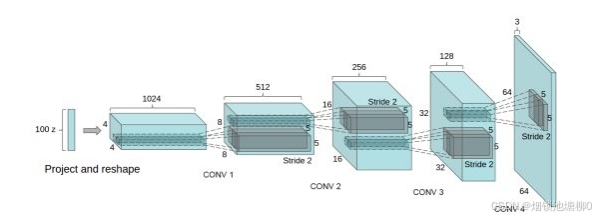
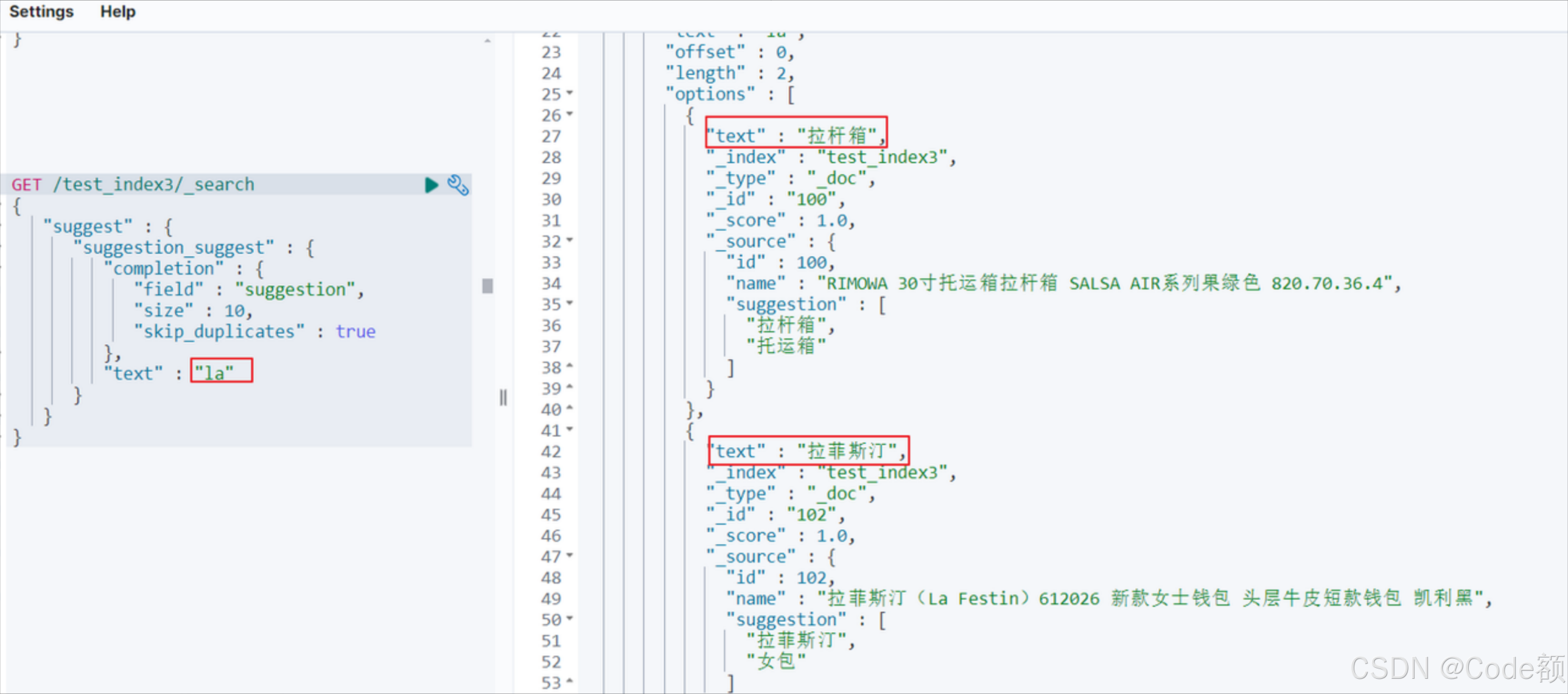
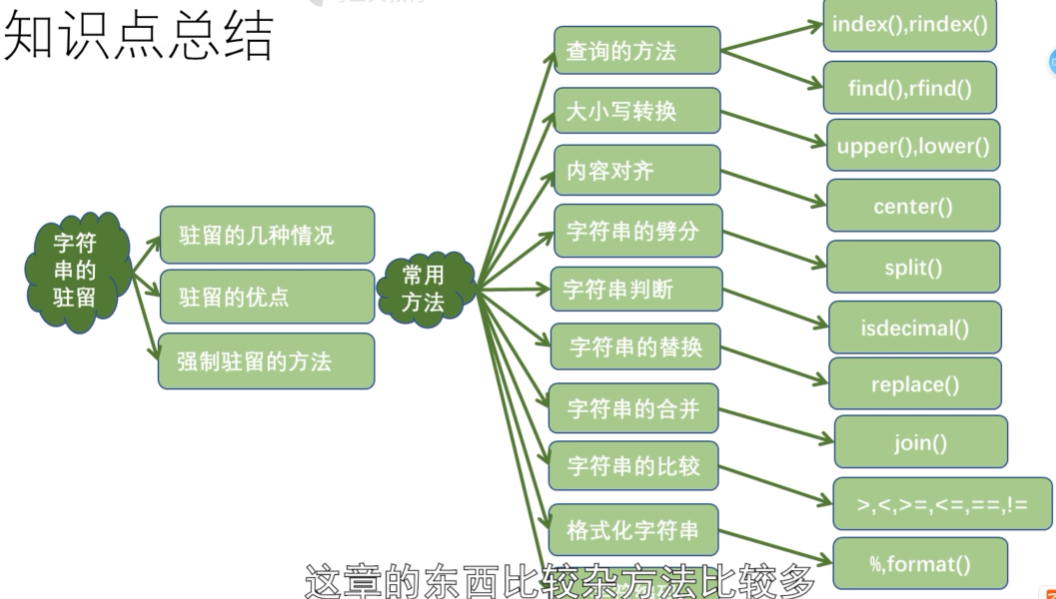
目录
什么是BUG
启动调试
逐过程,逐语句的区别?
打断点
条件断点
小结
之前推荐刚刚学习C/C++的小伙伴使用 Visual Studio 2019 这款工具来写代码。这篇博客就来简单介绍一下Visual Studio 2019 的调试方法~
什么是BUG
在最开始的晶体管的计算机的时候,实验室中的一台计算机,计算得出错误的结果,最终发现是一只臭虫,造成了晶体管故障,后来这个臭虫,BUG就代表了计算机中的计算错误了。
启动调试
我们就简单的以下面这个一段代码来说:

这里我们先说一下我们会用到的快捷键:
F5 开始调试 F10 逐过程 F11 逐语句 F9 打断点
我们按下键盘上的 F10 就可以,开始调试!

像下面的自动窗口,调用堆栈,这些窗口,就是在我们调试的时候为我们提供的一些便于观察程序状态的窗口,在这里我们推荐几个常用的窗口。

监视窗口,自动窗口,等等。
逐过程,逐语句的区别?
逐过程,如果遇到函数,按下 F10 我们就会直接得到这个函数执行后的结果。
逐语句,如果遇到函数,按下 F11 我们就会进入这个函数,看到这个函数内部的详细执行过程。在之前的一些比较老的工具,比如说VC++6.0是可以进入库函数的,现在的 Visual Studio 2019以及一些更加新的工具,都不会进入库函数了。
打断点
断点,就是让程序停在断点的工具。我们可以使用鼠标指针选中一行,之后按键盘上的F9,来打断点,之后按F5,就可以直接跳转到断点那一行。
条件断点
假如说,现在我们的程序有一个循环,要循环10000次,假如说我们要看第5000次,就可以使用条件断点。我在先创建断点,之后右键点击断点,选择“条件”。

设置条件。

之后,我们按F5,就可以执行跳转到 i 变量在50的位置了。
小结
调试,是我们必须要掌握的技巧,因为程序中的一个逻辑错误,是我们无法避免的,我们一定要学会一些解决他们的方式~~~
未来也会再作一个在Linux下GDB调试的博客,大家可以支持一下下。