在数据库管理系统中,索引是提升查询性能的关键。MySQL支持多种类型的索引,其中最基础也是最重要的两种是聚集索引和非聚集索引。本文将深入探讨这两种索引的区别,并通过实例、UML图以及Java代码示例来帮助您更好地理解和应用它们。
一、概念解析
聚集索引(Clustered Index)
聚集索引决定了表中数据的物理存储顺序。一个表只能有一个聚集索引,因为数据行本身只能按一种顺序存储。通常情况下,主键被用作聚集索引,因为它确保了每一行数据的唯一性并且能有效地对数据进行排序。
- 特点:
- 数据按索引键值的顺序存储。
- 表中仅能存在一个聚集索引。
- 插入新数据可能导致页分裂,影响插入效率。
- 非常适合范围查询,如
BETWEEN,<,>等操作。
非聚集索引(Non-clustered Index)
非聚集索引不改变数据的实际存储顺序,而是创建了一个独立的索引结构,其中包含了指向实际数据位置的指针。因此,一个表可以拥有多个非聚集索引。
- 特点:
- 索引树和数据分开存储。
- 可以有多个非聚集索引。
- 更适合精确查找,比如
=,IN等操作。 - 查询时需要两次查找:先找到索引条目,再通过指针访问数据。
二、实例说明
考虑一个简单的employees表:
CREATE TABLE employees (emp_id INT PRIMARY KEY,first_name VARCHAR(50),last_name VARCHAR(50),hire_date DATE
);
假设我们在这个表上定义了emp_id作为聚集索引,同时为last_name字段添加了一个非聚集索引:
CREATE INDEX idx_last_name ON employees(last_name);
当我们执行如下查询时:
- 对于
SELECT * FROM employees WHERE emp_id = 2;,由于使用了聚集索引,可以直接定位到ID为2的记录。 - 对于
SELECT * FROM employees WHERE last_name = 'Smith';,则首先在非聚集索引中查找‘Smith’对应的记录指针,然后根据该指针访问具体的数据行。
三、UML图示例
UML类图
以下是一个UML类图的PlantUML表示,描述了employees表及其索引关系:

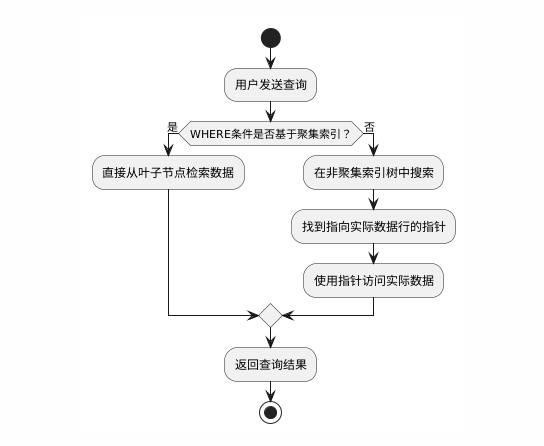
数据流图(查询执行流程)
下面是一个活动图,展示了基于聚集索引和非聚集索引的查询执行过程:
四、Java代码示例
为了演示如何使用JDBC连接到MySQL数据库并执行基于索引的查询,这里提供了一段示例代码:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;public class MySQLIndexExample {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/yourDatabase";String user = "root";String password = "password";try (Connection conn = DriverManager.getConnection(url, user, password)) {// 使用聚集索引(emp_id)查询String clusteredQuery = "SELECT * FROM employees WHERE emp_id = ?";PreparedStatement stmt1 = conn.prepareStatement(clusteredQuery);stmt1.setInt(1, 2);ResultSet rs1 = stmt1.executeQuery();System.out.println("来自聚集索引查询的结果:");while (rs1.next()) {System.out.println("员工ID: " + rs1.getInt("emp_id"));System.out.println("姓名: " + rs1.getString("first_name") + " " + rs1.getString("last_name"));System.out.println("入职日期: " + rs1.getDate("hire_date"));}// 使用非聚集索引(last_name)查询String nonClusteredQuery = "SELECT * FROM employees WHERE last_name = ?";PreparedStatement stmt2 = conn.prepareStatement(nonClusteredQuery);stmt2.setString(1, "Smith");ResultSet rs2 = stmt2.executeQuery();System.out.println("\n来自非聚集索引查询的结果:");while (rs2.next()) {System.out.println("员工ID: " + rs2.getInt("emp_id"));System.out.println("姓名: " + rs2.getString("first_name") + " " + rs2.getString("last_name"));System.out.println("入职日期: " + rs2.getDate("hire_date"));}} catch (Exception e) {e.printStackTrace();}}
}
通过上述内容,详细地介绍了MySQL中的聚集索引和非聚集索引,包括它们的基本概念、工作原理、如何利用这些索引来优化查询性能,以及如何通过Java代码实现相关的数据库操作。
















![[GESP202503 C++一级题解]:B4257:图书馆里的老鼠](https://i-blog.csdnimg.cn/direct/ca19bd59784c41719c7586f67aa626e8.png#pic_center)

