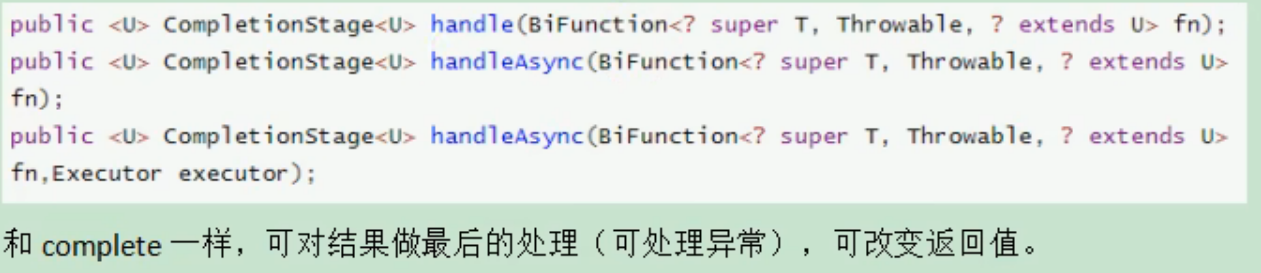
环境:
向量数据库
问题描述:
向量数据库是什么,它有什么作用

解决方案:
向量数据库是一种专门设计用于高效处理高维向量数据的系统,主要用于存储、索引、查询和检索高维向量数据,特别适合处理非结构化数据(如图像、音频、文本)。以下是向量数据库的详细知识:
定义
向量数据库是一种以向量形式存储数据集合的数据库,通过对原始数据应用某种变换或嵌入函数生成向量并进行管理、存储和检索。它能够实现传统数据库难以完成的高级分析和相似性搜索。
功能
- 索引:使用HNSW(分层可导航小世界)算法进行快速索引和搜索。HNSW构建了一个多层图,每个向量是一个节点,连接表示相似性。较高层次连接大体相似的向量,而较低层次则连接紧密相关的向量,使得搜索随着深入逐渐精确。
- 搜索:基于近似最近邻(ANN)算法的高效相似性搜索。当用户向数据库查询时,查询也会被转换成一个向量,算法快速识别图中最可能包含与查询向量最近的区域。
- 更新与删除:支持实时更新和批量修改向量,以及删除过时或重复数据以保持数据库高效和精准。
高级优化
- 量化:通过二进制或标量量化大幅降低内存使用,提升搜索速度至40倍。支持多种量化方法,如二进制量化、标量量化和产品量化。
- 分布式部署:分片(Sharding)将数据分布到多个节点上以实现负载均衡和并行处理;复制(Replication)在多个节点间保留数据副本以提高容错能力和高可用性;多租户架构(Multitenancy)支持不同用户或组织的数据隔离,优化合规性和隐私。
数据安全
- API密钥:通过API密钥进行简单身份验证。
- JWT与RBAC:使用JSON Web Tokens实现基于角色的访问控制。
- 网络隔离和加密:部署专用网络,启用数据传输和存储加密。
应用场景
- 相似性搜索:产品图片匹配、主题文档检索。
- 异常检测:银行用户行为分析、不规则模式识别。
- 推荐系统:个性化推荐(电影、音乐、商品)。
- RAG(检索增强生成):结合大语言模型生成语义相关答案。
- 多模态搜索:跨文本、图像、音频的数据检索。
- 语音与音频识别:语音转文本、声音分类与检索。
- 知识图谱扩展:关联研究文献、客户反馈与产品特性。
工具与支持
- SDKs:提供Python、Go、Rust、JavaScript/TypeScript、C#、Java等多语言支持。
- 文档与社区:丰富的教程、指南以及活跃的社区支持。
关键优势
- 更高效处理非结构化数据。
- 提供上下文语义搜索和关键词匹配的结合能力。
- 在数据安全、扩展性和高可用性方面表现卓越。
以下是常用的向量数据库及其特点和适用场景的总结:
1. Milvus
- 特点:专为大规模向量搜索设计,支持万亿级向量数据集的毫秒级搜索,适用于图像搜索、聊天机器人、化学结构搜索等场景。采用无状态架构,具备高度可扩展性和混合搜索能力。
- 适用场景:大规模数据处理、推荐系统、自然语言处理。
2. Weaviate
- 特点:云原生开源向量数据库,支持多模态数据(文本、图像等)的向量化与检索,内置AI模块(如问答、分类),并与OpenAI、HuggingFace等模型集成。
- 适用场景:语义搜索、实时应用开发。
3. Qdrant
- 特点:基于Rust开发的高性能向量搜索引擎,支持JSON负载过滤和多种数据类型(地理位置、数值范围等),提供高效的近似最近邻搜索(ANN)和容灾恢复功能。
- 适用场景:推荐系统、语义匹配。
4. Chroma
- 特点:专注于简化大型语言模型(LLM)应用的开发,提供嵌入存储、查询和过滤功能,支持与LangChain、LlamaIndex等框架集成。
- 适用场景:小型语义搜索原型、研究或教学项目。
5. Faiss
- 特点:Meta开源的向量搜索库(非数据库),提供高效的向量聚类和相似性搜索算法,支持CPU/GPU加速。
- 适用场景:推荐系统、图像检索。
6. Elasticsearch
- 特点:传统搜索引擎扩展支持向量搜索,结合文本、结构化数据和向量检索,适合混合搜索场景。
- 适用场景:需要同时进行全文搜索和向量搜索的复杂应用。
7. Pinecone
- 特点:商业化的云端向量数据库,由专业团队维护,提供了易于使用和高度可扩展的向量检索服务。
- 适用场景:云端部署、高性能需求的应用。
8. Vald
- 特点:分布式云原生向量搜索引擎,采用NGT算法实现快速ANN搜索,支持自动备份和水平扩展。
- 适用场景:处理数十亿级向量数据。
9. Vespa
- 特点:支持混合搜索(向量+文本+结构化数据),适用于大规模数据实时处理,提供机器学习模型集成和高吞吐写入。
- 适用场景:对性能和功能有极高要求的场景。
10. pgvector
- 特点:PostgreSQL的扩展插件,为传统关系型数据库添加向量搜索功能,适合已有PostgreSQL生态的用户低成本迁移。
- 适用场景:向量数据量较小、对性能要求不高。
选型建议
- 性能与规模:Milvus、Qdrant适合超大规模场景;Chroma、Weaviate适合快速原型开发。
- 多模态支持:Weaviate、Deep Lake支持文本、图像等混合数据。
- 集成生态:Elasticsearch、Vespa适合需要结合传统搜索与AI的应用。
- 轻量级需求:pgvector或Faiss可作为现有系统的补充。
根据具体需求和应用场景选择合适的向量数据库,可以更好地满足性能、扩展性和功能要求。
向量数据库与结构化数据库差异
向量数据库和结构化数据库是两种不同类型的数据库系统,它们在数据类型、查询方式、数据模型、性能、应用场景、扩展性以及数据安全和隐私保护等方面存在显著差异。以下是它们的详细对比:
数据类型
- 向量数据库:主要处理高维向量数据,如文本、图像、音频等非结构化数据。通过嵌入函数将这些数据转换为向量形式进行存储和检索。
- 结构化数据库:处理结构化数据,如表格中的行和列,数据类型通常是预定义的,如整数、字符串、日期等。
查询方式
- 向量数据库:基于相似性搜索,使用近似最近邻(ANN)算法,如HNSW、IVF等,来查找与查询向量最相似的向量。
- 结构化数据库:基于精确匹配,使用SQL查询语言,通过条件过滤(如WHERE子句)来查找与条件匹配的记录。
数据模型
- 向量数据库:通常使用非结构化或半结构化模型,数据以向量形式存储,支持多模态数据(如文本、图像等)。
- 结构化数据库:使用关系模型,数据存储在表格中,通过主键、外键等关系进行关联。
性能
- 向量数据库:在处理高维数据时表现出色,能够高效地进行相似性搜索,特别是在大规模数据集上。
- 结构化数据库:在处理低维、结构化数据时表现出色,查询速度快,特别是在事务处理和精确匹配方面。
应用场景
- 向量数据库:适用于AI和机器学习应用,如推荐系统、语义搜索、图像检索、异常检测等。
- 结构化数据库:适用于传统的企业应用,如ERP、CRM、财务管理等,这些应用通常需要精确的数据匹配和事务处理。
扩展性
- 向量数据库:通常具有良好的扩展性,支持分布式部署,能够处理大规模数据集。
- 结构化数据库:扩展性相对较差,通常需要垂直扩展(增加硬件资源),但在某些情况下也可以通过分片(Sharding)实现水平扩展。
数据安全和隐私保护
- 向量数据库:提供多种安全机制,如API密钥、JWT、RBAC等,支持数据加密和网络隔离。
- 结构化数据库:提供成熟的访问控制和加密机制,如基于角色的访问控制(RBAC)、数据加密(传输和存储)、审计日志等。
总结
- 向量数据库:适合处理非结构化数据和需要相似性搜索的场景,如AI和机器学习应用。
- 结构化数据库:适合处理结构化数据和需要精确匹配的场景,如传统的企业应用。
选择哪种数据库取决于具体的应用需求、数据类型和性能要求。在实际应用中,也可以结合使用向量数据库和结构化数据库,以充分利用它们各自的优势。