Megatron-LM:https://github.com/NVIDIA/Megatron-LM/tree/main
使用此仓库构建的著名的库也有很多,如:
- Colossal-AI, HuggingFace Accelerate, and NVIDIA NeMo Framework.
- Pai-Megatron-Patch工具是阿里人工智能平台PAI算法团队研发,ai-Megatron-Patch是各类开源大模型和Megatron训练加速引擎之间的“桥梁”,为用户提供用Megatron训练开源大模型的易用性以及LLM算法场景定制化的灵活性
- 华为的mindspeed
入口定义文件:
Megatron-LM-main\examples\post_training\modelopt\conf\deepseek-ai\DeepSeek-R1.sh
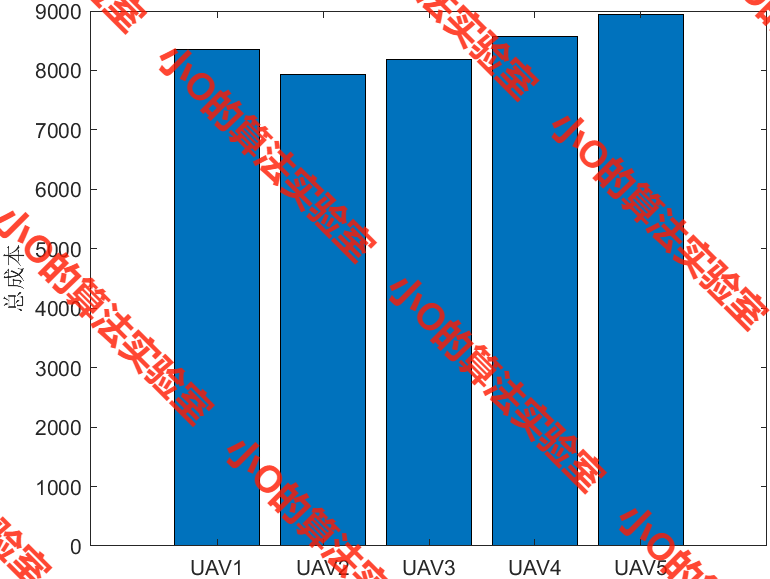
megatron推理服务和vllm对比
推理优化
Megatron 在推理阶段通过多种技术优化推理性能,包括模型并行化和内存优化。它可以将超大规模模型的权重分配到多个 GPU 上,从而保证推理速度。此外,针对推理中的显存占用问题,Megatron 提供了分布式推理方案。
推理过程
对于 Megatron-LM 训练的模型,可以直接用 Megatron-LM 框架进行推理。推理过程包括初始化预训练模型、加载训练好的模型权重、执行推理等步骤。例如,可以使用以下代码进行推理:
from megatron import get_args
from megatron.initialize import initialize_megatron
from megatron.model import GPTModel
import torch
from transformers import GPT2Tokenizer# 初始化配置
args = get_args()
initialize_megatron()# 加载预训练模型
model = GPTModel(num_layers=args.num_layers,hidden_size=args.hidden_size,num_attention_heads=args.num_attention_heads)
model.load_state_dict(torch.load(<checkpoint_path>))
model.eval()# 输入文本
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
input_text = "Once upon a time"
inputs = tokenizer(input_text, return_tensors="pt")# 模型推理
with torch.no_grad():outputs = model(inputs["input_ids"])# 生成输出文本
predicted_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(predicted_text)代码中实现:
examples/inference中有几个实现,要部署还是比较简单的,如:
#!/bin/bash
# This example will start serving the 345M model that is partitioned 8 way tensor parallel
DISTRIBUTED_ARGS="--nproc_per_node 8 \--nnodes 1 \--node_rank 0 \--master_addr localhost \--master_port 6000"CHECKPOINT=<Path to checkpoint (e.g /345m)>
VOCAB_FILE=<Path to vocab.json (e.g. /gpt2-vocab.json)>
MERGE_FILE=<Path to merges.txt (e.g. /gpt2-merges.txt)>pip install flask-restfulpython -m torch.distributed.launch $DISTRIBUTED_ARGS tools/run_text_generation_server.py \--tensor-model-parallel-size 8 \--pipeline-model-parallel-size 1 \--num-layers 24 \--hidden-size 1024 \--load ${CHECKPOINT} \--num-attention-heads 16 \--max-position-embeddings 1024 \--tokenizer-type GPT2BPETokenizer \--fp16 \--micro-batch-size 1 \--seq-length 1024 \--vocab-file $VOCAB_FILE \--merge-file $MERGE_FILE \--seed 42
代码解析资料
根据搜索结果,以下是一些关于Megatron代码分析的专栏和视频资源:
### 专栏资源
1. **知乎专栏:[细读经典]Megatron论文和代码详细分析**
- 作者:迷途小书僮
- 内容:该专栏详细分析了Megatron的论文和代码,包括模型并行化、分布式训练等关键技术。文章从基础概念讲起,逐步深入到代码细节,适合对Megatron有深入了解需求的读者。
- 链接:[细读经典]Megatron论文和代码详细分析
2. **博客园:[源码解析] 模型并行分布式训练Megatron**
- 作者:rossiXYZ
- 内容:该系列文章从Megatron的论文和基础概念入手,详细解读了其张量模型并行和流水线模型并行的实现机制,适合有一定分布式训练基础的读者。
- 链接:[源码解析] 模型并行分布式训练Megatron
3. **知乎专栏:图解大模型系列之:Megatron源码解读**
- 作者:猛猿
- 内容:该系列文章采用图解的方式,详细解读了Megatron的分布式环境初始化、模型并行机制等关键部分,适合希望通过直观方式理解Megatron代码的读者。
- 链接:图解大模型系列之:Megatron源码解读
4. **CSDN博客:跟代码执行流程,读Megatron源码**
- 作者:liuqiker
- 内容:该系列文章从Megatron的目录结构和训练入口开始,逐步深入到代码执行流程和关键模块的实现,适合希望通过代码执行流程来理解Megatron的读者。
- 链接:跟代码执行流程,读Megatron源码
### 视频资源
1. **哔哩哔哩:Megatron-LM技术讲解**
- 作者:poker125
- 内容:该视频详细讲解了Megatron-LM的技术原理,包括模型并行、数据并行等关键概念,适合对Megatron技术原理感兴趣的读者。
- 链接:Megatron-LM技术讲解
2. **哔哩哔哩:Megatron源码走读,代码层面理解1F1B流水线并行**
- 作者:fy-j
- 内容:该视频从代码层面详细解读了Megatron的1F1B流水线并行机制,并提供了相关的思维导图,适合希望通过代码层面理解Megatron并行机制的读者。
- 链接:Megatron源码走读,代码层面理解1F1B流水线并行
这些资源可以帮助你从不同角度深入理解Megatron的代码和实现机制,希望对你有所帮助。