文章目录
- 一、 Scrapyd 分布式部署
- 1.1 了解 Scrapyd
- 1.2 准备工作
- 1.3 访问 Scrapyd
- 1.4 Scrapyd 的功能
- 1.5 ScrapydAPI 的使用
- 二、Scrapyd-Client 的使用
- 2.1 准备工作
- 2.2 Scrapyd-Client 的功能
- 2.3 Scrapyd-Client 部署
- 三、Scrapyd 对接 Docker
- 3.1 准备工作
- 3.2 对接 Docker
- 四、Scrapyd 批量部署
- 4.1 镜像部署
- 4.2 模板部署
- 五、Gerapy 分布式管理
- 5.1 准备工作
- 5.2 使用说明
在将 Scrapy 项目放到各台主机运行时,你可能采用的是文件上传或者 Git 同步的方式,但这样需要各台主机都进行操作,如果有 100 台、1000 台主机,那工作量可想而知。
分布式爬虫部署方面可以采取的一些措施以方便地实现批量部署和管理。
一、 Scrapyd 分布式部署
分布式爬虫完成并可以成功运行了,但是有个环节非常烦琐,那就是代码部署。
我们设想下面的几个场景。
- 如果采用上传文件的方式部署代码,我们首先将代码压缩,然后采用 SFTP 或 FTP 的方式将文件上传到服务器,之后再连接服务器将文件解压,每个服务器都需要这样配置。
- 如果采用 Git 同步的方式部署代码,我们可以先把代码 Push 到某个 Git 仓库里,然后再远程连接各台主机执行 Pull 操作,同步代码,每个服务器同样需要做一次操作。
如果代码突然有更新,那我们必须更新每个服务器,而且万一哪台主机的版本没控制好,这可能会影响整体的分布式爬取状况。
所以我们需要一个更方便的工具来部署 Scrapy 项目,如果可以省去一遍遍逐个登录服务器部署的操作,那将会方便很多。
本节我们就来看看提供分布式部署的工具 Scrapyd。
1.1 了解 Scrapyd
Scrapyd 是一个运行 Scrapy 爬虫的服务程序,它提供一系列 HTTP 接口来帮助我们部署、启动、停止、删除爬虫程序。Scrapyd 支持版本管理,同时还可以管理多个爬虫任务,利用它我们可以非常方便地完成 Scrapy 爬虫项目的部署任务调度。
1.2 准备工作
请确保本机或服务器已经正确安装好了 Scrapyd;
1.3 访问 Scrapyd
安装并运行了 Scrapyd 之后,我们就可以访问服务器的 6800 端口看到一个 WebUI 页面了,例如我的服务器地址为 120.27.34.25,在上面安装好了 Scrapyd 并成功运行,那么我就可以在本地的浏览器中打开:http://120.27.34.25:6800,就可以看到 Scrapyd 的首页,这里请自行替换成你的服务器地址查看即可,如图所示:
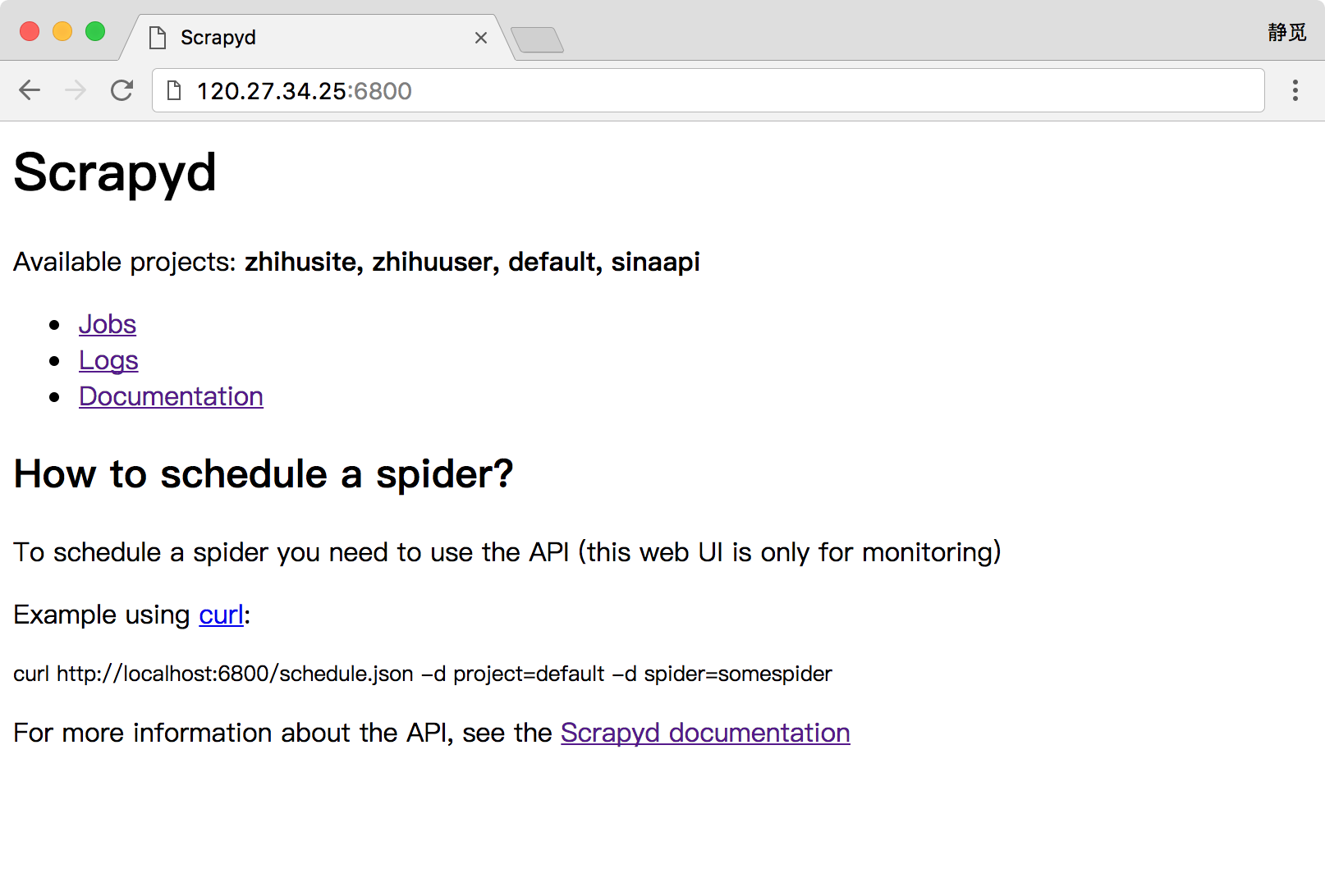
如果可以成功访问到此页面,那么证明 Scrapyd 配置就没有问题了。
1.4 Scrapyd 的功能
Scrapyd 提供了一系列 HTTP 接口来实现各种操作,在这里我们可以将接口的功能梳理一下,以 Scrapyd 所在的 IP 为 120.27.34.25 为例:
daemonstatus.json
这个接口负责查看 Scrapyd 当前的服务和任务状态,我们可以用 curl 命令来请求这个接口,命令如下:
curl http://139.217.26.30:6800/daemonstatus.json
这样我们就会得到如下结果:
{"status": "ok", "finished": 90, "running": 9, "node_name": "datacrawl-vm", "pending": 0}
返回结果是 Json 字符串,status 是当前运行状态, finished 代表当前已经完成的 Scrapy 任务,running 代表正在运行的 Scrapy 任务,pending 代表等待被调度的 Scrapyd 任务,node_name 就是主机的名称。
addversion.json
这个接口主要是用来部署 Scrapy 项目用的,在部署的时候我们需要首先将项目打包成 Egg 文件,然后传入项目名称和部署版本。
我们可以用如下的方式实现项目部署:
curl http://120.27.34.25:6800/addversion.json -F project=wenbo -F version=first -F egg=@weibo.egg
在这里 -F 即代表添加一个参数,同时我们还需要将项目打包成 Egg 文件放到本地。
这样发出请求之后我们可以得到如下结果:
{"status": "ok", "spiders": 3}
这个结果表明部署成功,并且其中包含的 Spider 的数量为 3。
此方法部署可能比较繁琐,在后文会介绍更方便的工具来实现项目的部署。
schedule.json
这个接口负责调度已部署好的 Scrapy 项目运行。
我们可以用如下接口实现任务调度:
curl http://120.27.34.25:6800/schedule.json -d project=weibo -d spider=weibocn
在这里需要传入两个参数,project 即 Scrapy 项目名称,spider 即 Spider 名称。
返回结果如下:
{"status": "ok", "jobid": "6487ec79947edab326d6db28a2d86511e8247444"}
status 代表 Scrapy 项目启动情况,jobid 代表当前正在运行的爬取任务代号。
cancel.json
这个接口可以用来取消某个爬取任务,如果这个任务是 pending 状态,那么它将会被移除,如果这个任务是 running 状态,那么它将会被终止。
我们可以用下面的命令来取消任务的运行:
curl http://120.27.34.25:6800/cancel.json -d project=weibo -d job=6487ec79947edab326d6db28a2d86511e8247444
在这里需要传入两个参数,project 即项目名称,job 即爬取任务代号。
返回结果如下:
{"status": "ok", "prevstate": "running"}
status 代表请求执行情况,prevstate 代表之前的运行状态。
listprojects.json
这个接口用来列出部署到 Scrapyd 服务上的所有项目描述。
我们可以用下面的命令来获取 Scrapyd 服务器上的所有项目描述:
curl http://120.27.34.25:6800/listprojects.json
这里不需要传入任何参数。
返回结果如下:
{"status": "ok", "projects": ["weibo", "zhihu"]}
status 代表请求执行情况,projects 是项目名称列表。
listversions.json
这个接口用来获取某个项目的所有版本号,版本号是按序排列的,最后一个条目是最新的版本号。
我们可以用如下命令来获取项目的版本号:
curl http://120.27.34.25:6800/listversions.json?project=weibo
在这里需要一个参数 project,就是项目的名称。
返回结果如下:
{"status": "ok", "versions": ["v1", "v2"]}
status 代表请求执行情况,versions 是版本号列表。
listspiders.json
这个接口用来获取某个项目最新的一个版本的所有 Spider 名称。
我们可以用如下命令来获取项目的 Spider 名称:
curl http://120.27.34.25:6800/listspiders.json?project=weibo
在这里需要一个参数 project,就是项目的名称。
返回结果如下:
{"status": "ok", "spiders": ["weibocn"]}
status 代表请求执行情况,spiders 是 Spider 名称列表。
listjobs.json
这个接口用来获取某个项目当前运行的所有任务详情。
我们可以用如下命令来获取所有任务详情:
curl http://120.27.34.25:6800/listjobs.json?project=weibo
在这里需要一个参数 project,就是项目的名称。
返回结果如下:
{"status": "ok","pending": [{"id": "78391cc0fcaf11e1b0090800272a6d06", "spider": "weibocn"}],"running": [{"id": "422e608f9f28cef127b3d5ef93fe9399", "spider": "weibocn", "start_time": "2017-07-12 10:14:03.594664"}],"finished": [{"id": "2f16646cfcaf11e1b0090800272a6d06", "spider": "weibocn", "start_time": "2017-07-12 10:14:03.594664", "end_time": "2017-07-12 10:24:03.594664"}]}
status 代表请求执行情况,pendings 代表当前正在等待的任务,running 代表当前正在运行的任务,finished 代表已经完成的任务。
delversion.json
这个接口用来删除项目的某个版本。
我们可以用如下命令来删除项目版本:
curl http://120.27.34.25:6800/delversion.json -d project=weibo -d version=v1
在这里需要一个参数 project,就是项目的名称,还需要一个参数 version,就是项目的版本。
返回结果如下:
{"status": "ok"}
status 代表请求执行情况,这样就代表删除成功了。
delproject.json
这个接口用来删除某个项目。
我们可以用如下命令来删除某个项目:
curl http://120.27.34.25:6800/delproject.json -d project=weibo
在这里需要一个参数 project,就是项目的名称。
返回结果如下:
{"status": "ok"}
status 代表请求执行情况,这样就代表删除成功了。
以上就是 Scrapyd 所有的接口,我们可以直接请求 HTTP 接口即可控制项目的部署、启动、运行等操作。
1.5 ScrapydAPI 的使用
以上的这些接口可能使用起来还不是很方便,没关系,还有一个 ScrapydAPI 库对这些接口又做了一层封装,其安装方式也可以参考第一章的内容。
下面我们来看下 ScrapydAPI 的使用方法,其实核心原理和 HTTP 接口请求方式并无二致,只不过用 Python 封装后使用更加便捷。
我们可以用如下方式建立一个 ScrapydAPI 对象:
from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://120.27.34.25:6800')
然后就可以调用它的方法来实现对应接口的操作了,例如部署的操作可以使用如下方式:
egg = open('weibo.egg', 'rb')
scrapyd.add_version('weibo', 'v1', egg)
这样我们就可以将项目打包为 Egg 文件,然后把本地打包的的 Egg 项目部署到远程 Scrapyd 了。
另外 ScrapydAPI 还实现了所有 Scrapyd 提供的 API 接口,名称都是相同的,参数也是相同的。
例如我们可以调用 list_projects() 方法即可列出 Scrapyd 中所有已部署的项目:
scrapyd.list_projects()
['weibo', 'zhihu']
另外还有其他的方法在此不再一一列举了,名称和参数都是相同的,更加详细的操作可以参考其官方文档:http://python-scrapyd-api.readthedocs.io/。
本节介绍了 Scrapyd 及 ScrapydAPI 的相关用法,我们可以通过它来部署项目,并通过 HTTP 接口来控制人物的运行,不过这里有一个不方便的地方就是部署过程,首先它需要打包 Egg 文件然后再上传,还是比较繁琐的,在下一节我们介绍一个更加方便的工具来完成部署过程。
二、Scrapyd-Client 的使用
这里有现成的工具来完成部署过程,它叫作 Scrapyd-Client。本节将简单介绍使用 Scrapyd-Client 部署 Scrapy 项目的方法。
2.1 准备工作
请先确保 Scrapyd-Client 已经正确安装;
2.2 Scrapyd-Client 的功能
Scrapyd-Client 为了方便 Scrapy 项目的部署,提供两个功能:
- 将项目打包成 Egg 文件。
- 将打包生成的 Egg 文件通过 addversion.json 接口部署到 Scrapyd 上。
也就是说,Scrapyd-Client 帮我们把部署全部实现了,我们不需要再去关心 Egg 文件是怎样生成的,也不需要再去读 Egg 文件并请求接口上传了,这一切的操作只需要执行一个命令即可一键部署。
2.3 Scrapyd-Client 部署
要部署 Scrapy 项目,我们首先需要修改一下项目的配置文件,例如我们之前写的 Scrapy 微博爬虫项目,在项目的第一层会有一个 scrapy.cfg 文件,它的内容如下:
[settings]
default = weibo.settings[deploy]
#url = http://localhost:6800/
project = weibo
在这里我们需要配置一下 deploy 部分,例如我们要将项目部署到 120.27.34.25 的 Scrapyd 上,就需要修改为如下内容:
[deploy]
url = http://120.27.34.25:6800/
project = weibo
这样我们再在 scrapy.cfg 文件所在路径执行如下命令:
scrapyd-deploy
运行结果如下:
Packing version 1501682277
Deploying to project "weibo" in http://120.27.34.25:6800/addversion.json
Server response (200):
{"status": "ok", "spiders": 1, "node_name": "datacrawl-vm", "project": "weibo", "version": "1501682277"}
返回这样的结果就代表部署成功了。
我们也可以指定项目版本,如果不指定的话默认为当前时间戳,指定的话通过 version 参数传递即可,例如:
scrapyd-deploy --version 201707131455
值得注意的是在 Python3 的 Scrapyd 1.2.0 版本中我们不要指定版本号为带字母的字符串,需要为纯数字,否则可能会出现报错。
另外如果我们有多台主机,我们可以配置各台主机的别名,例如可以修改配置文件为:
[deploy:vm1]
url = http://120.27.34.24:6800/
project = weibo[deploy:vm2]
url = http://139.217.26.30:6800/
project = weibo
有多台主机的话就在此统一配置,一台主机对应一组配置,在 deploy 后面加上主机的别名即可,这样如果我们想将项目部署到 IP 为 139.217.26.30 的 vm2 主机,我们只需要执行如下命令:
scrapyd-deploy vm2
这样我们就可以将项目部署到名称为 vm2 的主机上了。
如此一来,如果我们有多台主机,我们只需要在 scrapy.cfg 文件中配置好各台主机的 Scrapyd 地址,然后调用 scrapyd-deploy 命令加主机名称即可实现部署,非常方便。
如果 Scrapyd 设置了访问限制的话,我们可以在配置文件中加入用户名和密码的配置,同时端口修改一下,修改成 Nginx 代理端口,如在第一章我们使用的是 6801,那么这里就需要改成 6801,修改如下:
[deploy:vm1]
url = http://120.27.34.24:6801/
project = weibo
username = admin
password = admin[deploy:vm2]
url = http://139.217.26.30:6801/
project = weibo
username = germey
password = germey
这样通过加入 username 和 password 字段我们就可以在部署时自动进行 Auth 验证,然后成功实现部署。
本节介绍了利用 Scrapyd-Client 来方便地将项目部署到 Scrapyd 的过程,有了它部署不再是麻烦事。
三、Scrapyd 对接 Docker
我们使用了 Scrapyd-Client 成功将 Scrapy 项目部署到 Scrapyd 运行,前提是需要提前在服务器上安装好 Scrapyd 并运行 Scrapyd 服务,而这个过程比较麻烦。如果同时将一个 Scrapy 项目部署到 100 台服务器上,我们需要手动配置每台服务器的 Python 环境,更改 Scrapyd 配置吗?如果这些服务器的 Python 环境是不同版本,同时还运行其他的项目,而版本冲突又会造成不必要的麻烦。
所以,我们需要解决一个痛点,那就是 Python 环境配置问题和版本冲突解决问题。如果我们将 Scrapyd 直接打包成一个 Docker 镜像,那么在服务器上只需要执行 Docker 命令就可以启动 Scrapyd 服务,这样就不用再关心 Python 环境问题,也不需要担心版本冲突问题。
接下来,我们就将 Scrapyd 打包制作成一个 Docker 镜像。
3.1 准备工作
请确保本机已经正确安装好了 Docker,如没有安装可以参考第 1 章的安装说明。
3.2 对接 Docker
接下来我们首先新建一个项目,然后新建一个 scrapyd.conf,即 Scrapyd 的配置文件,内容如下:
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
在这里实际上是修改自官方文档的配置文件:https://scrapyd.readthedocs.io/en/stable/config.html#example-configuration-file,其中修改的地方有两个:
- max_proc_per_cpu = 10,原本是 4,即 CPU 单核最多运行 4 个 Scrapy 任务,也就是说 1 核的主机最多同时只能运行 4 个 Scrapy 任务,在这里设置上限为 10,也可以自行设置。
- bind_address = 0.0.0.0,原本是 127.0.0.1,不能公开访问,在这里修改为 0.0.0.0 即可解除此限制。
接下来新建一个 requirements.txt ,将一些 Scrapy 项目常用的库都列进去,内容如下:
requests
selenium
aiohttp
beautifulsoup4
pyquery
pymysql
redis
pymongo
flask
django
scrapy
scrapyd
scrapyd-client
scrapy-redis
scrapy-splash
如果我们运行的 Scrapy 项目还有其他的库需要用到可以自行添加到此文件中。
最后我们新建一个 Dockerfile,内容如下:
FROM python:3.6
ADD . /code
WORKDIR /code
COPY ./scrapyd.conf /etc/scrapyd/
EXPOSE 6800
RUN pip3 install -r requirements.txt
CMD scrapyd
第一行 FROM 是指在 python:3.6 这个镜像上构建,也就是说在构建时就已经有了 Python 3.6 的环境。
第二行 ADD 是将本地的代码放置到虚拟容器中,它有两个参数,第一个参数是 . ,即代表本地当前路径,/code 代表虚拟容器中的路径,也就是将本地项目所有内容放置到虚拟容器的 /code 目录下。
第三行 WORKDIR 是指定工作目录,在这里将刚才我们添加的代码路径设成工作路径,在这个路径下的目录结构和我们当前本地目录结构是相同的,所以可以直接执行库安装命令等。
第四行 COPY 是将当前目录下的 scrapyd.conf 文件拷贝到虚拟容器的 /etc/scrapyd/ 目录下,Scrapyd 在运行的时候会默认读取这个配置。
第五行 EXPOSE 是声明运行时容器提供服务端口,注意这里只是一个声明,在运行时不一定就会在此端口开启服务。这样的声明一是告诉使用者这个镜像服务的运行端口,以方便配置映射。另一个用处则是在运行时使用随机端口映射时,会自动随机映射 EXPOSE 的端口。
第六行 RUN 是执行某些命令,一般做一些环境准备工作,由于 Docker 虚拟容器内只有 Python3 环境,而没有我们所需要的一些 Python 库,所以在这里我们运行此命令来在虚拟容器中安装相应的 Python 库,这样项目部署到 Scrapyd 中便可以正常运行了。
第七行 CMD 是容器启动命令,在容器运行时,会直接执行此命令,在这里我们直接用 scrapyd 来启动 Scrapyd 服务。
到现在基本的工作就完成了,运行如下命令进行构建:
docker build -t scrapyd:latest .
构建成功后即可运行测试:
docker run -d -p 6800:6800 scrapyd
运行之后我们打开:http://localhost:6800 即可观察到 Scrapyd 服务,如图所示:
这样我们就完成了 Scrapyd Docker 镜像的构建并成功运行了。
然后我们可以将此镜像上传到 Docker Hub,例如我的 Docker Hub 用户名为 germey,新建了一个名为 scrapyd 的项目,首先可以打一个标签:
docker tag scrapyd:latest germey/scrapyd:latest
这里请自行替换成你的项目名称。
然后 Push 即可:
docker push germey/scrapyd:latest
之后我们在其他主机运行此命令即可启动 Scrapyd 服务:
docker run -d -p 6800:6800 germey/scrapyd
执行命令后会发现 Scrapyd 就可以成功在其他服务器上运行了。
这样我们就利用 Docker 解决了 Python 环境的问题,在后一节我们再解决一个批量部署 Docker 的问题就可以解决批量部署问题了。
四、Scrapyd 批量部署
我们在上一节实现了 Scrapyd 和 Docker 的对接,这样每台主机就不用再安装 Python 环境和安装 Scrapyd 了,直接执行一句 Docker 命令运行 Scrapyd 服务即可。但是这种做法有个前提,那就是每台主机都安装 Docker,然后再去运行 Scrapyd 服务。如果我们需要部署 10 台主机的话,工作量确实不小。
一种方案是,一台主机已经安装好各种开发环境,我们取到它的镜像,然后用镜像来批量复制多台主机,批量部署就可以轻松实现了。
另一种方案是,我们在新建主机的时候直接指定一个运行脚本,脚本里写好配置各种环境的命令,指定其在新建主机的时候自动执行,那么主机创建之后所有的环境就按照自定义的命令配置好了,这样也可以很方便地实现批量部署。
目前很多服务商都提供云主机服务,如阿里云、腾讯云、Azure、Amazon 等,不同的服务商提供了不同的批量部署云主机的方式。例如,腾讯云提供了创建自定义镜像的服务,在新建主机的时候使用自定义镜像创建新的主机即可,这样就可以批量生成多个相同的环境。Azure 提供了模板部署的服务,我们可以在模板中指定新建主机时执行的配置环境的命令,这样在主机创建之后环境就配置完成了。
本节我们就来看看这两种批量部署的方式,来实现 Docker 和 Scrapyd 服务的批量部署。
4.1 镜像部署
以腾讯云为例进行说明。首先需要有一台已经安装好环境的云主机,Docker 和 Scrapyd 镜像均已经正确安装,Scrapyd 镜像启动加到开机启动脚本中,可以在开机时自动启动。
接下来我们来看下腾讯云下批量部署相同云服务的方法。
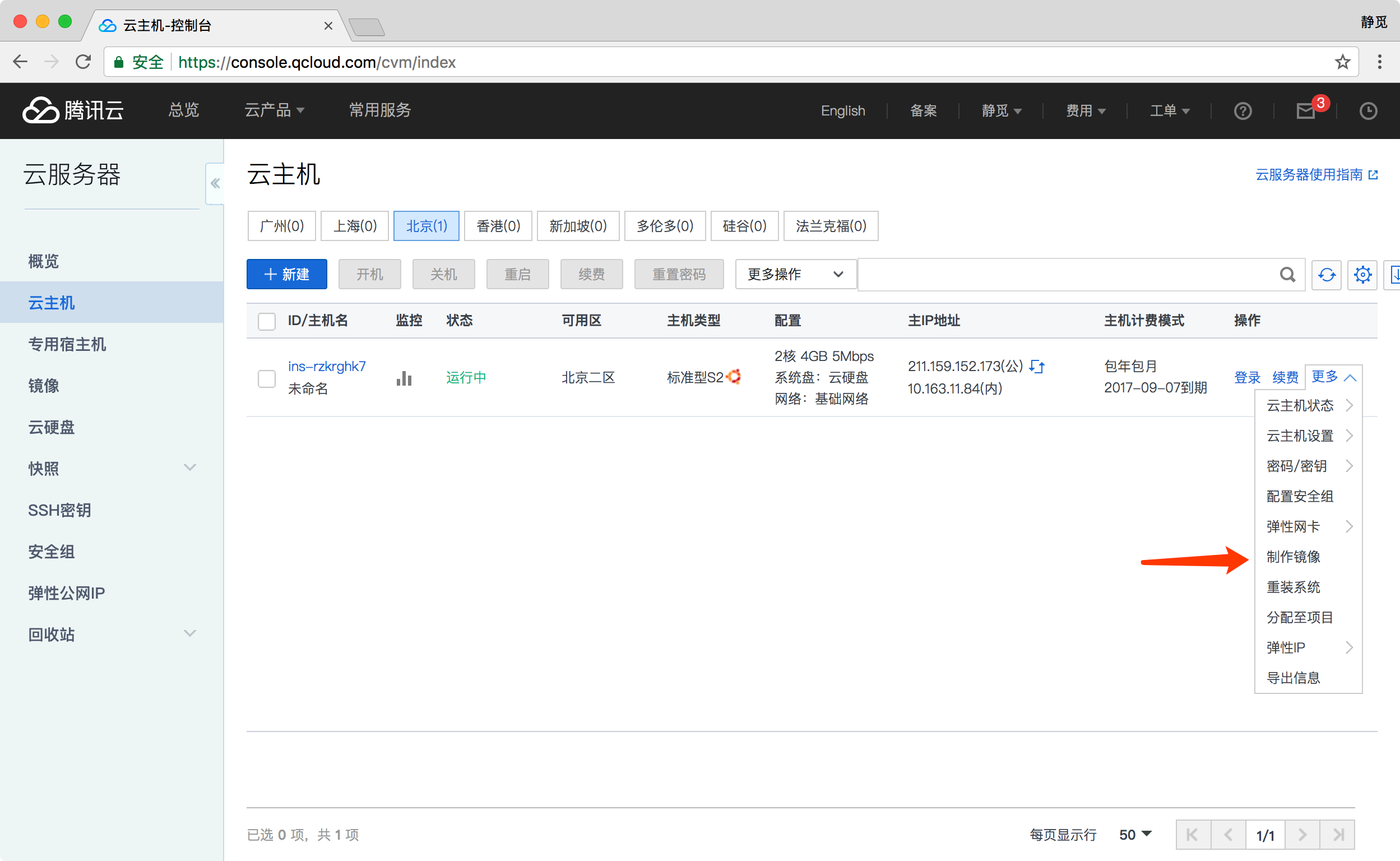
首先进入到腾讯云后台,可以点击更多选项制作镜像,如图所示。
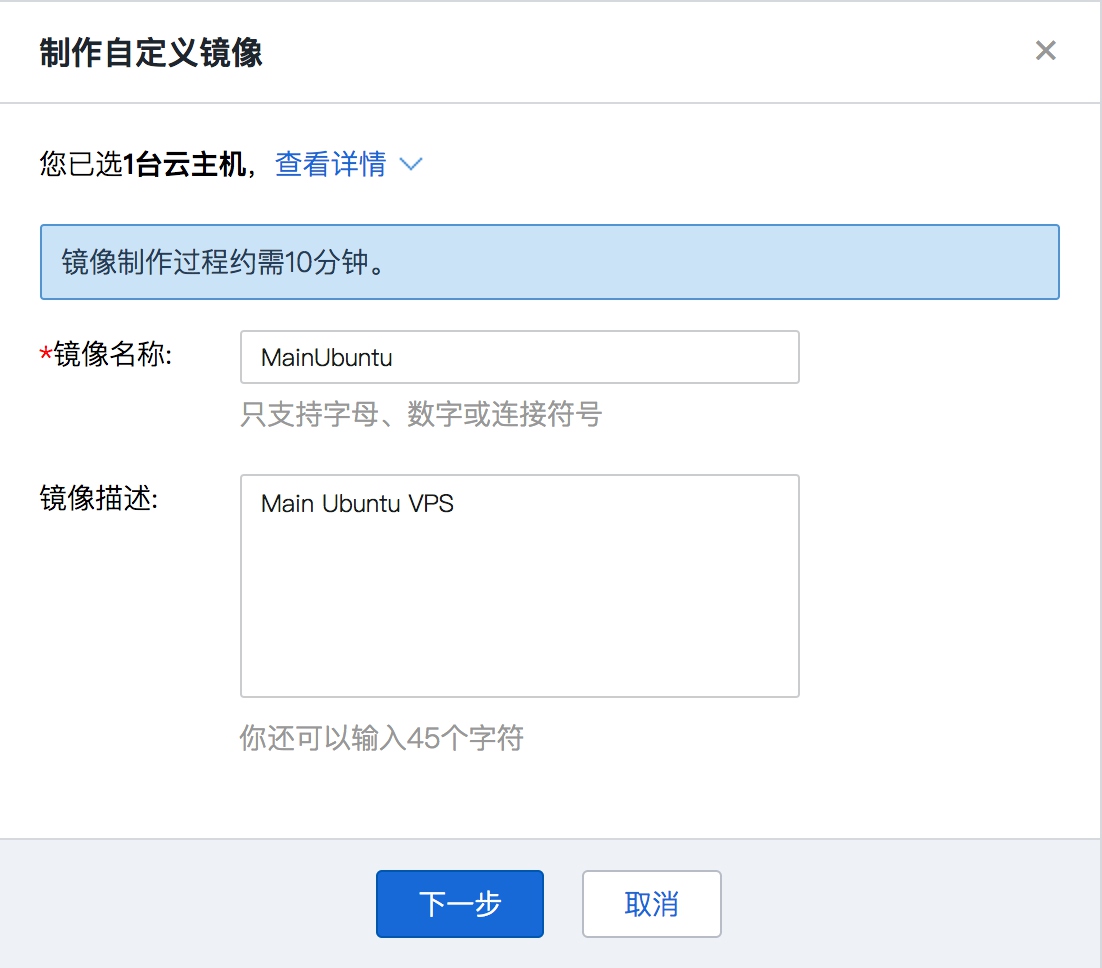
然后输入镜像的一些配置信息,如图所示。
最后确认制作镜像即可,稍等片刻即可制作成功。
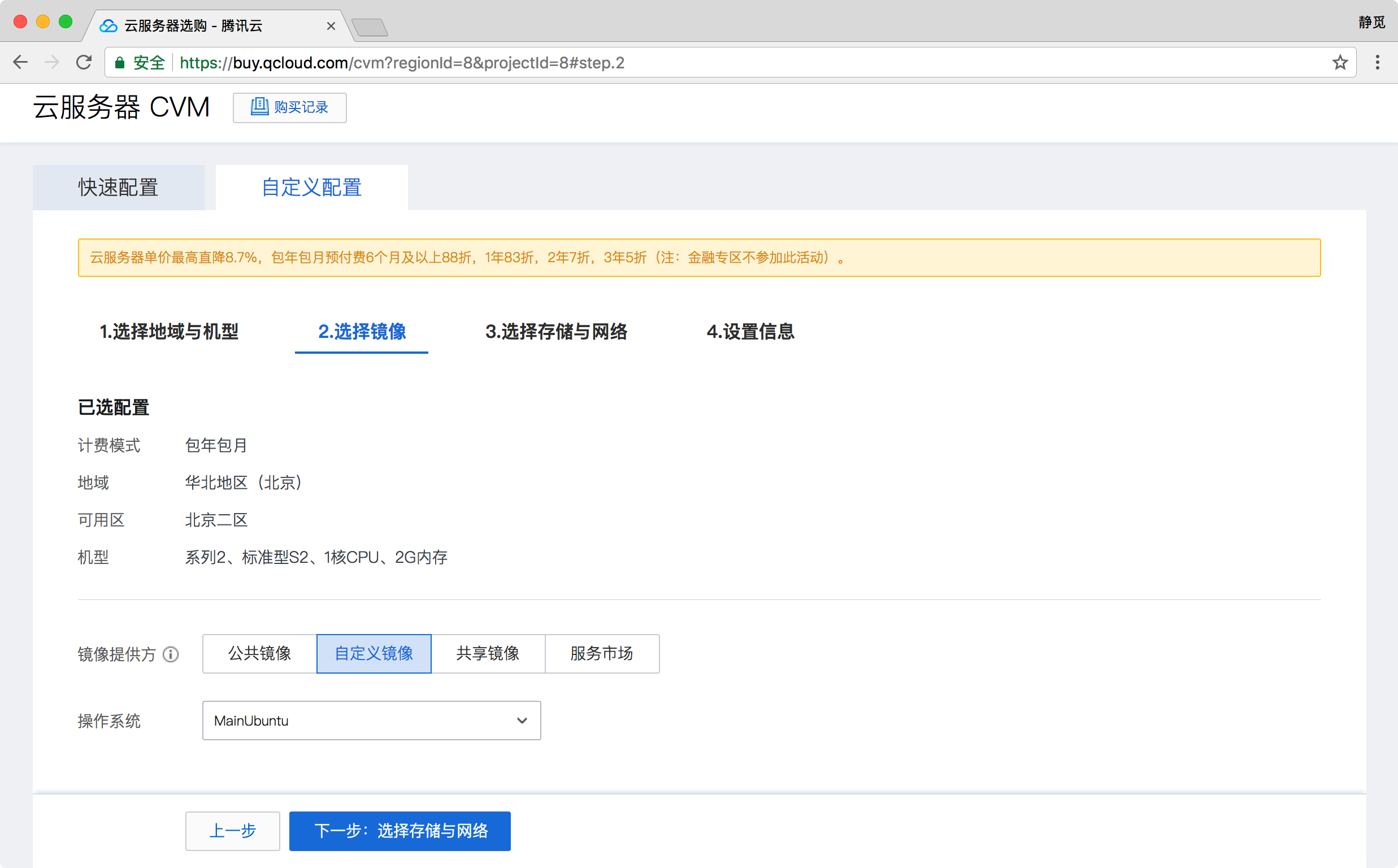
接下来我们可以创建新的主机,在新建主机时选择已经制作好的镜像即可,如图所示。
后续配置过程按照提示进行即可。
配置完成之后登录新到云主机,即可看到当前主机 Docker 和 Scrapyd 镜像都已经安装好,Scrapyd 服务已经正常运行。
我们就通过自定义镜像的方式实现了相同环境的云主机的批量部署。
4.2 模板部署
Azure 的云主机在部署时都会使用一个部署模板,这个模板实际上是一个 JSON 文件,里面包含了很多部署时的配置选项,如主机名称、用户名、密码、主机型号等。在模板中我们可以指定新建完云主机之后执行的命令行脚本,如安装 Docker、运行镜像等。等部署工作全部完成之后,新创建的云主机就已经完成环境配置,同时运行相关服务。
这里提供一个部署 Linux 主机时自动安装 Docker 和运行 Scrapyd 镜像的模板,模板内容太多,源文件可以查看:https://github.com/Python3WebSpider/ScrapydDeploy/blob/master/azuredeploy.json。模板中 Microsoft.Compute/virtualMachines/extensions 部分有一个 commandToExecute 字段,它可以指定建立主机后自动执行的命令。这里的命令完成的是安装 Docker 并运行 Scrapyd 镜像服务的过程。
首先安装一个 Azure 组件,安装过程可以参考:https://docs.azure.cn/zh-cn/xplat-cli-install。之后就可以使用 azure 命令行进行部署。
登录 Azure,这里登录的是中国区,命令如下:
azure login -e AzureChinaCloud
如果没有资源组的话需要新建一个资源组,命令如下:
azure group create myResourceGroup chinanorth
其中 myResourceGroup 就是资源组的名称,可以自行定义。
接下来就可以使用该模板进行部署了,命令如下:
azure group deployment create --template-file azuredeploy.json myResourceGroup myDeploymentName
这里 myResourceGroup 就是资源组的名称,myDeploymentName 是部署任务的名称。
例如,部署一台 Linux 主机的过程如下:
azure group deployment create --template-file azuredeploy.json MyResourceGroup SingleVMDeploy
info: Executing command group deployment create
info: Supply values for the following parameters
adminUsername: datacrawl
adminPassword: DataCrawl123
vmSize: Standard_D2_v2
vmName: datacrawl-vm
dnsLabelPrefix: datacrawlvm
storageAccountName: datacrawlstorage
运行命令后会提示输入各个配置参数,如主机用户名、密码等。之后等待整个部署工作完成即可,命令行会自动退出。然后,我们登录云主机即可查看到 Docker 已经成功安装并且 Scrapyd 服务正常运行。
以上内容便是批量部署的两种方法。在大规模分布式爬虫架构中,如果需要批量部署多个爬虫环境,使用如上方法可以快速批量完成环境的搭建工作,而不用再去逐个主机配置环境。
到此为止,我们解决了批量部署的问题,创建主机完毕之后即可直接使用 Scrapyd 服务。
五、Gerapy 分布式管理
我们可以通过 Scrapyd-Client 将 Scrapy 项目部署到 Scrapyd 上,并且可以通过 Scrapyd API 来控制 Scrapy 的运行。那么,我们是否可以做到更优化?方法是否可以更方便可控?
我们重新分析一下当前可以优化的问题。
- 使用 Scrapyd-Client 部署时,需要在配置文件中配置好各台主机的地址,然后利用命令行执行部署过程。如果我们省去各台主机的地址配置,将命令行对接图形界面,只需要点击按钮即可实现批量部署,这样就更方便了。
- 使用 Scrapyd API 可以控制 Scrapy 任务的启动、终止等工作,但很多操作还是需要代码来实现,同时获取爬取日志还比较烦琐。如果我们有一个图形界面,只需要点击按钮即可启动和终止爬虫任务,同时还可以实时查看爬取日志报告,那这将大大节省我们的时间和精力。
所以我们的终极目标是如下内容。
- 更方便地控制爬虫运行
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更简单地实现项目部署
- 更统一地实现主机管理
而这所有的工作均可通过 Gerapy 来实现。
Gerapy 是一个基于 Scrapyd、Scrapyd API、Django、Vue.js 搭建的分布式爬虫管理框架。接下来将简单介绍它的使用方法。
5.1 准备工作
在本节开始之前请确保已经正确安装好了 Gerapy;
5.2 使用说明
首先可以利用 gerapy 命令新建一个项目,命令如下:
gerapy init
这样会在当前目录下生成一个 gerapy 文件夹,然后进入 gerapy 文件夹,会发现一个空的 projects 文件夹,我们后文会提及。
这时先对数据库进行初始化:
gerapy migrate
这样即会生成一个 SQLite 数据库,数据库中会用于保存各个主机配置信息、部署版本等。
接下来启动 Gerapy 服务,命令如下:
gerapy runserver
这样即可在默认 8000 端口上开启 Gerapy 服务,我们浏览器打开:http://localhost:8000 即可进入 Gerapy 的管理页面,在这里提供了主机管理和项目管理的功能。
主机管理中,我们可以将各台主机的 Scrapyd 运行地址和端口添加,并加以名称标记,添加之后便会出现在主机列表中,Gerapy 会监控各台主机的运行状况并以不同的状态标识,如图所示:
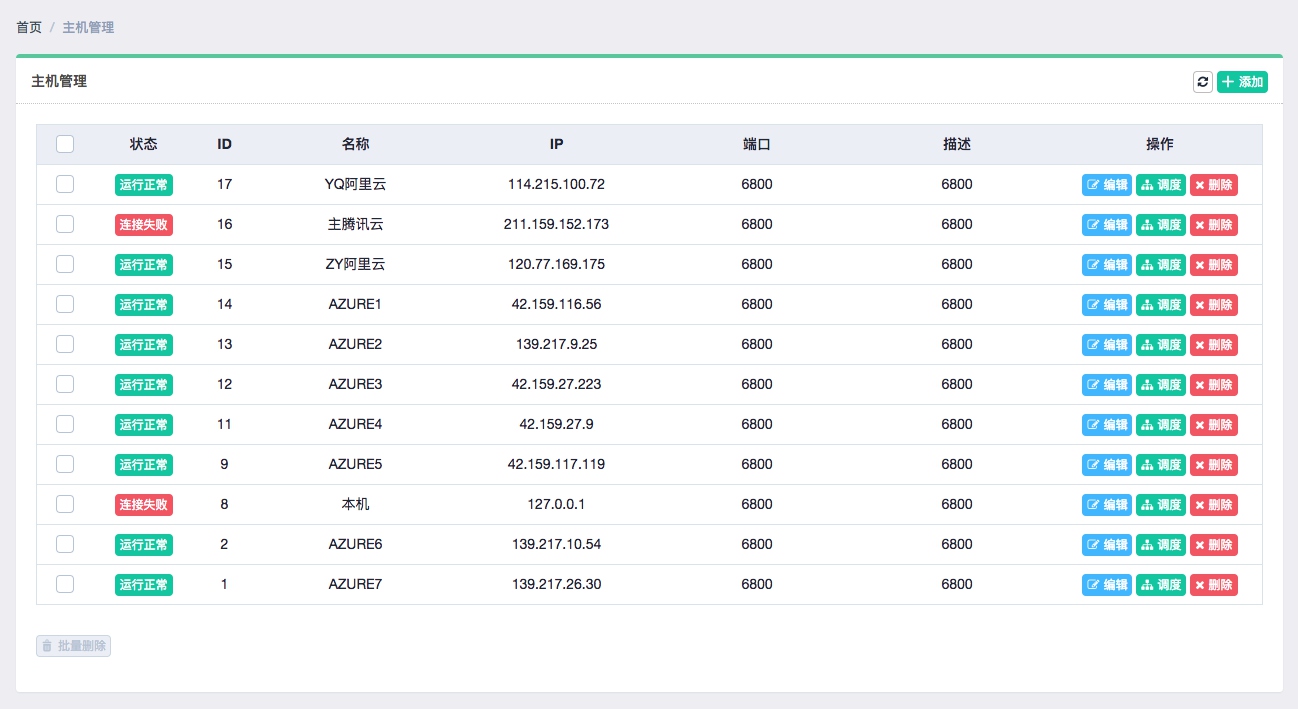
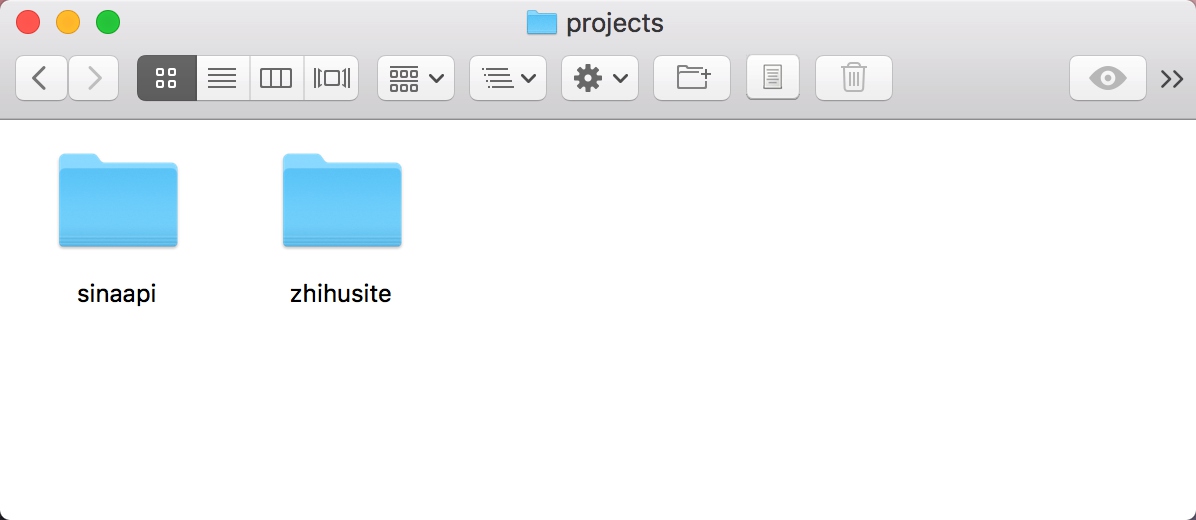
另外刚才我们提到在 gerapy 目录下有一个空的 projects 文件夹,这就是存放 Scrapy 目录的文件夹,如果我们想要部署某个 Scrapy 项目,只需要将该项目文件放到 projects 文件夹下即可。
比如这里我放了两个 Scrapy 项目,如图所示:
这时重新回到 Gerapy 管理界面,点击项目管理,即可看到当前项目列表,如图所示:
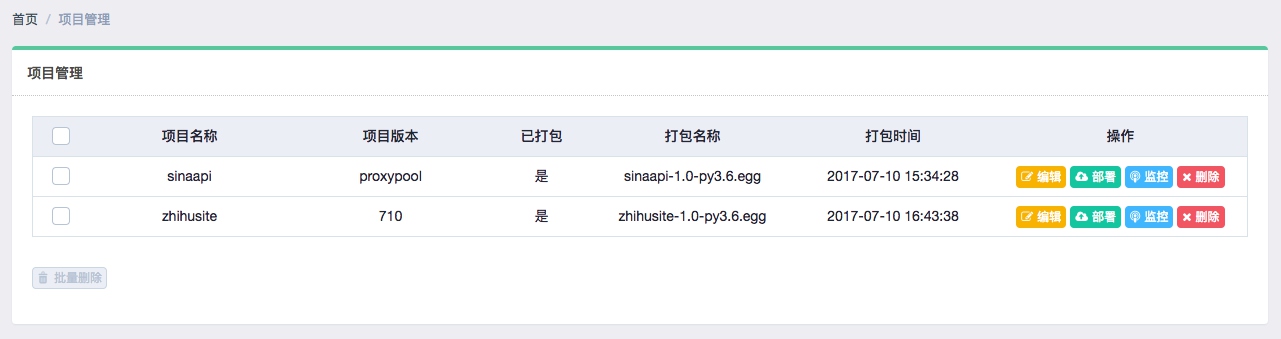
由于此处我有过打包和部署记录,在这里分别予以显示。
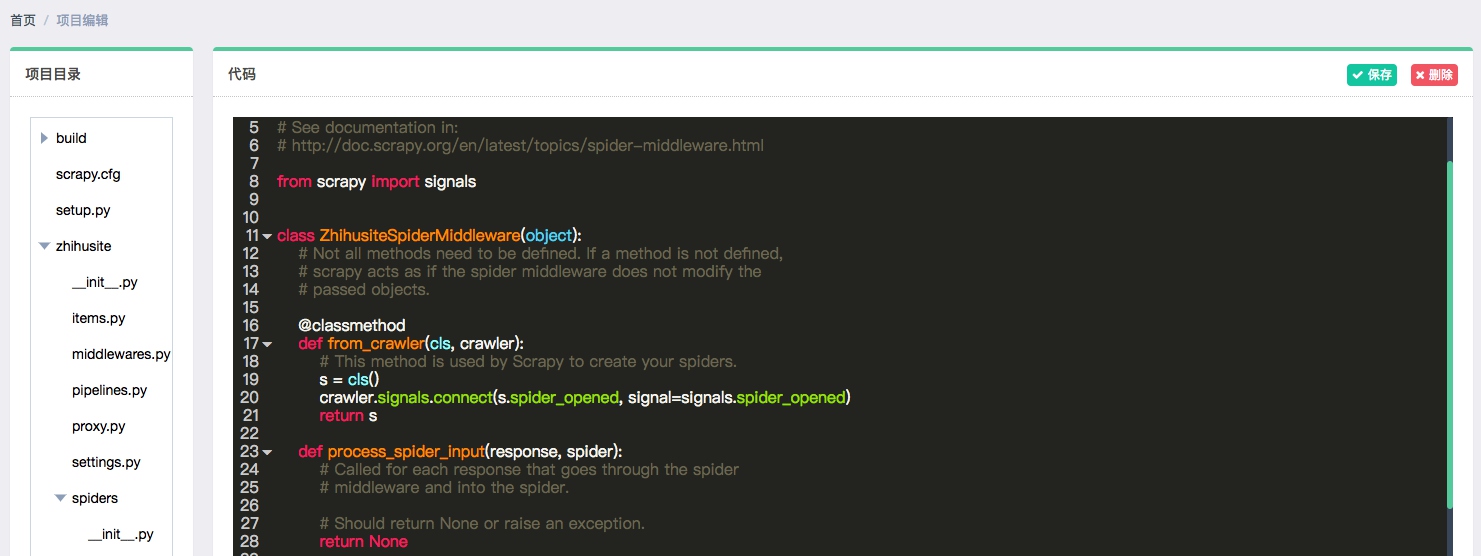
Gerapy 提供了项目在线编辑功能,我们可以点击编辑即可可视化地对项目进行编辑,如图所示:
如果项目没有问题,可以点击部署进行打包和部署,部署之前需要打包项目,打包时可以指定版本描述,如图所示:
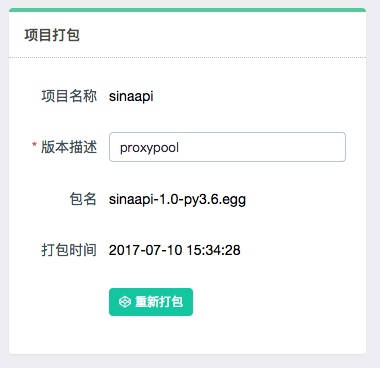
打包完成之后可以直接点击部署按钮即可将打包好的 Scrapy 项目部署到对应的云主机上,同时也可以批量部署,如图所示:
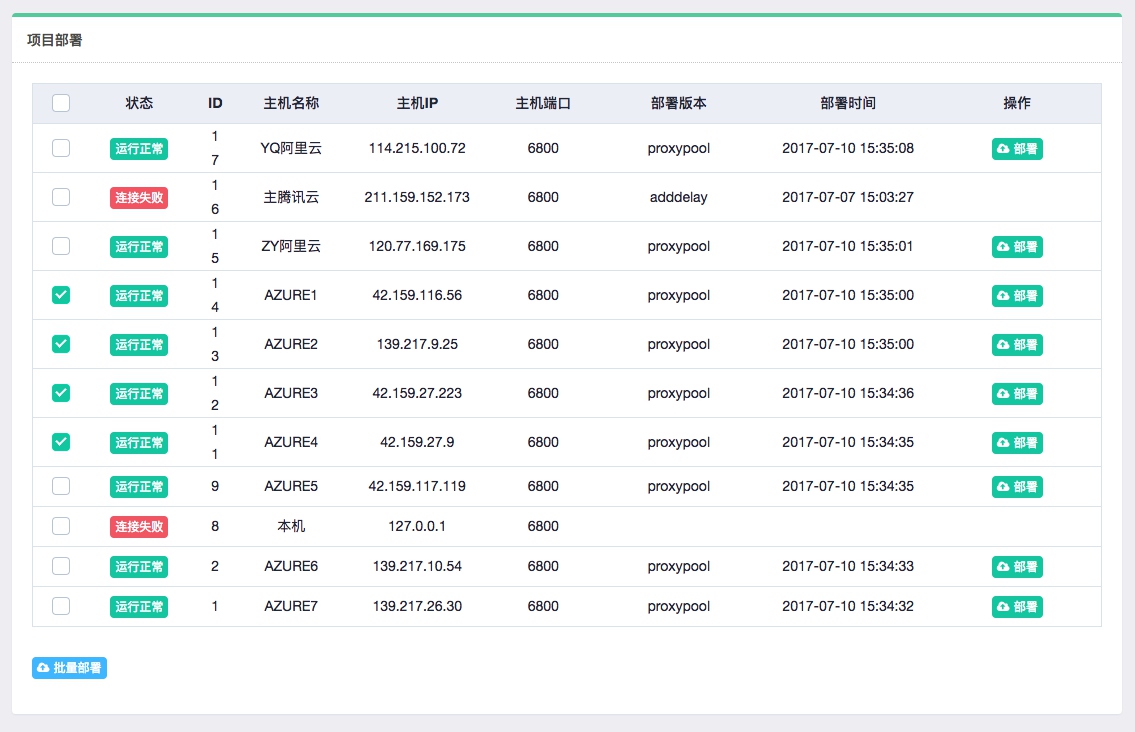
部署完毕之后就可以回到主机管理页面进行任务调度了,点击调度即可查看进入任务管理页面,可以当前主机所有任务的运行状态,如图所示:
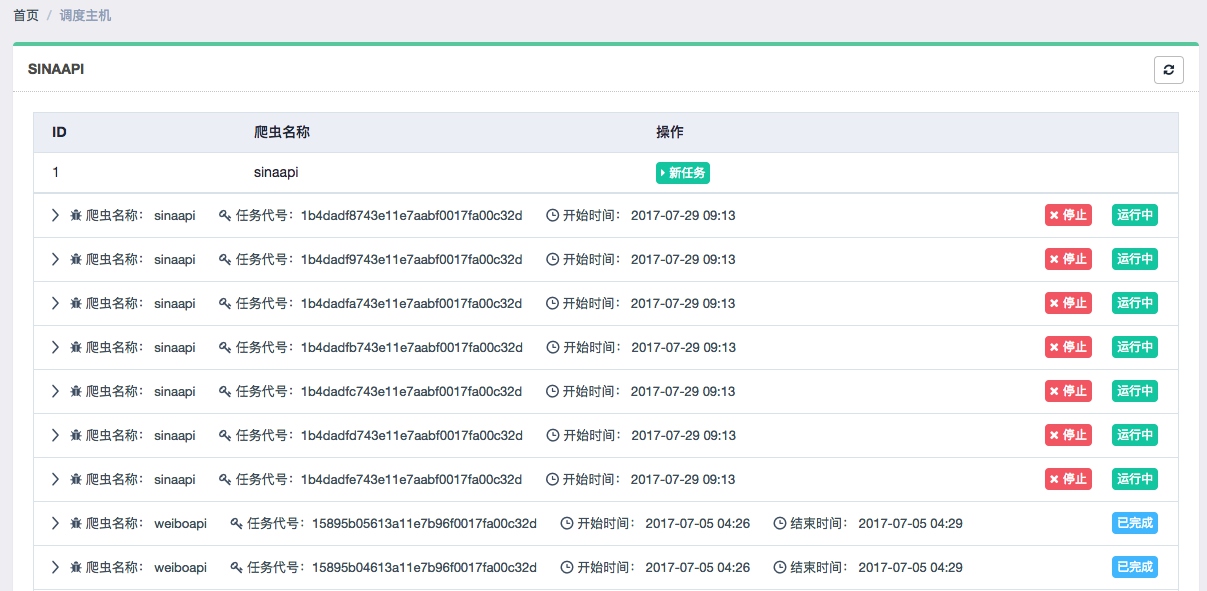
我们可以通过点击新任务、停止等按钮来实现任务的启动和停止等操作,同时也可以通过展开任务条目查看日志详情,如图所示:
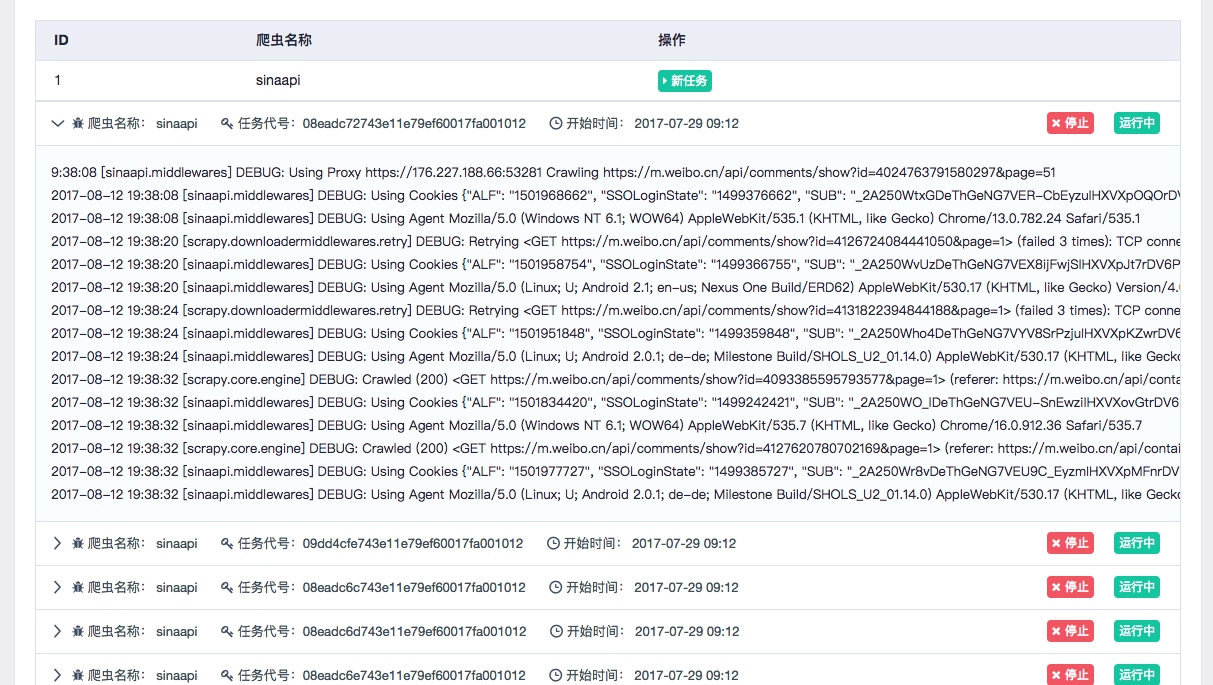
这样我们就可以实时查看到各个任务运行状态了。
以上便是 Gerapy 的一些功能的简单介绍,使用它我们可以更加方便地管理、部署和监控 Scrapy 项目,尤其是对分布式爬虫来说。
更多的信息可以查看 Gerapy 的 GitHub 地址:https://github.com/Gerapy。
本节我们介绍了 Gerapy 的简单使用,利用它我们可以方便地实现 Scrapy 项目的部署、管理等操作,可以大大提高效率。








![LeetCode[中等] 49.字母异位词分组](https://i-blog.csdnimg.cn/direct/054e7cba4b1549938ff036be4cec2dc0.png)