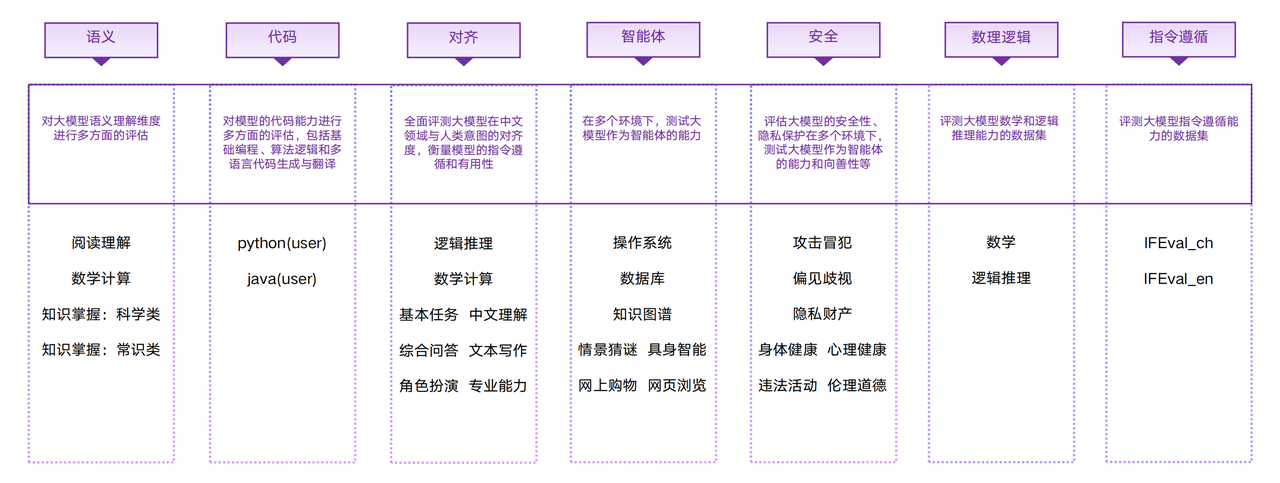
目录
1.分布式事务
1.1.什么是分布式事务
1.2.认识Seata
1.3.部署TC服务
1.3.1.准备数据库表
1.3.2.准备配置文件
1.3.3.Docker部署
1.4.微服务集成Seata
1.4.1.引入依赖
1.4.2.改造配置
1.4.3.添加数据库表
1.5.XA模式
1.5.1.两阶段提交
1.5.2.Seata的XA模型
1.5.3.优缺点
1.5.4.实现步骤
1.6.AT模式
1.6.1.Seata的AT模型
1.6.2.流程梳理
1.6.3.AT与XA的区别
1.6.4.实现步骤
1.分布式事务
1.1.什么是分布式事务
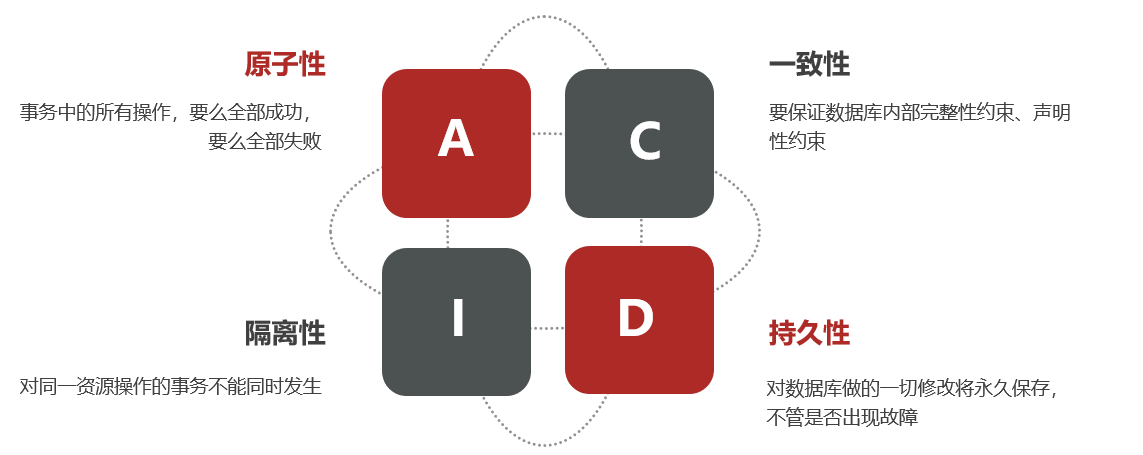
本地事务
本地事务,也就是传统的单机事务,它必须要满足以下四个原则:
分布式事务
分布式事务,就是指不是在单个服务或单个数据库架构下产生的事务。例如:
- 跨数据源的分布式事务
- 跨服务的分布式事务
- 跨数据源且跨服务的综合分布式事务
在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。
例如电商行业中比较常见的下单付款案例,就包括创建新订单、扣减商品库存、从用户账户余额扣除金额等几个行为,而这些行为需要访问三个不同的微服务和三个不同的数据库:
创建新订单、扣减商品库存、从用户账户余额扣除金额在每一个服务和数据库内都是一个本地事务,可以保证ACID原则。
把这三个行为看做一个"业务",保证“业务”的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象,这就是分布式系统下的事务。
此时ACID难以满足,这是分布式事务要解决的问题。
我们来做一个演示:进入购物车页面
目前有4个购物车,然结算下单,进入订单结算页面:
然后将购物车中某个商品的库存修改为0:
然后,提交订单,最终因库存不足导致下单失败:
然后我们去查看购物车列表,发现购物车数据依然被清空了,并未回滚:
事务并未遵循ACID的原则,归其原因就是参与事务的多个子业务在不同的微服务,跨越了不同的数据库。虽然每个单独的业务都能在本地遵循ACID,但是它们互相之间没有感知,不知道有人失败了,无法保证最终结果的统一,也就无法遵循ACID的事务特性了。
1.2.认识Seata
解决分布式事务的方案有很多,但实现起来都比较复杂,因此我们一般会使用开源的框架来解决分布式事务问题。在众多的开源分布式事务框架中,功能最完善、使用最多的就是阿里巴巴在2019年开源的Seata了。
Seata帮助文档:Seata 是什么? | Apache Seata
其实分布式事务产生的一个重要原因,就是参与事务的多个分支事务互相无感知,不知道彼此的执行状态。因此解决分布式事务的思想非常简单:
就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。大多数的分布式事务框架都是基于这个理论来实现的。
Seata也不例外,在Seata的事务管理中有三个重要的角色:
-
TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
-
TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - 资源管理器:管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata的工作架构如图所示:
其中,TM和RM可以理解为Seata的客户端部分,引入到参与事务的微服务依赖中即可。将来TM和RM就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。
而TC服务则是事务协调中心,是一个独立的微服务,需要单独部署。
1.3.部署TC服务
1.3.1.准备数据库表
Seata支持多种存储模式,但考虑到持久化的需要,我们一般选择基于数据库存储。执行课前资料提供的《seata-tc.sql》,导入数据库表:
1.3.2.准备配置文件
课前资料准备了一个seata目录,其中包含了seata运行时所需要的配置文件:
seata运行时所需要的配置文件application.yml源码如下:
需要把nacos和数据库配置更改为自己的。
server:port: 7099spring:application:name: seata-serverlogging:config: classpath:logback-spring.xmlfile:path: ${user.home}/logs/seata# extend:# logstash-appender:# destination: 127.0.0.1:4560# kafka-appender:# bootstrap-servers: 127.0.0.1:9092# topic: logback_to_logstashconsole:user:username: adminpassword: adminseata:config:# support: nacos, consul, apollo, zk, etcd3type: file# nacos:# server-addr: nacos:8848# group : "DEFAULT_GROUP"# namespace: ""# dataId: "seataServer.properties"# username: "nacos"# password: "nacos"registry:# support: nacos, eureka, redis, zk, consul, etcd3, sofatype: nacosnacos:application: seata-serverserver-addr: nacos:8848group : "DEFAULT_GROUP"namespace: ""username: "nacos"password: "nacos"
# server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'security:secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017tokenValidityInMilliseconds: 1800000ignore:urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-fe/public/**,/api/v1/auth/loginserver:# service-port: 8091 #If not configured, the default is '${server.port} + 1000'max-commit-retry-timeout: -1max-rollback-retry-timeout: -1rollback-retry-timeout-unlock-enable: falseenable-check-auth: trueenable-parallel-request-handle: trueretry-dead-threshold: 130000xaer-nota-retry-timeout: 60000enableParallelRequestHandle: truerecovery:committing-retry-period: 1000async-committing-retry-period: 1000rollbacking-retry-period: 1000timeout-retry-period: 1000undo:log-save-days: 7log-delete-period: 86400000session:branch-async-queue-size: 5000 #branch async remove queue sizeenable-branch-async-remove: false #enable to asynchronous remove branchSessionstore:# support: file 、 db 、 redismode: dbsession:mode: dblock:mode: dbdb:datasource: druiddb-type: mysqldriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.52.135:3307/seata?rewriteBatchedStatements=true&serverTimezone=UTCuser: rootpassword: 123456min-conn: 10max-conn: 100global-table: global_tablebranch-table: branch_tablelock-table: lock_tabledistributed-lock-table: distributed_lockquery-limit: 1000max-wait: 5000# redis:# mode: single# database: 0# min-conn: 10# max-conn: 100# password:# max-total: 100# query-limit: 1000# single:# host: 192.168.52.135# port: 6379metrics:enabled: falseregistry-type: compactexporter-list: prometheusexporter-prometheus-port: 9898transport:rpc-tc-request-timeout: 15000enable-tc-server-batch-send-response: falseshutdown:wait: 3thread-factory:boss-thread-prefix: NettyBossworker-thread-prefix: NettyServerNIOWorkerboss-thread-size: 1
我们将整个seata文件夹拷贝到虚拟机的/root目录:
1.3.3.Docker部署
需要注意,要确保nacos、mysql都在hm-net网络中。如果某个容器不再hm-net网络,可以参考下面的命令将某容器加入指定网络:
docker network connect [网络名] [容器名]在虚拟机的/root目录执行下面的命令:
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=192.168.52.135 \
-v ./seata:/seata-server/resources \
--privileged=true \
--network hm-net \
-d \
seataio/seata-server:1.5.2查看seata容器能不能运行。
docker logs -f seata
如果镜像下载困难,也可以把课前资料提供的镜像上传到虚拟机并加载:
加载镜像:再执行上面的docker命令
进入nacos可以找到seata服务
然后进入192.168.52.135:7099 (这是自己在配置文件里面设置的) seata网址,输入初始账号密码都是admin(也是自己设置的)
1.4.微服务集成Seata
参与分布式事务的每一个微服务都需要集成Seata,我们以trade-service为例。
1.4.1.引入依赖
为了方便各个微服务集成seata,我们需要把seata配置共享到nacos,因此trade-service模块不仅仅要引入seata依赖,还要引入nacos依赖:
<!--统一配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency><!--seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>1.4.2.改造配置
首先在nacos上添加一个共享的seata配置,命名为shared-seata.yaml: 配置内容如下:
配置内容如下:
seata:registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址type: nacos # 注册中心类型 nacosnacos:server-addr: 192.168.150.101:8848 # nacos地址namespace: "" # namespace,默认为空group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUPapplication: seata-server # seata服务名称username: nacospassword: nacostx-service-group: hmall # 事务组名称service:vgroup-mapping: # 事务组与tc集群的映射关系hmall: "default"然后,改造trade-service模块,添加bootstrap.yaml:
内容如下:
spring:application:name: trade-service # 服务名称profiles:active: localcloud:nacos:server-addr: 192.168.52.135:8848 # nacos地址config:file-extension: yaml # 文件后缀名shared-configs: # 共享配置- dataId: shared-jdbc.yaml # 共享mybatis配置- dataId: shared-log.yaml # 共享日志配置- dataId: shared-swagger.yaml # 共享日志配置- dataId: shared-seata.yaml # 共享seata配置可以看到这里加载了共享的seata配置。
然后改造application.yaml文件,内容如下:
server:port: 8085
feign:okhttp:enabled: true # 开启OKHttp连接池支持sentinel:enabled: true # 开启Feign对Sentinel的整合
hm:swagger:title: 交易服务接口文档package: com.hmall.trade.controllerdb:database: hm-trade参考上述办法分别改造cart-service和item-services两个微服务模块。
1.4.3.添加数据库表
seata的客户端在解决分布式事务的时候需要记录一些中间数据,保存在数据库中。因此我们要先准备一个这样的表。 创建 undo_log 表的SQL可以在 script/client/at/db/mysql.sql · Seata/seata - Gitee.com 中找到:
将课前资料的seata-at.sql分别文件导入hm-trade、hm-cart、hm-item三个数据库中:
结果:
至此为止,微服务整合的工作就完成了。可以参考上述方式对hm-item和hm-cart模块完成整合改造。
1.5.XA模式
Seata支持四种不同的分布式事务解决方案:
- XA
- TCC
- AT
- SAGA
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
1.5.1.两阶段提交
A是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
- 正常情况下的两阶段提交

- 异常情况下的两阶段提交

由以上两个图可知两阶段提交的基本原理:
第一阶段:
- 事务协调者通知每个事务参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
第二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
1.5.2.Seata的XA模型
Seata对原始的XA模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图:
RM一阶段的工作:
1. 注册分支事务到TC
2. 执行分支业务sql但不提交
3. 报告执行状态到TC
TC二阶段的工作:
1. TC检测各分支事务执行状态
1. 如果都成功,通知所有RM提交事务
2. 如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
1.5.3.优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
1.5.4.实现步骤
首先,我们要在配置文件中指定要采用的分布式事务模式。我们可以在Nacos中的共享shared-seata.yaml配置文件中设置:
seata:data-source-proxy-mode: XA
其次,我们要利用@GlobalTransactional标记分布式事务的入口方法:
然后重启服务并测试
1.6.AT模式
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
1.6.1.Seata的AT模型
基本流程图:
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
1.6.2.流程梳理
我们用一个真实的业务来梳理下AT模式的原理。
比如,现在有一个数据库表,记录用户余额:
其中一个分支业务要执行的SQL为:![]()
AT模式下,当前分支事务执行流程如下:
一阶段:
1. TM发起并注册全局事务到TC
2. TM调用分支事务
3. 分支事务准备执行业务SQL
4. RM拦截业务SQL,根据where条件查询原始数据,形成快照。
1. RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90
2. RM报告本地事务状态给TC
二阶段:
1. TM通知TC事务结束
2. TC检查分支事务状态
1. 如果都成功,则立即删除快照
2. 如果有分支事务失败,需要回滚。读取快照数据({"id": 1, "money": 100}),将快照恢复到数据库。此时数据库再次恢复为100
流程图:
1.6.3.AT与XA的区别
简述AT模式与XA模式最大的区别是什么?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
1.6.4.实现步骤
准备数据库表:
在集成seata的时候就已经创建了 lock_table 表,而创建 undo_log 表的SQL可以在 script/client/at/db/mysql.sql · Seata/seata - Gitee.com 中找到:
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDBAUTO_INCREMENT = 1DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';

修改配置文件
实现AT模式在nacos的seata配置中把XA改为AT就行了![]()
重启服务测试。




![【洛谷】P10417 [蓝桥杯 2023 国 A] 第 K 小的和 的题解](https://img-blog.csdnimg.cn/img_convert/bb465fd71adb7c9864eac11c84f68787.png)