多线程回顾
多线程实现的4种方式
1. 继承 Thread 类
通过继承 Thread 类并重写 run() 方法实现多线程。
public class MyThread extends Thread {@Overridepublic void run() {System.out.println("线程运行: " + Thread.currentThread().getName());}
}// 使用
public static void main(String[] args) {MyThread thread = new MyThread();thread.start(); // 启动线程
}
特点:
- 缺点:Java 单继承的限制,无法再继承其他类。
- 适用场景:简单任务,无需共享资源。
2. 实现 Runnable 接口
实现 Runnable 接口,将任务逻辑写在 run() 方法中。
public class MyRunnable implements Runnable {@Overridepublic void run() {System.out.println("线程运行: " + Thread.currentThread().getName());}
}// 使用
public static void main(String[] args) {Thread thread = new Thread(new MyRunnable());thread.start();
}
特点:
- 优点:避免单继承限制,适合资源共享(如多个线程处理同一任务)。
- 推荐场景:大多数情况下优先使用。
3. 实现 Callable 接口 + Future
通过 Callable 允许返回结果和抛出异常,结合 Future 或 FutureTask 获取异步结果。
import java.util.concurrent.*;public class MyCallable implements Callable<String> {@Overridepublic String call() throws Exception {return "执行结果: " + Thread.currentThread().getName();}
}// 使用
public static void main(String[] args) throws Exception {ExecutorService executor = Executors.newSingleThreadExecutor();Future<String> future = executor.submit(new MyCallable());System.out.println(future.get()); // 阻塞获取结果executor.shutdown();
}
特点:
- 优点:支持返回值和异常处理。
- 适用场景:需要获取线程执行结果的场景。
4. 使用线程池(Executor 框架)
通过 Executors 工具类创建线程池,统一管理线程资源。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ThreadPoolDemo {public static void main(String[] args) {ExecutorService executor = Executors.newFixedThreadPool(3);for (int i = 0; i < 5; i++) {executor.execute(() -> {System.out.println("线程运行: " + Thread.currentThread().getName());});}executor.shutdown();}
}
特点:
- 优点:降低资源消耗,提高线程复用率,支持任务队列和拒绝策略。
- 推荐场景:生产环境首选,高并发任务处理。
对比与建议
| 方式 | 返回值 | 异常处理 | 灵活性 | 资源消耗 |
|---|---|---|---|---|
继承 Thread | 不支持 | 有限 | 低 | 高 |
实现 Runnable | 不支持 | 有限 | 高 | 低 |
实现 Callable | 支持 | 支持 | 高 | 中 |
线程池(Executor) | 支持 | 支持 | 最高 | 最低 |
建议:
- 优先选择 实现
Runnable/Callable接口,避免继承局限性。 - 生产环境务必使用 线程池,提升性能并确保稳定性。
- 需要结果时使用
Callable+Future,简单任务用Runnable。
线程池ExecutorService的7大参数
线程池构造函数
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler
)
参数说明
1. 核心线程数(corePoolSize)
- 作用:线程池中始终保持存活的线程数量(即使空闲)。
- 特点:
- 默认情况下,核心线程在空闲时不会销毁(除非设置
allowCoreThreadTimeOut(true))。
- 默认情况下,核心线程在空闲时不会销毁(除非设置
2. 最大线程数(maximumPoolSize)
- 作用:线程池允许创建的最大线程数(包括核心线程和非核心线程)。
- 规则:
- 当任务队列已满且当前线程数小于最大线程数时,会创建新线程处理任务。
3. 线程存活时间(keepAliveTime + unit)
- 作用:非核心线程空闲时的存活时间。
unit为时间单位 - 规则:
- 非核心线程在空闲时间超过
keepAliveTime后会被销毁。 - 如果
allowCoreThreadTimeOut(true),核心线程也会受此时间限制。
- 非核心线程在空闲时间超过
4. 任务队列(workQueue)
- 作用:用于存放待执行任务的阻塞队列。
- 常见队列类型:
- 无界队列:如
LinkedBlockingQueue(默认无界,可能导致 OOM)。 - 有界队列:如
ArrayBlockingQueue(需指定容量)。 - 同步移交队列:如
SynchronousQueue(不存储任务,直接移交线程)。
- 无界队列:如
5. 线程工厂(threadFactory)
- 作用:自定义线程的创建方式(如命名、优先级、是否为守护线程等)。
- 默认实现:
Executors.defaultThreadFactory()。
6. 拒绝策略(handler)
- 作用:当任务队列已满且线程数达到最大时,如何处理新提交的任务。
- 常见策略:
AbortPolicy(默认):抛出RejectedExecutionException异常,且不会静默丢弃任务CallerRunsPolicy:由提交任务的线程直接执行任务。DiscardPolicy:静默丢弃新任务。DiscardOldestPolicy:丢弃队列中最旧的任务,尝试重新提交新任务。
运行流程
1. 线程池创建,准备好 core 数量的核心线程,准备接受任务2. 新的任务进来,用 core 准备好的空闲线程执行。(1)、core满了,就将再进来的任务放入阻塞队列中。空闲的 core 就会自己去阻塞队列获取任务执行(2)、阻塞队列满了,就直接开新线程执行,最大只能开到max指定的数量(3)、max都执行好了。Max-core 数量空闲的线程会在 keepAliveTime指定的时间后自动销毁。最终保持到 core 大小(4)、如果线程数开到了 max的数量,还有新任务进来,就会使用 reject 指定的拒绝策略进行处理3. 所有的线程创建都是由指定的 factory 创建的。
- 优先级顺序:核心线程 → 任务队列 → 非核心线程 → 拒绝策略。
- 非核心线程:仅在队列满时创建,空闲超时后销毁。
- 队列选择:
- 无界队列:可能导致 OOM(如
LinkedBlockingQueue)。 - 同步队列:适合高并发快速响应(如
SynchronousQueue)。
- 无界队列:可能导致 OOM(如
常见面试问题:
一个线程池中core 7; max 20; quue 50, 100个并发进来怎么分配:
7个会被立即执行,50个进入阻塞队列,再开13个线程进行执行,剩下的30个就使用拒绝策略
常见4种线程池
A、newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
core是0,所有都可回收
B、newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
固定大小,core=max;都不可回收
C、newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。
定时任务的线程池
D、newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序 (FIFO、LIFO、优先级) 执行。
单线程的线程池,后台从队列里面获取任务,挨个执行
为何实际开发中使用线程池
-
降低资源的消耗
通过重复利用已经创建好的线程降低线程的创建和销毁带来的损耗
-
提高响应速度
因为线程池中的线程数没有超过线程池的最大上限时,有的线程处于等待分配任务的状态,当任务来时无需创建新的线程就能执行
-
提高线程的可管理性
线程池会根据当前系统特点对池内的线程进行优化处理,减少创建和销毁线程带来的系统开销。无限的创建和销毁线程不仅消耗系统资源,还降低系统的稳定性,使用线程池进行统一分配
CompletableFuture异步编排
1. 简介 & 业务场景
Future 是 Java 5 添加的类,用来描述一个异步计算的结果。可以使用isDone方法检查计算是否完成,或者使用get阻塞住调用线程,直到计算完成返回结果,也可以使用cancel 方法停止任务的执行。
虽然Future以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的初衷相违背,轮询的方式又会耗费无谓的 CPU 资源,而且也不能及时地得到计算结果,为什么不能用观察者设计模式当计算结果完成及时通知监听者呢?
CompletableFuture 是 Java 8 引入的一个异步编程工具,位于 java.util.concurrent 包中。它结合了 Lambda 表达式以及丰富的 API,使得编写、组合和管理异步任务变得更加简洁和灵活。
- 主要特点:
- 非阻塞执行:在等待 I/O 或耗时操作时,不会占用主线程,充分利用系统资源。
- 任务组合:支持将多个任务串行化、并行组合或者以其他灵活的方式进行协同工作。
- 异常处理:内置了异常感知与处理机制,可以在任务执行过程中捕获并处理异常。
- 灵活的回调机制:通过丰富的回调方法,可以在任务完成后进行进一步处理。
- 业务场景:
- 高并发场景:如 Web 应用中同时处理大量请求时,通过异步调用提高吞吐量。
- 分布式系统:在微服务架构下,多个服务之间的异步通信和数据聚合。
- I/O 密集型任务:例如文件读写、网络请求、数据库操作等,异步化可以避免线程阻塞。
- 复杂业务流程:当多个任务存在依赖关系或者需要并行处理后再组合结果时,CompletableFuture 能够简化代码逻辑。
谷粒商城中商品详情页的逻辑较为复杂,涉及远程调用

假如商品详情页的每个查询,需要如上标注的事件才能完成,那么用户需要5.5秒之后才能看到商品详情页的内容,这显然是不可接受的,但是如果有多个线程同时完成这6步操作,也许可以在1.5s内响应
2. 启动异步任务
启动异步任务主要有两种常用方法:
-
supplyAsync
用于启动有返回结果的异步任务。典型用法如下:CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {// 执行耗时操作,比如调用远程服务、数据库查询等return "任务结果"; }); -
runAsync
用于启动没有返回结果的异步任务。例如:CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {// 执行任务,但不需要返回结果 }); -
自定义线程池
可以通过传入自定义的Executor来管理线程资源,避免使用默认的 ForkJoinPool,从而更好地控制线程数和任务调度:ExecutorService executor = Executors.newFixedThreadPool(10); CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {// 耗时任务return "结果"; }, executor);
3. 回调与异常感知
CompletableFuture 提供了一系列回调方法,方便在任务完成后自动触发后续操作,同时内置了异常处理能力:
-
常用回调方法:
public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action); public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable>action); public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable>action,Executor executor); public CompletableFuture<T> exceptionally(Function<Throwable,? extends T> fn)whenComplete 可以处理正常和异常的计算结果,exceptionally 处理异常情况。
whenComplete 和 whenCompleteAsync 的区别:
whenComplete:是执行当前任务的线程继续执行 whenComplete 的任务。whenCompleteAsync:是执行把 whenCompleteAsync 这个任务继续提交给线程池来进行执行。方法不以 Async 结尾,意味着 Action 使用相同的线程执行,而 以Async 结尾可能会使用其他线程执行 (如果是使用相同的线程池,也可能会被同一个线程选中执行)。
-
whenComplete
无论任务正常还是异常结束,都可以在此方法中进行后续处理。其回调中可以同时获得任务的结果和异常信息:future.whenComplete((result, exception) -> {if (exception != null) {// 异常处理逻辑} else {// 正常处理逻辑} }); -
exceptionally
用于捕获任务执行过程中出现的异常,并提供一个默认返回值:CompletableFuture<String> futureWithFallback = future.exceptionally(e -> "默认结果");
-
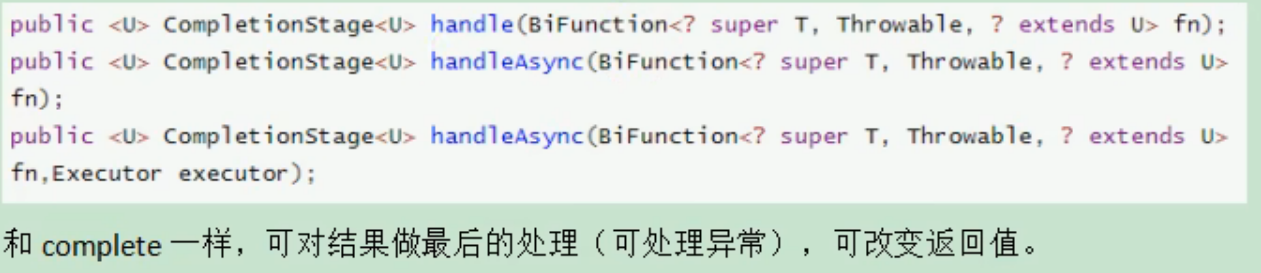
4. handle 最终处理
handle 方法是一个综合性的处理方式,可以同时处理正常结果与异常情况,其回调接收两个参数:上一步的结果和异常对象。你可以在 handle 中根据情况返回一个新的值,用于后续处理。
CompletableFuture<String> handledFuture = future.handle((result, exception) -> {if (exception != null) {// 出现异常时返回默认值return "默认结果";}// 正常时返回经过处理的结果,比如转换为大写return result.toUpperCase();
});
与 whenComplete 不同的是,handle 的返回值可以作为后续任务的输入,从而实现统一的结果处理。
5. 线程串行化
线程串行化是指多个任务按照一定顺序依次执行,前一个任务的输出作为下一个任务的输入。这种方式常见于需要依赖前一个步骤结果的场景:
-
thenApply
用于对上一步结果进行转换:当一个线程依赖另一个线程是,获取上一个人物返回的结果,并返回当前任务的返回值CompletableFuture<String> futureChain = CompletableFuture.supplyAsync(() -> "初始结果").thenApply(result -> result + " -> 处理后结果"); -
thenAccept
消费处理结果。接受任务的处理结果,并消费处理,无返回结果。CompletableFuture<String> futureChain = CompletableFuture.supplyAsync(() -> "初始结果").thenAccept(); -
thenRun
只要上面的任务执行完成,就开始执行thenRun,只是处理完任务之后,执行thenRun的后续操作
public static void main(String[] args) throws ExecutionException, InterruptedException {CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {System.out.println("当前线程:" + Thread.currentThread().getName());int i = 10 / 2;System.out.println("运行结果...." + i);return i;}, executor).thenApplyAsync(res -> {System.out.println("任务二启动了..." + "拿到了上一步的结果:" + res);return res*2;}, executor);Integer integer = future.get();System.out.println("返回数据:"+integer);}
这种链式调用的方式,确保了任务间严格的顺序执行和数据传递,使得编写复杂的业务逻辑更加直观和易于维护。
6. 线程任务组合
两任务组合-都要完成
public <U,V> CompletableFuture<V> thenCombine(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn);public <U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn);public <U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn, Executor executor);public <U> CompletableFuture<Void> thenAcceptBoth(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action);public <U> CompletableFuture<Void> thenAcceptBothAsync(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action);public <U> CompletableFuture<Void> thenAcceptBothAsync(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action, Executor executor);public CompletableFuture<Void> runAfterBoth(CompletionStage<?> other,Runnable action);public CompletableFuture<Void> runAfterBothAsync(CompletionStage<?> other,Runnable action);public CompletableFuture<Void> runAfterBothAsync(CompletionStage<?> other,Runnable action,Executor executor);
两个任务必须都完成,触发该任务。
thenCombine:组合两个future,获取两个future的返回结果,并返回当前任务的返回值
thenAcceptBoth:组合两个future,获取两个future任务的返回结果,然后处理任务,没有返回值。
runAfterBoth:组合两个future,不需要获取future的结果,只需两个future处理完任务后,处理该任务。
两任务组合-一个完成
public <U> CompletableFuture<U> applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn);public <U> CompletableFuture<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn);public <U> CompletableFuture<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn,Executor executor);public CompletableFuture<Void> acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action);public CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action);public CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action,Executor executor);public CompletableFuture<Void> runAfterEither(CompletionStage<?> other,Runnable action);public CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other,Runnable action);public CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other,Runnable action,Executor executor);
当两个任务中,任意一个future任务完成的时候,执行任务。
applyToEither:两个任务有一个执行完成,获取它的返回值,处理任务并有新的返回值。
acceptEither:两个任务有一个执行完成,获取它的返回值,处理任务,没有新的返回值。
runAfterEither:两个任务有一个执行完成,不需要获取future的结果,处理任务,也没有返回值。
多任务组合
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs);public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs);
allOf:等待所有任务完成
anyOf:只要有一个任务完成
示例代码
package com.fancy.gulimall.search.thread;import java.util.concurrent.*;public class ThreadTest {public static ExecutorService executor = Executors.newFixedThreadPool(10);public static void main(String[] args) throws ExecutionException, InterruptedException {System.out.println("main....start....");
// CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 2;
// System.out.println("运行结果:" + i);
// }, executor);/*** 方法完成后的感知* */
// CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 0;
// System.out.println("运行结果:" + i);
// return i;
// }, executor).whenComplete((res,excption)->{
// //虽然能得到异常信息,但是没法修改返回数据。
// System.out.println("异步任务成功完成了...结果是:"+res+";异常是:"+excption);
// }).exceptionally(throwable -> {
// //可以感知异常,同时返回默认值
// return 10;
// });/*** 方法执行完成后的处理*/
// CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 4;
// System.out.println("运行结果:" + i);
// return i;
// }, executor).handle((res, thr) -> {
// if (res != null) {
// return res * 2;
// }
// if (thr != null) {
// return 0;
// }
// return 0;
// });//R apply(T t, U u);/*** 线程串行化* 1)、thenRun:不能获取到上一步的执行结果,无返回值* .thenRunAsync(() -> {* System.out.println("任务2启动了...");* }, executor);* 2)、thenAcceptAsync;能接受上一步结果,但是无返回值* 3)、thenApplyAsync:;能接受上一步结果,有返回值*/
// CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
// System.out.println("当前线程:" + Thread.currentThread().getId());
// int i = 10 / 4;
// System.out.println("运行结果:" + i);
// return i;
// }, executor).thenApplyAsync(res -> {
// System.out.println("任务2启动了..." + res);
//
// return "Hello " + res;
// }, executor);//void accept(T t);//R apply(T t);//future.get()/*** 两个都完成*/
// CompletableFuture<Object> future01 = CompletableFuture.supplyAsync(() -> {
// System.out.println("任务1线程:" + Thread.currentThread().getId());
// int i = 10 / 4;
// System.out.println("任务1结束:" );
// return i;
// }, executor);
//
// CompletableFuture<Object> future02 = CompletableFuture.supplyAsync(() -> {
// System.out.println("任务2线程:" + Thread.currentThread().getId());
//
// try {
// Thread.sleep(3000);
// System.out.println("任务2结束:" );
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// return "Hello";
// }, executor);// future01.runAfterBothAsync(future02,()->{
// System.out.println("任务3开始...");
// }, executor);// void accept(T t, U u);
// future01.thenAcceptBothAsync(future02,(f1,f2)->{
// System.out.println("任务3开始...之前的结果:"+f1+"--》"+f2);
// }, executor);//R apply(T t, U u);
// CompletableFuture<String> future = future01.thenCombineAsync(future02, (f1, f2) -> {
// return f1 + ":" + f2 + " -> Haha";
// }, executor);/*** 两个任务,只要有一个完成,我们就执行任务3* runAfterEitherAsync:不感知结果,自己没有返回值* acceptEitherAsync:感知结果,自己没有返回值* applyToEitherAsync:感知结果,自己有返回值*/
// future01.runAfterEitherAsync(future02,()->{
// System.out.println("任务3开始...之前的结果:");
// },executor);//void accept(T t);
// future01.acceptEitherAsync(future02,(res)->{
// System.out.println("任务3开始...之前的结果:"+res);
// },executor);
// CompletableFuture<String> future = future01.applyToEitherAsync(future02, res -> {
// System.out.println("任务3开始...之前的结果:" + res);
// return res.toString() + "->哈哈";
// }, executor);CompletableFuture<String> futureImg = CompletableFuture.supplyAsync(() -> {System.out.println("查询商品的图片信息");return "hello.jpg";},executor);CompletableFuture<String> futureAttr = CompletableFuture.supplyAsync(() -> {System.out.println("查询商品的属性");return "黑色+256G";},executor);CompletableFuture<String> futureDesc = CompletableFuture.supplyAsync(() -> {try {Thread.sleep(3000);System.out.println("查询商品介绍");} catch (InterruptedException e) {e.printStackTrace();}return "华为";},executor);// CompletableFuture<Void> allOf = CompletableFuture.allOf(futureImg, futureAttr, futureDesc);CompletableFuture<Object> anyOf = CompletableFuture.anyOf(futureImg, futureAttr, futureDesc);anyOf.get();//等待所有结果完成// System.out.println("main....end...."+futureImg.get()+"=>"+futureAttr.get()+"=>"+futureDesc.get());System.out.println("main....end...."+anyOf.get());}
}
谷粒商城业务
业务描述
这个功能主要是满足,在商品详情页面查询时,通过一个接口去获取商品的有关的所有信息
sku基本信息
sku图片信息
获取spu销售属性组合
获取spu介绍
获取spu规格参数信息
其中有些查询是可以同时进行的,有些操作则需要在其他步骤返回结果后,拿到结果去继续查询,最后返回结果。
所以我们为了优化接口的加载速度可以选择异步编排
代码
线程池配置属性类
package com.atguigu.gulimall.product.config;import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;@ConfigurationProperties(prefix = "gulimall.thread")
@Component
@Data
public class ThreadPoolConfigProperties {private Integer coreSize;private Integer maxSize;private Integer keepAliveTime;
}
线程池配置类
package com.atguigu.gulimall.product.config;import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;//@EnableConfigurationProperties(ThreadPoolConfigProperties.class)
@Configuration
public class MyThreadConfig {@Beanpublic ThreadPoolExecutor threadPoolExecutor(ThreadPoolConfigProperties threadPoolConfigProperties) {return new ThreadPoolExecutor(threadPoolConfigProperties.getCoreSize(), threadPoolConfigProperties.getMaxSize(), threadPoolConfigProperties.getKeepAliveTime(), TimeUnit.SECONDS, new LinkedBlockingDeque<>(10000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());}
}
主业务逻辑方法
@Overridepublic SkuItemVo item(Long skuId) throws ExecutionException, InterruptedException {SkuItemVo skuItemVo = new SkuItemVo();CompletableFuture<SkuInfoEntity> infoFuture = CompletableFuture.supplyAsync(() -> {// sku基本信息SkuInfoEntity info = getById(skuId);skuItemVo.setInfo(info);return info;}, executor);CompletableFuture<Void> saleAttrFuture = infoFuture.thenAcceptAsync((res) -> {// spu销售属性组合List<SkuItemSaleAttrVo> saleAttrsBySpuId = skuSaleAttrValueService.getSaleAttrsBySpuId(res.getSpuId());skuItemVo.setSaleAttr(saleAttrsBySpuId);}, executor);CompletableFuture<Void> descFuture = infoFuture.thenAcceptAsync(res -> {// spu介绍SpuInfoDescEntity descEntity = spuInfoDescService.getById(res.getSpuId());skuItemVo.setDesp(descEntity);}, executor);CompletableFuture<Void> baseFuture = infoFuture.thenAcceptAsync((res) -> {// spu的规格参数List<SpuItemAttrGroupVo> groupVos = attrGroupService.getAttrGroupWithAttrsBySpuId(res.getSpuId(), res.getCatalogId());skuItemVo.setGroupAttrs(groupVos);}, executor);CompletableFuture<Void> imagesFuture = CompletableFuture.runAsync(() -> {// sku图片信息List<SkuImagesEntity> skuImages = skuImagesService.getImagesBySkuId(skuId);skuItemVo.setImages(skuImages);}, executor);// 等待所有任务都完成CompletableFuture.allOf(infoFuture,saleAttrFuture,descFuture,baseFuture,imagesFuture).get();return skuItemVo;}