继承异常类
在一些业务场景中,预定义的异常类并不能完全满足我们的需求,这时我们就需要自定义异常,以便于在程序出现问题时,可以及时抛出或处理。
例如电商项目的库存不足异常、商品找不到异常,论坛项目中的“帖子找不到异常”、“无效评论异常”等等。
自定义异常的方法: 可以通过继承异常根类,或者它们的子类,重写父类的方法,以达到自定义异常的效果:
- 编译时异常类:需要继承 Exception 类。
- 运行时异常类:需要继承 RuntimeException 类。
代码示例:
自定义分数异常类,如果学生成绩小于0分或大于100分,则抛出此异常。
1.定义分数异常类:
/*** @Author: vincewm* @CreateTime: 2024/05/20* @Description: 自定义异常类* @Version: 1.0*/ public class ScoreException extends Exception {public ScoreException(String wrongScore) {//带参构造,异常时控制台输出指定字符串super(wrongScore);} }2.定义学生类,其中有个方法判断分数是否合格
/*** @Author: vincewm* @CreateTime: 2024/05/20* @Description: 学生类* @Version: 1.0*/ public class Student {/*** 检查分数是否合法* @param score 分数* @throws ScoreException:要加throws,声明此方法会抛出异常*/public void checkScore(int score) throws ScoreException{System.out.println("开始检查分数");if(score>100||score<0){throw new ScoreException("分数"+score+"不合法");}else {System.out.println("分数正常");}} }3.测试类:传参分数,校验是否合法:
/*** @Author: vincewm* @CreateTime: 2024/05/20* @Description:* @Version: 1.0*/ public class Demo {public static void main(String[] args) {Student s=new Student();try{s.checkScore(111);}catch (ScoreException e){e.printStackTrace();}System.out.println("这里也能输出");} }运行结果:

七、集合
7.1 集合体系
7.1.1 集合和映射
在Java中,集合是一组用于操作和存储数据的接口和类。 它主要包括Collection和Map两种。
- 集合(Collection):一组单独的元素。它通常应用了某种规则,例如 List(列表)必须按特定的顺序容纳元素,而一个Set(集)不可包含任何重复的元素。
- 映射(Map):一系列“键-值”对的集合。它的存储内容是一系列键值对,如果知道了键(key),我们可以直接获取到这个键所对应的值(value),时间复杂度是O(1)。散列表是Map的一种较为普遍的展现。

Java中的集合类分为4大类,分别由4个接口来代表,它们是Set、List、Queue、Map。其中,Set、List、Queue接口都继承自Collection接口,Map接口不继承自其他接口。
Set代表无序的、元素不可重复的集合。
List代表有序的、元素可以重复的集合。有序说的是元素顺序直接由插入顺序决定。
Queue代表先进先出(FIFO)的队列。
Map代表具有映射关系(key-value)的集合。
Java提供了众多集合的实现类,它们都是这些接口的直接或间接的实现类,其中比较常用的有:HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap等。
7.1.2 思考:Map是不是集合?
对于集合一直有个争议,一些人认为集合是个狭窄的概念,只包括Collection接口下的实现类,毕竟Collection就译为“集合”。因为Map不是Collection接口的实现类,所以Map不属于集合。
另一些人认为,集合是个广泛的概念,这些存储各种数据、对象及其关系的容器都称为集合。所以Map和Collection统称为集合。
事实上,两种说法都可以说是对的,区别仅仅在于“集合”这个概念的理解区别、广义和狭义。
《Java编程思想》原文:
Java 实用类库还提供了一套相当完整的容器类来解决这个问题,其中基本的类型是List、
Set、Queue和Map。这些对象类型也称为集合类,但由于Java的类库中使用了Collection这个名字来指代该类库的一个特殊子集,所以我使用了范围更广的术语“容器”称呼它们。容器提供了完善的方法来保存对象,你可以使用这些工具来解决数量惊人的问题。
7.1.3 常见集合的底层和性能对比
- ArrayList:
- 使用场景:频繁查询但不经常增删元素
- 底层:数组 。允许存储多个null值。
- 性能:查询(get、contains)操作时间复杂度为O(1),添加(add)和删除(remove)元素时,可能需要移动数组中的元素,导致时间复杂度为O(n)。
- LinkedList:
- 使用场景:频繁增删元素但不经常查询
- 底层:链表 。允许存储多个null值。
- 性能: 查询很慢(需要从头(或尾)遍历链表,查询操作时间复杂度为O(n) ),增删很快(只需调整链表的指针,插入(add)和删除(remove)操作时间复杂度为O(1))。
- Stack:
- 使用场景:需要后进先出(LIFO)访问顺序的数据结构,例如递归、回溯算法等。线程安全,因为它是Vector的实现类
- 底层:数组(因为它是Vector的实现类)。允许存储多个 null 值。
- 性能: 增删改查都是在栈顶操作,所以时间复杂度都是O(1)
-
常用方法:
- push(E item):将元素压入栈顶
- pop():移除并返回栈顶元素
- peek():返回栈顶元素但不移除
- isEmpty():检查栈是否为空
- search(Object o):返回元素在栈中的位置,以 1 为基准
- HashSet:
- 使用场景:需要高效去重、快速查找、不考虑内存浪费的场景
- 底层:哈希表(快速查找)和Set(去重)。它自动对元素进行去重(通过 hashCode 和 equals 方法),并且无序(存入后顺序会乱),允许存储一个null值。
- 性能:底层是哈希表,所以插入、删除和查找操作的时间复杂度都是O(1),代价是浪费一些空间。
- TreeSet:
- 使用场景:适用于多读少写、排序的场景。
- 底层:红黑树(快速查找、排序)和Set(去重)。不允许存储null值
- 性能:插入、删除、查找操作的时间复杂度为O(log n),因为操作需要维护树的平衡,所以适用于多读少写的场景。
- HashMap:
- 使用场景:适用于多读少写、需要快速读的场景。
- 底层:哈希表(快速查找)和Map(键值对)。可以存储一个null键(key)和多个null值(value)。
- 性能:底层是哈希表,所以插入、删除和查找操作的时间复杂度都是O(1),代价是浪费一些空间。
红黑树: 近似平衡二叉树,左右子树高差有可能大于 1,查找效率略低于平衡二叉树,但增删效率高于平衡二叉树,适合频繁插入删除。
- 结点非黑即红;
- 根结点是黑色,叶节点是黑色空节点(常省略);
- 任何相邻节点不能同时为红色;
- 从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点;
- 查询性能稳定O(logN),高度最高2log(n+1);
7.1.4 知识加油站:
7.1.4.1 集合的线程安全性
线程不安全的集合:
Java提供了众多集合的实现类,它们都是这些接口的直接或间接的实现类,其中比较常用的有:HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap等。这些集合都是线程不安全的。
线程安全的集合:
- Collections工具类:Collections工具类的synchronizedXxx()方法,将ArrayList等集合类包装成线程安全的集合类。例如
List list = Collections.synchronizedList(new ArrayList()); - 古老api:java.util包下性能差的古老api,如Vector、Hashtable,它们在JDK1就出现了,不推荐使用,因为线程安全的方案不成熟,性能差。
- 降低锁粒度的并发容器(推荐):JUC包下Concurrent开头的、以降低锁粒度来提高并发性能的容器,如ConcurrentHashMap。适用于读写操作都很频繁的场景。
- 复制技术实现的并发容器:JUC包下以CopyOnWrite开头的、采用写时写入时复制技术实现的并发容器,如CopyOnWriteArrayList。写操作时,先将当前数组进行一次复制,对复制后的数组进行操作,操作完成后再将原来的数组引用指向复制后的数组。避免了并发修改同一数组的线程安全问题。适用于读操作比写操作频繁且数据量不大的场景。适用于读操作远多于写操作的场景。
7.1.4.2 思考:什么是线程不安全?
线程不安全是指在多线程环境下,当多个线程并发地访问和修改共享数据时,由于缺乏适当的同步机制,可能导致数据的不一致、错误或者程序行为不可预测的现象。
以HashMap为例:
在JDK8中,HashMap底层是采用“数组+单向链表+红黑树”来实现的。数组用作哈希查找,链表用作链地址法处理冲突,红黑树替换长度为8的链表。
JDK7扩容时死循环问题:
单线程扩容流程:JDK7中,HashMap链地址法处理冲突时采用头插法,在扩容时依然头插法,所以链表里结点顺序会反过来。
假如有T1、T2两个线程同时对某链表扩容,他们都标记头结点和第二个结点,此时T2阻塞,T1执行完扩容后链表结点顺序反过来,此时T2恢复运行再进行翻转就会产生环形链表,即B.next=A; A.next=B,从而死循环。

JDK8 尾插法:JDK8中,HashMap采用尾插法,扩容时链表节点位置不会翻转,解决了扩容死循环问题,但是性能差了一点,因为要遍历链表再查到尾部。
JDK8 put时数据覆盖问题:
HashMap非线程安全,如果两个并发线程插入的数据hash取余后相等,就可能出现数据覆盖。
线程A刚找到链表null位置准备插入时就阻塞了,然后线程B找到这个null位置插入成功。借着线程A恢复,因为已经判过null,所以直接覆盖插入这个位置,把线程B插入的数据覆盖了。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有 hash 碰撞,则直接插入tab[i] = newNode(hash, key, value, null);}
线程安全解决方案:
- 使用Hashtable(古老api不推荐)
- 使用Collections工具类,将HashMap包装成线程安全的HashMap。
Collections.synchronizedMap(map); - 使用更安全的ConcurrentHashMap(推荐),ConcurrentHashMap通过对槽(链表头结点)加锁,以较小的性能来保证线程安全。
- 使用synchronized或Lock加锁HashMap之后,再进行操作,相当于多线程排队执行(比较麻烦,也不建议使用)。
7.1.2 常用API
7.1.2.1 Collection:
- add():向集合中添加一个元素。
- 获取元素:没有直接提供获取指定位置元素的方法,因为它的实现类元素不一定有序。若需访问,需要通过迭代器iterator()
- remove():从集合中移除一个指定的元素。
- contains(Object o): 检查集合中是否包含指定元素。
- size(): 返回集合中的元素数量。
- isEmpty(): 检查集合是否为空。
- clear(): 移除集合中的所有元素。
代码示例:
/*** @Author: vince* @CreateTime: 2024/05/13* @Description: 测试类* @Version: 1.0*/
public class Test {public static void main(String[] args) {// 创建一个集合Collection<String> collection = new ArrayList<>();// 使用 add() 方法向集合中添加元素collection.add("苹果");collection.add("香蕉");collection.add("樱桃");System.out.println("添加元素后: " + collection);// 遍历集合System.out.println("开始遍历集合...");Iterator<String> iterator = collection.iterator();while (iterator.hasNext()) {String element = iterator.next();System.out.println(element);}System.out.println("遍历集合完毕...");// 使用 contains() 方法检查集合中是否包含指定元素boolean containsBanana = collection.contains("香蕉");System.out.println("包含 '香蕉': " + containsBanana);// 使用 size() 方法返回集合中的元素数量int size = collection.size();System.out.println("集合的大小: " + size);// 使用 isEmpty() 方法检查集合是否为空boolean isEmpty = collection.isEmpty();System.out.println("集合是否为空: " + isEmpty);// 使用 remove() 方法从集合中移除一个指定的元素collection.remove("香蕉");System.out.println("移除 '香蕉' 后: " + collection);// 再次使用 size() 方法返回集合中的元素数量size = collection.size();System.out.println("移除后集合的大小: " + size);// 使用 clear() 方法移除集合中的所有元素collection.clear();System.out.println("清空集合后: " + collection);// 使用 isEmpty() 方法检查集合是否为空isEmpty = collection.isEmpty();System.out.println("清空后集合是否为空: " + isEmpty);}
}
7.1.2.2 Map
- put():向映射中添加一个键值对。如果键已经存在,则更新其对应的值。
- get():根据键获取对应的值。
- remove(Object key): 根据键移除键值对。
- containsKey(Object key): 检查是否包含指定键。
- containsValue(Object value): 检查是否包含指定值。
- size(): 返回映射中的键值对数量。
- isEmpty(): 检查映射是否为空。
- clear(): 移除映射中的所有键值对。
代码示例:
public class Test {public static void main(String[] args) {// 创建一个 HashMapMap<Integer, String> map = new HashMap<>();// 使用 put() 方法向映射中添加键值对map.put(1, "苹果");map.put(2, "香蕉");map.put(3, "樱桃");System.out.println("添加键值对后: " + map);// 使用 get() 方法根据键获取对应的值String value = map.get(2);System.out.println("键 2 对应的值: " + value);// 使用 containsKey() 方法检查是否包含指定键boolean containsKey2 = map.containsKey(2);System.out.println("包含键 2: " + containsKey2);// 使用 containsValue() 方法检查是否包含指定值boolean containsValueBanana = map.containsValue("香蕉");System.out.println("包含值 '香蕉': " + containsValueBanana);// 使用 size() 方法返回映射中的键值对数量int size = map.size();System.out.println("映射的大小: " + size);// 使用 isEmpty() 方法检查映射是否为空boolean isEmpty = map.isEmpty();System.out.println("映射是否为空: " + isEmpty);// 使用 remove() 方法根据键移除键值对map.remove(2);System.out.println("移除键 2 后: " + map);// 再次使用 size() 方法返回映射中的键值对数量size = map.size();System.out.println("移除后映射的大小: " + size);// 使用 clear() 方法移除映射中的所有键值对map.clear();System.out.println("清空映射后: " + map);// 使用 isEmpty() 方法检查映射是否为空isEmpty = map.isEmpty();System.out.println("清空后映射是否为空: " + isEmpty);}
}
7.1.3 常用工具类
Java 的集合框架提供了许多有用的工具类,用于简化集合的操作。最常见的工具类是 java.util.Collections 和 java.util.Arrays。这些工具类提供了许多静态方法,可以对集合进行排序、搜索、填充、反转等操作。
7.1.3.1 集合工具类Collections
Collections工具类常用方法:
- sort(List<T> list):对指定的列表按自然顺序进行升序排序。
- sort(List<T> list, Comparator<? super T> c):使用指定的比较器对指定的列表进行排序。
- reverse(List<?> list):反转指定列表中元素的顺序。
- max(Collection<? extends T> coll):返回给定集合的最大元素,按自然顺序比较。
- max(Collection<? extends T> coll, Comparator<? super T> comp):返回给定集合的最大元素,使用指定的比较器比较。
- binarySearch(List<? extends T> list, T key):使用二分法搜索指定列表以查找指定对象。
- copy(List<? super T> dest, List<? extends T> src):将源列表的所有元素复制到目标列表中。
- fill(List<? super T> list, T obj):用指定的元素替换指定列表中的所有元素。
- frequency(Collection<?> c, Object o):返回指定集合中等于指定对象的元素数。
- indexOfSubList(List<?> source, List<?> target):返回指定源列表中首次出现指定目标列表的起始位置。
- swap(List<?> list, int i, int j):交换指定列表中指定位置的元素。
代码示例:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class CollectionsExample {public static void main(String[] args) {// 创建一个ArrayList并添加元素List<Integer> list = new ArrayList<>();list.add(5);list.add(3);list.add(8);list.add(1);list.add(6);// 输出原始列表System.out.println("原始列表: " + list);// 使用sort方法按自然顺序排序Collections.sort(list);System.out.println("排序后的列表: " + list);// 使用reverse方法反转列表Collections.reverse(list);System.out.println("反转后的列表: " + list);// 使用binarySearch方法查找元素int index = Collections.binarySearch(list, 3);System.out.println("元素3的索引: " + index);// 创建一个目标列表并使用copy方法复制元素List<Integer> destList = new ArrayList<>(Collections.nCopies(list.size(), 0));Collections.copy(destList, list);System.out.println("复制后的目标列表: " + destList);// 使用fill方法填充列表Collections.fill(list, 7);System.out.println("填充后的列表: " + list);// 使用swap方法交换元素Collections.swap(destList, 0, destList.size() - 1);System.out.println("交换后的目标列表: " + destList);}
}

7.1.3.2 数组工具类Arrays
Arrays工具类常用方法:
- asList(T... a):将数组转换为列表。
- sort(T[] a):对指定数组按自然顺序进行升序排序。
- sort(T[] a, Comparator<? super T> c):使用指定的比较器对数组进行排序。
- binarySearch(T[] a, T key):使用二分法搜索指定数组以查找指定对象。
- binarySearch(T[] a, T key, Comparator<? super T> c):使用二分法搜索指定数组以查找指定对象,使用指定的比较器。
- copyOf(T[] original, int newLength):复制指定的数组,截取或填充 null 以使副本具有指定的长度。
- copyOfRange(T[] original, int from, int to):复制指定的数组,从指定的起始位置开始到终止位置结束。
- equals(Object[] a, Object[] a2):如果两个指定数组彼此相等,则返回 true。一维数组时比较内容是否一致,多维数组时只比较最外层数组对象的内容。
- deepEquals(Object[] a1, Object[] a2):如果两个指定数组彼此深度相等,则返回 true。一维和多维数组比较内容是否一致。
- fill(T[] a, T val):用指定的值填充指定数组。
- toString(T[] a):返回指定数组内容的字符串表示形式。
- deepToString(Object[] a):返回指定数组内容的深层字符串表示形式。
代码示例:
/*** @Author: vince* @CreateTime: 2024/05/13* @Description: 测试类* @Version: 1.0*/
public class Test {public static void main(String[] args) {// 使用asList方法将数组转换为列表String[] stringArray = {"apple", "banana", "cherry"};List<String> stringList = Arrays.asList(stringArray);System.out.println("数组转换为列表: " + stringList);// 使用sort方法对数组进行排序int[] intArray = {5, 3, 8, 1, 6};System.out.println("原数组(直接打印): " + intArray);System.out.println("原数组(用Arrays.toString()打印):" + Arrays.toString(intArray));Arrays.sort(intArray);System.out.println("排序后的数组: " + Arrays.toString(intArray));// 使用binarySearch方法查找元素int index = Arrays.binarySearch(intArray, 3);System.out.println("元素3的索引: " + index);// 使用copyOf方法复制数组int[] copiedArray = Arrays.copyOf(intArray, intArray.length);System.out.println("复制后的数组: " + Arrays.toString(copiedArray));// 使用deepEquals方法比较多维数组Integer[][] deepArray1 = {{1, 2}, {3, 4}};Integer[][] deepArray2 = {{1, 2}, {3, 4}};boolean deepEqual = Arrays.deepEquals(deepArray1, deepArray2);System.out.println("多维数组是否深度相等: " + deepEqual);// 使用fill方法填充数组int[] fillArray = new int[5];Arrays.fill(fillArray, 7);System.out.println("填充后的数组: " + Arrays.toString(fillArray));// 使用toString方法将数组转换为字符串String arrayString = Arrays.toString(intArray);System.out.println("数组的字符串表示: " + arrayString);}
}
7.2 ArrayList
7.2.1 基本介绍
- 基本介绍:可以动态修改的数组,没有固定大小的限制。
- 使用场景:频繁查询但不经常增删元素
- 底层:数组 。允许存储多个null值。
- 性能:查询(get、contains)操作时间复杂度为O(1),添加(add)和删除(remove)元素时,可能需要移动数组中的元素,导致时间复杂度为O(n)。
- 常用API:
- Collection接口的add()、remove()等方法
- get():获取一个指定下标的元素
- subList(int fromIndex, int toIndex):返回从 fromIndex(包括)到 toIndex(不包括)之间的部分列表。
- trimToSize():将 ArrayList 的容量调整为当前元素的数量,以节省内存。
排序方法:
- Collections工具类的sort()方法:Collections.sort(list);
- stream流:list.stream().sort();
- 比较器:list.sort(new Comparator<Integer>() {})
- 手写排序:冒泡排序、选择排序、插入排序、二分法排序、快速排序、堆排序。
代码示例:
public static void main(String[] args) {// 创建一个 ArrayListArrayList<Integer> arrayList = new ArrayList<>();// 使用 add() 方法向集合中添加元素arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);System.out.println("添加元素后: " + arrayList);// 使用 get() 方法获取指定索引的元素int elementAtIndex2 = arrayList.get(2);System.out.println("索引 2 处的元素: " + elementAtIndex2);// 使用 set() 方法修改指定索引的元素arrayList.set(2, 35);System.out.println("修改索引 2 后: " + arrayList);// 使用 remove() 方法移除指定索引的元素arrayList.remove(1);System.out.println("移除索引 1 后: " + arrayList);// 使用 size() 方法获取集合的大小int size = arrayList.size();System.out.println("集合的大小: " + size);// 使用 contains() 方法检查集合中是否包含某个元素boolean contains30 = arrayList.contains(30);System.out.println("集合中是否包含 30: " + contains30);// 使用 isEmpty() 方法检查集合是否为空boolean isEmpty = arrayList.isEmpty();System.out.println("集合是否为空: " + isEmpty);}
7.2.2 底层源码和扩容机制
数组实现:
ArrayList是基于数组实现的,它的内部封装了一个Object[]数组。

transient Object[] elementData; // non-private to simplify nested class access通过默认构造器创建容器时,该数组先被初始化为空数组,之后在首次添加数据时再将其初始化成长度为10的数组。我们也可以使用有参构造器来创建容器,并通过参数来显式指定数组的容量,届时该数组被初始化为指定容量的数组。

/*** Default initial capacity.*/private static final int DEFAULT_CAPACITY = 10;每次扩容1.5倍:
如果向ArrayList中添加数据会造成超出数组长度限制,则会触发自动扩容,然后再添加数据。扩容就是数组拷贝,将旧数组中的数据拷贝到新数组里,而新数组的长度为原来长度的1.5倍。
// minCapacity 代表着最小扩容量
private void grow(int minCapacity) {// elementData 是 ArrayList 存储数据的数组,这里是获取当前数组的长度int oldCapacity = elementData.length;// 计算扩容后的数组长度 = 当前数组长度 + (当前数组长度 * 0.5);也就是扩容到当前的 1.5 倍int newCapacity = oldCapacity + (oldCapacity >> 1);// 判断新的数组是否满足最小扩容量,如果不满足就将新数组的扩容长度赋值为最小扩容量if (newCapacity - minCapacity < 0)newCapacity = minCapacity;// 如果扩容后的长度超过了最大数组大小,则将其设置为合适的容量if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity 通常接近于 size,因此这是一个有效的优化elementData = Arrays.copyOf(elementData, newCapacity);
}
手动缩容:
ArrayList支持缩容,但不会自动缩容,即便是ArrayList中只剩下少量数据时也不会主动缩容。如果我们希望缩减ArrayList的容量,则需要自己调用它的trimToSize()方法,届时数组将按照元素的实际个数进行缩减,底层也是通过创建新数组拷贝实现的。
public void trimToSize() {// 增加modCount,modCount是ArrayList的属性,用于记录集合被修改的次数。// 除了ArrayList,LinkedList、HashSet、TreeSet、HashMap、TreeMap等集合都有modCount属性modCount++;// 如果当前大小小于数组的长度,则进行缩容操作if (size < elementData.length) {// 如果 size 为 0,则将 elementData 置为 EMPTY_ELEMENTDATA// 否则将 elementData 缩容到 size 大小elementData = (size == 0) ? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size);}
}
7.2.3 线程不安全问题和解决方案
添加元素add()方法的源码:
public boolean add(E e) {// 1.扩容:判断列表的capacity容量是否足够,是否需要扩容ensureCapacityInternal(size + 1); // Increments modCount!!// 2.添加:真正将元素放在列表的元素数组里面elementData[size++] = e;return true;
}1.某线程刚扩容后就失去调度
在JVM中,CPU在多个线程中通过程序计数器来回调度,同一时刻一个CPU只能运行一个线程,所以就存在add()时,某个线程在刚刚ensureCapacityInternal()扩容后、还没往数组存元素时被暂停,等待被调度,然后其他线程add()成功把数组存满了,此时原线程恢复运行,执行elementData[size++] = e,因为数组容量已经满了,就会报错数组越界异常ArrayIndexOutOfBoundsException。
例如:
表大小为9,线程A新增一个元素,判断容量是不是足够,同时线程B也新增一个元素,判断容量是不是足够,线程A开始进行设置值操作, elementData[size++] = e 操作。此时size变为10,线程B也开始进行设置值操作,它尝试设置elementData[10] = e,而elementData没有进行过扩容,它的下标最大为9。于是此时会报出一个数组越界的异常ArrayIndexOutOfBoundsException.
2.数组存值时不是原子操作
另外第二步 elementData[size++] = e 设置值的操作同样会导致线程不安全。从这儿可以看出,这步操作也不是一个原子操作。
解决方案:
- 原子类
- volatile
- 锁
- 线程安全的集合:
- Collections工具类:Collections工具类的synchronizedXxx()方法,将ArrayList等集合类包装成线程安全的集合类。例如
Collections.synchronizedList(new ArrayList<>()); - 古老api:java.util包下性能差的古老api,如Vector、Hashtable
- 降低锁粒度的并发容器:JUC包下Concurrent开头的、以降低锁粒度来提高并发性能的容器,如ConcurrentHashMap。
- 复制技术实现的并发容器:JUC包下以CopyOnWrite开头的、采用写时复制技术实现的并发容器,如CopyOnWriteArrayList。
- Collections工具类:Collections工具类的synchronizedXxx()方法,将ArrayList等集合类包装成线程安全的集合类。例如
7.2.4 六种遍历方法
7.2.4.1. 常规 for 循环
普通 for 循环适用于遍历数组和实现了 List 接口的集合。它通过索引访问元素,性能通常较好。
优点:
- 性能高:性能通常优于增强 for 循环和迭代器,尤其是对于数组和 ArrayList。
- 复杂操作:允许在遍历过程中进行复杂的控制操作。
缺点:
- 可读性差:代码相对冗长,需要手动管理循环变量。
- 只能通过索引访问:仅适用于可以通过索引下标访问元素的集合。
通过for循环,用get(下标) 的方法遍历:
import java.util.ArrayList;public class ForLoopExample {public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);// 使用 for 循环遍历System.out.println("使用 for 循环遍历:");for (int i = 0; i < arrayList.size(); i++) {System.out.print(arrayList.get(i) + " ");}System.out.println();}
}
7.2.4.2. 增强 for 循环(只遍历不修改)
在某些情况下,常规的遍历方式容易显得代码臃肿,增强for可以简化数组和Collection集合的遍历,增强代码的可读性。
增强 for 循环:一种简洁的遍历集合的方法,它适用于遍历数组和实现了 Iterable 接口的所有集合。
Collection实现类都实现了Iterable 接口:
在标准的 Java Collections Framework 中,所有主要的集合实现类都实现了 Iterable 接口。换句话说,如果一个类实现了 Collection 接口,那么它也会实现 Iterable 接口,因为这是 Collection 接口的一个基本要求。
tip:Map集合没有实现Iterable 接口,因为它也没有实现Collection接口。
格式:
// 数据类型:即遍历对象中元素的数据类型。// 变量名:遍历时声明的变量,每次遍历得到的元素都会赋值给这个变量。// 数组或者集合对象:需要遍历的对象。for (数据类型 变量名 : 数组或者Collection集合对象) {//循环体System.out.println(变量名);}IDEA快捷键:输入iter然后回车:


优点:
-
简洁易读:增强 for 循环语法简洁,代码更容易阅读。
-
避免错误:相比传统的 for 循环,不需要手动管理循环变量,减少了出错的可能性。
缺点:
- 性能略差:性能略差于普通for循环,以略微的性能代价,提高了可读性
- 不允许修改;
代码示例:
public class EnhancedForLoopExample {public static void main(String[] args) {List<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);// 使用增强 for 循环遍历System.out.println("使用增强 for 循环遍历:");for (Integer num : arrayList) {System.out.print(num + " ");}System.out.println();}
}
7.2.4.3. 迭代器 Iterator(遍历并修改)
迭代器是遍历Collection集合的通用方式,它不需要关注集合和集合内元素的类型,对集合内的元素进行读取、添加、修改操作。
基本方法:
- hasNext():返回 true 如果还有未遍历的元素。
- next():返回下一个元素。
- remove():从集合中移除 next() 返回的最后一个元素。
优点:
- 各类型集合统一迭代器:不需要了解集合的内部实现,通过 Iterator 可以统一遍历不同类型的集合。
- 安全:在遍历过程中,如果其他线程修改了集合,Iterator 可以抛出 ConcurrentModificationException 以防止不一致性。
缺点:
- 性能略差:性能略差于普通for循环,以略微的性能代价,提高了可读性
- 复杂:相比增强for,需要next()、hasNext(),麻烦了一些
- 不能双向遍历
import java.util.ArrayList;
import java.util.Iterator;public class IteratorRemoveExample {public static void main(String[] args) {// 创建一个 ArrayList 并添加一些元素List<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);// 获取 ArrayList 的迭代器Iterator<Integer> iterator = arrayList.iterator();// 使用迭代器遍历 ArrayList 并移除元素System.out.println("使用迭代器遍历 ArrayList 并移除元素:");while (iterator.hasNext()) {Integer num = iterator.next();if (num > 30) {iterator.remove(); // 移除大于 30 的元素}}// 打印修改后的 ArrayListSystem.out.println("修改后的 ArrayList:");for (Integer num : arrayList) {System.out.print(num + " ");}System.out.println();}
}
7.2.4.4. 迭代器 ListIterator (双向遍历并修改)
Set、List、Queue都是Collection的子接口,它们都继承了父接口的iterator()方法,从而具备了迭代的能力。Map使用迭代器必须通过先entrySet()转为Set,然后再使用迭代器或for遍历。
但是,相比于另外两个接口,List还单独提供了listIterator()方法,增强了迭代能力。iterator()方法返回Iterator迭代器,listIterator()方法返回ListIterator迭代器,并且ListIterator是Iterator的子接口。
ListIterator在Iterator的基础上,增加了listIterator.previous()向前遍历的支持,增加了listIterator.set()在迭代过程中修改数据的支持。与 Iterator 相比,ListIterator 提供了更多的方法,但只适用于实现了 List 接口的集合(如 ArrayList 和 LinkedList)。
常用方法:
- hasNext():如果列表中有下一个元素,则返回 true。
- next():返回列表中的下一个元素。
- hasPrevious():如果列表中有上一个元素,则返回 true。
- previous():返回列表中的上一个元素。
- nextIndex():返回下一元素的索引。
- previousIndex():返回上一元素的索引。
- remove():移除上一个通过 next() 或 previous() 返回的元素。
- set(E e):替换上一个通过 next() 或 previous() 返回的元素。
- add(E e):在列表中插入指定元素。
优点:
- 可读性高;
- 安全:在遍历过程中,如果其他线程修改了集合,迭代器可以抛出 ConcurrentModificationException 以防止不一致性。
- 双向遍历;
缺点:
- 只支持List:只适用于实现了 List 接口的集合(如 ArrayList 和 LinkedList)。
- 性能略差:性能略差于普通for循环,以略微的性能代价,提高了可读性
public class ListIteratorExample {public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);// 使用 ListIterator 遍历(正向)System.out.println("使用 ListIterator 正向遍历:");ListIterator<Integer> listIterator = arrayList.listIterator();while (listIterator.hasNext()) {System.out.print(listIterator.next() + " ");}System.out.println();// 使用 ListIterator 反向遍历System.out.println("使用 ListIterator 反向遍历:");while (listIterator.hasPrevious()) {System.out.print(listIterator.previous() + " ");}System.out.println();}
}
7.2.4.5. forEach + Lambda 表达式(只遍历不修改)
在 Java 8 及以上版本中,forEach 方法与 Lambda 表达式的结合提供了一种简洁、功能强大的方式来遍历集合。forEach 方法属于 Iterable 接口,允许对集合中的每个元素执行指定的操作。
优点:
- 简洁:相比于传统的 for 循环和迭代器,代码更简洁,减少样板代码。
- 可读性强:使用 Lambda 表达式和方法引用,使代码更加易读和表达意图明确。
缺点:
- 性能略差:性能略差于普通for循环,以略微的性能代价,提高了代码的优雅性可读性 ;同时各个元素之间的遍历是顺序执行的,不像Stream流的forEach是并发执行的,性能略差。
- 不允许修改元素:因为 Lambda 表达式的参数是 final 或等效于 final 的,所以不允许修改集合中的元素。想修改的话,只能创建另一个集合,然后在遍历时将处理后的元素add进另一个集合。
- 版本限制:只适用JDK8及以上;
import java.util.ArrayList;public class ForEachLambdaExample {public static void main(String[] args) {List<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);// 使用 forEach 方法和 Lambda 表达式遍历System.out.println("使用 forEach 方法和 Lambda 表达式遍历:");arrayList.forEach(num -> System.out.print(num + " "));System.out.println();}
}
7.2.4.6. Stream API 遍历(推荐,并发遍历并修改)
Stream 流是 Java 8 引入的一项新特性,用于对集合进行函数式编程风格的操作。它允许我们以声明性方式对数据进行过滤、加工、遍历、排序等操作,而不是以命令式方式逐个操作元素。
优点:
- 简洁:相比于传统的 for 循环和迭代器,代码更简洁,减少样板代码。
- 生成修改后的新集合:允许通过map()、filter()等方法修改元素,然后收集成一个新集合。
- 性能高:因为是并发的,所以性能高。
缺点:
- 版本限制:只适用JDK8及以上;
import java.util.ArrayList;public class StreamExample {public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);// 使用 Stream API 遍历System.out.println("使用 Stream API 遍历:");arrayList.stream().forEach(num -> System.out.print(num + " "));System.out.println();}
}
7.2.4.7 小结:六种遍历方法的适用场景
- 需要根据索引下标遍历:普通for
- 只需要顺序读取元素:建议增强for,也可以用其他所有遍历方法
- 需要修改元素:普通for、迭代器、Stream流
- 需要双向遍历:ListIterator
- 需要过滤、加工、排序等高级操作:Stream流
7.3 List接口
7.3.1 主要实现类
Collection将集合划分为两大类,即List和Set。
常见的 List 实现类包括 ArrayList、LinkedList、Vector(JDK1的上古集合,虽然线程安全但性能差,已经基本不用) 和 Stack。
主要实现类
- ArrayList:
- 使用场景:频繁查询但不经常增删元素
- 底层:数组 。允许存储多个null值。
- 性能:查询(get、contains)操作时间复杂度为O(1),添加(add)和删除(remove)元素时,可能需要移动数组中的元素,导致时间复杂度为O(n)。
- LinkedList:
- 使用场景:频繁增删元素但不经常查询
- 底层:链表 。允许存储多个null值。
- 性能: 查询很慢(需要从头(或尾)遍历链表,查询操作时间复杂度为O(n) ),增删很快(只需调整链表的指针,插入(add)和删除(remove)操作时间复杂度为O(1))。
- Vector:
- 使用场景:需要线程安全且频繁查询的场景(JDK1的上古集合,虽然线程安全但性能差,已经基本不用。线程安全集合:
- Collections工具类:Collections工具类的synchronizedXxx()方法,将ArrayList等集合类包装成线程安全的集合类。
- 古老api:java.util包下性能差的古老api,如Vector、Hashtable
- 无序列表降低锁粒度的并发容器:JUC包下Concurrent开头的、以降低锁粒度来提高并发性能的容器,如ConcurrentHashMap。
- 复制技术实现的并发容器:JUC包下以CopyOnWrite开头的、采用写时复制技术实现的并发容器,如CopyOnWriteArrayList。
- 底层:数组。允许存储多个 null 值。
- 性能: 查询(get、contains)操作时间复杂度为O(1),添加(add)和删除(remove)元素时,可能需要移动数组中的元素,导致时间复杂度为O(n)。
- 使用场景:需要线程安全且频繁查询的场景(JDK1的上古集合,虽然线程安全但性能差,已经基本不用。线程安全集合:
- Stack:
- 使用场景:需要后进先出(LIFO)访问顺序的数据结构,例如递归、回溯算法等。线程安全,因为它是Vector的实现类
- 底层:数组(因为它是Vector的实现类)。允许存储多个 null 值。
- 性能: 增删改查都是在栈顶操作,所以时间复杂度都是O(1)
-
常用方法:
- push(E item):将元素压入栈顶
- pop():移除并返回栈顶元素
- peek():返回栈顶元素但不移除
- isEmpty():检查栈是否为空
- search(Object o):返回元素在栈中的位置,以 1 为基准
7.3.2 特点
主要特点:
- 有序【存储有序】
- 可重复
- 可以存储 null值
- 部分子集合线程安全,部分不安全 例如 ArrayList 和 Vector
7.3.3 常用方法
- 增:
- void add(int index, E element):在指定索引 index 处插入元素 element。
- boolean addAll(int index, Collection<? extends E> c):在指定索引 index 处插入集合 c 中的所有元素。
- 删:
- E remove(int index):删除指定索引 index 处的元素。
- 改:
- E set(int index, E element):修改指定索引 index 处的元素为 element。
- 遍历:
- E get(int index) + int size():使用 for 循环遍历集合中的每一个元素。
- ListIterator listIterator():通过列表迭代器遍历集合中的每一个元素。
- ListIterator listIterator(int index):通过列表迭代器从指定索引处开始正向或者逆向遍历集合中的元素。
- 获取:
- E get(int index):获取指定索引处的元素。
- int indexOf(Object o):从左往右查找,获取指定元素在集合中的索引,如果元素不存在返回 -1。
- int lastIndexOf(Object o):从右往左查找,获取指定元素在集合中的索引,如果元素不存在返回 -1
- List<E> subList(int fromIndex, int toIndex): 截取从 fromIndex 开始到 toIndex-1 处的元素
7.3.4 代码示例
public static void main(String[] args) {// 创建一个 ArrayListList<String> list = new ArrayList<>();// 增加元素list.add("元素1");list.add("元素2");list.add("元素3");System.out.println("增加元素后:" + list);// 在指定索引插入元素list.add(1, "元素4");System.out.println("在索引1插入元素4后:" + list);// 删除指定索引的元素list.remove(2);System.out.println("删除索引2的元素后:" + list);// 修改指定索引的元素list.set(1, "元素5");System.out.println("修改索引1的元素为元素5后:" + list);// 获取指定索引的元素String element = list.get(2);System.out.println("获取索引2的元素:" + element);// 获取元素的索引int index = list.indexOf("元素5");System.out.println("元素5的索引:" + index);// 遍历集合System.out.println("使用for循环遍历集合:");for (int i = 0; i < list.size(); i++) {System.out.println("索引" + i + "的元素:" + list.get(i));}// 使用 ListIterator 迭代器遍历集合System.out.println("使用ListIterator遍历集合:");ListIterator<String> listIterator = list.listIterator();while (listIterator.hasNext()) {System.out.println("元素:" + listIterator.next());}// 获取子列表List<String> subList = list.subList(1, 3);System.out.println("子列表(从索引1到索引2): " + subList);}
7.3.5 面向接口编程
面向接口编程:
面向接口编程(Programming to an Interface)是一种编程原则,它强调使用接口(Interface)而不是具体实现类(Concrete Class)来编写代码。
具体的使用方法是,声明一个接口的变量(接口的引用)可以指向一个实现类(实现该接口的类)的实例。
注意:因为是接口的引用,所以该引用的变量不能使用实现类中有、但接口中没有的方法(实现类中没有重写的方法,自添加的方法)。
以面向接口编程为原则,以多态的形式创建集合对象:
以下两种方法都可以创建ArrayList,但是更推荐第一种方法:
// 推荐,面向接口编程,多态形式,对象实例指向接口引用 List<Integer> arrayList = new ArrayList<>(); // 不推荐,常规创建对象形式 ArrayList<Integer> arrayList = new ArrayList<>();因为前者符合设计模式中的依赖倒置原则。即程序要尽量依赖于抽象,不依赖于具体。
在Java语法中,这种方式符合Java三大特性中的多态,即使用接口引用指向具体实现。
依赖倒转的好处是,后期扩展方便。比如,你若希望用LinkedList的实现来替代ArrayList的话,只需改动一行即可,其他的所有的都不需要改动:List<Integer> list=new LinkedList<>();这也是一种很好的设计模式,符合面向接口编程原则.一个接口有多种实现,当你想换一种实现方式时,你需要做的改动很小.
优点:
- 解耦合:声明的变量与具体实现类解耦。变量只依赖于接口,而不是具体实现,这样可以很容易地替换具体实现类,而不需要修改客户端代码。
- 可扩展性:当需要添加新功能时,只需实现新的接口,让原引用指向新的实现类,而不需要修改现有代码。例如SpringBoot项目中,我们经常用XxxService接口和XxxServiceImpl1、XxxServiceImpl2等业务实现类,在使用时,通常将这个接口引用通过@Autowired等注解注入XxxService,然后通过@Primary、@Qualifier等注解指定具体注入XxxServiceImpl1还是XxxServiceImpl2,方便扩展。
- 可测试性:在单元测试中,可以轻松地使用接口的模拟实现来替换真实的实现,从而进行隔离测试。
符合设计原则:
- 开闭原则OCP(Open-Close Principle): 对拓展开放、对修改关闭。
- 依赖倒置原则DIP(Dependency Inversion Principle): 抽象不应该依赖于细节、细节应该依赖于抽象。例如我们开发中要用Service接口和ServiceImpl实现类,而不是直接一个ServiceImpl类中写业务。
设计原则详细参考:
设计模式——设计模式简介和七大原则_理解设计模式的核心思想和基本理念是什么-CSDN博客
7.4 LinkedList
7.4.1 基本介绍
LinkedList:
- 使用场景:频繁增删元素但不经常查询
- 底层:链表 。允许存储多个null值。
- 性能: 查询很慢(需要从头(或尾)遍历链表,查询操作时间复杂度为O(n) ),增删很快(只需调整链表的指针,插入(add)和删除(remove)操作时间复杂度为O(1))。
常用方法:
| 方法 | 描述 |
|---|---|
| public void add(int index, E element) | 向指定位置插入元素。 |
| public void addFirst(E e) | 元素添加到头部。 |
| public void addLast(E e) | 元素添加到尾部。 |
| public void clear() | 清空链表。 |
| public E remove(int index) | 删除指定位置的元素。 |
| public E removeFirst() | 删除并返回第一个元素。 |
| public E removeLast() | 删除并返回最后一个元素。 |
| public boolean contains(Object o) | 判断是否含有某一元素。 |
| public E getFirst() | 返回第一个元素。 |
| public E getLast() | 返回最后一个元素。 |
代码示例:
public static void main(String[] args) {LinkedList<String> link=new LinkedList<String>();link.addLast("hello");link.addLast("world");for(String s:link) System.out.println(s);System.out.println(link);}7.4.2 ArrayList和LinkedList的区别
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 使用场景 | 频繁查询但不经常增删元素 | 频繁增删元素但不经常查询 |
| 底层 | 数组 | 链表 |
| 允许存储 null 值 | 是。允许存储多个null值 | 是。允许存储多个null值 |
| 查询性能 | 快。根据索引查询(get、contains)操作时间复杂度为 O(1) | 慢。根据索引查询很慢(需要从头(或尾)遍历链表,查询操作时间复杂度为 O(n)) |
| 添加性能 | 慢。添加(add)元素时,可能需要移动数组中的元素,导致时间复杂度为 O(n) | 快。插入(add)操作时间复杂度为 O(1),插入后不需要移动元素 |
| 删除性能 | 慢。删除(remove)元素时,可能需要移动数组中的元素,导致时间复杂度为 O(n) | 快。删除(remove)操作时间复杂度为 O(1),删除后不需要移动元素 |
7.5 Hashset
7.5.1 基本介绍
HashSet:
- 使用场景:需要高效去重、快速查找、不考虑内存浪费的场景
- 底层:哈希表(快速查找)和Set(去重)。它自动对元素进行去重(通过 hashCode 和 equals 方法),并且无序(存入后顺序会乱),允许存储一个null值。
- 性能:底层是哈希表,所以插入、删除和查找操作的时间复杂度都是O(1),代价是浪费一些空间。
哈希表是元素为链表的数组,默认容量16,负载因子0.75,处理冲突方法是链地址法。
import java.util.HashSet;
import java.util.LinkedList;public class Test2 {public static void main(String[] args) {HashSet<String > h=new HashSet<String>();h.add("nihao");String s1=new String("nihao");h.add(s1);System.out.println(s1=="nihao"); //falsefor(String s:h) System.out.println(s); //不含重复元素 }
}

如果Hashset里的元素是对象,若想将成员变量相同视为对象相同,要重写hashCode():
import java.util.HashSet;public class Test {public static void main(String[] args) { //输出23Dog dog1=new Dog(23);Dog dog2=new Dog(23);HashSet<Dog> h=new HashSet<Dog>();h.add(dog1);h.add(dog2);for(Dog dog:h) System.out.println(dog.weight); }
}package package1;public class Dog extends Animal{int weight=4;public Dog(){
// System.out.println("doggouzaao");}public Dog(int weight){this.weight=weight;}@Overridepublic void show() {name="dogname";System.out.println("dog");}@Overridepublic boolean equals(Object o) { //alt+insert生成equals()和hashCode()方法。这里其实只需要重写hashCode方法就能保证自动去重,equals方法用于元素间的比较if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Dog dog = (Dog) o;return weight == dog.weight;}@Overridepublic int hashCode() {return weight;}@Overridepublic String toString() {return "Dog{" +"weight=" + weight +'}';}
}
7.5.2 去重原理:hashCode值
HashSet自动去重的原理:hashCode值。
所有Java的类或接口都直接或间接继承了Object类,Object类是一切类的根类。Object类有一个clone(),HashCode(),equals(),toString(),wait(),notify()等基本方法,我们可以通过重写这些方法,对类的特性进行设置。
例如我们给测试类新加一个hashCode()方法,而不加@Override注解(用于声明一个方法为重写的方法),编译器将进行警告:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/
public class Test {
// @Overridepublic int hashCode() {return 1;}public static void main(String[] args) {}
}
HashSet通过hashCode值来判断重复元素的,hashCode值是通过HashCode()方法返回的。
默认情况下,哈希值是根据对象的地址计算出的一个整数值,所以同一对象的哈希值一定相同(因为地址是同一地址),不同对象的哈希值默认不同(因为地址不同)。
重写hashCode()后哈希值可以相同,例如我们给Student类重写hashCode(),返回学生的学号,那么学号相同的学生,哈希值就一定相等。
代码示例:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description:* @Version: 1.0*/
class Student {private String name;private int id;public Student(String name, int id) {this.name = name;this.id = id;}/*** 重写 hashCode() 方法,返回学号作为哈希值* @return int*/@Overridepublic int hashCode() {return id;}/*** 重写 equals() 方法,判断学号是否相同* @param obj* @return boolean*/@Overridepublic boolean equals(Object obj) {if (this == obj) {return true;}if (obj == null || getClass() != obj.getClass()) {return false;}Student student = (Student) obj;return id == student.id;}/*** 重写 toString() 方法,返回学生姓名和学号* @return {@link String }*/@Overridepublic String toString() {return "Student{name='" + name + "', id=" + id + "}";}public static void main(String[] args) {Student student1 = new Student("Tom", 1);Student student2 = new Student("Tom", 1);// 根据重写的 equals() 方法输出// trueSystem.out.println(student1.equals(student2));// 1System.out.println(student1.hashCode());// 1System.out.println(student2.hashCode());// 根据重写的 toString() 方法输出// Student{name='Tom', id=1}System.out.println(student1.toString());}
}运行main方法后,结果:

7.5.3 知识加油站
7.5.3.1 equals()和hashcode()的关系
两者在用途上的区别:
- hashCode()方法的主要用途是获取哈希码;
- equals()主要用来比较两个对象是否相等。
为什么重写equals()就要重写hashcode()?
因为二者之间有两个约定,相等对象的哈希码也要相等。
所以equals()方法重写时,通常也要将hashCode()进行重写,使得这两个方法始终满足相关的约定。 例如HashSet排序机制底层就是通过计算哈希码进行排序的,如果只重写equals()将达不到根据哈希码排序的效果。
如果两个对象相等,它们必须有相同的哈希码;但如果两个对象的哈希码相同,他们却不一定相等。
7.5.3.2 ==与equals()的区别
-
== 比较基本数据类型时,比较的是两个数值是否相等; 比较引用类型是,比较的是对象的内存地址是否相等。
-
equals() 没有重写时,Object类默认以==来实现,即比较两个对象的内存地址是否相等; 重写以后,按照重写的逻辑进行比较。

7.6 HashMap
7.6.1 基本介绍
使用场景: 适用于需要基于键值对快速查找数据的场景。“键”可以理解为钥匙,通过这个钥匙,可以找到它唯一对应的“值”。
底层: 哈希表(数组+链表/红黑树)。
性能:
- 查询性能: 快,时间复杂度为 O(1)。
- 添加性能: 快,时间复杂度为 O(1)。
- 删除性能: 快,时间复杂度为 O(1)。
是否允许 null:
- 键可以为 null(但最多一个键为 null)。
- 值可以为 null。
常用方法:
- put():向映射中添加一个键值对。如果键已经存在,则更新其对应的值。
- get():根据键获取对应的值。
- getOrDefault():获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值
- keySet():返回所有key的Set集合。
- remove(Object key): 根据键移除键值对。
- containsKey(Object key): 检查是否包含指定键。
- containsValue(Object value): 检查是否包含指定值。
- size(): 返回映射中的键值对数量。
- isEmpty(): 检查映射是否为空。
- clear(): 移除映射中的所有键值对。
代码示例:
public class Test {public static void main(String[] args) {// 创建一个 HashMapMap<String, String> fruitColor = new HashMap<>();// 使用 put() 方法向映射中添加键值对fruitColor.put("苹果", "红色");fruitColor.put("香蕉", "黄色");fruitColor.put("樱桃", "红色");System.out.println("添加键值对后: " + fruitColor);// 使用 get() 方法根据键获取对应的值String value = fruitColor.get("香蕉");System.out.println("键 '香蕉' 对应的值: " + value);// 遍历 keySetSet<String> keys = fruitColor.keySet();System.out.println("遍历 keySet:");for (String key : keys) {System.out.println("水果: " + key + " 颜色: " + fruitColor.get(key));}// 使用 containsKey() 方法检查是否包含指定键boolean containsKeyBanana = fruitColor.containsKey("香蕉");System.out.println("包含键 '香蕉': " + containsKeyBanana);// 使用 containsValue() 方法检查是否包含指定值boolean containsValueYellow = fruitColor.containsValue("黄色");System.out.println("包含值 '黄色': " + containsValueYellow);// 使用 size() 方法返回映射中的键值对数量int size = fruitColor.size();System.out.println("映射的大小: " + size);// 使用 isEmpty() 方法检查映射是否为空boolean isEmpty = fruitColor.isEmpty();System.out.println("映射是否为空: " + isEmpty);// 使用 remove() 方法根据键移除键值对fruitColor.remove("香蕉");System.out.println("移除键 '香蕉' 后: " + fruitColor);// 再次使用 size() 方法返回映射中的键值对数量size = fruitColor.size();System.out.println("移除后映射的大小: " + size);// 使用 clear() 方法移除映射中的所有键值对fruitColor.clear();System.out.println("清空映射后: " + fruitColor);// 使用 isEmpty() 方法检查映射是否为空isEmpty = fruitColor.isEmpty();System.out.println("清空后映射是否为空: " + isEmpty);}
}
7.6.2 HashMap和HashSet区别
相同点:
- 他们的前缀的是HashXxx,代表他们底层都是哈希表,用hashCode()判断元素是否重复。
哈希表增删改查的时间复杂度是O(1),缺点是可能出现冲突。
HashXxx都使用哈希算法来确定元素的存储位置,因此插入元素的速度通常比较快。哈希表插入时主要看是否发生冲突,如果key通过哈希算法计算后的值所处位置已有元素,则需要根据链地址法或开放地址法处理冲突。

不同点:
| 特性 | HashMap | HashSet |
|---|---|---|
| 接口 | 实现了 Map 接口 | 实现了 Set 接口 |
| 存储结构 | 存储键值对(Key-Value pairs) | 仅存储对象(Unique elements) |
| 存储方式 | 使用 put() 方法将元素放入 Map 中 | 使用 add() 方法将元素放入 Set 中 |
| 底层实现 | 基于哈希表,使用数组和链表(或红黑树) | 基于 HashMap 实现,每个元素作为 HashMap 的键,值为一个常量对象 |
| 存储内容 | 键和值都可以为 null,键最多只能有一个 null | 仅允许一个 null 元素 |
| 是否允许重复 | 键不允许重复,值可以重复 | 不允许重复元素 |
| 时间复杂度 | 插入、删除、查找的平均时间复杂度为 O(1) | 插入、删除、查找的平均时间复杂度为 O(1),但 contains() 时间复杂度可能更高 |
| 插入速度 | 比较快,因为底层是哈希表 | 比较快,因为底层是哈希表 |
| 使用场景 | 需要键值对映射的场景 | 需要存储唯一元素的场景 |
7.6.3 知识加油站:HashMap的底层原理
7.6.3.1 线程不安全
HashMap是线程不安全的,多线程环境下建议使用Collections工具类和JUC包的ConcurrentHashMap。
- 线程安全:程序在多线程环境下可以持续进行正确的处理,不会产生数据竞争(例如死锁)和不一致的问题。
线程安全的解决方案:原子类、volatile、锁、线程安全的集合
线程安全的集合:
- Collections工具类:Collections工具类的synchronizedXxx()方法,将ArrayList等集合类包装成线程安全的集合类。
Collections.synchronizedMap(map); - 古老api:java.util包下性能差的古老api,如Vector、Hashtable
- 降低锁粒度的并发容器:JUC包下Concurrent开头的、以降低锁粒度来提高并发性能的容器,如ConcurrentHashMap。
- 复制技术实现的并发容器:JUC包下以CopyOnWrite开头的、采用写时复制技术实现的并发容器,如CopyOnWriteArrayList。
7.6.3.2 底层数据结构
在JDK8中,HashMap底层是采用“数组+单向链表+红黑树”来实现的。数组用作哈希查找,链表用作链地址法处理冲突,红黑树替换长度为8的链表。

7.6.3.3 扩容机制
HashMap中,数组的默认初始容量为16,这个容量会以2的指数进行扩容。具体来说,当数组中的元素达到一定比例的时候HashMap就会扩容,这个比例叫做负载因子,默认为0.75。
自动扩容机制,是为了保证HashMap初始时不必占据太大的内存,而在使用期间又可以实时保证有足够大的空间。采用2的指数进行扩容,是为了利用位运算,提高扩容运算的效率。
数组每个元素存的是链表头结点地址,链地址法处理冲突,若链表的长度达到了8,红黑树代替链表。
7.6.3.4 put()流程
put()方法的执行过程中,主要包含四个步骤:
- 计算key存取位置,与运算hash&(2^n-1),实际就是哈希值取余,位运算效率更高。
- 判断数组,若发现数组为空,则进行首次扩容为初始容量16。
- 判断数组存取位置的头节点,若发现头节点为空,则新建链表节点,存入数组。
- 判断数组存取位置的头节点,若发现头节点非空,则看情况将元素覆盖或插入链表(JDK7头插法,JDK8尾插法)、红黑树。
- 插入元素后,判断元素的个数,若发现超过阈值则以2的指数再次扩容。
其中,第3步又可以细分为如下三个小步骤:
1. 若元素的key与头节点的key一致,则直接覆盖头节点。
2. 若元素为树型节点,则将元素追加到树中。
3. 若元素为链表节点,则将元素追加到链表中。追加后,需要判断链表长度以决定是否转为红黑树。若链表长度达到8、数组容量未达到64,则扩容。若链表长度达到8、数组容量达到64,则转为红黑树。
哈希表处理冲突:开放地址法(线性探测、二次探测、再哈希法)、链地址法
7.6.3.5 HashMap容量为什么是2的n次方?
2^n-1和2^(n+1)-1的二进制除了第一位,后几位都是相同的。这样可以使得添加的元素均匀分布在HashMap的每个位置上,防止哈希碰撞。
例如15的二进制为1111,31的二进制为11111,63的二进制为111111,127的二进制为1111111。
扩容均匀散列演示:从2^4扩容成2^5
0&(2^4-1)=0;0&(2^5-1)=0
16&(2^4-1)=0;16&(2^5-1)=16。所以扩容后,key为0的一部分value位置没变,一部分value迁移到扩容后的新位置。
1&(2^4-1)=1;1&(2^5-1)=1
17&(2^4-1)=1;17&(2^5-1)=17。所以扩容后,key为1的一部分value位置没变,一部分value迁移到扩容后的新位置。
7.6.3.6 JDK7扩容时死循环问题
单线程扩容流程:JDK7中,HashMap链地址法处理冲突时采用头插法,在扩容时依然头插法,所以链表里结点顺序会反过来。
假如有T1、T2两个线程同时对某链表扩容,他们都标记头结点和第二个结点,此时T2阻塞,T1执行完扩容后链表结点顺序反过来,此时T2恢复运行再进行翻转就会产生环形链表,即B.next=A; A.next=B,从而死循环。
JDK8 尾插法:JDK8中,HashMap采用尾插法,扩容时链表节点位置不会翻转,解决了扩容死循环问题,但是性能差了一点,因为要遍历链表再查到尾部。
7.6.3.7 JDK8 put时数据覆盖问题:
HashMap非线程安全,如果两个并发线程插入的数据hash取余后相等,就可能出现数据覆盖。
线程A刚找到链表null位置准备插入时就阻塞了,然后线程B找到这个null位置插入成功。借着线程A恢复,因为已经判过null,所以直接覆盖插入这个位置,把线程B插入的数据覆盖了。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有 hash 碰撞,则直接插入tab[i] = newNode(hash, key, value, null);}
7.6.3.8 modCount非原子性自增问题
put会执行modCount++操作(modCount是HashMap的成员变量,用于记录HashMap被修改次数),这步操作分为读取、增加、保存,不是一个原子性操作,也会出现线程安全问题。
7.7 TreeSet
7.7.1 基本介绍
TreeSet:
- 特点:有序(自然顺序或自定义排序器),去重复。
-
元素为基本类型时自然有序:new TreeSet<int>()。如果TreeSet内元素是基本数据类型,它会自动去重有序。
-
元素为类时自然或比较器排序:new TreeSet<类>(Comperable c)。如果TreeSet内元素是类,要实现去重有序,有两种方法。
-
自然排序:类要实现Comparable<>接口,并重写compareTo(T)方法;
-
比较器排序:以比较器作为构造参数,创建TreeSet对象。如果即实现了Comparable<>接口,又指定了比较器,则使用比较器排序。
-
-
- 使用场景:适用于多读少写、排序的场景。
- 底层:红黑树(快速查找、排序)和Set(去重)。不允许存储null值
- 性能:插入、删除、查找操作的时间复杂度为O(log n),因为操作需要维护树的平衡,所以适用于多读少写的场景。
方法一:自然排序
实现Comparable<>重写compareTo()方法
/*** @Author: vince* @CreateTime: 2024/07/02* @Description: 狗类:按自然排序时要实现Comperable<>并重写compareTo()方法* @Version: 1.0*/
public class Dog implements Comparable<Dog>{ int weight;String name;public Dog(int weight, String name) {this.weight = weight;this.name = name;}@Overridepublic String toString() {return "Dog{" +"weight=" + weight +", name='" + name + '\'' +'}';}@Overridepublic int compareTo(Dog dog){ //实参是上一只狗,本狗与上狗做比较//返回正数,即本狗比上只狗大,按存取顺序排序return 1;//return -1;存储逆序排序//return 0;视为相等,后插入的重复元素会被删除。//return this.weight-dog.weight;按体重从小到大排序,后狗-前狗。}
}
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/
public class Test {public static void main(String[] args) {// 创建两个小狗对象,让他们按自己compareTo()逻辑排序,即按存取顺序排序Dog dog1=new Dog(23,"abc");Dog dog2=new Dog(45,"abc");Dog dog3=new Dog(45,"abc");TreeSet<Dog> dogs=new TreeSet<>();dogs.add(dog1);dogs.add(dog2);dogs.add(dog3);// 因为第三只狗和第二只狗存取顺序不同,所以他们被认为是两只狗// [Dog{weight=26, name='abc'}, Dog{weight=26, name='abcd'}, Dog{weight=34, name='abc'}]System.out.println(dogs);}
}
方法二:比较器排序
无需Dog类再实现Comparable接口,直接TreeSet类带参构造方式创建对象即可,参数为比较器Comparator<>。
/*** @Author: vince* @CreateTime: 2024/07/02* @Description: 狗类:按比较器排序时不需要再实现Comperable<>* @Version: 1.0*/
public class Dog {int weight;String name;public Dog(int weight, String name) {this.weight = weight;this.name = name;}@Overridepublic String toString() {return "Dog{" +"weight=" + weight +", name='" + name + '\'' +'}';}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}Dog dog = (Dog) o;return weight == dog.weight && Objects.equals(name, dog.name);}@Overridepublic int hashCode() {return Objects.hash(weight, name);}
}/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/
public class Test {public static void main(String[] args) {//下面比较器也可以用Lambda表达式形式,即TreeSet<>((a,b)->{..})TreeSet<Dog> dogs=new TreeSet<>(new Comparator<Dog>() {@Overridepublic int compare(Dog a, Dog b){if(a.weight!=b.weight) {return a.weight-b.weight;}else {return a.name.compareTo(b.name);}}});dogs.add(new Dog(34,"abc"));dogs.add(new Dog(26,"abc"));dogs.add(new Dog(26,"abcd"));dogs.add(new Dog(26,"abcd"));// 可以看见,前三只狗按体重、名称排序,第四只狗被去重了// [Dog{weight=26, name='abc'}, Dog{weight=26, name='abcd'}, Dog{weight=34, name='abc'}]System.out.println(dogs);}
}
7.7.2 HashSet和TreeSet的区别
相同点:元素都可以自动去重
不同点:
| HashSet | TreeSet | |
|---|---|---|
| 实现 | 基于哈希表 实现 | 基于红黑树 (Red-Black Tree) 实现 |
| 排序 | 不保证顺序 | 按自然顺序或指定的比较器排序 |
| 性能 | 插入、删除和查找操作的时间复杂度为 O(1) | 插入、删除和查找操作的时间复杂度为 O(log n) |
| 是否允许 null 元素 | 允许存储一个 null 元素 | 不允许存储 null 元素 |
| 适用场景 | 适用于对顺序无要求、自动去重、快速查找和插入的场景 | 适用于需要自动有序、去重存储的场景 |
| 去重原理 | 通过复写hashCode()方法和equals()方法来保证的 | Treeset是通过Compareable接口的compareto方法来保证的。 |
八、泛型
8.1 基本介绍
泛型本质是将类、接口和方法中具体的类型参数化,并且提供了编译时类型安全检测机制。通过使用泛型,可以避免使用Object类导致的类型转换错误和减少了代码的冗余。
尖括号“<>”是泛型的标志,例如ArrayList<E>就是一个泛型,“<E>”将实际的集合元素类型参数化了,这样我们使用时可以指定new ArrayList<String>,将它指定:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: ArrayList<E>是标准的类泛型,在使用时指定这个“E”具体是什么* @Version: 1.0*/
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
..
}我们在使用ArrayList时,尖括号指定<String>,这样它就只能存String类型的元素了:
// 我们在使用ArrayList时,尖括号指定<String>,这样它就只能存String类型的元素了
ArrayList<String> list = new ArrayList<String>();这样,如果给它存String类型参数,就是正常的,一旦存其他类型,就会在代码下面出现红色波浪线,编译期间就报错:

这也是泛型的优点,如果我们不用泛型,而用public class ArrayList<Object>{}方式声明ArrayList,就可以往集合里存所有类型的参数,编译是也不报错,但是可读性很差,你不知道它具体应该存哪些类型,存的类型不是业务中需要类型时,编译期间也不报错,直到生产环境运行时报错,就会出现不好的影响了。
详细介绍:
泛型:将具体的类型参数化,是一种编程范式,提供了编译时类型安全检测机制。
通过使用泛型,我们可以将数据类型作为参数传递给类、接口或方法,可以在编译时期进行类型检查,避免在运行时期出现类型转换错误。
泛型的范围:泛型接口,泛型类(创建对象时再指定具体类型),泛型方法。
实现方式:以泛型类举例。我们只需要在类名后面使用尖括号<>将一个符号或多个符号包裹起来,这样在类里面就可以使用该符号代替具体类型了。使用泛型类时,调用者实际传进来什么类型,编译时就会将泛型符号擦除,替换成这个实际类型。泛型符号可以是任意符号,但我们约定使用T、E、K、V等符号。
为什么要有泛型,而不是使用Object类?
因为泛型是在编译时泛型擦除和替换实际类型的,而使用Object类会很麻烦,需要经常强制转换。
例如List集合里,如果直接声明存Object类的话,存的时候还好,可以通过多态机制直接向上转型,而取的时候就麻烦了,要强转Object类为String等对象,然后才能访问该对象的成员;而且你不知道实际元素到底是String类型还是Integer等其他类型,还要通过i instanceof String判断类型,就更麻烦了。
这也是泛型的优点:
- 防止运行时报错:可以在编译时检查类型安全,防止在程序运行期间出现BUG。
- 隐式转换:所有的强制转换都是自动和隐式的,可以提高代码的重用率。
8.2 格式
8.2.1 泛型参数类型
我们可以看见,前面 ArrayList<E>,尖括号内是“E”,然后我们可能看见其他泛型尖括号内是“T”,具体是哪个大写字母,其实并没有特定的要求,只是遵循了某些约定俗成的惯例。
泛型参数类型的惯例:
-
<E>:表示元素(Element),通常在集合类中使用。例如,List<E>,Set<E>。
-
<T>:表示类型(Type),通常在一般类型中使用。例如,Box<T>,Comparable<T>。
-
<K> 和 <V>:分别表示键(Key)和值(Value),通常在映射(Map)类中使用。例如,Map<K, V>,Entry<K, V>。
-
<N>:表示数字(Number),在需要表示数字的泛型中使用。
8.2.2 泛型类
泛型类定义了一个泛型参数,创建对象时给它传入这个参数的实际类型。
格式:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 类泛型* @Version: 1.0*/
class ClassName<T> {// 成员变量、构造方法和方法可以使用类型参数T
}代码示例:
模拟ArrayList增、查、扩容:
/*** @Author: vince* @CreateTime: 2024/07/04* @Description: ArrayList简化版* @Version: 1.0*/
public class MyList<E> {// 初始容量private static final int INITIAL_CAPACITY = 10;// 存储元素的数组private Object[] elementData;// 当前元素数量private int size;// 构造方法,初始化数组和大小public MyList() {elementData = new Object[INITIAL_CAPACITY];size = 0;}/*** 添加元素到列表中* @param e* @return boolean*/public boolean add(E e) {// 如果当前数组容量不足,则扩容if (size == elementData.length) {grow();}// 将元素添加到数组中,并增加元素数量elementData[size++] = e;return true;}/*** 获取指定位置的元素* @param index* @return {@link E }*/@SuppressWarnings("unchecked")public E get(int index) {// 检查索引是否有效if (index < 0 || index >= size) {throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);}// 返回元素,强制转换为泛型类型return (E) elementData[index];}/*** 返回当前元素数量* @return int*/public int size() {return size;}/*** 扩容方法,将数组容量扩大 1.5 倍*/private void grow() {int newCapacity = elementData.length + (elementData.length >> 1);elementData = Arrays.copyOf(elementData, newCapacity);}public static void main(String[] args) {MyList<String> myList = new MyList<>();myList.add("Hello");myList.add("World");myList.add("!");System.out.println("元素数量: " + myList.size());// 输出: 第一个元素: HelloSystem.out.println("第一个元素: " + myList.get(0));// 输出: 第二个元素: WorldSystem.out.println("第二个元素: " + myList.get(1));// 输出: 第三个元素: !System.out.println("第三个元素: " + myList.get(2));// 尝试获取索引越界的元素,抛出 IndexOutOfBoundsException// System.out.println(myList.get(3));}
}

8.2.3 泛型接口
泛型接口和泛型类类似,也是定义了一个泛型参数。不同的点是,泛型接口在被实现或者被继承时需要指定具体类型。
如果泛型接口的实现类不是泛型:
- 实现泛型接口时,如果没有省略尖括号“<>”,则必须在接口“<>”中指定类型
- 实现泛型接口时,如果省略了尖括号“<>”,则默认“<>”内是Object类
如果泛型接口的实现类是泛型:
- 实现泛型接口时,实现类也必须是泛型类,并且类型与泛型接口保持一致
格式:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 接口泛型* @Version: 1.0*/
interface InterfaceName<T> {// 接口中的方法可以使用类型参数T
}代码示例:
泛型接口:
/*** @Author: vince* @CreateTime: 2024/07/04* @Description: 泛型接口* @Version: 1.0*/
public interface IGen<E> {public void fun(E e);
}
如果泛型接口的实现类不是泛型,实现泛型接口时,如果没有省略尖括号“<>”,则必须在接口“<>”中指定类型:
/*** @Author: vince* @CreateTime: 2024/07/04* @Description: 泛型接口实现类必须指定具体类型,否则会报错* @Version: 1.0*/
public class Gen implements IGen<Integer>{@Overridepublic void fun(Integer integer) {System.out.println(integer);}
}如果泛型接口的实现类不是泛型,实现泛型接口时,如果省略了尖括号“<>”,则默认“<>”内是Object类
/*** @Author: vince* @CreateTime: 2024/07/04* @Description: 泛型接口实现类:如果接口省略<>,则默认是Object* @Version: 1.0*/
public class Gen implements IGen{/*** 如果参数不是Object,就报错。因为接口了省略<>,默认是IGen<Object>* @param integer*/@Overridepublic void fun(Object integer) {System.out.println(integer);}
}如果泛型接口的实现类是泛型,实现泛型接口时,实现类也必须是泛型类,并且类型与泛型接口保持一致
/*** @Author: vince* @CreateTime: 2024/07/04* @Description: 泛型接口实现类也是泛型类时,泛型参数类型必须与泛型接口保持一致,用<E>,而不是<T>等* @Version: 1.0*/
public class Gen<E> implements IGen<E>{@Overridepublic void fun(E e) {System.out.println(e);}
}8.2.4 泛型方法
当在一个方法签名中的返回值前面声明了一个 < T > 时,该方法就被声明为一个泛型方法。
然后返回类型、参数类型都可以用这个<T>,当然也可以不用。
格式:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 方法泛型* @Version: 1.0*/
public <T> 返回类型 方法名(参数类型 parameter) {// 方法体
}示例:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/public class Test {/*** 泛型方法1:返回值和参数可以T* @param t* @return {@link T }*/public <T> T fun1(T t){return t;}/*** 泛型方法1:参数可以是多个,但类型必须都是T** @param a* @param b* @return {@link T }*/public <T> T fun2(T a,T b){return a;}/*** 泛型方法2:返回值和参数并不一定是T,也可以是具体类型* @param integer* @return {@link Integer }*/public <T> void fun3(Integer integer){System.out.println(integer);}public static void main(String[] args) {Test test = new Test();// 实参传入String类型System.out.println(test.fun1("Hello"));// 实参传入int类型System.out.println(test.fun1(1111));// 实参传入多个String类型System.out.println(test.fun2("Hello", "World"));test.fun3(2222);}
}
8.3 类型通配符
类型通配符跟泛型参数<T>、<E>等类似,用于表示不确定的类型,不同的点在于:
- 类型参数:用于声明泛型类、泛型接口或泛型方法。声明时是未知类型,使用时擦除成具体的类型(在编译时泛型擦除)。
- 类型通配符:用于使用泛型时,表示一种未知的类型。
类型通配符有三种:
- <?> :无限定的通配符。可以用来表示任何类型。无限定通配符只能读Object类型的值,只能写null类型的值,其他类型都不能读写。
- <? extends T> :有上界的通配符。表示继承自T的任何类型,这里上界指的就是T。它通常用于生产者,即返回T。上界通配符只允许读值,不允许写null以外值。
- <? super T> :有下界的通配符。表示子类是T的任何类型,这里下界指的就是T。它通常用于消费者,即写入T。下界类型通配符只允许写值,不允许读Object以外的值。
无限定类型通配符:<?>
例如List<?>:表示元素类型未知的List,它的元素可以匹配任何类型。无限定通配符只能读Object类型的值,只能写null类型的值,其他类型都不能读写。
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/public class Test {public static void main(String[] args) {List<String> strings = new ArrayList<>();List<Integer> integers = new ArrayList<>();strings.add("he");integers.add(23);// 1.无界通配符用作形参,实参可以是任意元素// 打印集合:List<?>可以接受所有List元素类型的实参printList(strings);printList(integers);List<?> anyList=new ArrayList<>();// 正确,因为无限定通配符可以写null类型的值。anyList.add(null);// 下面代码会报错,因为无限定通配符只能读Object类型的值,只能写null类型的值,其他类型都不能读写。// anyList.add(23);}/*** * 打印集合:List<?>可以接受所有List元素类型的实参。Collection<?>可以接受任何类型任何元素类型的集合* @param c 集合元素*/public static void printList(List<?> c) {for (Object e : c) {System.out.println(e);}}}
上界类型通配符:List<? extends 指定类型>
表示继承自T的任何类型,这里上界指的就是T。它主要用于写入数据的场景。
上界类型通配符只允许读值,不允许写null以外的值。
tip:Number是·Integer的父类:

public static void main(String[] args) {List<String> strings = new ArrayList<>();List<Integer> integers = new ArrayList<>();strings.add("he");integers.add(23);// 上界通配符可以接受继承于T的类,即T的子类printNumbers(integers);// 下面会报错,因为上界通配符,元素类型只能是Number的子类// printNumbers(strings);}/*** 上界通配符可以接受继承于T的类,即T的子类* @param list*/public static void printNumbers(List<? extends Number> list) {list.get(0);// 下面会报错,因为上界类型通配符只允许读值,不允许写null以外值。for (Number number : list) {System.out.println(number);}}
下界类型通配符:List<? super 指定类型>
表示子类是T的任何类型,这里下界指的就是T。它主要用于读取数据的场景。
下界类型通配符只允许写值,不允许读Object以外的值。
public static void main(String[] args) {List<String> strings = new ArrayList<>();List<Integer> integers = new ArrayList<>();strings.add("he");integers.add(23);addNumbers(integers);printList(integers);// 下面会报错,因为上界通配符,元素类型只能是Number的子类// printNumbers(strings);}/*** * 下界通配符可以接受实现了Integer接口的类,即Integer的父类* @param list*/public static void addNumbers(List<? super Integer> list) {list.add(1);list.add(2);list.add(3);// 正确。因为下界类型通配符允许写值Object object=list.get(0);// 下面会报错,因为下界类型通配符只允许写值,不允许读Object以外类型的值。// Number number=list.get(0);}
8.4 可变参数
(int... a)是将所有int参数封装到a数组里。

注意可变参数要放在后面。例如(int a,int... b)正确,(int... a,int b)会报错。

8.5 知识加油站
8.5.1 泛型的向上转型
泛型类或接口可以向上转型为父类,泛型符号不能向上转型。
泛型向上转型指的是将一个泛型对象转换为其父类类型或者接口类型的过程。这个过程实际上是将泛型对象的类型参数擦除,重新赋值为其父类或接口类型。
- 泛型类或接口可以向上转型:ArrayList<T>可以向上转型为List<T>
ArrayList<Integer> arrayList = new ArrayList<>(); // 向上转型为 List<Integer> List<Integer> list = arrayList; - 泛型符号不能向上转型:ArrayList<Integer>泛型不可以向上转化为ArrayList<Number>。因为ArrayList<Number>接收ArrayList<float>,但ArrayList< Integer>不可以接收ArrayList< Float>,不能转回来
ArrayList<Integer> integerList = new ArrayList<>(); // 编译错误:不能将 ArrayList<Integer> 向上转型为 ArrayList<Number> // ArrayList<Number> numberList = integerList;
除了向上转型,也有向下转型。
向下转型:
向下转型和向上转型类似,指的是将一个父类类型的对象转换为子类类型的过程。这种转换需要进行类型检查,确保转换是安全的。
示例:
List<Integer> list = new ArrayList<>();
ArrayList<Integer> arrayList = (ArrayList<Integer>) list; // 向下转型为 ArrayList<Integer>
8.5.2 泛型擦除
泛型擦除:java的泛型是伪泛型,这是因为java在编译期间,所有的泛型类型都会被擦掉,并转换为普通类型。
泛型擦除:java的泛型是伪泛型,这是因为java在编译期间,所有的泛型类型都会被擦掉,并转换为普通类型。
泛型擦除的主要目的是为了向低版本兼容,因为Java泛型是在JDK 1.5之后才引入的特性,为了保证旧有的代码能正常运行,Java编译器采用了泛型擦除来兼容之前的代码。
为什么要有泛型,而不是使用Object类?
因为泛型是在编译时泛型擦除和替换实际类型的,而使用Object类会很麻烦,需要经常强制转换。
例如List集合里,如果直接声明存Object类的话,存的时候还好,可以通过多态机制直接向上转型,而取的时候就麻烦了,要强转Object类为String等对象,然后才能访问该对象的成员;而且你不知道实际元素到底是String类型还是Integer等其他类型,还要通过i instanceof String判断类型,就更麻烦了。
这也是泛型的优点:
- 防止运行时报错:可以在编译时检查类型安全,防止在程序运行期间出现BUG。
- 隐式转换:所有的强制转换都是自动和隐式的,可以提高代码的重用率。
编译时安全检查:
Java在1.5版本中引入了泛型,在没有泛型之前,每次从集合中读取对象都必须进行类型转换,而这么做带来的结果就是:如果有人不小心插入了类型错误的对象,那么在运行时转换处理阶段就会出错。
在提出泛型之后,我们可以告诉编译器集合中接受哪些对象类型。编译器会自动的为你的插入进行转化,并在编译时告知是否插入了类型错误的对象。这使程序变得更加安全更加清楚
九、JDK8新特性
9.1 基本介绍
Java8是一个拥有丰富特性的版本,新增了很多特性,这里着重介绍几点:
- Lambda表达式:Lambda表达式可以被视为一个对象,必须有上下文环境,作用是实现单方法的接口。该特性可以将功能视为方法参数,或者将代码视为数据。上下文环境意思是能证明它是对象,例如让它处在方法或类的实参里,或者赋值给对象引用。
- 省略情况:形参类型、返回类型可以省略,单参数能省略小括号,单语句能省略return、分号和大括号(全省略或全不省略)
- 方法引用:引用已存在的Lambda表达式,达到相同的效果。引用已有Java类或对象(实例)的静态方法、实例方法、对象方法(System.out::println;)、构造器方法。可以与Lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 接口默认方法:允许在接口中定义默认方法,默认方法必须使用default修饰。默认方法是接口中有方法体的方法,用于向已有的接口添加新的功能,而无需破坏现有的实现。实现类可以直接调用默认方法,也可以重写默认方法。
- Stream API:新添加的Stream API(java.util.stream)支持对元素流进行函数式操作。Stream API 集成在 Collections API 中,可以对集合进行批量操作(stream流的生成、操作、收集),例如filter()过滤、distinct()去重、map()加工、sorted()排序等操作。
- Date Time API新增LocalDate、LocalTime、DateTimeFormatter等类:加强对日期与时间的处理。LocalDate、LocalTime可以获取本地时间。线程安全的DateTimeFormatter代替线程不安全的SimpleDateFormat,用于将日期和字符串之间格式转换。
- HashMap底层引入红黑树:之前版本HashMap底层是“数组+链表”,当头插法的value链表长度大于等于8时,链表会转为红黑树,红黑树查询性能稳定O(logn),是近似平衡二叉树,层数最高2logn。
- ConcurrentHashMap降低锁的粒度:JDK1.8之前采用分段锁,锁粒度是分段segment,JDK1.8采用synchronized+CAS,锁粒度是槽(头节点)
- CompletableFuture:是Future的实现类,JDK8引入,用于异步编排。
- JVM方法区的实现方式由永久代改为元空间:元空间属于本地内存,由操作系统直接管理,不再受JVM管理。同时内存空间可以自动扩容,避免内存溢出。默认情况下元空间可以无限使用本地内存,也可以通过-XX:MetaspaceSize限制内存大小。
JVM内存模型:
什么是JVM的内存模型?详细阐述Java中局部变量、常量、类名等信息在JVM中的存储位置_jvm中主要用于存储类的元数据(类型信息(类的描述信息 类的元数据))、静态变量、常-CSDN博客
9.2 Lambda表达式
Lambda 表达式是 Java 8 引入的一种新特性,主要用于实现单方法的接口,符合函数式思想。
函数式思想:
在数学中,函数是一套计算方案,包含输入量和输出量,即“拿数据做操作”。
面向对象思想强调通过对象的形式来完成任务,而函数式思想则尽量忽略面向对象的复杂语法,强调“做什么”,而不是“以什么形式去做”。
Lambda表达式正是函数式思想的体现。它用来实现单方法接口的方法逻辑,实现过程中的参数可以省略类型(因为类型已经在接口里声明过了),单个表达式时可以省略分号和大括号(因为只有单个语句,不用分号分割也不会有歧义)。
Lambda表达式实际是一个对象,形式是一个方法的逻辑:():{}。
例如前面TreeSet那块有提到过:
// 匿名内部类形式TreeSet<Dog> dogs = new TreeSet<>(new Comparator<Dog>() {@Overridepublic int compare(Dog a, Dog b) {return a.weight - b.weight;}});
可以用Lambda表达式简化成:
// Lambda表达式形式
TreeSet<Dog> dogs = new TreeSet<>((a, b) -> a.weight - b.weight);Lambda和匿名内部类区别:
- 接口:Lambda只能是接口,匿名内部类可以是接口、抽象类、具体类。
- 方法:Lambda只能单方法,匿名内部类可以多方法。
- 原理:Lambda编译后字节码在运行时动态生成,匿名内部类编译后生成一个字节码文件。
基本语法:
(参数列表) -> 单个表达式
或
(参数列表) -> { 表达式1;表达式2; }
可省略内容:
- 形参类型、返回类型可以省略;
- 单参数能省略小括号;
- 单语句能省略return、分号和大括号(全省略或全不省略)
代码示例:
- 形参类型、返回类型可以省略。毕竟接口里也声明了类型,类型必须要么都写要么都省略。例如:
public class Demo {public static void main(String[] args) {// 使用Lambda表达式前,需要再创建一个Dog实现类,然后创建对象传入fun()方法// 使用Lambda表达式后,直接一行代码就解决了,Lambda表达式本身是实现了add()方法逻辑的Dog对象// Lambda形参类型、返回类型可以省略fun((a,b)->a+b);}public static void fun(Dog d){d.add(1,4);}
}/*** @Author: vince* @CreateTime: 2024/06/13* @Description: 单方法接口* @Version: 1.0*/
public interface Dog {/*** 只能有一个方法* @param a* @param b* @return int*/public int add(int a,int b);
}9.3 Stream流
9.3.1 基本介绍
Stream 流是 Java 8 引入的一项新特性,用于对集合进行函数式编程风格的操作。它允许我们以声明性方式对数据进行过滤、加工、遍历、排序等操作,而不是以命令式方式逐个操作元素。
特点:
- 声明式编程:使用流操作表达数据处理的意图,而不是具体的实现。声明式编程强调“做什么”而不是“怎么做”。在声明式编程中,程序员专注于描述要完成的任务或问题,而不是描述具体的实现步骤。Stream流把复杂啰嗦的代码改成一串简洁的代码,符合声明式编程。
- 链式操作:流操作可以链式调用,使代码更加简洁和易读。链式操作是利用运算符进行的连续运算(操作),如连续的赋值操作,而非拆成多条语句一个个加。例如stringBuilder.append(1).append(2);是链式操作,而stringBuilder.append("a");stringBuilder.append("b");不是链式操作。
- 惰性求值:流操作是惰性求值的,即只有在终端操作才会执行实际计算,map等中间操作不会直接计算求值。
- 并行处理:遍历的每一层之间是并发处理的,性能高。
常用方法:
生成操作:生成一个流
- Stream.of(T... values):通过提供的值创建一个流。
- Stream.ofNullable(T t):通过单个值创建一个包含该值的流或一个空流。
- Arrays.stream(T[] array):通过数组创建一个流。
- Collection.stream():通过集合创建一个顺序流。
- Collection.parallelStream():通过集合创建一个并行流。
- Stream.generate(Supplier<T> s):生成一个无限流,元素由提供的 Supplier 生成。
- Stream.iterate(T seed, UnaryOperator<T> f):生成一个无限流,初始元素为 seed,后续元素由一元运算符生成。
中间操作:中间操作返回一个新的流,可以链式调用多个中间操作。
- filter(Predicate predicate):过滤元素
- map(Function<T, R> mapper):加工,每个元素处理后返回一个新的元素。
- map和filter区分:
filter是满足条件的留下,是对原数组的过滤;map则是对原数组的加工,映射成一对一映射的新数组。
- map和filter区分:
- mapToInt(ToIntFunction<? super T> mapper):返回一个 IntStream,除常规流式操作外,还可以取和、平均数等Integer的操作;
- concat():连接
- skip(long n):跳过n个元素
- distinct():去重
- sorted(比较器):排序
- limit(long maxSize):只截取前maxSize个元素
终端操作:终端操作触发流的计算,并返回一个结果或副作用。
- forEach(Consumer action):对每个元素执行操作
- collect(Collector<T, A, R> collector):收集流的元素到一个集合或其他类型
- count():计算流中的元素数量
代码示例:
先获取List的stream流,给集合中每个元素+2,然后升序排序、过滤只保留大于20的元素,最后收集成List类型的集合:
/*** @Author: vince* @CreateTime: 2024/05/13* @Description: 测试类* @Version: 1.0*/
public class Test {public static void main(String[] args) {List<Integer> arrayList = new ArrayList<>();arrayList.add(10);arrayList.add(20);arrayList.add(30);arrayList.add(40);arrayList.add(50);// 使用 Stream API 给每个元素加 2 并生成新的列表System.out.println("使用 Stream API 遍历并修改元素:");List<Integer> modifiedList = arrayList.stream().map(num -> num + 2).sorted().filter(num -> num > 20).collect(Collectors.toList());// 打印修改后的列表System.out.println(modifiedList);}
}
9.3.2 生成
生成操作:生成一个流
- Stream.of(T... values):通过提供的值创建一个流。
- Stream.ofNullable(T t):通过单个值创建一个包含该值的流或一个空流。
- Arrays.stream(T[] array):通过数组创建一个流。
- Collection.stream():通过集合创建一个顺序流。
- Collection.parallelStream():通过集合创建一个并行流。
- Stream.generate(Supplier<T> s):生成一个无限流,元素由提供的 Supplier 生成。
- Stream.iterate(T seed, UnaryOperator<T> f):生成一个无限流,初始元素为 seed,后续元素由一元运算符生成。
代码示例:
/*** 示例代码展示如何生成 Stream 流*/
public class StreamGeneration {public static void main(String[] args) {// Collection 体系:可以便用默认方法 stream() 生成流List<String> list = new ArrayList<String>();Stream<String> listStream = list.stream();Set<String> set = new HashSet<String>();Stream<String> setStream = set.stream();// Map 体系:间接的生成流Map<String, Integer> map = new HashMap<String, Integer>();Stream<String> keyStream = map.keySet().stream();Stream<Integer> valueStream = map.values().stream();Stream<Map.Entry<String, Integer>> entryStream = map.entrySet().stream();// 数组体系:可以通过 Stream 接口的静态方法 of(T... values) 生成流String[] strArray = {"hello", "world", "java"};Stream<String> strArrayStream = Stream.of(strArray);Stream<String> strArrayStream2 = Stream.of("hello", "world", "java");Stream<Integer> intStream = Stream.of(10, 20, 30);}
}
9.3.3 中间操作
中间操作:中间操作返回一个新的流,可以链式调用多个中间操作。
- filter(Predicate predicate):过滤元素
- map(Function<T, R> mapper):加工,每个元素处理后返回一个新的元素。
- map和filter区分:
filter是满足条件的留下,是对原数组的过滤;map则是对原数组的加工,映射成一对一映射的新数组。
- map和filter区分:
- mapToInt(ToIntFunction<? super T> mapper):返回一个 IntStream,除常规流式操作外,还可以取和、平均数等Integer的操作;
- concat():连接
- skip(long n):跳过n个元素
- distinct():去重
- sorted(比较器):排序
- limit(long maxSize):只截取前maxSize个元素
filter:过滤
filter 方法用于通过设置的条件过滤出元素。以下代码片段使用 filter 方法过滤掉空字符串,打印非空字符串。filter 的参数是 Lambda,Lambda 参数是 list 的每个元素,返回值是 Boolean,为 true 时留下。
List<String> list = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
// forEach 终结后,原 list 不变,处理后的 list 遍历输出
list.stream().filter(item -> !item.isEmpty()).forEach(System.out::println);

skip & limit:跳过、限制
List<String> list = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");// 需求: 跳过 2 个元素,把剩下的元素中前 2 个在控制台输出list.stream().skip(2).limit(2).forEach(System.out::println);
concat 和 distinct:连接和去重
Stream<String> s1 = Stream.of("a", "b", "c");
Stream<String> s2 = Stream.of("b", "c", "d");
Stream.concat(s1, s2).distinct().forEach(System.out::println);

sorted 比较器:
sorted() 方法返回由此流的元素组成的流,根据自然顺序排序。
示例:按字母序排序(sorted()的参数可省略,因为默认就是按字母序排序)
List<String> list = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");// 按字母序排序(默认)// forEach 终结后,原 list 不变,处理后的 list 遍历输出list = list.stream().sorted((item1, item2) -> {return item1.compareTo(item2);}).collect(Collectors.toList());System.out.println(list);![]()
map
中间操作 map() 用法和 filter 类似,map 的参数是 Lambda,Lambda 参数是 list 的每个元素,返回值是加工后的 list 元素。
List<String> list = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
// collect 收集后原 list 不变,处理后的 list 收集成返回值
list = list.stream().map(item -> item.toUpperCase()).collect(Collectors.toList());
System.out.println(list);
![]()
mapToInt
mapToInt 返回一个 IntStream,其中包含将给定函数应用于此流的元素的结果。IntStream 是由 Integer 元素组成的流,可以取和、平均数、排序、skip、limit、count、forEach 等。
List<String> list = Arrays.asList("10", "20", "30");// 输出每个元素list.stream().mapToInt(Integer::parseInt).forEach(System.out::println);// 计算元素的总和int sum = list.stream().mapToInt(Integer::parseInt).sum();System.out.println(sum);
9.3.4 终结和收集
- forEach(Consumer action):对每个元素执行操作
- collect(Collector<T, A, R> collector):收集流的元素到一个集合或其他类型
- count():计算流中的元素数量
count
count() 方法返回此流中的元素数量。
List<String> list = Arrays.asList("10", "20", "30");
long count = list.stream().mapToInt(Integer::parseInt).count();
System.out.println(count); // 输出 3
forEach
forEach(IntConsumer action) 方法对此流的每个元素执行操作。
List<String> list = Arrays.asList("10", "20", "30");
list.stream().mapToInt(Integer::parseInt).forEach(value -> System.out.println(value));
collect
- collect(Collector<T, A, R> collector):收集流的元素到一个集合或其他类型
- public static <T> Collector toList(): 把元素收集到 List 集合中
- public static <T> Collector toSet(): 把元素收集到 Set 集合中
- public static Collector toMap(Function keyMapper, Function valueMapper): 把元素收集到 Map 集合中
List<String> list = new ArrayList<>();list.add("123");list.add("4567");// 1.过滤只保留长度为3的字符串,收集成List<String>类型List<String> ansList = list.stream().filter(item -> item.length() == 3).collect(Collectors.toList());System.out.println(ansList);// 2.收集成List<Integer>类型List<Integer> ansList1 = list.stream().map(Integer::parseInt).collect(Collectors.toList());System.out.println(ansList1);// 3.收集成Set<Integer>类型Set<Integer> ansList2 = list.stream().map(Integer::parseInt).collect(Collectors.toSet());System.out.println(ansList2);// 4.收集成Map<String,Integer>类型,key是字符串,value是长度Map<String, Integer> stringSizeMap = list.stream().collect(Collectors.toMap(item -> item, item -> item.length()));System.out.println(stringSizeMap);// 5.收集成String类型,按逗号分割String ansString = list.stream().collect(Collectors.joining(","));System.out.println(ansString);
9.3 函数式接口
9.3.1 基本介绍
函数式接口是指仅包含一个抽象方法的接口,可以使用 Lambda 表达式或方法引用来创建该接口的实例。Java 8 引入了函数式接口,并在 java.util.function 包中提供了许多预定义的函数式接口,例如 Function、Supplier、Consumer、Predicate 等。
函数式接口:有且仅有一个抽象方法的接口。 Java中函数式编程体现就是Lambda表达式。
函数式接口注解:@FunctionalInterface
如果方法的返回值是函数式接口,可以使用Lambda表达式作为结果返回。
格式: 函数式接口对象作为一个方法的形参,实参是Lambda表达式。
常见的函数式接口:
事实上,JDK自带一些函数式接口:函数式接口Supplier中get获取有返回值的数据,Predicate中test返回boolean型数据,Consumer中accept无返回值数据操作。
| 接口 | 方法 | 作用 | 示例 |
| Supplier | get(),返回各类型的数据 | 获取 | 返回数组最大值 |
| Function | apply(),返回各类型数据 | 转换 | 数字字符串转换 |
| Predicate | test(),返回boolean型数据 | 判断 | 判断数字是否大于5 |
| Consumer | accept(),无返回值 | 操作 | 翻转字符串 |
9.3.2 生产者接口Supplier

作用:获取到生产出的数据
Supplier译作生产者,生产的数据类型由泛型参数T指定。
示例:
例如生产者接口,创建一个方法,获取数组的最大值,实际的获取逻辑由Lambda表达式确认:
public class Test {public static void main(String[] args) {// 定义一个int数组int[] arr = {19, 50, 28, 37, 46};// 获取数组中的最大值int maxValue = getMax(() -> {int max = arr[0];for (int i : arr) {if (i > max) {max = i;}}return max;});// 输出最大值System.out.println("数组中的最大值是: " + maxValue);}/*** 返回一个int数组中的最大值** @param sup Supplier<Integer>函数式接口* @return int数组中的最大值*/private static int getMax(Supplier<Integer> sup) {return sup.get();}}
9.3.3 函数式接口Consumer

作用:对数据进行操作,无返回值。
Consumer是消费型接口,消费的数据类型由泛型指定。
方法:
void | accept(T t) 对给定的参数执行此操作。 | |||
default Consumer<T> | andThen(Consumer<? super T> after) 返回一个组合的 |
代码示例:
两种方式和一种方式消费字符串
public class Test {public static void main(String[] args) {String name = "Hello World";// 使用两种方式消费字符串operatorString(name, str -> System.out.println("转大写:"+str.toUpperCase()), str -> System.out.println("转小写:"+str.toLowerCase()));// 使用一个方式消费字符串operatorString(name, str -> System.out.println("空格替换成下划线:"+str.replace(" ", "_")));}/*** 定义一个方法,用两种方式消费同一个字符串数据,共消费5次* @param name 字符串数据* @param con1 第一个消费者* @param con2 第二个消费者*/private static void operatorString(String name, Consumer<String> con1, Consumer<String> con2) {// 第一个消费者消费一次System.out.println("第一个消费者消费一次");con1.accept(name);// 第二个消费者消费一次System.out.println("第二个消费者消费一次");con2.accept(name);// 第一个消费者组合第二个消费者,再组合第一个消费者,按顺序各消费一次System.out.println("第一个消费者组合第二个消费者,再组合第一个消费者,按顺序各消费一次");con1.andThen(con2).andThen(con1).accept(name);}/*** 定义一个方法,消费一个字符串* @param name 字符串数据* @param con 消费者*/private static void operatorString(String name, Consumer<String> con) {con.accept(name);}}
9.3.4 函数式接口Predicate

Predicate接口用于表示布尔值函数,判断参数是否满足条件。它接受一个参数,并返回一个布尔值。
译作谓词,谓语。
| 方法签名 | 说明 |
|---|---|
| boolean test(T t) | 对给定的参数进行判断(谓词操作)。返回布尔值。 |
| default Predicate<T> and(Predicate<? super T> other) | 返回一个组合的 Predicate,表示逻辑与(AND)操作。 |
| default Predicate<T> negate() | 返回一个表示逻辑非(NOT)操作的 Predicate。 |
| default Predicate<T> or(Predicate<? super T> other) | 返回一个组合的 Predicate,表示逻辑或(OR)操作。 |
方法的形参Predicate,接受的实参是Lambda参数。
public class Test {public static void main(String[] args) {// 测试字符串长度是否在5到100之间// falseboolean result = checkString("hello",s -> s.length() > 5,s -> s.length() < 100);System.out.println(result);// 测试字符串是否长度不等于5// falseSystem.out.println(negateCheck("hello",s->s.length()==5));}/*** 检查字符串是否满足两个谓词的逻辑与条件* @param s 要检查的字符串* @param p1 第一个谓词* @param p2 第二个谓词* @return 如果字符串满足两个谓词的逻辑与条件,返回true;否则返回false*/private static boolean checkString(String s, Predicate<String> p1, Predicate<String> p2) {return p1.and(p2).test(s);}/*** 检查字符串是否不满足谓词条件* @param s 要检查的字符串* @param p 谓词* @return 如果字符串不满足谓词条件,返回true;否则返回false*/private static boolean negateCheck(String s, Predicate<String> p) {return p.negate().test(s);}
}
9.4 方法引用
9.4.1 概念
方法引用跟Lambda类似,都可以根据上下文推导。
格式:
引用类::不带括号的方法名9.4.2 引用实例方法
还是以前面TreeSet的代码示例为例:
/*** @Author: vince* @CreateTime: 2024/07/02* @Description: 狗类:按比较器排序时不需要再实现Comperable<>* @Version: 1.0*/
public class Dog {int weight;String name;public Dog(int weight, String name) {this.weight = weight;this.name = name;}@Overridepublic String toString() {return "Dog{" +"weight=" + weight +", name='" + name + '\'' +'}';}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}Dog dog = (Dog) o;return weight == dog.weight && Objects.equals(name, dog.name);}@Overridepublic int hashCode() {return Objects.hash(weight, name);}
}/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/public class Test {public static void main(String[] args) {// 使用Lambda表达式TreeSet<Dog> dogsLambda = new TreeSet<>((a, b) -> a.weight - b.weight);// 1.使用方法引用,引用compareDogsByWeight()方法TreeSet<Dog> dogsMethodRef = new TreeSet<>(Test::compareDogsByWeight);// 添加一些示例数据dogsLambda.add(new Dog(10, "旺财"));dogsLambda.add(new Dog(5, "小黑"));dogsLambda.add(new Dog(15, "小白"));dogsMethodRef.add(new Dog(10, "旺财"));dogsMethodRef.add(new Dog(5, "小黑"));dogsMethodRef.add(new Dog(15, "小白"));// 打印排序结果System.out.println("使用Lambda表达式打印结果:");dogsLambda.forEach(dog->{System.out.println(dog);});System.out.println("2.使用方法引用,引用PrintStream类的println方法:");dogsMethodRef.forEach(System.out::println);}/*** 比较两个Dog对象的体重* @param a 第一个Dog对象* @param b 第二个Dog对象* @return 返回体重差*/public static int compareDogsByWeight(Dog a, Dog b) {return a.weight - b.weight;}
}
9.4.4 引用构造器
一些场景下,我们需要在使用时才确定创建对象的逻辑,这时就可以引用构造器。
格式:
类名::new示例:
例如我们有个学生类:
/*** Student 类*/
class Student {private String name;private int age;public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public int getAge() {return age;}
}我们想要在使用时再确认对象的创建逻辑,就需要创建一个StudentBuilder接口,再使用时通过Lambda或者方法引用对它进行实现:
/*** StudentBuilder 接口*/
@FunctionalInterface
interface StudentBuilder {Student build(String name, int age);
}/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/public class Test {public static void main(String[] args) {// 使用 Lambda 表达式builderLinQinXia((name, age) -> new Student(name, age));builderZhangXueYou((name, age) -> new Student(name, age));// 使用构造方法引用builderLinQinXia(Student::new);builderZhangXueYou(Student::new);}/*** 使用 StudentBuilder 创建 Student 对象,对象的name是林青霞* @param sb StudentBuilder 接口的实例*/private static void builderLinQinXia(StudentBuilder sb) {Student s = sb.build("林青霞", 30);System.out.println(s.getName() + " " + s.getAge());}/*** 使用 StudentBuilder 创建 Student 对象,对象的name是张学友* @param sb StudentBuilder 接口的实例*/private static void builderZhangXueYou(StudentBuilder sb) {Student s = sb.build("张学友", 26);System.out.println(s.getName() + " " + s.getAge());}
}
9.5 接口组成更新
java8后加入了默认方法、静态方法。java9后加入了私有方法。
9.5.1 接口默认方法
之前4.3.2小节有提到过,接口中的方法会被隐式的指定为 public abstract方法,抽象方法不能有实际的内容。但是有一些业务场景,我们需要在接口中扩展一些有业务逻辑的方法,又不想直接改成抽象类(因为抽象类只能单继承),这种情况下,JDK8就扩展了接口的默认方法,需要用defaule关键字修饰方法。
格式:
default 返回值 方法名(参数) {...}特点:
- 默认方法可以有方法体
- 默认方法可被接口的实现类对象调用。
- 默认方法不是抽象方法,实现类可以重写,也可以不重写,同名冲突时必须重写(某个类实现了多个包含默认方法fun()的接口,为了防止冲突,此时实现类必须重写这个类)。
示例:
/*** @Author: vince* @CreateTime: 2024/07/09* @Description: 接口* @Version: 1.0*/
public interface MyInterface {/*** 抽象方法,默认public abstract修饰*/void abstractMethod();/*** 默认方法,使用default修饰*/default void defaultMethod() {System.out.println("这是接口的默认方法");}
}9.5.2 接口静态方法
在 Java 8 中,引入了接口静态方法。接口静态方法与类静态方法类似,但它们属于接口本身,而不是接口的实现类。静态方法常用于在接口中提供静态工具方法,帮助操作或处理与接口相关的数据。
格式:
与类的静态方法一致:
static 返回类型 方法名(参数列表) {// 方法体}
特点:
- 命名冲突时要重写:因为Java是单继承多实现的,所以存在一个类实现多个接口的情况。如果一个类同时实现了多个接口,并且这些接口都有相同签名的默认方法,则必须在实现类中重写该方法以解决冲突。例如类A实现了有同名静态方法的接口B、C,则A的对象分不清调用哪个接口的方法。
-
扩展接口功能:默认方法允许在不破坏现有实现的情况下扩展接口功能,对现有功能影响较小,符合设计模式中的开闭原则。
-
接口中静态方法跟类的静态方法,属于“类方法”,先于对象产生,所以只能被接口名调用,不能被实现类对象调用。
示例:
public interface MyInterface {// 静态方法static void staticMethod() {System.out.println("这是接口的静态方法");}
}
9.5.3 知识加油站:JDK9接口私有方法
之前4.3.2小节有提到过,接口中的方法会被隐式的指定为 public abstract方法。为了将接口中多个默认或静态方法中的共性方法抽离出来,JDK9引入了接口私有方法。
接口私有方法只能在接口内部,被接口静态方法或者接口默认方法调用,不能在接口外部或实现类中调用。
格式:
private 返回类型 方法名(参数列表) {// 方法体
}
或者:
private static 返回类型 方法名(参数列表) {// 方法体
}
特点:
- 接口私有方法可以是普通私有方法,也可以是静态私有方法;
- 只能被接口内静态、默认方法调用;
- 必须JDK9及以上版本;
示例:
/*** @Author: vince* @CreateTime: 2024/07/09* @Description: 动物接口* @Version: 1.0*/
public interface Animal {default void eat() {System.out.println("动物在吃东西");privateSoundMethod();}/*** 私有实例方法:发出声音*/private void privateSoundMethod() {System.out.println("这是私有实例方法,接口内私有、静态、默认方法都可以调用它:发出声音");}/*** 静态方法*/static void staticMethod() {System.out.println("静态方法调用私有静态方法");privateStaticMethod();}/*** 私有静态方法*/private static void privateStaticMethod() {System.out.println("这是私有静态方法,它只能被接口中的静态方法调用");}
}
/*** @Author: vince* @CreateTime: 2024/07/02* @Description: 狗类:可以重写默认方法,但这里我们不需要重写* @Version: 1.0*/
public class Dog implements Animal {public static void main(String[] args) {Dog dog = new Dog();dog.eat();Animal.staticMethod();}
}运行结果:
静态方法调用私有静态方法
这是私有静态方法,它只能被接口中的静态方法调用
动物在吃东西
这是私有实例方法,接口内私有、静态、默认方法都可以调用它:发出声音十、I/O流
10.1 基本介绍
什么是I/O流?
I/O流(Input/Output Stream),即输入(Input)和输出(Output)流,是用于处理输入和输出操作的数据流。在Java中,一般用IO流写一个文件输出到操作系统中,或者从操作系统中输入一个文件进行读取。
IO流分类:
按数据流向:
- 输入流:读数据。
- 输出流:写数据。
按数据类型:
- 字节流:它处理单元为1个字节(byte),操作字节和字节数组,存储的是二进制文件。
- 使用场景:在Java中,一般用IO流写一个文件输出到操作系统中,或者从操作系统中输入一个文件进行读取。如果是音频文件、图片、歌曲,就用字节流(1byte = 8位)。
- 字符流:它处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的。
- 使用场景:如果是关系到中文(文本)的,用字符流(1Unicode = 2字节 = 16位);
字节流和和字符流继承关系:


输入字节流 (InputStream)
-
FileInputStream:基本的文件输入流,用于读取字节文件(如图片、视频)中的数据。
-
FilterInputStream:过滤输入流,是所有过滤输入流的父类。用于对数据进行解密、校验、转换、过滤、缓存。因为它是抽象类,所以我们一般用它的子类:
-
BufferedInputStream:相比于FileInputStream,它的读取性能会高很多。因为它多了一个缓冲区数组(在内存中),在第一次调用read()读取数据时,他会将数据尽可能多的填满缓冲区,这样再次read()时会优先从缓冲区中读,而不用直接在磁盘中读。我们知道内存读写性能是远高于磁盘的,所以它更快。默认缓冲区大小是8192字节,即8KB,超过这个容量就必须在磁盘读取了。
-
DataInputStream:与相比于FileInputStream,它的读取性能会高很多。因为它直接提供了读取Java中基本数据类型的方法,如 readInt()、readDouble()、readUTF() 等,而不需要额外的解析步骤。
-
SocketInputStream:网络输入流。
-
输出字节流 (OutputStream)
-
FileOutputStream:基本的文件输出流,用于将数据写入字节文件(如图片、视频)。
-
FilterOutputStream:过滤输出流,是所有过滤输出流的父类,提供了基本的输出流功能。用于压缩数据、加密数据等。因为它是抽象类,所以我们一般用它的子类:
-
BufferedOutputStream:为输出流提供缓冲功能,提高写入效率。每次写入数据时,先写进缓冲区,缓冲区满了会自动刷新写入到磁盘中,也可以手动调用flash()方法刷新。
-
DataOutputStream:性能高,因为它直接提供了写入Java中基本数据类型的方法,如 wirteInt(),而不需要额外的转换步骤。
-
SocketOutputStream;
-
字符流
字符流是以字符为单位处理数据的流,分为输入字符流和输出字符流。
输入字符流 (Reader)
-
InputStreamReader:输入流读取类,用于将字节流转换为字符流再读取字符数据。使用系统默认字符编码。
-
FileReader:文件读取类,用于直接从文件中读取字符数据。可以指定字符编码来解码字节流。
-
-
BufferedReader:为字符输入流提供缓冲功能,提高读取效率。
输出字符流 (Writer)
-
OutputStreamWriter:将字符流转换为字节流。
-
FileWriter:用于将字符数据写入文件。
-
-
BufferedWriter:为字符输出流提供缓冲功能,提高写入效率。
10.2 File类
File类是用于表示文件和目录路径名的类。
注意:File类封装的不是真正的文件,只是路径。所以File类可以对文件进行创建、删除、重命名、修改时间、文件大小等操作,但不能对文件里的数据进行读取或者写入,它一般作为输入输出流的构造参数,指明文件的路径。
创建文件示例:
import java.io.File;
import java.io.IOException;public class Demo {public static void main(String[] args) throws IOException {File f=new File("D:\\1\\2.txt");//只创建已存在文件夹“D://1”下的2.txt。若“D://1”不存在,报错IOException: 系统找不到指定的路径。System.out.println(f.createNewFile()); //true,当目标位置已存在同名文件则创建失败输出false}
}文件默认路径:
在当前包内IO流,使用File类创建文件时
new File("1.txt");默认存的位置是在项目文件夹下,而不是包文件夹下。
关于路径斜杠和反斜杠:
路径斜杠可以是//,/,\\,不能是\,因为它是转义符。
正斜杠“/”和“//”都可以,反斜杠必须“\\”,因为“\”会ASCII转义,“\\”在字符串里才是“\”。
File file = new File("D://1//1.txt");File file1 = new File("D:/1/2.txt");File file2 = new File("D:\\1\\3.txt"); // File file3 = new File("D:\1\4.txt"); //这样会报错,单个反斜杠会进行转义System.out.println(file.createNewFile()); //trueSystem.out.println(file1.createNewFile()); //trueSystem.out.println(file2.createNewFile()); //true // System.out.println(file3.createNewFile()); //false查看当前路径:
System.out.println(System.getProperty("user.dir")); //D:\workspace\java\test
常用方法:
- boolean createNewFile(): 当且仅当具有该名称的文件尚不存在时,原子地(保证线程安全)创建一个由该抽象路径名命名的新空文件。抽象路径名指的是构造 File 对象时传递的路径名字符串。创建File对象时,构造参数的路径并不一定真实存在,可能是虚拟的、等待通过createNewFile等方法进行创建。
- boolean mkdir() :创建目录。如果父目录不存在,则不会创建目录,并返回 false。
- boolean mkdirs(): 创建目录。如果父目录不存在,它会一并创建。
- boolean delete(): 删除文件或目录。成功删除文件或目录时返回 true,否则返回 false。注意如果要删除目录,该目录必须为空,否则会返回false。
- boolean isDirectory(): 测试File是否为目录。
- boolean isFile(): 测试File是否为文件。
- boolean exists(): 测试File是否真实存在。
- String getAbsolutePath(): 返回绝对路径名字符串。
- String getPath(): 将抽象路径名。也就是构造 File 对象时传递的路径名字符串,可能是绝对路径,也可能是相对路径。
- String getName(): 返回由此抽象路径名表示的文件或目录的名称。
- String[] list(): 返回对应目录下所有文件的文件名数组。
- File[] listFiles(): 返回对应目录下所有文件的File文件数组。
举例:
public static void main(String[] args) {File f = new File("1\\2\\3");// mkdirs()如果父目录不存在,它会一并创建。System.out.println(f.mkdirs());File f1 = new File("1\\2\\3\\4.txt");try {System.out.println(f1.createNewFile());} catch (IOException e) {System.out.println("创建失败" + e);}// listFiles()是路径下的所有文件组成的数组,若f文件会报错File[] f2 = f.listFiles();for (File file : f2) {if (file.isFile()) {System.out.println(file.getName() + "," + file.getPath());}}// 删除// 删除目录时要确保目录下没文件。// f1.delete();// f.delete();}
10.3 字节流的超类
10.3.1 字节输出流OutputStream
概念:
Java中的 InputStream 和 OutputStream 都是 io 包中面向字节操作的顶级抽象类。所有字节流类都是他们的子类。
子类:
- 网络数据传输:SocketOutputStream
- 文件操作:FileOutputStream
- 字节数据操作:DataOutputStream
常用api:
- void close() :关闭此输出流并释放与此流相关联的任何系统资源。
- void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- void write(byte[] b) :将 b.length 字节从指定的字节数组写入此输出流。
- void write(byte[] b, int off, int len) : 从指定的字节数组写入 len 个字节,从偏移 off 开始输出到此输出流。
- abstract void write(int b) :将指定的字节写入此输出流。
10.3.2 字节输入流InputStream
概念:
Java中的 InputStream 和 OutputStream 都是 io 包中面向字节操作的顶级抽象类,关于java同步 io字节流的操作都是基于这两个的。
子类:
- 网络数据传输:SocketInputStream
- 文件操作:FileInputStream
- 字节数据操作:DataInputStream。与相比于FileInputStream,它的读取性能会高很多。因为它直接提供了读取Java中基本数据类型的方法
- 带缓冲区的输入流:BufferedInputStream
常用api:
- abstract int read():从输入流读取数据的下一个字节。
- int read(byte[] b):从输入流读取一些字节数,并将它们存储到缓冲区 b,返回值为长度 。
- int read(byte[] b, int off, int len):从输入流读取最多 len字节的数据到一个字节数组。
10.4 字节文件流
10.4.1 文件输出流FileOutputStream
基本的文件输出流,用于将数据写入字节文件(如图片、视频)。输出流是写数据,把数据输出到文件里。
构造方法:
- FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。
- FileOutputStream(String name):创建文件输出流以指定的名称写入文件
- FileOutputStream(String name, boolean append):创建文件输出流以指定的名称写入文件。append默认是false,即彻底覆盖写入。append为true时是追加写入。
- FileOutputStream(File file, boolean append): 使用文件对象创建文件输出流,并选择是否追加数据。
写操作方法
- void write(int b): 将指定的字节写入输出流。
- void write(byte[] b): 将字节数组 b 写入输出流。
- void write(byte[] b, int off, int len): 将字节数组 b 中从偏移量 off 开始的 len 个字节写入输出流。
关闭方法
- void close(): 关闭文件输出流并释放与此流有关的所有系统资源。
示例,将“abcde” 写入1.txt文件中:
/*** @Author: vince* @CreateTime: 2024/06/27* @Description: 测试类* @Version: 1.0*/public class Test {public static void main(String[] args) {FileOutputStream fos=null;try {fos=new FileOutputStream("D://1.txt");byte[] b ="abcde".getBytes();fos.write(b);fos.close();}catch (IOException e){// 实际开发不建议用e.printStackTrace()打日志,而是logger.error()e.printStackTrace();}finally {// 判空,防止创建流的时候就失败,进入catch中if(fos!=null){try {fos.close();} catch (IOException e) {e.printStackTrace();}}}}
}注意:写数据时的换行符,windows系统下是\r\n,linux的换行是\n,mac换行\r.
可以看到D盘下多了个1.txt,内容是
![]()
10.4.2 文件输入流 FileInputStream
基本的文件输入流,用于读取字节文件(如图片、视频)中的数据。
常用方法:
- FileInputStream(File file):构造方法,创建一个 FileInputStream,它读取从指定File对象的文件。
- FileInputStream(String name):构造方法,创建一个 FileInputStream,它读取从指定文件路径名的文件
- int read():读取一个字节的数据。返回的int是读取字节的个数,如果到达流的末尾,则返回值 -1。
- int read(byte[] b):读取一定字节(0~b.length,具体长度取决于是否读到了末尾)的数据,将其存储在缓冲区数组 b 中。返回读取的字节数,如果没有可用的字节,则返回 -1。
- int read(byte[] b, int off, int len):最多读取 len 个字节的数据到一个字节数组。尝试读取最多 len 个字节的数据到缓冲区 b 中,从 off 位置开始。返回读取的字节数,如果没有可用的字节,则返回 -1。
代码示例:
通过文件输入输出流复制图片
public class Test {/*** 实际开发时不建议throws异常,而是try-catch,finally中关闭流** @param args * @throws IOException IO异常*/public static void main(String[] args) throws IOException {FileInputStream fis=new FileInputStream("D://1.png");FileOutputStream fos=new FileOutputStream("D://2.png");byte []b=new byte[1024];int len=fis.read(b);while(len!=-1){fos.write(b,0,len);len=fis.read(b);}}
}可以看到文件已经复制成功:

扩展
使用maven后可以导入commons-io包,直接通过工具类复制。
使用IOUtils.copy(fis,os)进行流的复制(推荐)
(1)pom.xml添加依赖
<dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version> </dependency>(2)调用工具类方法实现复制
//fis:输入流 //os:输出流 IOUtils.copy(fis,os);参考文章:
JavaWeb基础3——Maven基础&MyBatis
10.5 字节缓冲流(推荐)
特点:
字节缓冲流仅提供缓冲区,真正读写数据还要靠基本字节流对象操作。
字节缓冲流读写数据比基本字节流快很多,因为它有个存在内存中的字节数组,作为缓冲区,读写时先在缓冲区中读写,性能比直接在磁盘中读写快很多。
10.5.1 字节缓冲输出流BufferedOutputStream
BufferedOutputStream:
BufferedOutputStream是一个带缓冲区的输出流,它跟FileOutputStream一样,都继承自OutputStream抽象类。
但与普通的OutputStream相比,BufferedOutputStream在写入数据时使用了一个存在内存中的中间缓冲区。当向BufferedOutputStream写入数据时,数据首先会被写入到缓冲区,而不是直接写入到目标输出流(即最终的目标输出,比如文件、网络连接、控制台)。当缓冲区满了、手动刷新flash()、手动关闭close()时,BufferedOutputStream会将缓冲区中的数据一次性写入到目标输出流中。
这种缓冲机制可以减少实际的物理写操作,从而提高写操作的效率。因为磁盘IO是很慢的,而内存IO是很快的,相比于每次写入一个字节到目标输出流,将多个字节一次性写入会更加高效,磁盘IO次数有效减少。
构造方法
- BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
- BufferedOutputStream(OutputStream out, int size): 创建一个新的缓冲输出流,以将数据写入指定的底层输出流,并具有指定的缓冲区大小。
写入方法
- void write(int b): 将指定的字节写入此缓冲输出流。
- void write(byte[] b, int off, int len): 将字节数组中的指定字节写入此缓冲输出流。
刷新方法
- void flush(): 刷新此缓冲输出流,将任何缓冲的输出字节写出到底层输出流。
关闭方法
- void close(): 关闭此输出流并释放与此流相关联的任何系统资源。在关闭流之前,会刷新它。
构造方法
- BufferedInputStream(InputStream in): 创建一个新的缓冲输入流,以从指定的底层输入流读取数据。
- BufferedInputStream(InputStream in, int size): 创建一个新的缓冲输入流,以从指定的底层输入流读取数据,并具有指定的缓冲区大小。
读取方法
- int read(): 从输入流中读取数据的下一个字节。
- int read(byte[] b, int off, int len): 从输入流中将最多 len 个字节的数据读入一个字节数组。
- int read(byte[] b): 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
跳过和可用
- long skip(long n): 跳过和丢弃输入流中最多 n 个字节的数据。
- int available(): 返回可以不受阻塞地从输入流中读取的剩余字节数。阻塞(Blocking) 是指程序在等待某些操作完成(例如读取数据、写入数据、获取网络响应等)时停止执行其他操作,直到该操作完成。
标记和重置
- void mark(int readlimit): 在输入流中标记当前位置。
- void reset(): 将流重新定位到上次调用 mark 方法时的位置。
- boolean markSupported(): 测试输入流是否支持 mark 和 reset 方法。
关闭
- void close(): 关闭输入流并释放与此流相关联的任何系统资源。
10.5.2 字节缓冲输入流BufferedInputStream
BufferedInputStream是字节缓冲输入流。
相比于FileInputStream,它的读取性能会高很多。因为它多了一个缓冲区数组(在内存中),在第一次调用read()读取数据时,他会将数据尽可能多的填满缓冲区,这样再次read()时会优先从缓冲区中读,而不用直接在磁盘中读。
我们知道内存读写性能是远高于磁盘的,所以它更快。默认缓冲区大小是8192字节,即8KB,超过这个容量就必须在磁盘读取了。
代码示例:使用缓冲流复制图片
public class Test {/*** 实际开发时不建议throws异常,而是try-catch,finally中关闭流** @param args * @throws IOException IO异常*/public static void main(String[] args) throws IOException {BufferedInputStream bis = new BufferedInputStream(new FileInputStream("D://1.png"));BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("D://2.png"));byte[] buffer = new byte[1024];int len;// 读取和写入字节数据while ((len = bis.read(buffer)) != -1) {bos.write(buffer, 0, len);}bis.close();bos.close();}
}可以看到文件已经复制成功:
10.6 字符流
10.6.1 继承关系
字符流的继承关系:
10.6.2 字符流的编码和解码
为什么要用字符流?
因为字节流编码不支持汉字。
计算机底层存储数据都是通过二进制的字节文件存储的,所以我们看到的文件信息都是有多少字节、多少KB、多少MB,文本文件需要设置编码是UTF-8、GBK等类型。


GBK编码,一个汉字占用2个字节。
utf-8编码,一个汉字占用3个字节。
一个英文字符占一个字节,一个汉字占多个字节,因为字节流都是单字节读取,所以字节流在读中文的时候有可能会读到半个中文,造成乱码,所以这就引入了字符流。
字符流对字节文件进行编码和解码:
- 编码:字符输出流将字符编码为字节写入字节文件
- 解码:字符输入流从字节文件解码出字符。
这样可以保证我们写入文件时,写入的格式是字节文件,读取文件时,将字节文件转为字符文件。
字符串的编码解码方法: 字符串的编码和解码是指在不同字符集之间转换字符数据的过程。
- 编码:将字符串转换为字节数组
- 解码:将字节数组转换为字符串。
public static void main(String[] args) throws IOException {String str = "你好";// 编码byte[] bytes = str.getBytes("UTF-8");// 解码String bytesToString = new String(bytes, "UTF-8");System.out.println(bytesToString);// 如果编码设置的不对,设为GBK就会乱码:浣犲ソString bytesToString2 = new String(bytes, "GBK");System.out.println(bytesToString2);}
10.6.3 字符输入输出流
10.6.3.1 字符输出流OutputStreamWriter
OutputStreamWriter:将字符编码为字节,再写入字节文件。
OutputStreamWriter 是 Java 中一个桥接器类,用于将字符流转换为字节流。它使用指定的字符编码将字符写入字节流。它可以用于写入文件、网络流等。
桥接器类:指充当中介,用于连接或转换两种不兼容类型的类
构造方法:构造参数都有OutputStream,因为要讲字符流编码成字节流OutputStream
- OutputStreamWriter(OutputStream out): 创建一个使用默认字符编码的 OutputStreamWriter。
- OutputStreamWriter(OutputStream out, String charsetName): 创建一个使用指定字符编码的 OutputStreamWriter。
- OutputStreamWriter(OutputStream out, Charset cs): 创建一个使用指定 Charset 的 OutputStreamWriter。
- OutputStreamWriter(OutputStream out, CharsetEncoder enc): 创建一个使用指定 CharsetEncoder 的 OutputStreamWriter。
写入方法
- void write(int c): 写入单个字符。
- void write(char[] cbuf, int off, int len): 写入字符数组的一部分。
- void write(char[] cbuf): 写入字符数组。
- void write(String str, int off, int len): 写入字符串的一部分。
- void write(String str): 写入整个字符串。
代码示例:
/*** 实际开发时不建议throws异常,而是try-catch,finally中关闭流** @param args * @throws IOException IO异常*/public static void main(String[] args) throws IOException {// 创建文件输出流FileOutputStream fos = new FileOutputStream("D://output.txt");// 创建使用 UTF-8 编码的 OutputStreamWriterOutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");// 写入字符串osw.write("Hello, World!");osw.write("\n");osw.write("这是一个测试。");// 刷新和关闭流osw.flush();osw.close();}
10.6.3.2 字符输入流InputStreamReader
InputStreamReader 是 Java 中一个桥接器类,用于从字节文件解码出字符。因为计算机底层存储的数据都是二进制的字节码文件,所以我们要读取文本文件,就需要将其根据编码解析成字符流,才能读取文件中的内容。
构造方法:构造参数都有InputStream,因为InputStreamReader作用是将字节文件转为字符
- InputStreamReader(InputStream in): 使用默认字符集将给定的输入流 in 转换为字符流。
- InputStreamReader(InputStream in, Charset cs): 使用指定的字符集 cs 将给定的输入流 in 转换为字符流。
读取字符:
- int read(): 读取单个字符并返回其 Unicode 编码,如果到达流的末尾,则返回 -1。
- int read(char[] cbuf, int offset, int length): 将字符读入数组 cbuf,从 offset 位置开始存放,最多读取 length 个字符。
其他方法:
- void mark(int readAheadLimit): 标记流的当前位置,最多可以在流中读取 readAheadLimit 个字符。
- void reset(): 将流重置到最后一次标记的位置。
- boolean markSupported(): 测试此输入流是否支持标记功能。
- void close(): 关闭流并释放与之关联的所有系统资源。
代码示例:
/*** 实际开发时不建议throws异常,而是try-catch,finally中关闭流** @param args* @throws IOException*/public static void main(String[] args) throws IOException {// 创建文件输入流FileInputStream fis = new FileInputStream("D://output.txt");// 创建使用 UTF-8 编码的 InputStreamReaderInputStreamReader isr = new InputStreamReader(fis, "UTF-8");// 读取文件内容并输出char[] buffer = new char[1024];int length;while ((length = isr.read(buffer)) != -1) {System.out.print(new String(buffer, 0, length));}// 关闭流isr.close();}
10.6.4 FileWriter和FileReader:简化字符流
FileWriter是OutputStreamWriter的子类,FileReader是InputStreamReader的子类。这两个类的作用是简化字符输入输出流的构造方法。
我们可以看FileReader的源码,可以看到它继承了InputStreamReader类,并且只有三个构造方法,这几个构造方法封装了super(new FileInputStream(fileName或者file));,从而可以让我们直接将文件名或者File对象作为构造参数,而不需要再麻烦的创建一个FileInputStream对象,再将它作为构造参数创建InputStreamReader对象了。
package java.io;
public class FileReader extends InputStreamReader {/*** ..*/public FileReader(String fileName) throws FileNotFoundException {super(new FileInputStream(fileName));}/*** ...*/public FileReader(File file) throws FileNotFoundException {super(new FileInputStream(file));}/*** ..*/public FileReader(FileDescriptor fd) {super(new FileInputStream(fd));}}
下面两段代码效果是一样的,都是创建字符输入流,明显FileReader更方便:
InputStreamReader创建字符输入流方式:
// 创建文件输入流FileInputStream fis = new FileInputStream("D://output.txt");// 创建使用 UTF-8 编码的 InputStreamReaderInputStreamReader isr = new InputStreamReader(fis, "UTF-8");FileReader创建字符输入流方式:
FileReader reader = new FileReader("output.txt")
除了构造方法外,其他方法和他们的父类一致,这里不再赘述。
FileReader构造方法
- FileReader(String fileName): 创建一个新的 FileReader,读取指定文件。
- FileReader(File file): 创建一个新的 FileReader,读取指定的 File 对象。
FileWriter构造方法
- FileWriter(String fileName): 创建一个使用默认字符编码的 FileWriter,将数据写入指定文件。如果文件不存在,则创建新文件;如果文件存在,则覆盖原有内容。
- FileWriter(String fileName, boolean append): 创建一个使用默认字符编码的 FileWriter,将数据写入指定文件。若 append 为 true,则在文件末尾追加内容,而不是覆盖。
- FileWriter(File file): 创建一个 FileWriter,将数据写入指定的 File 对象。
- FileWriter(File file, boolean append): 创建一个 FileWriter,将数据写入指定的 File 对象,并选择是否在文件末尾追加内容。
代码示例:
/*** 实际开发时不建议throws异常,而是try-catch,finally中关闭流** @param args* @throws IOException IO异常*/public static void main(String[] args) throws IOException {// 写文件FileWriter writer = new FileWriter("output.txt");writer.write("Hello, World!");writer.write("\nWelcome to Java FileWriter.");writer.close();// 读文件FileReader reader = new FileReader("output.txt");int character;while ((character = reader.read()) != -1) {System.out.print((char) character);}reader.close();} 
JDK7之前的异常处理版本:
实际场景中,IO流需要进行异常处理,确保文件资源能正常读写和关闭,保证程序更加健壮:
public static void main(String[] args) {FileWriter writer = null;FileReader reader = null;try {// 写文件writer = new FileWriter("output.txt");writer.write("Hello, World!");writer.write("\nWelcome to Java FileWriter.");} catch (IOException e) {// 实际场景建议用logger.error(),而不是e.printStackTrace()e.printStackTrace();} finally {// 判空,防止创建流的时候就失败,进入catch中if (writer != null) {// 关闭流时也需要异常处理,防止关闭失败try {writer.close();} catch (IOException e) {// 实际场景建议用logger.error(),而不是e.printStackTrace()e.printStackTrace();}}}try {// 读文件reader = new FileReader("output.txt");int character;while ((character = reader.read()) != -1) {System.out.print((char) character);}} catch (IOException e) {e.printStackTrace();} finally {if (reader != null) {try {reader.close();} catch (IOException e) {e.printStackTrace();}}}}
10.6.5 字符缓冲流(推荐)
BufferedWriter和BufferedReader是带缓冲区的字符流,读写效率相对于普通的字符流OutputStreamWriter和InputStreamReader会高很多。
为什么字符缓冲流读写效率高?
原因跟字节缓冲流类似,它维护了默认容量8192容量的char类型数组,在写入时会将字符先写进这个存于内存的数组中,等容量满了之后,会一次性将数据写进磁盘,而不是每次写数据都进行磁盘IO一次,有效降低了读写次数,又因为磁盘的IO效率是远低于内存IO效率的,所以字符缓冲流的写效率高。
BufferedReader也一个道理,它在第一次读的时候将数据尽可能多的塞满char类型数组,下次读的时候优先从char数组中读,读的效率肯定比直接在磁盘中读的效率高很多。

BufferedWriter
构造方法
-
BufferedWriter(Writer out): 创建一个使用默认大小输出缓冲区的缓冲字符输出流。默认值8192足够大,可用于大多数用途。
public BufferedWriter(Writer out) {// 没指定缓冲区容量时,默认是最大长度8192this(out, defaultCharBufferSize);} -
BufferedWriter(Writer out, int sz): 创建一个使用指定大小输出缓冲区的缓冲字符输出流。参数sz可以指定缓冲区大小,或者可以接受默认大小8192。
常用方法
- void write(int c): 写入单个字符。
- void write(char[] cbuf, int off, int len): 写入字符数组的某一部分。
- void write(String s, int off, int len): 写入字符串的某一部分。
- void newLine(): 写入一个行分隔符。
-
public void newLine() throws IOException {// lineSeparator是本类的一个属性,在构造函数执行时获取当前操作系统的行分隔符并赋值write(lineSeparator);} - void flush(): 刷新该流的缓冲区。每次写完bw.flush();可以将缓冲字符写入文本,虽然close()也能刷新后关闭,但加上flush更保险。
- void close(): 关闭该流,但要先刷新它。
BufferedReader
构造方法:可以指定缓冲区大小,或者可以使用默认大小8192。 默认值足够大,可用于大多数用途。
- BufferedReader(Reader in): 创建一个使用默认大小输入缓冲区的缓冲字符输入流。
- BufferedReader(Reader in, int sz): 创建一个使用指定大小输入缓冲区的缓冲字符输入流。
常用方法
- int read(): 读取单个字符。
- int read(char[] cbuf, int off, int len): 将字符读入数组的某一部分。
- String readLine(): 读取一个文本行。
- boolean ready(): 判断输入流是否准备好被读取。
- void close(): 关闭该流并释放与之关联的所有资源。
代码示例:
BufferedWriter写入三行文字,然后BufferedReader读出来:
public static void main(String[] args) {// 定义文件路径String filePath = "example.txt";// 使用 BufferedWriter 写文件// 使用JDK7的异常处理形式,就不需要finally里关闭流对象了,出异常后系统会自动关闭try (BufferedWriter bw = new BufferedWriter(new FileWriter(filePath))) {bw.write("你好");bw.newLine();bw.write("世界");bw.newLine();bw.write("宇宙");} catch (IOException e) {// 实际场景建议用logger.error(),而不是e.printStackTrace()e.printStackTrace();}// 使用 BufferedReader 读文件try (BufferedReader br = new BufferedReader(new FileReader(filePath))) {String line;while ((line = br.readLine()) != null) {System.out.println(line);}} catch (IOException e) {e.printStackTrace();}}
BufferedReader实现读取键盘录入:
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));代码示例:
public static void main(String[] args) {// 使用 InputStreamReader 包装 System.in,再使用 BufferedReader 包装 InputStreamReaderBufferedReader br = new BufferedReader(new InputStreamReader(System.in));// 提示用户输入System.out.println("请输入一些文字:");// 读取用户输入并输出try {String input = br.readLine();System.out.println("你输入的是:" + input);} catch (IOException e) {e.printStackTrace();} finally {// 关闭 BufferedReadertry {if (br != null) {br.close();}} catch (IOException e) {e.printStackTrace();}}}输入123后回车:

10.7 知识加油站:I/O流JDK7异常处理
I/O流的异常处理:
JDK7之前的常规做法:try...catch...finally
try {// 可能出现异常的代码
} catch (异常类名 变量名) {// 异常的处理代码
} finally {// 执行所有清除操作
}
JDK7改进方案:try-with-resources
因为之前方案,每次都要finally中再次判空、try-catch区关闭IO流,太过麻烦,所以JDK7引入了新的异常处理形式,可以把流对象放到try()的括号里,这样就不需要再写finally了,系统会自动释放资源
try (定义流对象) {// 可能出现异常的代码
} catch (异常类名 变量名) {// 异常的处理代码
}
// 自动释放资源
代码示例:
使用字符缓冲流写文件后,读文件:
JDK7之前格式:
异常处理后,需要在finally里关闭流对象:
public static void main(String[] args) {// 定义文件路径String filePath = "example.txt";// 使用 BufferedWriter 写文件BufferedWriter bw = null;try {bw = new BufferedWriter(new FileWriter(filePath));bw.write("Hello, World!");bw.newLine();bw.write("Welcome to Java BufferedWriter.");bw.newLine();bw.write("This is an example of BufferedWriter.");} catch (IOException e) {// 实际场景建议用logger.error(),而不是e.printStackTrace()e.printStackTrace();} finally {if (bw != null) {// 关闭流时也需要异常处理,防止关闭失败try {bw.close();} catch (IOException e) {e.printStackTrace();}}}// 使用 BufferedReader 读文件BufferedReader br = null;try {br = new BufferedReader(new FileReader(filePath));String line;while ((line = br.readLine()) != null) {System.out.println(line);}} catch (IOException e) {e.printStackTrace();} finally {if (br != null) {try {br.close();} catch (IOException e) {e.printStackTrace();}}}}JDK7格式:
异常处理后,不需要再写finally了,系统会自动释放资源,可以看到代码变简洁很多:
public static void main(String[] args) {// 定义文件路径String filePath = "example.txt";// 使用 BufferedWriter 写文件// 使用JDK7的异常处理形式,就不需要finally里关闭流对象了,出异常后系统会自动关闭try (BufferedWriter bw = new BufferedWriter(new FileWriter(filePath))) {bw.write("你好");bw.newLine();bw.write("世界");bw.newLine();bw.write("宇宙");} catch (IOException e) {// 实际场景建议用logger.error(),而不是e.printStackTrace()e.printStackTrace();}// 使用 BufferedReader 读文件try (BufferedReader br = new BufferedReader(new FileReader(filePath))) {String line;while ((line = br.readLine()) != null) {System.out.println(line);}} catch (IOException e) {e.printStackTrace();}}
10.8 特殊操作流
10.8.1 标准输入输出流:System.in和System.out
什么是标准输入输出流?
- 标准输出流:System.out。用于指定输出到控制台的数据。
- 标准输入流:System.in。用于读取用户在控制台输入的数据。
10.8.1.1 标准输出流
基本介绍
标准输出流:System.out。用于往控制台输出数据。
常用方法:
- print(): 打印数据到控制台,不换行。
- println(): 打印数据到控制台,并换行。
- printf(): 使用指定的格式字符串和参数将数据格式化并打印到控制台。
代码示例:
public class Test {public static void main(String[] args) {// 输出 "Hello, " 不换行System.out.print("Hello, ");// 输出 "World!" 并换行System.out.println("World!");// 使用格式化输出System.out.printf("数字: %d", 42);}}![]()
常用格式化符号
使用System.out、String.format可以对字符串格式化。
常用格式化符号
- %d:十进制整数
- %f:十进制浮点数
- %e:科学计数法表示的十进制数
- %g:根据值的大小,自动选择使用普通计数法或科学计数法
- %s:字符串
- %c:字符
- %b:布尔值(true 或 false)
- %x:整数的十六进制表示
- %o:整数的八进制表示
- %t 或 %T:日期和时间(需要与日期时间转换符配合使用)
- %%:文字百分号(% 本身)
日期和时间转换符
- %tF:年-月-日(yyyy-MM-dd)
- %tD:月/日/年(MM/dd/yy)
- %tT:时:分:秒(HH:mm:ss)
- %tR:时:分(HH:mm)
- %tY:年(四位数)
- %ty:年(两位数)
- %tm:月(两位数)
- %td:日(两位数)
- %tH:小时(24 小时制,两位数)
- %tI:小时(12 小时制,两位数)
- %tM:分钟(两位数)
- %tS:秒(两位数)
- %tp:小写上午或下午标记(am 或 pm)
- %tZ:时区
代码示例:
public class Test {public static void main(String[] args) {int number = 123;double pi = 3.14159;String name = "小明";boolean flag = true;// 格式化输出整数System.out.printf("整数:%d\n", number);// 格式化输出浮点数System.out.printf("浮点数(两位小数):%.2f\n", pi);// 格式化输出字符串System.out.printf("名字:%s\n", name);// 格式化输出布尔值System.out.printf("布尔值:%b\n", flag);// 格式化输出十六进制整数System.out.printf("十六进制:%x\n", number);// 格式化输出八进制整数System.out.printf("八进制:%o\n", number);// 格式化输出百分比double percentage = 0.85;System.out.printf("百分比:%.2f%%\n", percentage * 100);// 左对齐和宽度格式化// %-10s 用于左对齐并指定宽度为10的字符串System.out.printf("左对齐:%-10s|\n", name);// 右对齐和宽度格式化// %10s 用于右对齐并指定宽度为10的字符串System.out.printf("右对齐:%10s|\n", name);// 格式化输出带符号的数值// %+d 用于格式化带符号的整数System.out.printf("带符号的整数:%+d\n", -number);// %+.2f 用于格式化带符号的浮点数System.out.printf("带符号的浮点数:%+.2f\n", pi);}
}
10.8.1.2 标准输入流
基本介绍
标准输入流:System.in。用于读取用户在控制台输入的数据。
用法:
- 字符输入流:作为构造参数传入字符输入流InputStreamReader中,例如new InputStreamReader(System.in)。
- Scanner:因为用字符输入流包装太麻烦,所以Java提供了一个工具类实现键盘录入,即Scanner类,专门用于从各种输入源(如控制台、文件、字符串等)读取输入。
常用方法:
- read(): 从输入流中读取一个字节。
- read(byte[] b): 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
- read(byte[] b, int off, int len): 从输入流中将 len 个字节的数据读入一个字节数组。
代码示例:
public static void main(String[] args) {// 使用 BufferedReader 包装 System.inBufferedReader reader = new BufferedReader(new InputStreamReader(System.in));// 提示用户输入System.out.print("随便输入一些文字: ");try {// 读取用户输入String text = reader.readLine();// 输出用户输入System.out.println("你输入的内容是: " + text);} catch (IOException e) {// 实际场景不建议e.printStackTrace(),而是logger.error()e.printStackTrace();}}
Scanner类
因为用字符输入流包装太麻烦,所以Java提供了一个工具类实现键盘录入,即Scanner类,专门用于从各种输入源(如控制台、文件、字符串等)读取输入。
构造方法:
- Scanner(InputStream source): 构造一个新的 Scanner,生成的扫描器从指定的输入流读取数据。用于读取用户在控制台输入的数据。一般用System.in,即标准输入流,用于读取用户在控制台输入的数据。
- Scanner(File source): 构造一个新的 Scanner,生成的扫描器从指定的文件读取数据。
- Scanner(String source): 构造一个新的 Scanner,生成的扫描器从指定的字符串读取数据。
常用方法:
- nextInt()、nextDouble()、next():获取输入的整数、浮点数、字符串(不包括空格)等。
- nextLine():获取一行输入(包括空格)。
- hasNextInt()、hasNextDouble()、hasNext(): 判断下一个输入是否为整数、浮点数、字符串。
- useDelimiter(String pattern): 设置分隔符模式,用于指定不同类型数据之间的分隔符,默认为空白字符。
- close():关闭扫描器。
示例:
从控制台输入整数、浮点数、字符串,并在控制台打印。
import java.util.Scanner;public class Test {public static void main(String[] args) {// 创建 Scanner 对象,关联 System.in(标准输入流)Scanner scanner = new Scanner(System.in);// 从控制台读取整数System.out.print("Enter an integer: ");int intValue = scanner.nextInt();System.out.println("You entered: " + intValue);// 从控制台读取浮点数System.out.print("Enter a double: ");double doubleValue = scanner.nextDouble();System.out.println("You entered: " + doubleValue);// 从控制台读取字符串System.out.print("Enter a string: ");String stringValue = scanner.next();System.out.println("You entered: " + stringValue);// 关闭 Scanner 对象scanner.close();} }结果:

10.8.2 打印流
10.8.2.1 字节打印流:PrintStream
PrintStream用于将不同的数据类型格式化为字节并写入到输出流,支持自动刷新。它只负责输出数据,不负责读取数据。
一般情况下,打印数据用System.out.printf()就可以了,PrintStream适用于需要重定向输出的场景,例如将打印的结果写入一个文件中。
重定向输出:将输出重定向到文件、网络流或其他输出目标。
public static void main(String[] args) {try (PrintStream ps = new PrintStream(new FileOutputStream("output.txt"))) {ps.println("Hello, World!");ps.println(123);ps.println(true);} catch (IOException e) {e.printStackTrace();}}
构造方法:
- PrintStream(OutputStream out): 创建一个新的打印流,使用指定的输出流。
- PrintStream(OutputStream out, boolean autoFlush): 创建一个新的打印流,使用指定的输出流和自动刷新设置。
- PrintStream(OutputStream out, boolean autoFlush, String encoding): 创建一个新的打印流,使用指定的输出流、自动刷新设置和字符编码。
- PrintStream(String fileName): 创建一个新的打印流,使用指定的文件名。
- PrintStream(String fileName, String encoding): 创建一个新的打印流,使用指定的文件名和字符编码。
- PrintStream(File file): 创建一个新的打印流,使用指定的文件。
- PrintStream(File file, String encoding): 创建一个新的打印流,使用指定的文件和字符编码。
常用方法:
- void print(String s): 打印字符串。
- PrintStream printf(String format, Object... args): 使用指定的格式字符串和参数,将格式化的字符串输出到该流。
- void println(int i): 打印整数并换行。
- close():关闭。
代码示例:
打印到控制台:
public static void main(String[] args) {// true 表示自动刷新PrintStream ps = new PrintStream(System.out, true);ps.println("Hello, World!");ps.println("Hello, World2!");}
打印到文件:
public static void main(String[] args) {PrintStream pw= null;try {pw = new PrintStream("1.txt");} catch (FileNotFoundException e) {e.printStackTrace();}pw.println("hello");pw.println(23);pw.close();}
10.8.2.2 字符打印流:PrintWriter
PrintWriter与 PrintStream 类似,都用于打印数据到文件。主要区别是PrintWriter用于打印字符流,而不是字节流,它可以自动处理字符编码。
构造方法:
- PrintWriter(OutputStream out): 创建一个新的 PrintWriter,从现有的 OutputStream 输出字符。
- PrintWriter(OutputStream out, boolean autoFlush): 创建一个新的 PrintWriter,从现有的 OutputStream 输出字符,并指定是否在调用 println、printf 或 format 方法时自动刷新。
- PrintWriter(Writer out): 创建一个新的 PrintWriter,从现有的 Writer 输出字符。
- PrintWriter(Writer out, boolean autoFlush): 创建一个新的 PrintWriter,从现有的 Writer 输出字符,并指定是否在调用 println、printf 或 format 方法时自动刷新。
- PrintWriter(String fileName): 创建一个新的 PrintWriter,将输出写入指定的文件。
- PrintWriter(String fileName, String csn): 创建一个新的 PrintWriter,将输出写入指定的文件,使用给定的字符集。
- PrintWriter(File file): 创建一个新的 PrintWriter,将输出写入指定的文件。
- PrintWriter(File file, String csn): 创建一个新的 PrintWriter,将输出写入指定的文件,使用给定的字符集。
常用方法:
- 跟PrintStream基本一致,这里不再赘述。
代码示例:
/*** 实际开发时不建议throws异常,而是try-catch,finally中关闭流** @param args* @throws IOException IO异常*/public static void main(String[] args) throws IOException {//自动刷新truePrintWriter pw=new PrintWriter("2.txt");//直接写一行加刷新pw.println("hello"); pw.println(23);pw.close();}10.8.3 序列号流和反序列化流
10.8.3.1 Serializable 接口和serialVersionUID变量
序列化和反序列化:
- 序列化:将对象转换为字节流。转为字节流后可以把它写入文件、数据库,或者传输到网络中。
- 反序列化:序列化的逆过程,也就是将字节流转换回对象。
不参与序列化的字段:被transient修饰的成员变量不参与序列化。
被序列化的类必须实现Serializable接口,并且声明一个成员变量serialVersionUID。
Serializable 接口:
用于标记一个类的对象可以被序列化。这个接口没有任何方法,它仅仅是一个标记,表明实现这个接口的类可以被 Java 的序列化机制处理。
如果一个类的对象没有实现这个接口,并且他的对象被序列号,则会报错不能序列号异常java.io.NotSerializableException:

serialVersionUID变量:
- 作用:serialVersionUID是类的版本号,类型是长整型数值,该字段的主要作用是检查反序列化时类的版本,与序列化时类的版本是否一致。
- 私有:为了保证不同Java编译器实现之间的一致的serialVersionUID值,一个可序列化的类必须声明一个显式的serialVersionUID值,尽量使用private修饰符。
- 序列化类必须包含serialVersionUID:为了保证不同Java编译器实现之间的一致的serialVersionUID值,一个可序列化的类必须声明一个显式的serialVersionUID值,尽量使用private修饰符。
- 建议手动指定:如果实现了Serializable接口,并且没有指定serialVersionUID,编译器会隐式地自动生成一个serialVersionUID,但是建议手动指定,因为默认的serialVersionUID计算对类详细信息非常敏感,从而出现InvalidClassException。
InvalidClassException异常:
序列化时版本号不匹配,会抛出无效类异常。例如反序列化时类的版本号,与序列化时类的版本号不一致在序列化之后,类的结构发生了变化,例如添加、删除或修改了字段,导致版本号不匹配。
代码示例:
创建一个可序列号的Dog类:
/*** @Author: vince* @CreateTime: 2024/07/02* @Description: 狗类* @Version: 1.0*/ public class Dog implements Serializable {private static final long serialVersionUID = 1L;int weight;String name;public Dog(int weight, String name) {this.weight = weight;this.name = name;}@Overridepublic String toString() {return "Dog{" +"weight=" + weight +", name='" + name + '\'' +'}';} }
10.8.3.2 对象序列化流:ObjectOutputStream
序列化流可以将对象转换为字节流,并保存到文件或者传输到网络。
构造方法:
- ObjectOutputStream(OutputStream out): 创建一个写入指定 OutputStream 的 ObjectOutputStream。构造参数是FileOutputStream等OutputStream的子类。
常用方法:
- void writeObject(Object obj): 将指定的对象写入 ObjectOutputStream。
- void close(): 关闭输出流并释放与此流相关联的所有系统资源。
- void flush(): 刷新输出流,并强制任何缓冲的输出字节被写出。
代码示例:被序列化的类使用上一节创建的Dog类:
public class Test {public static void main(String[] args) {Dog dog = new Dog(5, "旺财");// 使用JDK7的异常捕获,不需要手动关闭流try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("dog.txt"))) {oos.writeObject(dog);System.out.println("序列化完成:" + dog);} catch (IOException e) {e.printStackTrace();}}
}10.8.3.3 对象反序列化流:ObjectInputStream
ObjectInputStream是序列化的逆过程,也就是将字节流转换回对象。
构造方法
- ObjectOutputStream(OutputStream out): 创建一个写入指定 OutputStream 的 ObjectOutputStream。
常用方法
- void writeObject(Object obj): 将指定的对象写入 ObjectOutputStream。
- void close(): 关闭输出流并释放与此流相关联的所有系统资源。
- void flush(): 刷新输出流,并强制任何缓冲的输出字节被写出。
代码示例:反序列化上一节创建的dog.txt:
public class Test {public static void main(String[] args) {// Dog dog = new Dog(5, "旺财");//// try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("dog.txt"))) {// oos.writeObject(dog);// System.out.println("序列化完成:" + dog);// } catch (IOException e) {// e.printStackTrace();// }try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("dog.txt"))) {Dog dog = (Dog) ois.readObject();System.out.println("反序列化完成:" + dog);} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}} }