HashMap为什么线程不安全
put的不安全
由于多线程对HashMap进行put操作,调用了HashMap的putVal(),具体原因:
1、假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的;
-
当线程A执行完第六行由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入;
-
接着线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入;
-
最终就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
2、代码的第38行处有个++size,线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10;
-
当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU;
-
接着线程B拿到CPU后从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存;
-
接着线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存;
-
此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
1 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
2 boolean evict) {
3 Node <K, V> [] tab; Node <K, V> p; int n, i;
4 if ((tab = table) == null || (n = tab.length) == 0)
5 n = (tab = resize()).length;
6 if ((p = tab[i = (n - 1) & hash]) == null) //tab[i] = newNode(hash, key, value, null);else {Node < K, V > e;K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode <K, V> ) p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0;; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;38 if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}扩容不安全
Java7中头插法扩容会导致死循环和数据丢失,Java8中将头插法改为尾插法后死循环和数据丢失已经得到解决,但仍然有数据覆盖的问题。
这是jdk7中存在的问题
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry <K, V> e: table) {while (null != e) {Entry <K, V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}
}transfer过程如下:
-
对索引数组中的元素遍历
-
对链表上的每一个节点遍历:用 next 取得要转移那个元素的下一个,将 e 转移到新 Hash 表的头部,使用头插法插入节点。
-
循环2,直到链表节点全部转移
-
循环1,直到所有索引数组全部转移
注意 e.next = newTable[i] 和newTable[i] = e 这两行代码,就会导致链表的顺序翻转。
扩容操作就是新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
Map m = Collections.synchronizedMap(new LinkedHashMap(...));concurrentHashMap介绍
concurrentHashMap是一个支持高并发更新与查询的哈希表(基于HashMap)。
hashtable该类不依赖于synchronization去保证线程操作的安全。Collections.synchronizedMap()也可以将map转成线程安全的。而concurrentHashMap在保证安全的前提下,进行get不需要锁定。
底层源码
put方法
回顾hashMap的put方法过程
-
计算出key的槽位
-
根据槽位类型进行操作(链表,红黑树)
-
根据槽位中成员数量进行数据转换,扩容等操作
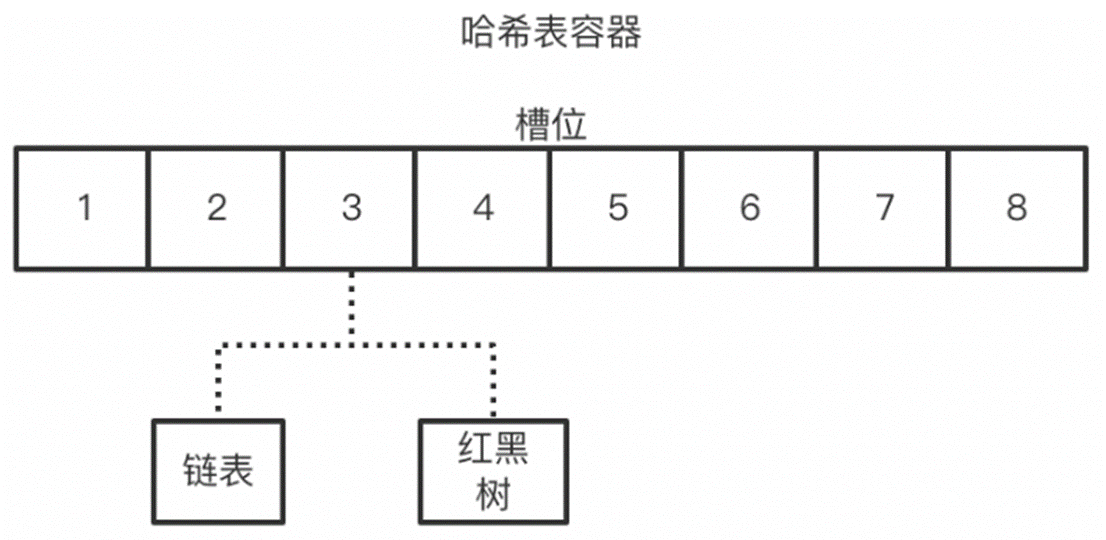
如何高效的执行并发操作:根据上面hashMap的数据结构可以直观的看到,如果以整个容器为一个资源进行锁定,那么就变为了串行操作。而根据hash表的特性,具有冲突的操作只会出现在同一槽位,而与其它槽位的操作互不影响。基于此种判断,那么就可以将资源锁粒度缩小到槽位上,这样热点一分散,冲突的概率就大大降低,并发性能就能得到很好的增强。

底层源码:
final V putVal(K key, V value, boolean onlyIfAbsent) {// key和value如果为null,直接甩异常if (key == null || value == null) throw new NullPointerException();// 计算key的hash值,(通过hash值决定Entry存放到数组的哪个索引位置)int hash = spread(key.hashCode());// 暂时当做标识,值为0int binCount = 0;// 声明临时变量为tab,tab赋值了table,table就是当前HashMap的数组!这是个死循环for (Node<K,V>[] tab = table;;) {// 声明了一堆变量//f-当前索引位置的数据//n-数组长度//i-数据要存储的索引位置//fh-桶位置数据的hash值Node<K,V> f; int n, i, fh;// 如果tab为null,或者tab的长度为0if (tab == null || (n = tab.length) == 0)// 进来说明数组没有初始化,开始初始化,ConcurrentHashMap要避免并发初始化时造成的问题tab = initTable();// tabAt(数组,索引位置),得到这个数组指定索引位置的值,f就是数组的下标位置的值 // 如果f == nullelse if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 进到这,说明索引位置没有值,基于CAS的方式将当前的key-value存储到这个索引位置if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))// 如果CAS成功,添加数据成功(添加到了数组上),如果走false,继续上述操作,尝试其他内容break; // no lock when adding to empty bin}// f是经过上述if得到的索引位置的值,当前key-value的hash是否为MOVED,如果相等,证明当前位置正在扩容else if ((fh = f.hash) == MOVED)//MOVED表示正在扩容// 如果正在扩容,帮你扩容(构建长度为原来2倍的数组,并且将老数组的值移动到新数组),帮助扩容的操作是迁移数据的操作tab = helpTransfer(tab, f);else {// 第一个判断:数组初始化了么? // 第二个判断:数组指定的位置有值么? // 第三个判断:现在正在扩容么? // 这个else就是第四个判断:是否需要将数据挂到链表上,或者添加到红黑树中?(出现了Hash冲突(碰撞))V oldVal = null;// 加个锁,锁的是f(f是数组的下标位置的值),也就是在这,锁住了这个桶synchronized (f) {// 拿到i索引位置的数据,判断与锁住的f是不是同一个if (tabAt(tab, i) == f) {// 如果fh 大于等于 0(判断hash值是否大于等于0),说明是链表if (fh >= 0) {// 将标识修改为1binCount = 1;// 开始循环,为了将插入的值挂到链表的最后面for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash && // 判断指向的节点的key是否等于当前要插入的节点的key((ek = e.key) == key || // 判断指向的节点的key是否等于当前要插入的节点的key(ek != null && key.equals(ek)))) { // 指向的节点的key是否域当前的key相等// 说明当前是修改操作oldVal = e.val;if (!onlyIfAbsent) // onlyIfAbsent如果为true,就什么事都不做e.val = value; // 修改值break;}// 是正常的添加操作Node<K,V> pred = e;// 如果节点的next为null,说明到链表的最后一个节点了,添加到链表的末尾if ((e = e.next) == null) {// 将当前值添加到链表的最后一个节点的next指向pred.next = new Node<K,V>(hash, key,value, null);break;}}}// 判断当前位置的桶数据是否是树else if (f instanceof TreeBin) {Node<K,V> p;// 标记修改为2binCount = 2;// 调用putTreeVal扔到红黑树if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {// 进到if说明是覆盖操作oldVal = p.val;if (!onlyIfAbsent) // 根据判断决定,是否修改数据p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)//链表长度大等于8treeifyBin(tab, i);//尝试转红黑树if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;
}计算hash值的spread方法
static final int spread(int h) {// (h ^ (h >>> 16)):与HashMap的散列算法一样,让高16位也参与运算// Entry存放的索引位置 = (数组长度 - 1) & hash // & HASH_BITS的运算目的是为了保证等到的hash值,一定是正数,因为最高位符号位100%是0// HASH_BITS = 0x7fffffff// 因为hash值为负数时,有特殊的含义,return (h ^ (h >>> 16)) & HASH_BITS;
}//hash值为负数时的特殊含义
static final int MOVED = -1; // 当前索引位置的数据正在扩容
static final int TREEBIN = -2; // 当前索引位置下面不是链表,是红黑树
static final int RESERVED = -3; // 当前索引位置被临时占用,compute方法会涉及初始化 initTable方法
/* sizeCtl = -1:说明当前ConcurrentHashMap正在初始化!!!
sizeCtl = -N:说明当前ConcurrentHashMap正在扩容!!!
sizeCtl = 0:默认初始值,当前ConcurrentHashMap还没有初始化
sizeCtl > 0:如果已经初始化过了,sizeCtl标识扩容的阈值, 如果没有初始化,sizeCtl标识数组的初始化容量 */private final Node<K,V>[] initTable() {// 声明一些变量Node<K,V>[] tab; int sc;// tab变量是HashMap的数组, 数组长度为null,或者数组的长度为0,说明数组还没有初始化!while ((tab = table) == null || tab.length == 0) {// 将sizeCtl赋值给sc,如果进到if中,说明正在扩容或者正在初始化if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spin// 以CAS的方式,尝试将sizeCtl从之前oldValue替换为-1,为了标识我当前ConcurrentHashMap正在初始化else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {// 开始扩容try {//DCL思想// table是不是还是null,或者长度还是0if ((tab = table) == null || tab.length == 0) {// 声明n,sc是sizeCtl,默认sizectl为0,但是现在正在初始化,我把sizeCtl改为了-1,但是sc还是0 // sc如果为0,不大于0,所以为DEFAULT_CAPACITY,16int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")// 创建数组!!!Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 将初始化的nt数组赋值给ConcurrentHashMap的tabletable = tab = nt;// 默认sc = 12,为扩容阈值sc = n - (n >>> 2);}} finally {// 将阈值赋值给sizeCtl,到这初始化完毕sizeCtl = sc;}break;}}return tab;
}链表转红黑树: treeifyBin
在 put 源码分析也说过,treeifyBin 不一定就会进行红黑树转换,也可能是仅仅做数组扩容。
private final void treeifyBin(Node<K,V>[] tab, int index) {Node<K,V> b; int n, sc;if (tab != null) {// MIN_TREEIFY_CAPACITY 为 64// 所以,如果数组长度小于 64 的时候,其实也就是 32 或者 16 或者更小的时候,会进行数组扩容if ((n = tab.length) < MIN_TREEIFY_CAPACITY)// 后面我们再详细分析这个方法tryPresize(n << 1);// b 是头节点else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {// 加锁synchronized (b) {if (tabAt(tab, index) == b) {// 下面就是遍历链表,建立一颗红黑树TreeNode<K,V> hd = null, tl = null;for (Node<K,V> e = b; e != null; e = e.next) {TreeNode<K,V> p =new TreeNode<K,V>(e.hash, e.key, e.val,null, null);if ((p.prev = tl) == null)hd = p;elsetl.next = p;tl = p;}// 将红黑树设置到数组相应位置中setTabAt(tab, index, new TreeBin<K,V>(hd));}}}}
}扩容: tryPresize
如果说 Java8 ConcurrentHashMap 的源码不简单,那么说的就是扩容操作和迁移操作。
这个方法要完完全全看懂还需要看之后的 transfer 方法。
这里的扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍。
// 首先要说明的是,方法参数 size 传进来的时候就已经翻了倍了
private final void tryPresize(int size) {// c: size 的 1.5 倍,再加 1,再往上取最近的 2 的 n 次方。int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :tableSizeFor(size + (size >>> 1) + 1);int sc;while ((sc = sizeCtl) >= 0) {Node<K,V>[] tab = table; int n;// 这个 if 分支和之前说的初始化数组的代码基本上是一样的,在这里,可以不用管这块代码if (tab == null || (n = tab.length) == 0) {n = (sc > c) ? sc : c;if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {if (table == tab) {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = nt;sc = n - (n >>> 2); // 0.75 * n}} finally {sizeCtl = sc;}}}else if (c <= sc || n >= MAXIMUM_CAPACITY)break;else if (tab == table) {int rs = resizeStamp(n);if (sc < 0) {Node<K,V>[] nt;if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;// 2. 用 CAS 将 sizeCtl 加 1,然后执行 transfer 方法// 此时 nextTab 不为 nullif (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}// 1. 将 sizeCtl 设置为 (rs << RESIZE_STAMP_SHIFT) + 2)// 没看懂这个值真正的意义是什么? 不过可以计算出来的是,结果是一个比较大的负数// 调用 transfer 方法,此时 nextTab 参数为 nullelse if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))transfer(tab, null);}}
}这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
数据迁移: transfer
下面这个方法有点长,将原来的 tab 数组的元素迁移到新的 nextTab 数组中。
虽然之前说的 tryPresize 方法中多次调用 transfer 不涉及多线程,但是这个 transfer 方法可以在其他地方被调用,典型地,我们之前在说 put 方法的时候就说过了,请往上看 put 方法,是不是有个地方调用了 helpTransfer 方法,helpTransfer 方法会调用 transfer 方法的。
此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程,这个读者应该能理解吧。其实就是将一个大的迁移任务分为了一个个任务包。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;// stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16// stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range// 如果 nextTab 为 null,先进行一次初始化// 前面说了,外围会保证第一个发起迁移的线程调用此方法时,参数 nextTab 为 null// 之后参与迁移的线程调用此方法时,nextTab 不会为 nullif (nextTab == null) {try {// 容量翻倍Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}// nextTable 是 ConcurrentHashMap 中的属性nextTable = nextTab;// transferIndex 也是 ConcurrentHashMap 的属性,用于控制迁移的位置transferIndex = n;}int nextn = nextTab.length;// ForwardingNode 翻译过来就是正在被迁移的 Node// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了// 所以它其实相当于是一个标志。ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了boolean advance = true;boolean finishing = false; // to ensure sweep before committing nextTab/** 下面这个 for 循环,最难理解的在前面,而要看懂它们,应该先看懂后面的,然后再倒回来看* */// i 是位置索引,bound 是边界,注意是从后往前for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;// 下面这个 while 真的是不好理解// advance 为 true 表示可以进行下一个位置的迁移了// 简单理解结局: i 指向了 transferIndex,bound 指向了 transferIndex-stridewhile (advance) {int nextIndex, nextBound;if (--i >= bound || finishing)advance = false;// 将 transferIndex 值赋给 nextIndex// 这里 transferIndex 一旦小于等于 0,说明原数组的所有位置都有相应的线程去处理了else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {// 看括号中的代码,nextBound 是这次迁移任务的边界,注意,是从后往前bound = nextBound;i = nextIndex - 1;advance = false;}}if (i < 0 || i >= n || i + n >= nextn) {int sc;if (finishing) {// 所有的迁移操作已经完成nextTable = null;// 将新的 nextTab 赋值给 table 属性,完成迁移table = nextTab;// 重新计算 sizeCtl: n 是原数组长度,所以 sizeCtl 得出的值将是新数组长度的 0.75 倍sizeCtl = (n << 1) - (n >>> 1);return;}// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 任务结束,方法退出if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;// 到这里,说明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,// 也就是说,所有的迁移任务都做完了,也就会进入到上面的 if(finishing){} 分支了finishing = advance = true;i = n; // recheck before commit}}// 如果位置 i 处是空的,没有任何节点,那么放入刚刚初始化的 ForwardingNode ”空节点“else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);// 该位置处是一个 ForwardingNode,代表该位置已经迁移过了else if ((fh = f.hash) == MOVED)advance = true; // already processedelse {// 对数组该位置处的结点加锁,开始处理数组该位置处的迁移工作synchronized (f) {if (tabAt(tab, i) == f) {Node<K,V> ln, hn;// 头节点的 hash 大于 0,说明是链表的 Node 节点if (fh >= 0) {// 下面这一块和 Java7 中的 ConcurrentHashMap 迁移是差不多的,// 需要将链表一分为二,// 找到原链表中的 lastRun,然后 lastRun 及其之后的节点是一起进行迁移的// lastRun 之前的节点需要进行克隆,然后分到两个链表中int runBit = fh & n;Node<K,V> lastRun = f;for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}// 其中的一个链表放在新数组的位置 isetTabAt(nextTab, i, ln);// 另一个链表放在新数组的位置 i+nsetTabAt(nextTab, i + n, hn);// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了setTabAt(tab, i, fwd);// advance 设置为 true,代表该位置已经迁移完毕advance = true;}else if (f instanceof TreeBin) {// 红黑树的迁移TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}// 如果一分为二后,节点数小于等于6,那么将红黑树转换回链表ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;// 将 ln 放置在新数组的位置 isetTabAt(nextTab, i, ln);// 将 hn 放置在新数组的位置 i+nsetTabAt(nextTab, i + n, hn);// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了setTabAt(tab, i, fwd);// advance 设置为 true,代表该位置已经迁移完毕advance = true;}}}}}
}说到底,transfer 这个方法并没有实现所有的迁移任务,每次调用这个方法只实现了 transferIndex 往前 stride 个位置的迁移工作,其他的需要由外围来控制。
这个时候,再回去仔细看 tryPresize 方法可能就会更加清晰一些了。
get 过程分析
get 方法从来都是最简单的,这里也不例外:
-
计算 hash 值
-
根据 hash 值找到数组对应位置: (n - 1) & h
-
根据该位置处结点性质进行相应查找
如果该位置为 null,那么直接返回 null 就可以了
如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
如果以上 3 条都不满足,那就是链表,进行遍历比对即可
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 判断头节点是否就是我们需要的节点if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}// 如果头节点的 hash 小于 0,说明 正在扩容,或者该位置是红黑树else if (eh < 0)// 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)return (p = e.find(h, key)) != null ? p.val : null;// 遍历链表while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;
}简单说一句,此方法的大部分内容都很简单,只有正好碰到扩容的情况,ForwardingNode.find(int h, Object k) 稍微复杂一些,不过在了解了数据迁移的过程后,这个也就不难了,所以限于篇幅这里也不展开说了。
计算Size
ConcurrentHashMap的size()操作中没有加任何锁,那么它是如何在多线程环境下 线程安全的计算出Map的size的?
查看源码,可以看出size()使用sumCount()方法计算。
public int size() {long n = sumCount();return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);
}final long sumCount() {CounterCell[] as = counterCells; // CAS修改baseCount失败后,使用CounterCell用来统计那个线程要修改的CounterCell a;// 当没有并发竞争的时候,只使用baseCount统计map的size。long sum = baseCount;// 遍历counterCells,将CounterCell数组中元素的 value 累加 到 sum变量上。if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}// 这个数字可能是不准确的,所以ConCurrentHashMap的size是一个参考值,并不是实时确切值。return sum;
}1、ConCurrentHashMap的大小 size 通过 baseCount 和 counterCells 两个变量维护:
-
在没有并发的情况下,使用一个volatile修饰的 baseCount 变量即可;
-
当有并发时,CAS 修改 baseCount 失败后,会使用 CounterCell 类,即 创建一个CounterCell对象,设置其volatile修饰的 value 属性为 1,并将其放在ConterCells数组的随机位置;
2、最终在sumCount()方法中通过累加 baseCount和CounterCells数组里每个CounterCell的值得出Map的总大小Size。
3、然而 返回的值是一个估计值;如果有并发插入或者删除操作,和实际的数量可能有所不同。
4、另外size()方法的最大值是 Integer 类型的最大值,而 Map 的 size 有可能超过 Integer.MAX_VALUE,所以JAVA8 建议使用 mappingCount()。
compute方法
需要知道的是,业务线程安全并不等于集合线程安全,并不是说使用了线程安全的集合 如ConcurrentHashMap 就能保证业务的线程安全。这是因为,ConcurrentHashMap只能保证put时是安全的,但是在put操作前如果还有其他的操作,那业务并不一定是线程安全的。
以下是compute()方法的一些典型使用场景:
-
原子更新键值对:当你需要确保对键值对的更新是原子的,即在一个线程对键值对进行更新时,其他线程无法看到中间状态。
-
计算键对应的值:如果需要根据键计算新的值来更新映射,
compute()可以确保计算和更新操作的原子性。 -
缓存更新:在缓存实现中,当缓存项需要根据某些条件动态更新时,可以使用
compute()方法来确保更新操作的原子性。 -
并行处理:在并行计算中,当多个线程需要更新同一个
ConcurrentHashMap中的项时,compute()可以用来确保每个键的处理是互不干扰的。
使用示例:
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.put("key1", 1);// 使用compute方法更新键为"key1"的值
map.compute("key1", (key, value) -> value + 1);对比总结
-
HashTable: 使用了synchronized关键字对put等操作进行加锁;
-
ConcurrentHashMap JDK1.7: 使用分段锁机制实现;
-
ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和CAS原子操作实现;synchronized锁住桶,以及大量的CAS操作
扩展:JDK7的分段锁机制
在 JDK7 中 ConcurrentHashMap 底层数据结构是数组加链表,源码如下:
//初始总容量,默认16
static final int DEFAULT_INITIAL_CAPACITY = 16;
//加载因子,默认0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//并发级别,默认16
static final int DEFAULT_CONCURRENCY_LEVEL = 16;static final class Segment<K,V> extends ReentrantLock implements Serializable {transient volatile HashEntry<K,V>[] table;
}其中并发级别控制了Segment的个数,在一个ConcurrentHashMap创建后Segment的个数是不能变的,扩容过程过改变的是每个Segment的大小。
段Segment继承了重入锁ReentrantLock,有了锁的功能,每个锁控制的是一段,如下图所示:
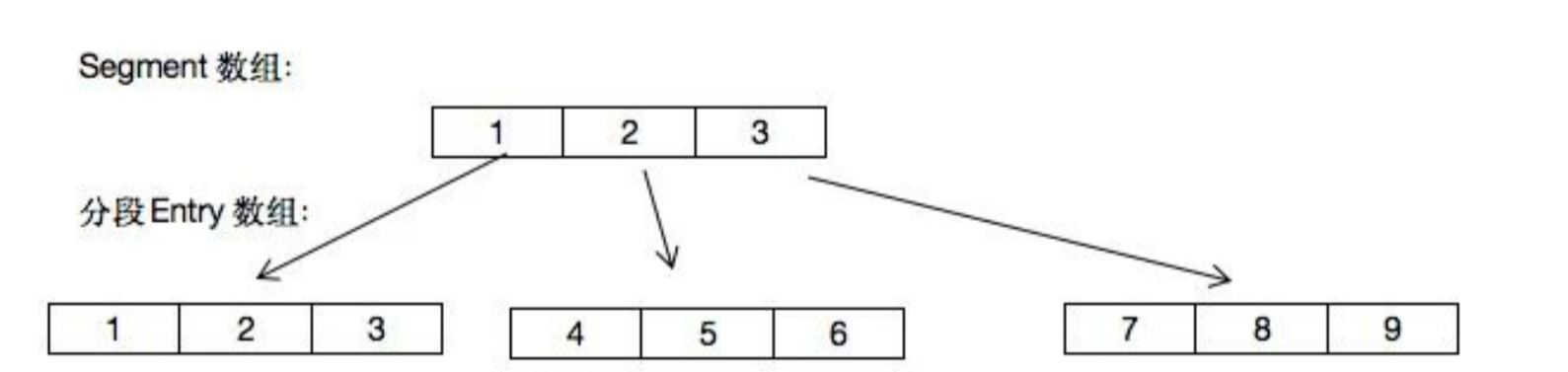
将一个大的Map分成若干个小的segment,每个segment使用一个独立的锁来保证线程安全,多个线程访问不同segment时可以并发访问,从而提高了并发性能。这相对于直接对整个map同步synchronized是有优势的。
那为什么J DK8 又舍弃掉了分段锁呢?
-
Segment的个数是不能变的,因此随着put的数据越多,每个Segment也就越来越大,锁的粒度也就会变得越大。此时,当某个段很大时,分段锁的性能会下降。
-
分成很多段时会比较浪费内存空间(不连续,碎片化);
-
操作map时竞争同一个分段锁的概率非常小时,分段锁反而会造成更新等操作的长时间等待;
因此,Java8中废除了分段锁,采用了一种新的方式来保证线程安全性。
扩展:为什么JDK8不用ReentrantLock而用synchronized
-
减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
-
内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。
为什么key 和 value 不允许为 null
HashMap中,null可以作为键或者值都可以。而在ConcurrentHashMap中,key和value都不允许为null。
ConcurrentHashMap的作者——Doug Lea的解释如下:

主要意思就是说:
ConcurrentMap(如ConcurrentHashMap、ConcurrentSkipListMap)不允许使用null值的主要原因是,在非并发的Map中(如HashMap),是可以容忍模糊性(二义性)的,而在并发Map中是无法容忍的。
假如说,所有的Map都支持null的话,那么map.get(key)就可以返回null,但是,这时候就会存在一个不确定性,当你拿到null的时候,你是不知道他是因为本来就存了一个null进去还是说就是因为没找到而返回了null。
在HashMap中,因为它的设计就是给单线程用的,所以当我们map.get(key)返回null的时候,我们是可以通过map.contains(key)检查来进行检测的,如果它返回true,则认为是存了一个null,否则就是因为没找到而返回了null。
但是,像ConcurrentHashMap,它是为并发而生的,它是要用在并发场景中的,当我们map.get(key)返回null的时候,是没办法通过map.contains(key)(ConcurrentHashMap有这个方法,但不可靠)检查来准确的检测,因为在检测过程中可能会被其他线程锁修改,而导致检测结果并不可靠。
所以,为了让ConcurrentHashMap的语义更加准确,不存在二义性的问题,他就不支持null。
文章转载自:seven97_top
原文链接:https://www.cnblogs.com/seven97-top/p/18421483
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构