GANMcC
- 简单介绍
- 网络结构
- 生成器
- 辨别器
- 损失函数
- 生成器损失函数
- 辨别器
- tips
- 总结
- 参考
论文:https://ieeexplore.ieee.org/document/9274337
如有侵权请联系博主
这几天又读了一篇关于GAN实现红外融合的论文,不出意外,还是FusionGAN作者团队的人写出的论文,相比之前的GAN实现红外图像融合的论文,这篇论文又提出了新的一些解决思路。一起来看看吧。

简单介绍
读过了几篇图像融合的论文,对这个领域稍微入门了一些,见到了各种各样的方法,不得不说,大佬们真的强。

今天要说的这篇论文是基于GAN来实现的,这篇论文提供给我的最重要的一个点就是在保存纹理细节和对比度上的处理。之前我们读过的大部分论文在这方面的处理都只是保留可视图像的纹理信息和红外图像的对比度,但正如这篇论文的作者所说的那样,可视图像的对比度和红外图像的纹理信息同样也值得我们注意。如下图,左边是可视图像,右边是红外图像

仔细观察上图的信息,你会发现第一行中的右边红外图像中树叶纹理信息反而保存的更好,第二行中可视图像的对比度更强,事情就开始变得有趣起来了,接下来我们一点点去聊这篇论文。

网络结构
先看下总体的网络结构
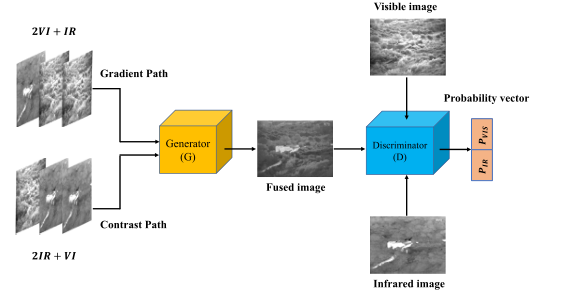
相比于DIVFusion的网络结构,还算是蛮简单的,接下来我们一点点去了解网络的组成部分。
生成器
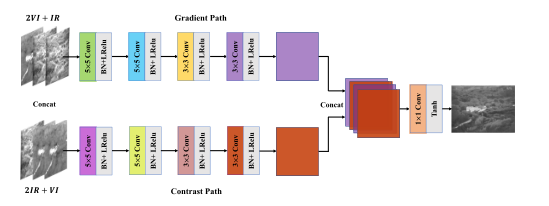
上图为生成器的网络结构,生成器的输入分为两个路径,分别是梯度路径和对比度路径,梯度路径包含两个可视图像和一个红外图像,对比度路径包含两个红外图像和一个可视图像。与FusionGAN相同,这里的输入图像都要被填充到132x132大小,从而保证最终生成的图像与输入图像有相同的大小。
两个路径的输入首先经过四层卷积(卷积核,激活函数和批量归一化的具体内容在图中都有表示),提取特征,然后将两个路径提取的特征连接到一起,经过一个1x1的卷积和激活就生成了目标图像。
这里有一个很有趣的地方,这里的生成器的输入不是单张的可视图像和红外图像,反而是这样多张的堆叠。
辨别器
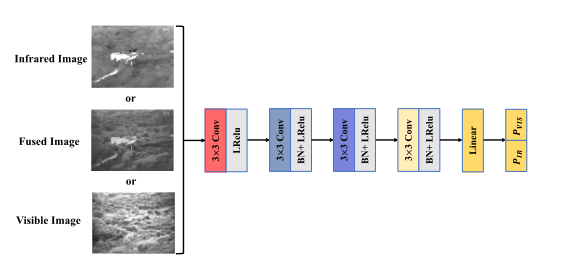
辨别器的网络结构如上图所示,细心的你会发现,最终输出和我们之前看到GAN不大一样。
回忆一下FusionGAN和DDcGAN,你会发现二者的辨别器最终都是只输出一个一维概率,即使像DDcGAN这样的双辨别器,最终输出也只是一维概率,而GANMcC中的辨别器的输出则是一个二维数据。
那么为什么要这么设计呢?
这里论文作者的逻辑与其他人的稍微有些不同,辨别器输出的二维数据分别代表输入图像是可视图像的概率和输入图像是红外图像的概率。
那么怎么应用这个二维数据?
现在想一下这个模型的作用,即生成一个包含更多纹理信息和对比度信息的融合图像,带入到GAN的架构中,是不是我们希望融合图像包含更多纹理信息就代表辨别器认为融合图像就是可视图像的概率越高越好,同样对于可视图像也是如此,即当融合图像输入到辨别器中输出的两个概率都很大时,我们的融合效果就很好了。在损失函数中我们详细的讲一下这个过程。
现在回到标题,你就会发现多分类就在这呢
损失函数
生成器损失函数
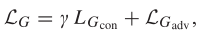
生成器整体的损失函数如上图所示,第一部分是纹理和对比度损失,第二部分是与辨别器的对抗损失。
这里的LGcon相对复杂一点,正如我们前面说的,一方面我们要保证可视图像的纹理和红外图像的对比度,另一方面我们还要保证可视图像的对比度和红外图像的纹理。
下面先讲LGcon的两个损失函数,这两个损失函数的作用就是保证融合图像中有可视图像的纹理特征和红外图像的对比度信息。
下面公式用于保证融合图像尽量包含更多红外图像中的对比度信息(以图像像素强度来保证对比度信息)
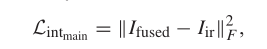
下面公式用于保证融合图像中包含更多可视图像中的纹理信息(这里以梯度信息来保证纹理信息)
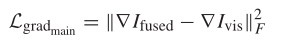
到了这里还没有结束,前文中提到,我们还要保留红外图像中的纹理信息和可视图像中的对比度信息,因此我们还要为保留这两类信息设计损失函数,如下。和上面的公式相同,就是计算梯度的对象变成了红外图像,计算强度(对比度信息)的变成了可视图像
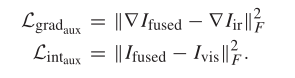
最终一个大汇总
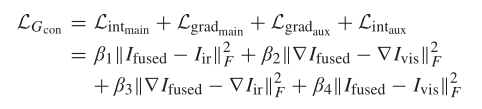
其中β1 > β4, β2 > β3, {β2, β3} > {β1, β4}
那么为什么要这么设置β呢?
这里作者在论文中做了解释,首先β1是融合图像与红外图像对比度之间损失函数的参数,β4是融合图像和可视图像对比度之间损失函数的参数,因为我们要保留的对比度信息主要来自红外图像,所以β1 > β4;同理也应设置β2 > β3。
那么为什么要设置{β2, β3} > {β1, β4}?作者在论文中提到梯度损失项的值往往小于对比度损失项,为了在训练过程中可以保证可以保留纹理信息和对比度信息相平衡,这里就要设置{β2, β3} > {β1, β4},即将纹理损失的参数设置的比对比度的参数要大。
到这里为止,生成器单独保证梯度信息和对比度信息的损失函数就讲完了。
因为文章中使用的网络架构是GAN,因此还需要与辨别器进行对抗,损失函数如下
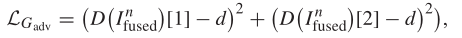
观察前面整个架构的图片,你会发现辨别其输出的是一个二维的向量,向量的第一个位置的数据代表输入图像为可视图像的概率,即D(Ifuse)[1];向量的第二个位置的数据代表输入图像为红外图像的概率,即D(Ifuse)[2]。
这样上面的损失函数就比较容易看懂了。因为希望辨别器认为融合图像是可视图像,同样也认为融合图像是红外图像,因此这里的d设置为1,这样训练之后的结果就会使得融合图像既像可视图像也像红外图像。
辨别器
辨别器的整体损失函数如下
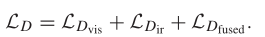
从左到右依次为可视图像辨别的损失,红外图像辨别的损失和融合图像辨别的损失。
他们的作用是什么呢?
很清楚,可视(红外或融合)图像辨别的损失是帮助辨别器拥有更强的识别判断是否是可视(红外或融合)图像的能力,将这三者结合在一起,就会使得辨别器拥有更好的识别可视图像,红外图像和融合图像的能力。
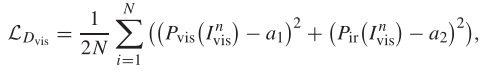
先看下可视图像辨别能力的损失函数。这里你会发现咋又多了个函数,Pvis,Pir是啥,别急,其实Pvis就对应我们前面生成器提到的D(Ifuse)[1],Pir就对应D(Ifuse)[2].
现在思考一下,如果你希望辨别器提高识别可是图像的能力,是不是说你希望输入一个可视图像,输出的Pvis尽可能的接近1,而Pir尽可能接近0,如果你是这么想的话,那恭喜你,你想对了。这里的
a1就设置为1,a2就设置为0。
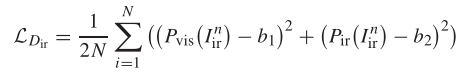
上面的损失函数是帮助辨别器提高辨别红外图像的能力,同上一个损失函数,这里的b1设置0,b2设置1,原因可以类比可以类比上一个可视图像识别损失函数。
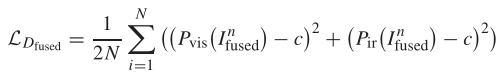
最后一个损失函数就是帮助辨别器提高识别融合图像的能力。以辨别器的角度来看,图像被他分成了三类,分别是可视图像,红外图像和融合图像,但是上面的只有两个概率(图像为可视和红外图像的概率),那应该怎么判别图像为融合图像的概率呢?
这里试想一下,如果说辨别器处理一个图像之后输出的可视图像概率和红外图像概率都很小,是不是代表这个图像在辨别器眼里不是可视图像,也不是红外图像,而辨别器中的图像共有三类,不是那两类,那就是第三类了,也就是融合图像,这样的话,我们就晓得了,那么c就设置为0,即让辨别器认为融合图像既不是可视图像也不是红外图像,从而实现辨别融合图像的功能。
tips
这里注意下,在论文的参数设置那里提到了关于损失函数中的a1,a2,b1,b2和c的设置,这里采用软标签,即本来应设置为1的,设置为0.7到1.2之间的一个随机数;而本来设置为0,被设置为0到0.3之间的随机数。而前面设置为1或0,只是为了方便大家理解。
总结
同样又是一篇收获满满的文章,这里简要说一下
- 提取纹理信息时不仅仅只关注可视图像,同样也关注红外图像的纹理信息
- 提取对比度信息时不仅仅只关注红外图像,同样也关注可视图像的对比度信息
- 辨别器生成多分类的概率
其他融合图像论文解读
读论文专栏,快来点我呀
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】DDcGAN
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] GANMcC: A Generative Adversarial Network With Multiclassification Constraints for Infrared and Visible Image Fusion