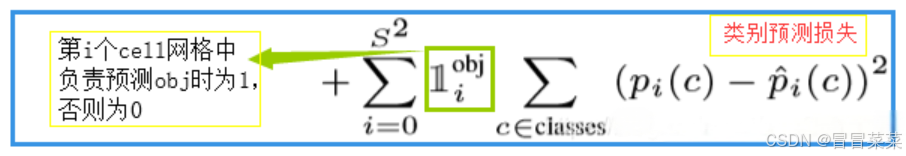文章目录
- 1. 概述
- 2. 算法流程
- 3. 网络结构
- 4. 损失函数
1. 概述
1. YOLO 的全称是 You Only Look Once: Unified, Real-Time Object Detection。YOLOv1 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box 的位置和 bounding box 所属的类别。简单来说,只看一次就知道图中物体的类别和位置。
2. 将一幅图像分成 SxS 个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object。一个格子只能预测一个物体,会生成两个预测框。


注:这里的 ( x , y , w , h , c ) (x,y,w,h,c) (x,y,w,h,c) 和 7 × 7 × 30 7×7×30 7×7×30 请看下文讲解。
3. 每个网格要预测 B 个bounding box(B一般取2),每个 bounding box 除了要回归自身的位置之外,还要附带预测一个 confidence 值。每个 bounding box 共 5 个参数 ( x , y , w , h , c ) (x,y,w,h,c) (x,y,w,h,c)。
- 使用 ( x , y ) (x,y) (x,y) 表示 bounding box 中心相对于方格左上角的偏移量,范围为 [0,1]。
- 使用 ( w , h ) (w,h) (w,h) 表示 bounding box 的宽和高,该值是相对于图像宽高的比,范围为 [0,1]。


- confidence 代表了所预测的 box 中含有 object 的置信度(有则为 1,没有则为 0)和这个 box 预测的有多准两重信息,其值是这样计算的:

该表达式含义:如果有 object 落在一个 grid cell 里,则第一项取 1,否则取 0。 第二项是预测的预测框(predict box)与真实标签框(ground truth)之间的交集(IOU)值。
问题:为什么每个网格有固定的 B 个 bounding box?(即 B=2)
在训练的时候会在线地计算每个 predictor 预测的 bounding box 和 ground truth 的 IOU,计算出来的 IOU 大的那个 predictor,就会负责预测这个物体,另外一个则不预测。这么做有什么好处?我的理解是,这样做的话,实际上有两个 predictor 来一起进行预测,然后网络会在线选择预测得好的那个 predictor(也就是 IOU 大)来进行预测。
2. 算法流程
整个 YOLO 检测系统如下图所示:

- 假设网络实现的预测类别数为 C 个。论文中使用 PASCAL VOC 数据集,C=20,即实现 20 类别物品的目标检测。
- 输入图像首先被 resize 到指定尺寸。论文中将输入图像统一调整到 448 × 448 448 × 448 448×448,即网络输入: 448 × 448 × 3 448 × 448 × 3 448×448×3。
- 对图像进行划分,共划分 S × S S×S S×S 个方格。论文中 S=7, 即共划分 7 × 7 = 49 7 × 7 = 49 7×7=49 个方格,每个方格包含 64 × 64 64 × 64 64×64 个像素点。
- 针对每个方格:生成 C 个类别目标的概率分数(表示该方格是否存在该目标的概率),用 p 表示;生成 B 个检测框,每个检测框共 5 个参数,即 ( x , y , w , h , c ) (x,y,w,h,c) (x,y,w,h,c)。
每个方格输出向量如下图所示。因此针对每个方格,共有参数量为 ( C + B × 5 ) (C+B×5) (C+B×5) 个。本论文中,即 ( 20 + 2 × 5 ) = 30 (20+2×5)=30 (20+2×5)=30 个。

- 针对一张图片,最终输出向量: S × S × ( C + B × 5 ) S×S×(C+B×5) S×S×(C+B×5)。本论文中即 7 × 7 × 30 = 1470 7 × 7 × 30 = 1470 7×7×30=1470。
- 对输出向量进行后处理,得到最终预测结果。
3. 网络结构
1. 网络结构如下所示。输入: 448 × 448 × 3 448×448×3 448×448×3,输出: 7 × 7 × 30 7×7×30 7×7×30。

针对卷积我们以图片的前两次为例计算一下。卷积计算大致就是如下所示这么一个过程。

2. 网络详解:
(1) YOLO 主要是建立一个 CNN 网络生成预测 7 × 7 × 1024 7×7×1024 7×7×1024 的张量 。
(2) 然后使用两个全连接层执行线性回归,以进行 7 × 7 × 2 7×7×2 7×7×2 边界框预测。将具有高置信度得分(大于 0.25)的结果作为最终预测。
(3) 在 3 × 3 3×3 3×3 的卷积后通常会接一个通道数更低 1 × 1 1×1 1×1 的卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力。
(4) 除了最后一层使用了线性激活函数外,其余层的激活函数为 Leaky ReLU 。
(5) 在训练中使用了 Dropout 与数据增强的方法来防止过拟合。
(6) 对于最后一个卷积层,它输出一个形状为 (7, 7, 1024) 的张量。 然后张量展开。使用 2 个全连接层作为一种线性回归的形式,它输出 1470 个参数,然后 reshape 为 (7, 7, 30) 。

4. 损失函数
1. 损失即计算网络输出值(或预测值)与标签值差异的程度。举例说明,如上图的包含狗狗的方格,对应的标签值与预测值形式如下:

2. YOLOv1 中损失函数共包含三项,即:(1) 坐标预测损失、(2) 置信度预测损失、(3) 类别预测损失。三个损失函数都使用了均方误差。计算公式如下所示:


问题:为什么坐标损失中的 w w w 和 h h h 要加根号?
在上图中,大框和小框的 bounding box 和 ground truth 都是差了一点,但对于实际预测来讲,大框(大目标)差的这一点也许没啥事儿,而小框(小目标)差的这一点可能就会导致bounding box的方框和目标差了很远。而如果还是使用第一项那样直接算平方和误差,就相当于把大框和小框一视同仁了,这样显然不合理。而如果使用开根号处理,就会一定程度上改善这一问题 。


3. 损失函数解释:
(1) 特殊符号含义:

(2) 坐标损失:

(3) 置信度损失:

(4) 分类损失: