Jmeter性能测试
一、性能测试介绍
1、什么叫做性能测试?
(1)通过某些工具或手段来检测软件的某些指标是否达到了要求,这就是性能测试
(2)指通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试
2、性能测试的时间?
在功能测试完成后才能进行性能测试
3、为什么要做性能测试?
(1)评估系统的能力,
(2)识别体系中的弱点
(3)验证稳定性
(4)系统调优
4、性能测试的流程?
(1)性能需求分析 (标准)
(2)性能计划的编写
(3)性能场景的设计
(4)脚本的开发(录制脚本)
(5)性能环境和数据
(6)性能执行
(7)结果分析(是否标准)
(8)性能总结报告
(9)性能调优
5、性能的类型有哪些?
(1)基准测试
在给系统施加较低压力时,查看系统的运行状况并记录相关数作为基础参考
(2)负载测试(慢慢接近临界点测试)
负载测试是对被测系统不断增加压力(即用户并发数),直至性能指标超过预期或者某项资源使用达到饱和状态(就是加压到系统崩溃)
(3)压力测试(也称为破坏性测试)(超过临界点测试)
压力测试:压力测试是系统在一定饱和状态下,例如cpu、内存、磁盘I/O在饱和使用情况下,不断给系统施加压力,看系统的处理能力,以及系统是否会出现错误。
(4)稳定性测试
稳定性测试是在给系统施加一定压力,持续运行一段时间(7*24),观察系统能否稳定运行。(也可以说是长时间的压力测试)
(5)并发测试
并发测试:并发测试是模拟多用户并发访问同一个应用、模块或者数据记录时可能发生的性能问题(如内存泄漏、线程锁和资源占用方面的问题)
6、性能测试常用的工具有哪些?
(1)jmeter 轻量级工具,免费,开源, (我们讲解的)
(2)loadrunn 商业版,收费,不易于安装,一个包4g包
7、性能测试文档包含哪些?
(1)性能测试测试计划
(2)性能场景设计用例
(3)性能报告
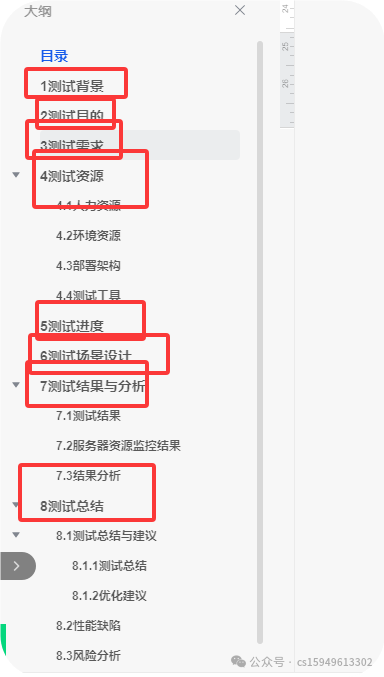
8、性能测试报告包含哪些内容?
(1)测试背景
(2)测试目的
(3)测试范围
(4)测试环境
(5)压测指标
(6)性能测试结果
(7)性能问题归纳
(8)性能调优
二、熟悉性能报告
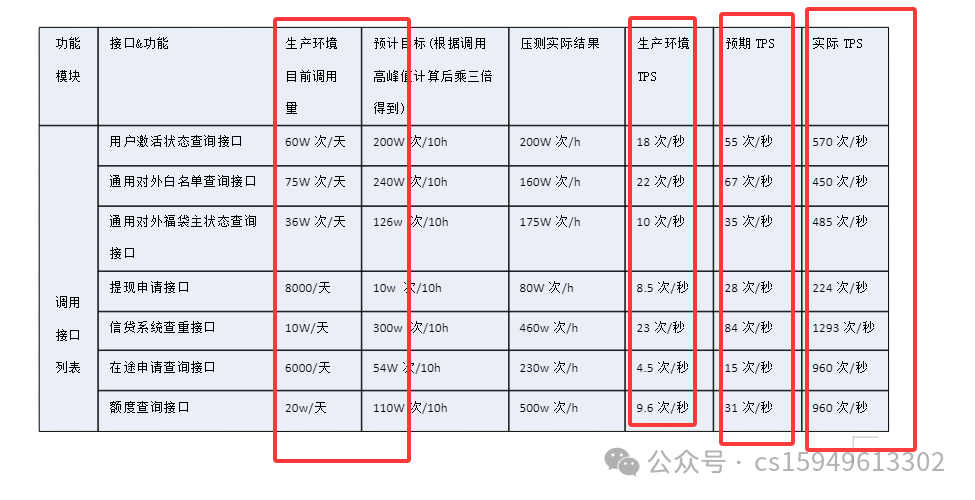
2. 性能问题
-
- (1) 提现申请接口3-5个线程并发时,容易引起死锁现象,经优化后,Tps达到224左右,且没有死锁现象出现;
- (2) 账单查询接口,优化索引前,响应时间为8s左右,Tps为11;优化索引后,响应时间缩短为0.15秒左右,Tps升为560左右
三、认识jmeter
(1)jmerer是一个什么工具?
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。
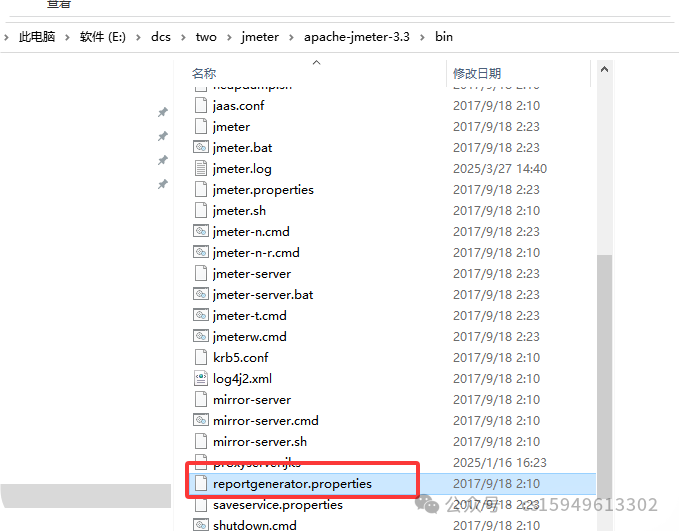
(2)详细讲解jmeter目录下常用文件有哪些?
bin目录:核心可执行文件
jmeter.bat:windows启动文件
jmeter-server.bat:分布式压测使用的启动文件
jmeter.properties:核心配置文件 examples(例子):该目录下存放Jmeter官方给的请求模板
report-template(报告模板):该目录下存放Jmeter的报告模板 templates(模板):该目录下存放Jmeter的各类配置模板 例如:JDBC、Beanshell等
(3)性能测试是生产环境还是测试环境?
性能测试要搭建性能环境,(不在测试环境和生产环境进行性能测试) 因为性能环境考验模拟线上环境,达到1:1比例; 通过造数据,jmeter 造大量数据,存储造大量数据
(4)jmeter 作性能测试的缺点?
jmeter 的缺点是压力值不能精确控制,难以适应高并发情况,由于是java编写,本身比较消耗资源。
(5)jmeter和loadrunner 的区别?
a.loadrunner 是一种预测系统行为和性能的负载测试工具。
b.loadrunner 能够最大限度地缩短测试时间,优化性能和加速应用系统的发布周期的商业工具
c、jmeter 是开发源代码项目,可以进行接口测试和性能测试的工具,
d、相对loadrunnrt是一个轻量级的工具,便于安装
获取接口的方式:
第一种:
抓包:写入接口fiddler或f12
第二种方式 :
录制脚本工具badboy 录制
1.点击安装包

2.快捷方式到桌面

3.点击打开badoy
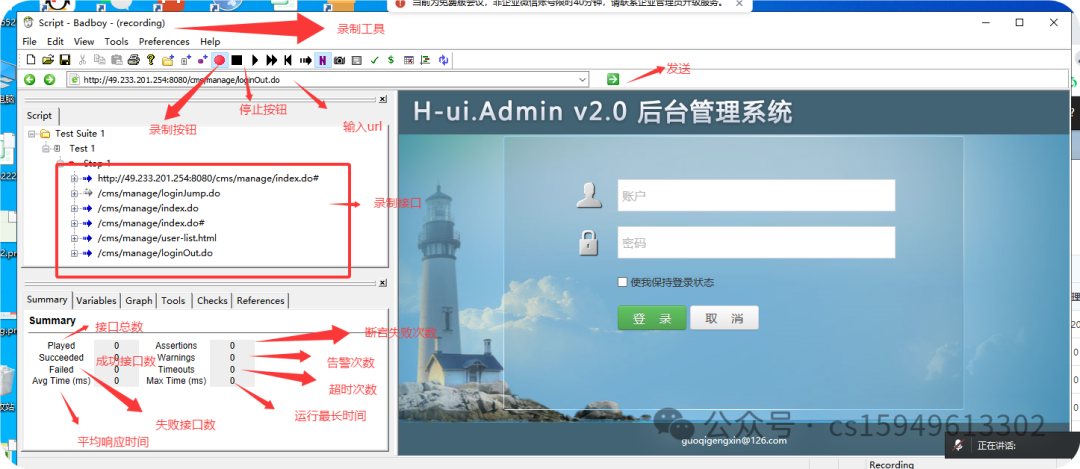
4.导出接口
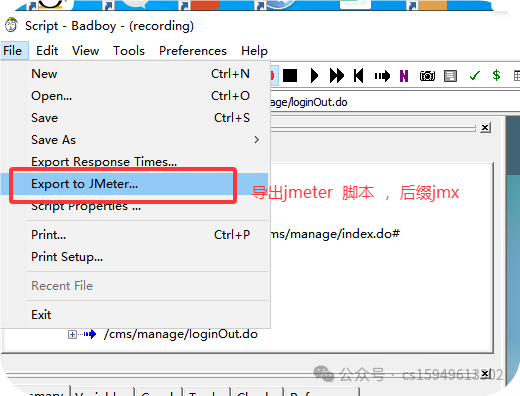
5.将录制的接口导入到jmeter种
第三种方式:
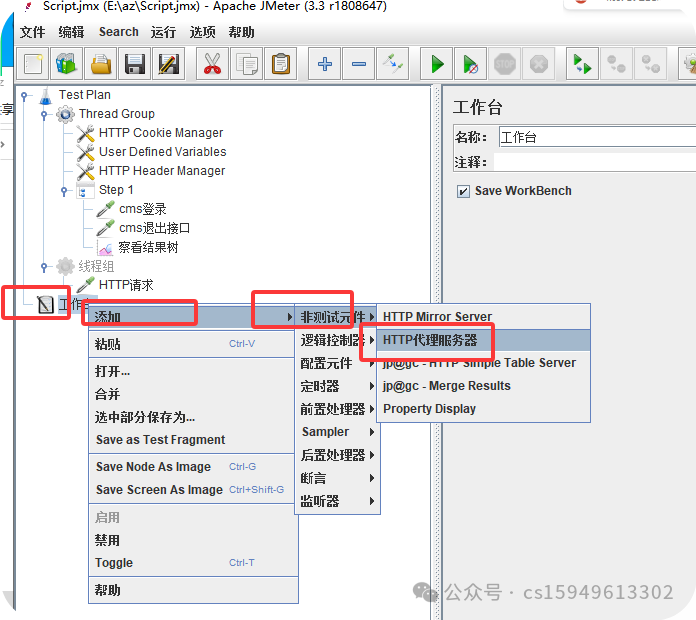
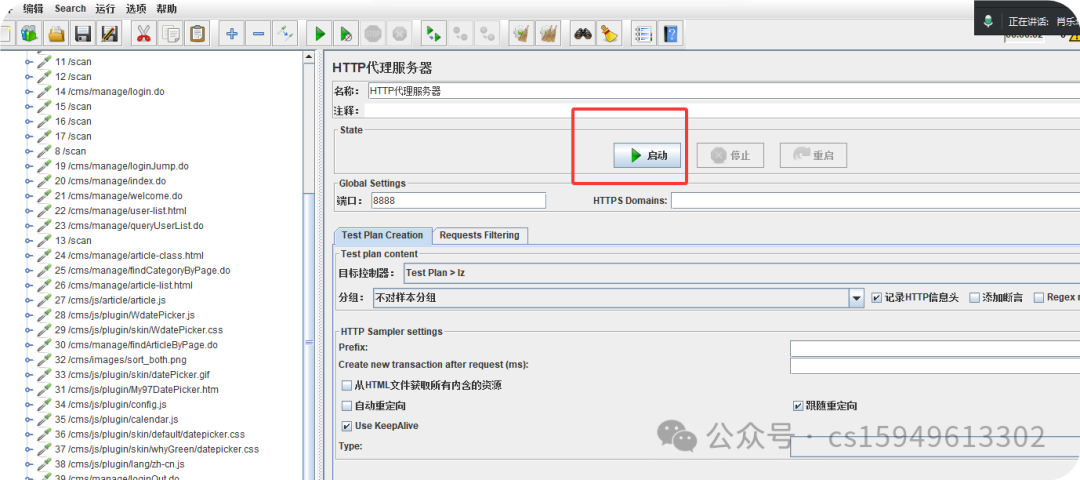
jmeter中有反向代理录制脚本
1.工作中添加http代理服务器
2.编辑代理服务器

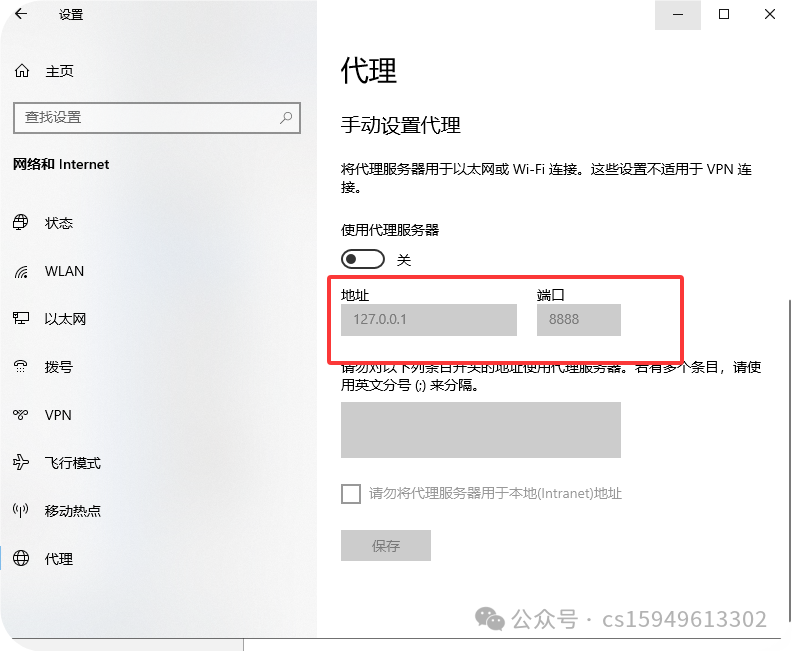
(1)端口号
端口:
默认为8888,可修改。但要注意,端口不能被其它程序占用,端口信息要与浏览器设置保持一致。
cmd.exe中使用如下命令检查端口使用情况:
1)netstat -an --列出本机所有使用端口信息
2)netstat -aon|findstr "8888" --查询端口是否被占用
3)tasklist|findstr "8888" --查询对应端口被什么程序占用
端口号:8888(默认)改成不常用的端口号避免端口号冲突;如8800
目标控制器:使用录制控制器(默认)后面根据情况进行更改
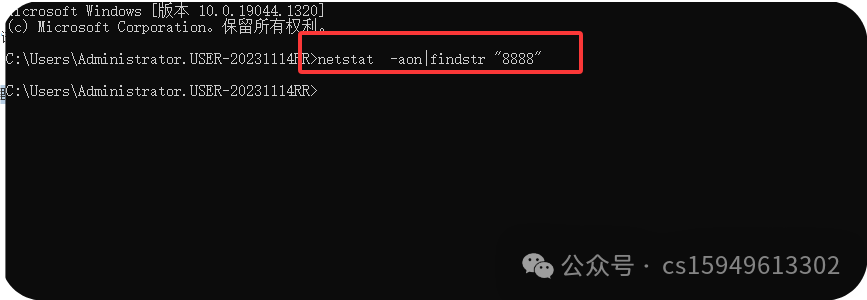
如上就是没有占用
2.操作浏览器(打开浏览器)
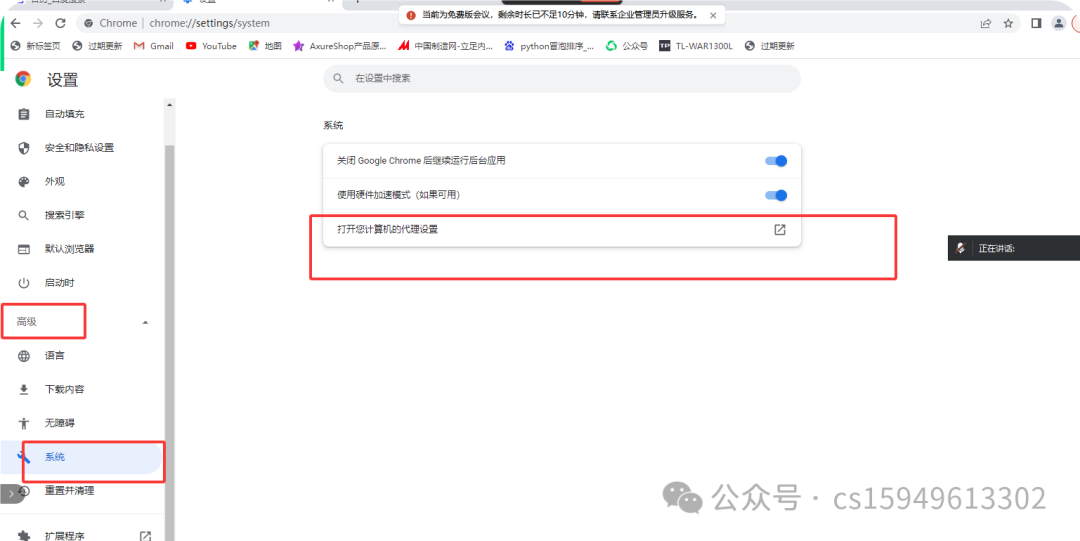
3.打开代理,填写参数

4.开启jmeter中的代理
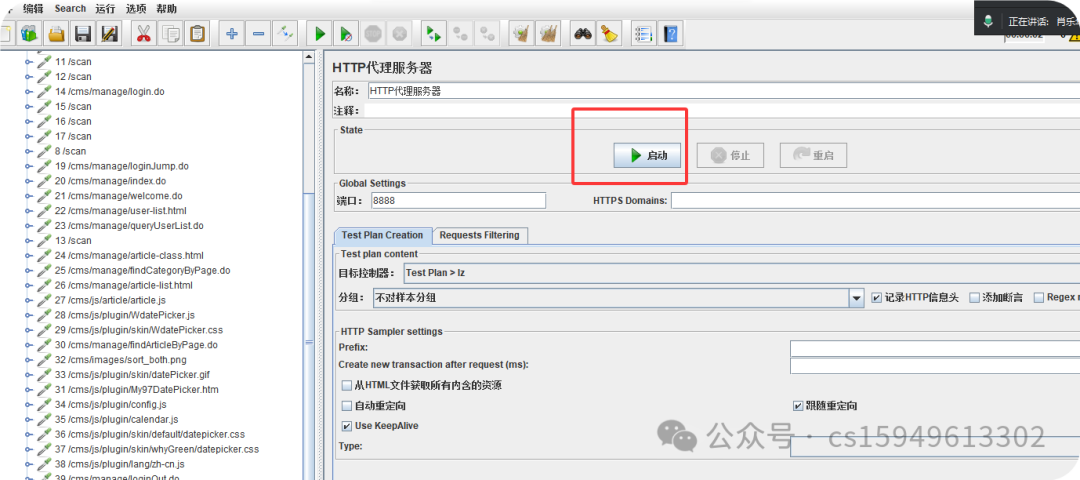
5.启动后就在页面访问,录制到接口
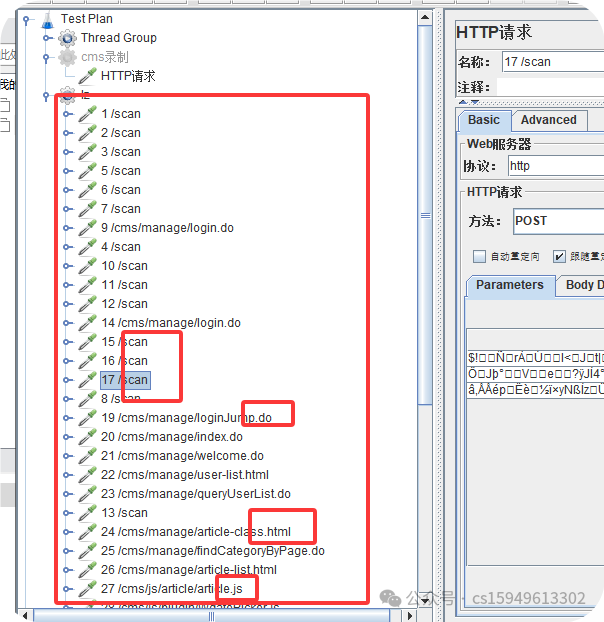
以上是录制了所有的功能
要录制的要排除不需要的接口
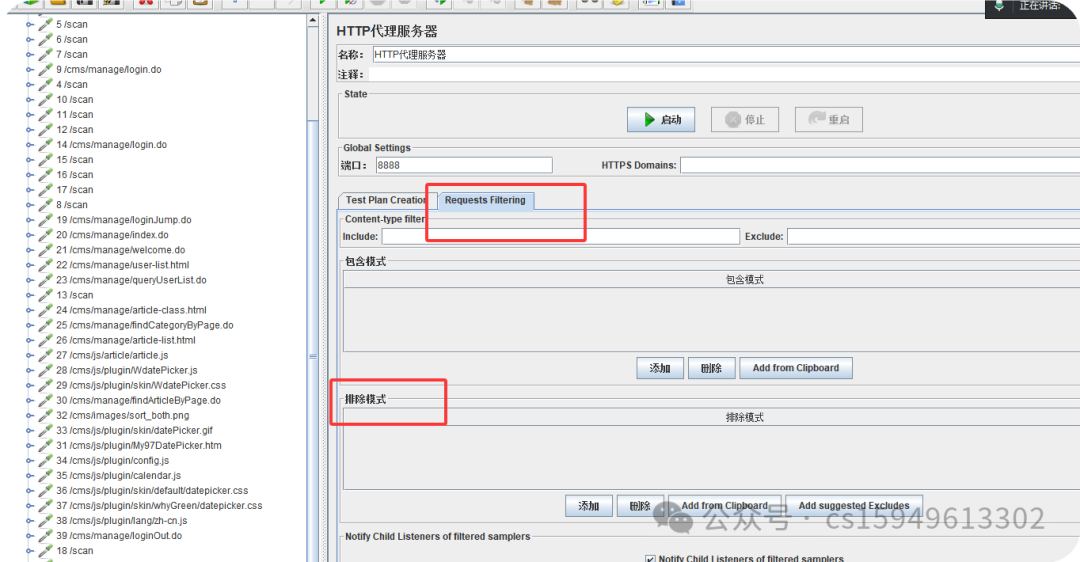
测试计划 -> http代理服务器 -> requests filtering -> 排除模式 ,录制时排除在外的内容:
.*\.(js|css|PNG|jpg|ico|png|gif).*
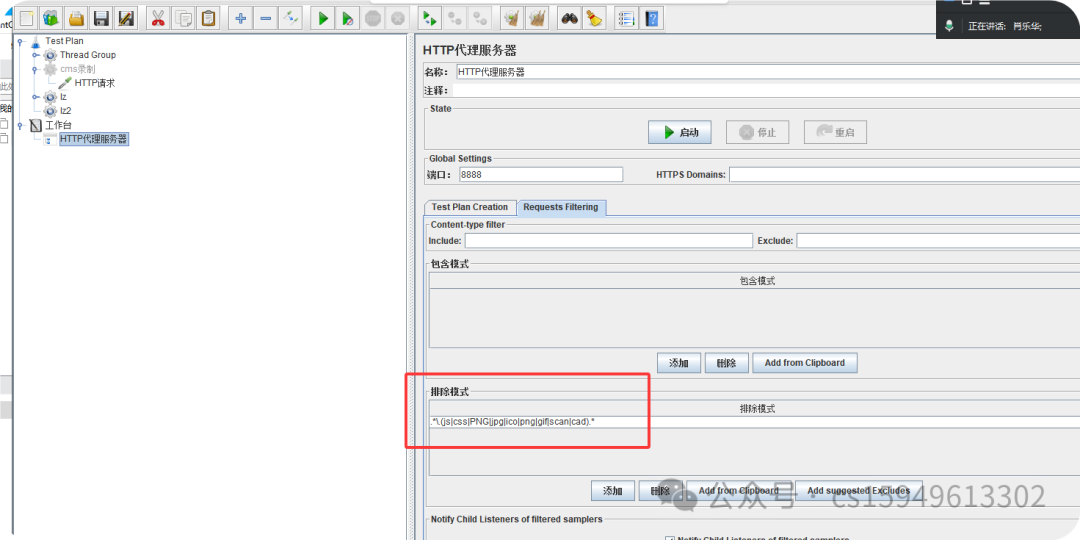

实战性能
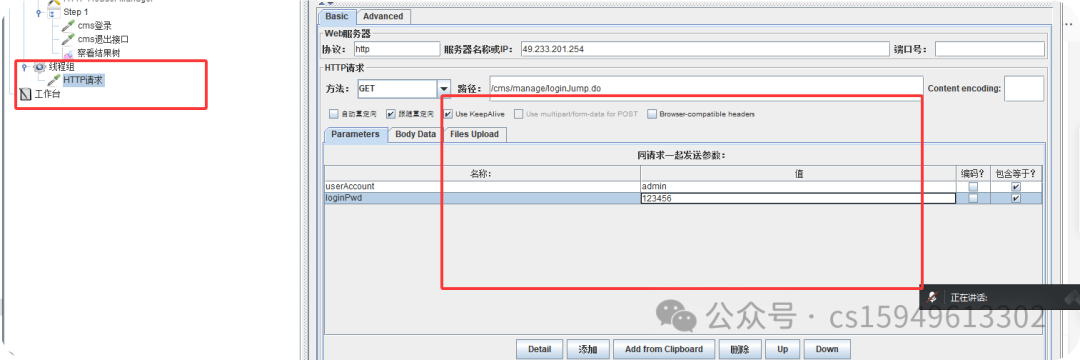
1.单接口性能测试(同一用户进行压力测试)
POST http://49.233.201.254:8080/cms/manage/loginJump.do
POST data:
userAccount=admin&loginPwd=123456
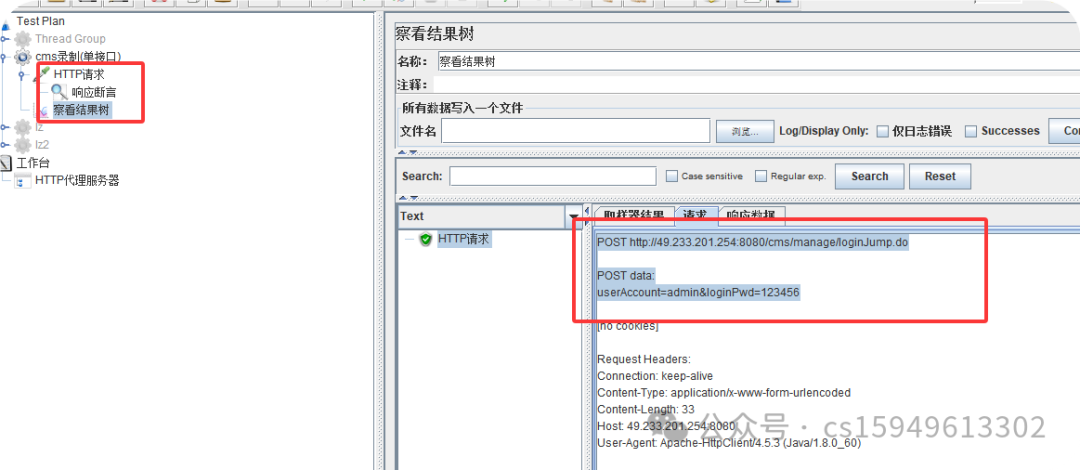
按100 压力测试
(1)在线程中修改虚拟用户数
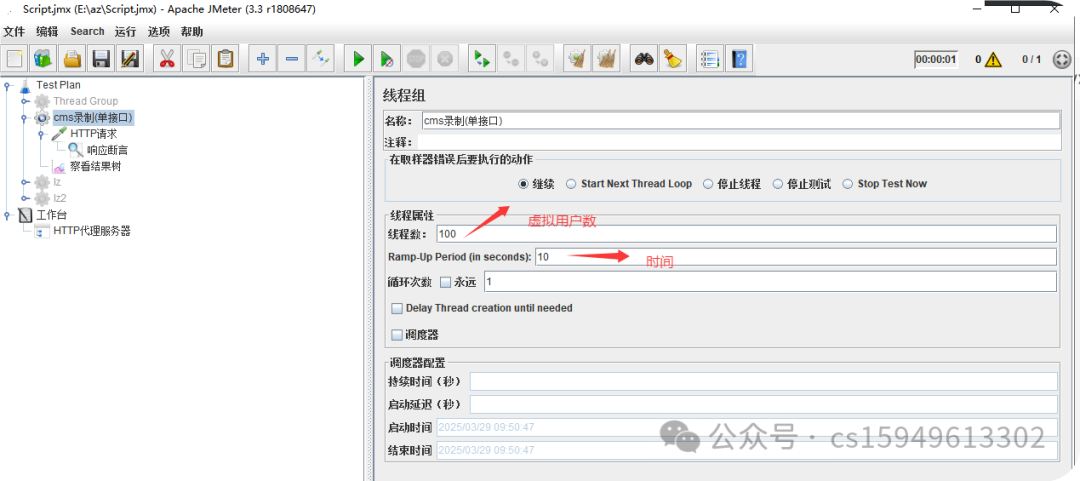
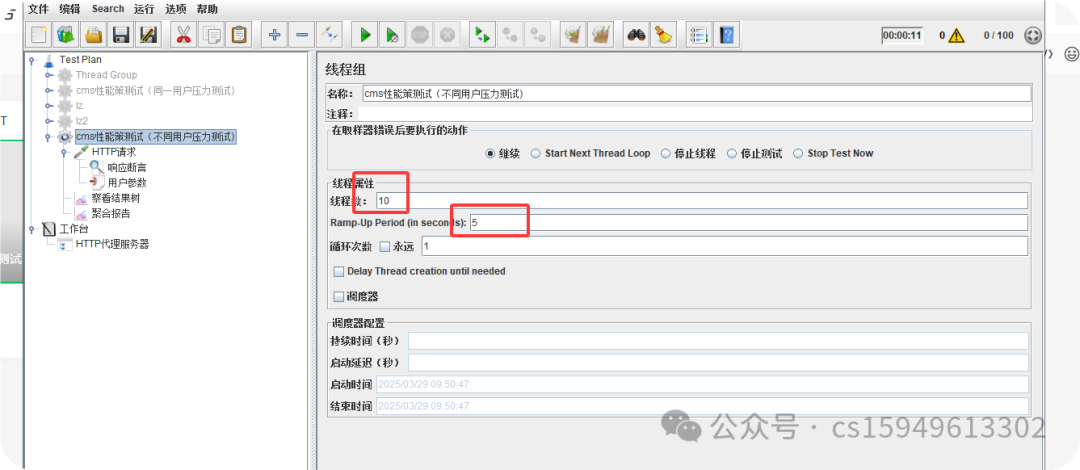
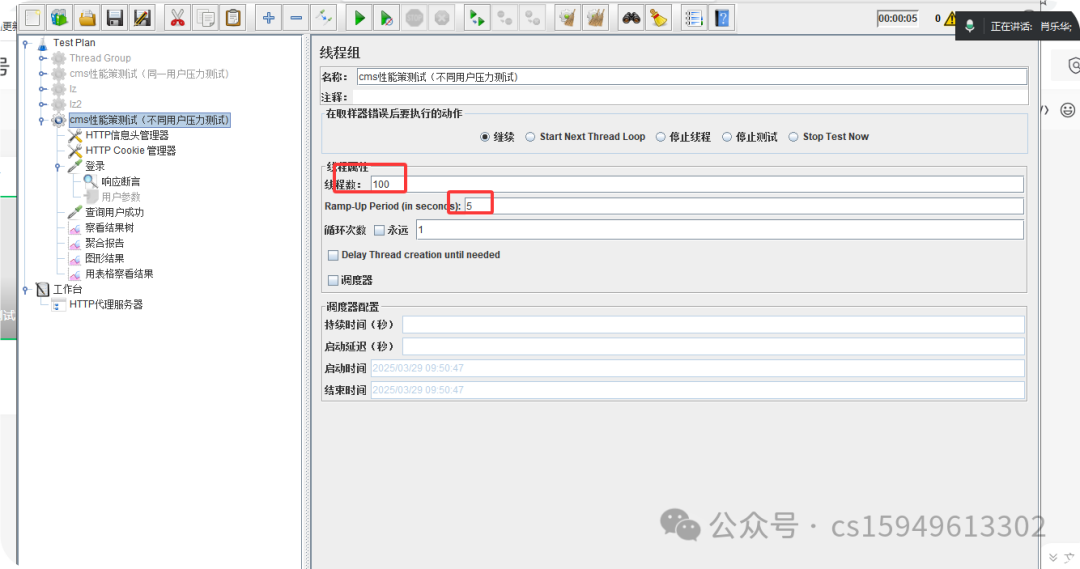
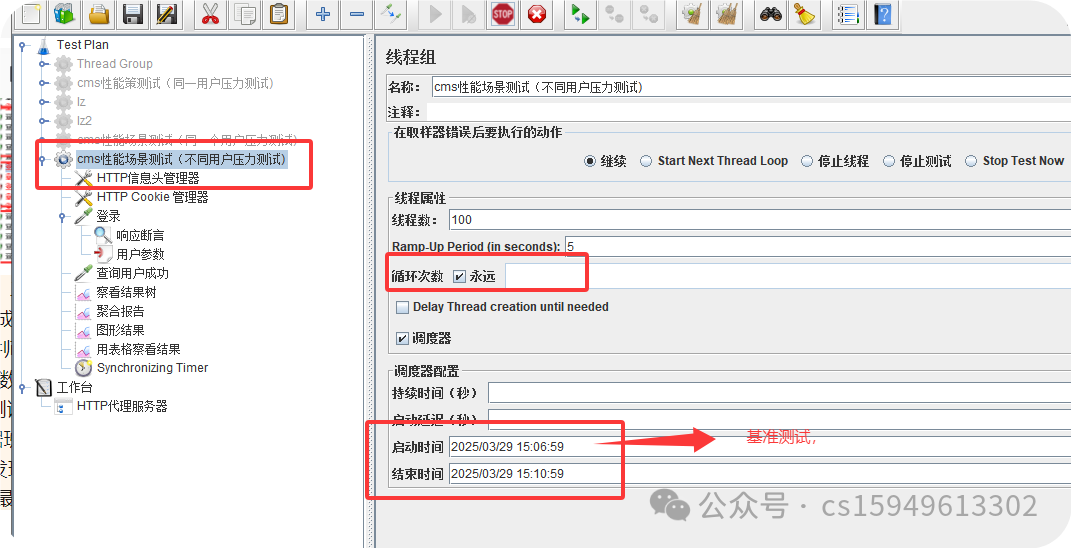
线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里也就是设置多少个线程数。
Ramp-Up Period(in seconds)准备时长:设置的虚拟用户数需要多长时间全部启动。如果线程数为10,准备时长为2,那么需要50秒钟启动500个线程,也就是每秒钟启动10个线程。
循环次数:每个线程发送请求的次数。如果线程数为500,循环次数为2,那么每个线程发送2次请求。总请求数为500*2=1000 。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
Delay Thread creation until needed:直到需要时延迟线程的创建。
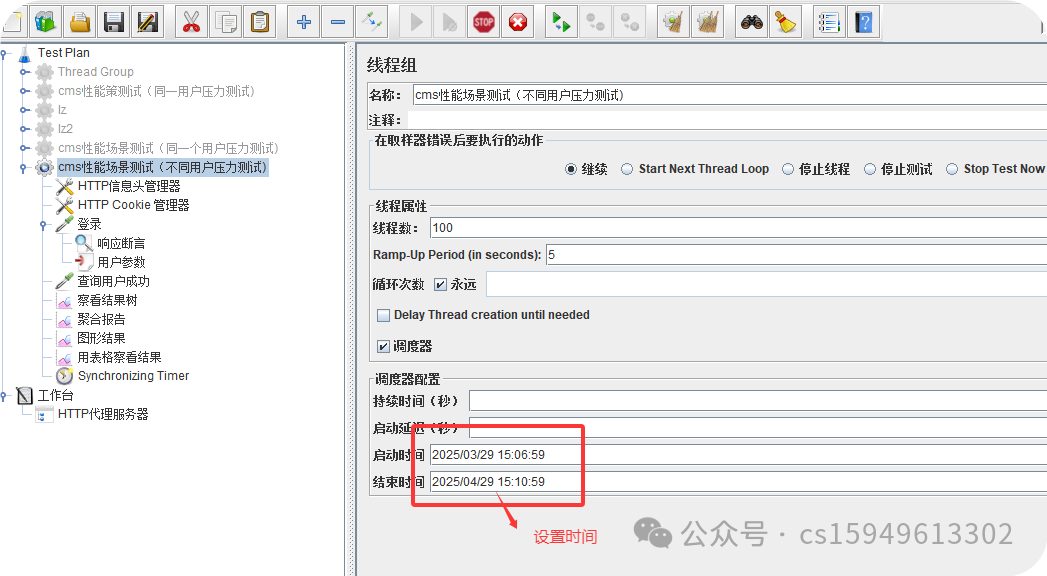
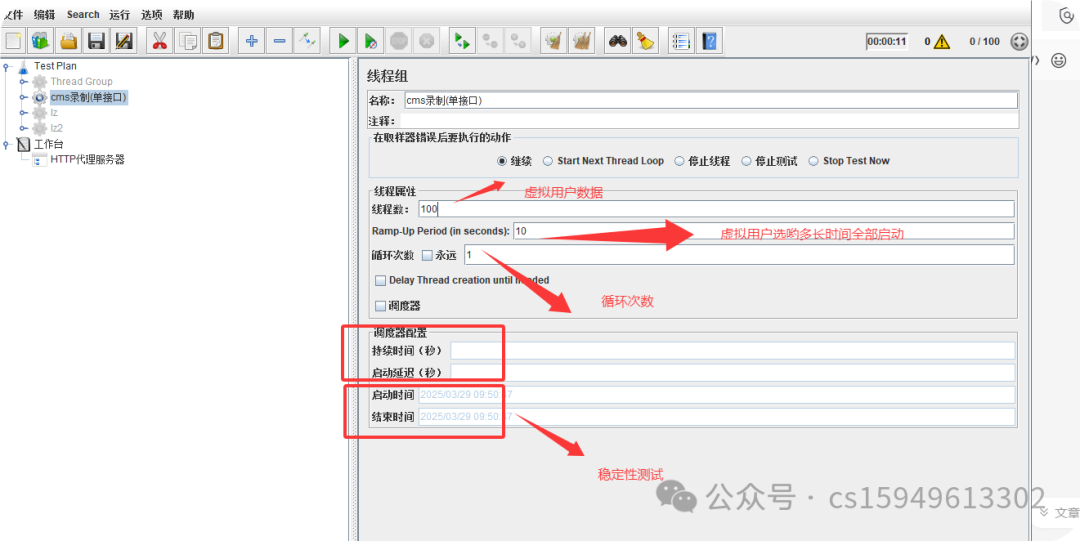
调度器:设置线程组启动的开始时间和结束时间(配置调度器时,需要勾选循环次数为永远)
持续时间(秒):测试持续时间,会覆盖结束时间
启动延迟(秒):测试延迟启动时间,会覆盖启动时间
启动时间:测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前时间也会覆盖它。
结束时间:测试结束时间,持续时间会覆盖它。‘
(2)添加查看结果树
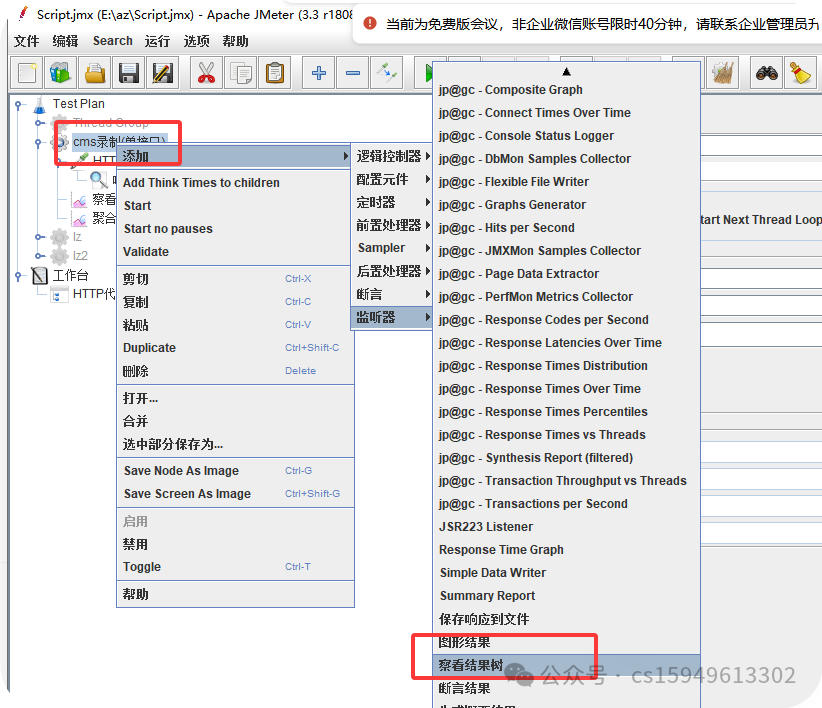
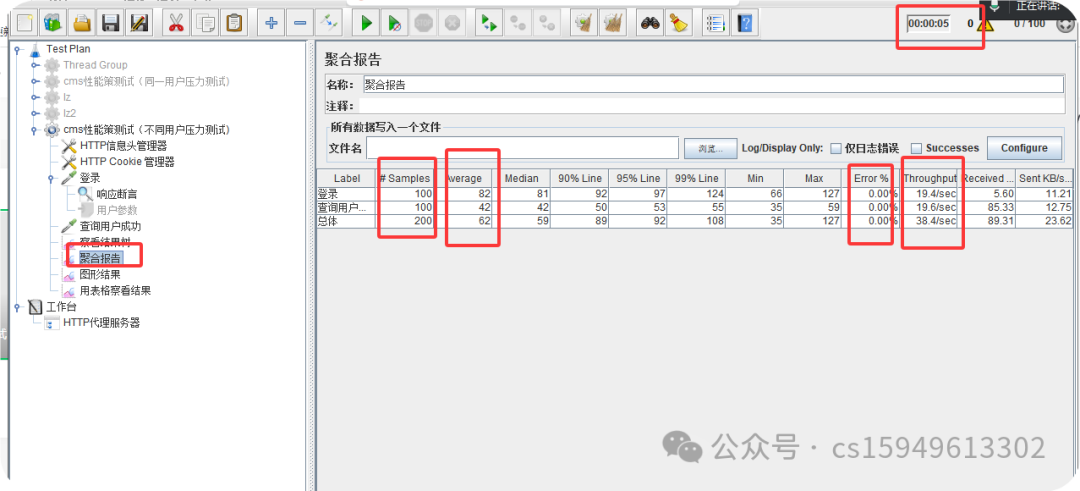
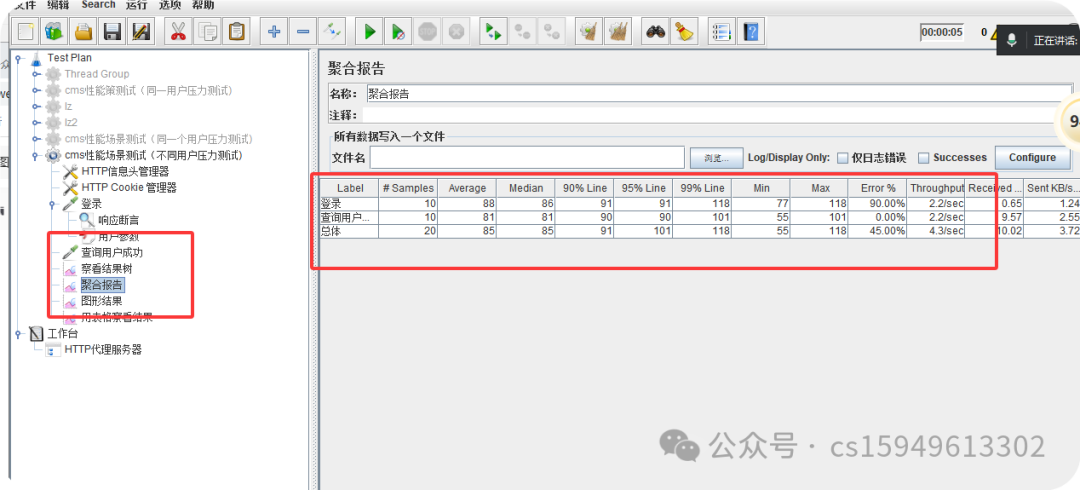
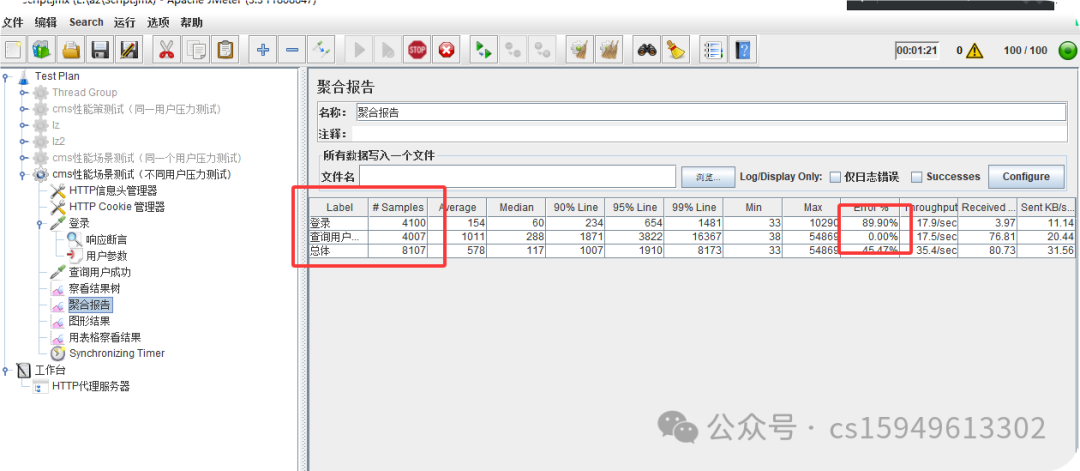
(3)添加聚合报告
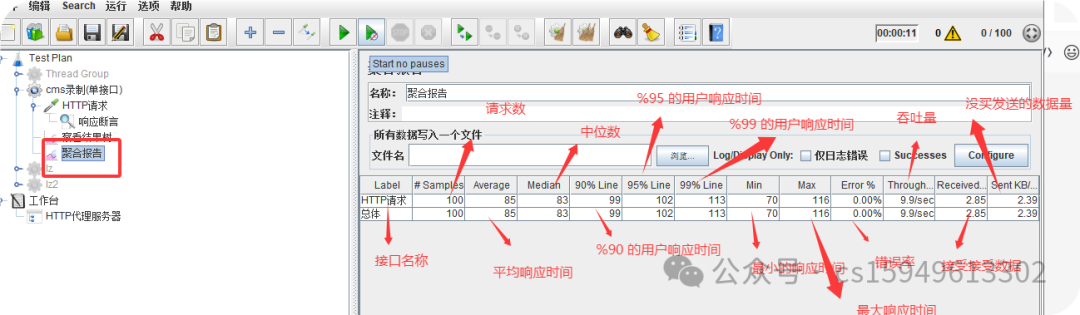
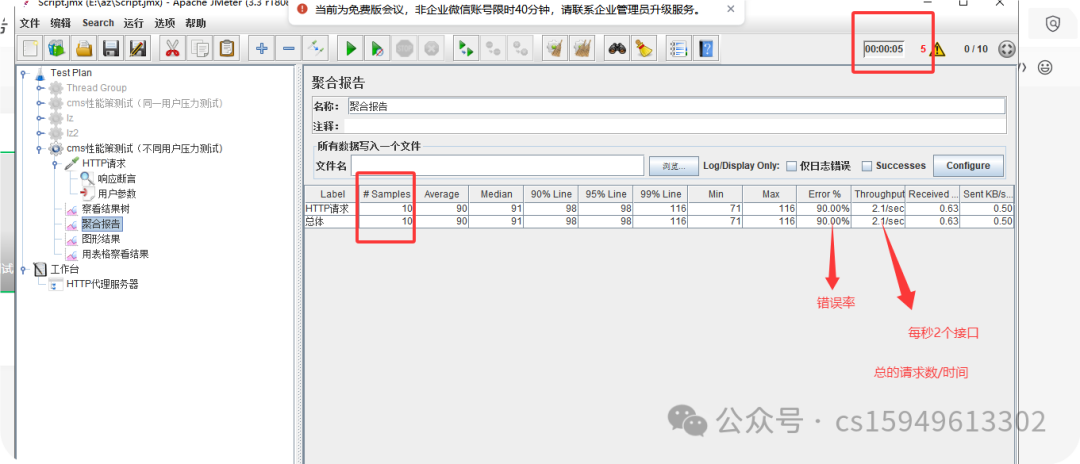
聚合报告参数详解:
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#Samples:请求数——表示这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
90% Line:90% 用户的响应时间
95% Line:90% 用户的响应时间
99% Line:90% 用户的响应时间
Min:最小响应时间
Max:最大响应时间
Error%:错误率——错误请求数/请求总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
一般而言,性能测试中我们需要重点关注的数据有:
#Samples 请求数,Average 平均响应时间,Min 最小响应时间,Max 最大响应时间,Error% 错误率及Throughput 吞吐量
2.单接口性能测试(不同用户进行压力测试)
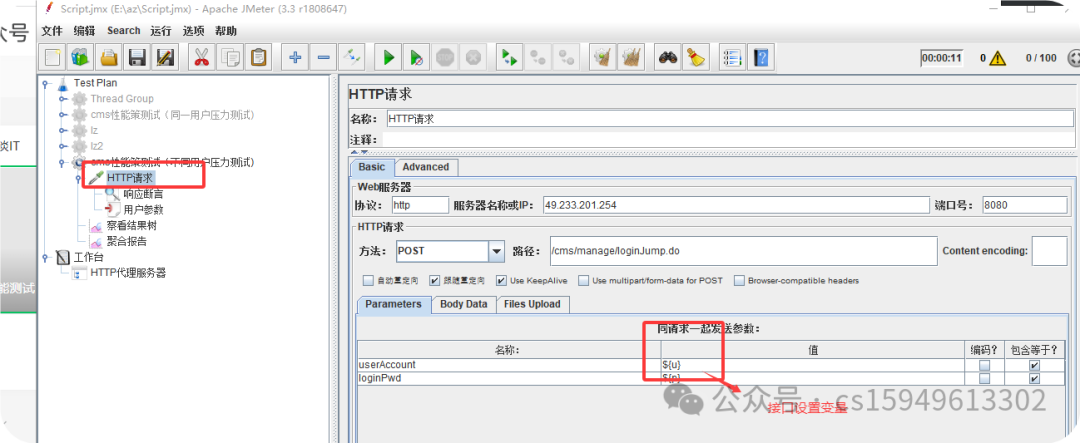
(1)登录接口设置变量
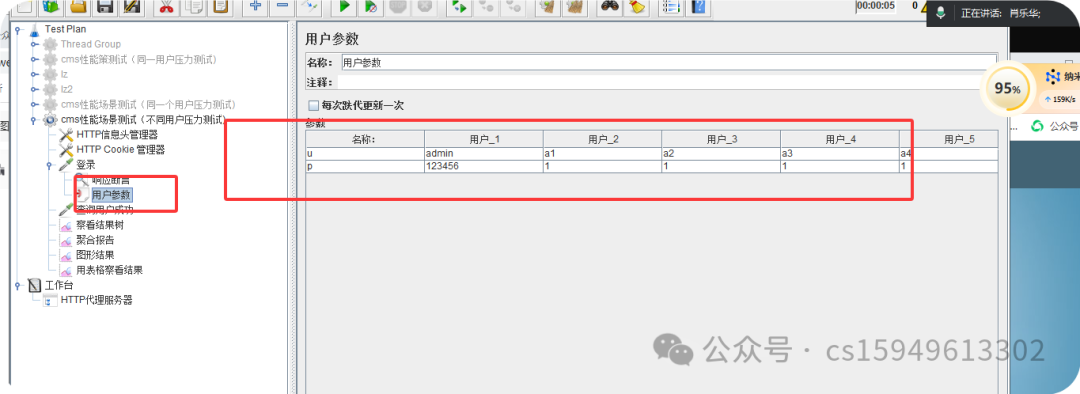
(2)后台造数据用户(10个)
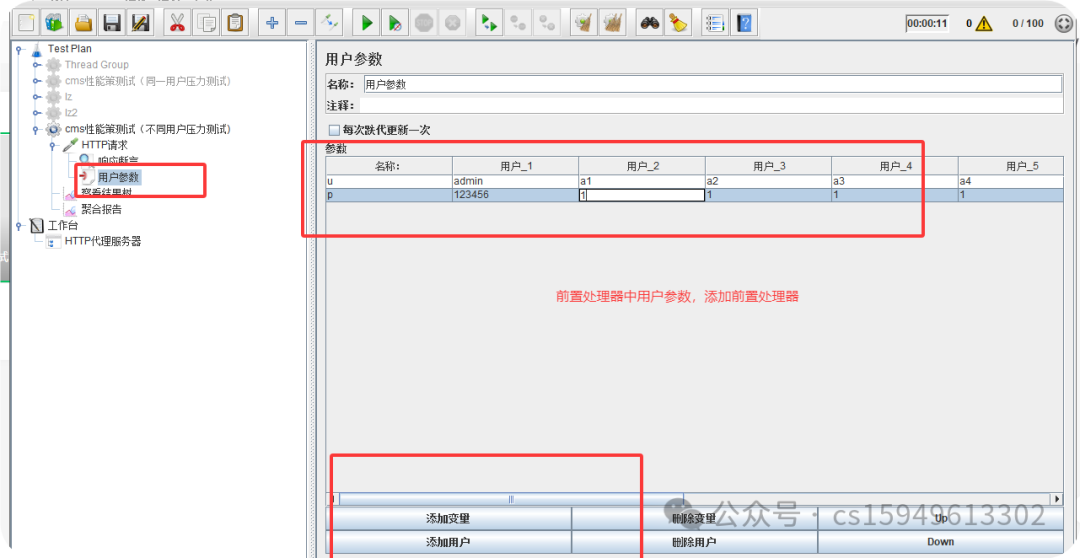
(3)通过前置处理中的用户参数或csv data config
(4)在线程中设置虚拟用户
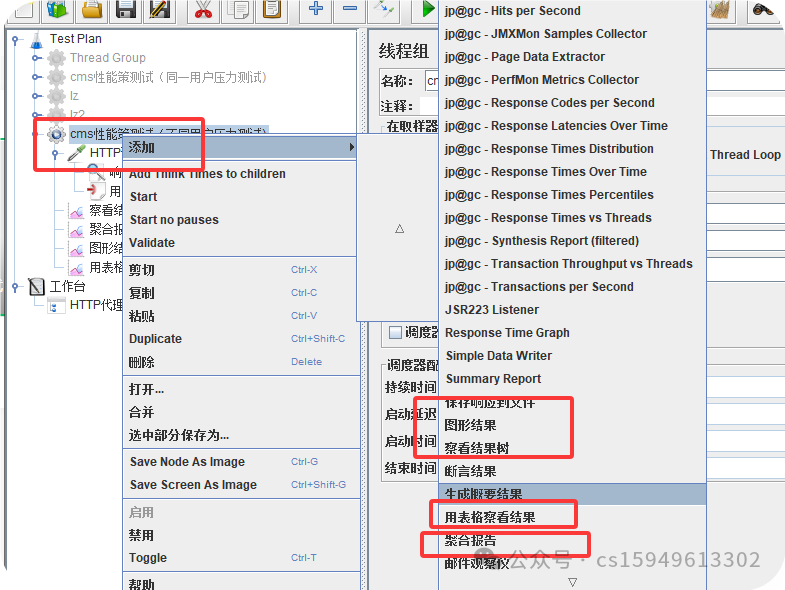
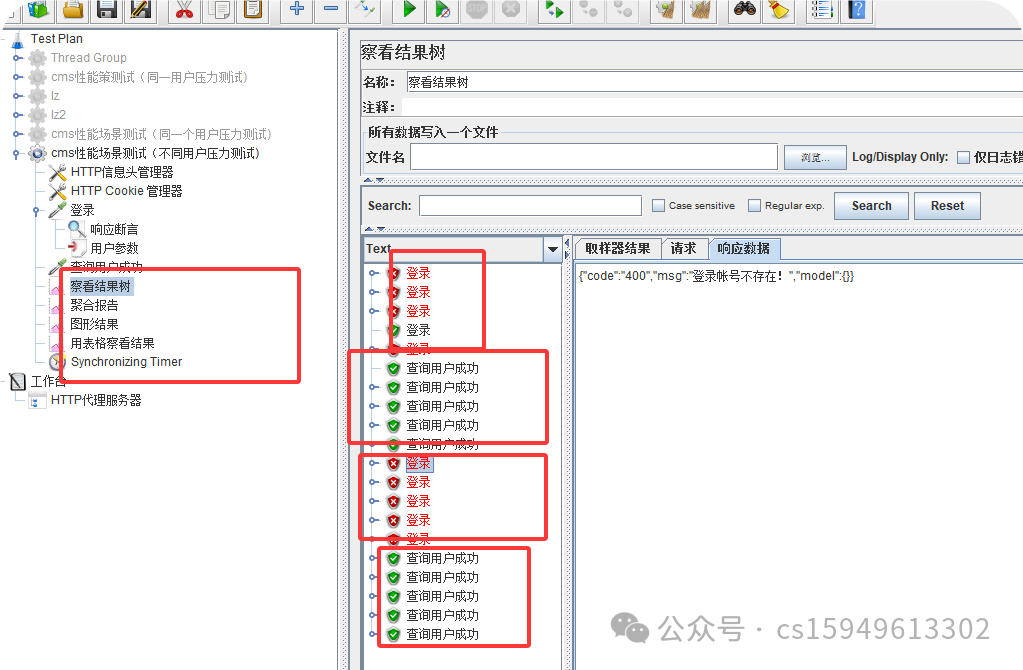
(5)查看结果树,聚合报告,图形报告,表格报告
(6)查看结果树结果
(7)聚合报告
(8)表格报告

(9)图形报告
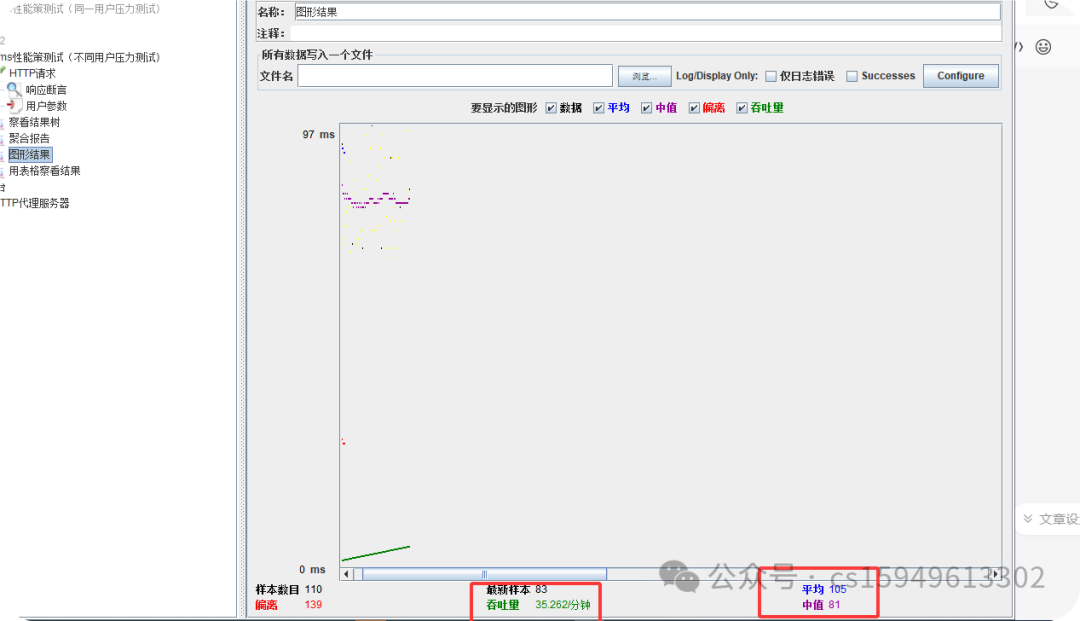
3.一个场景的接口测试(压力测试同一用户)
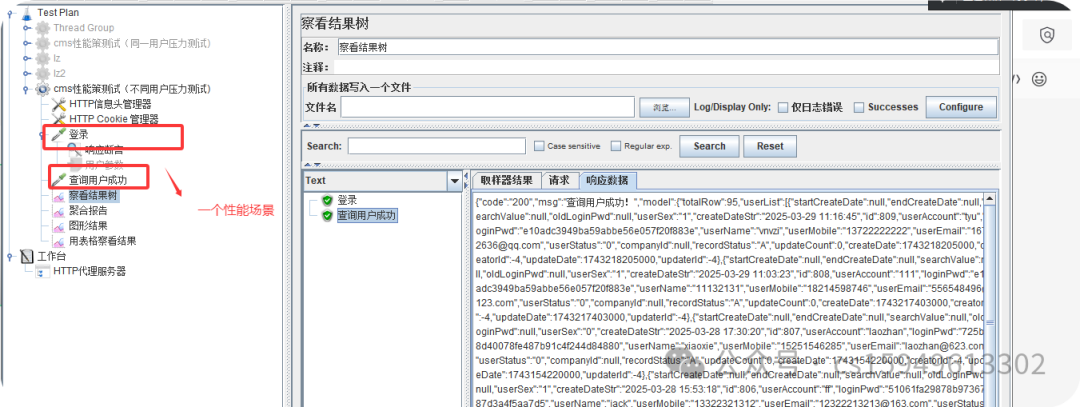
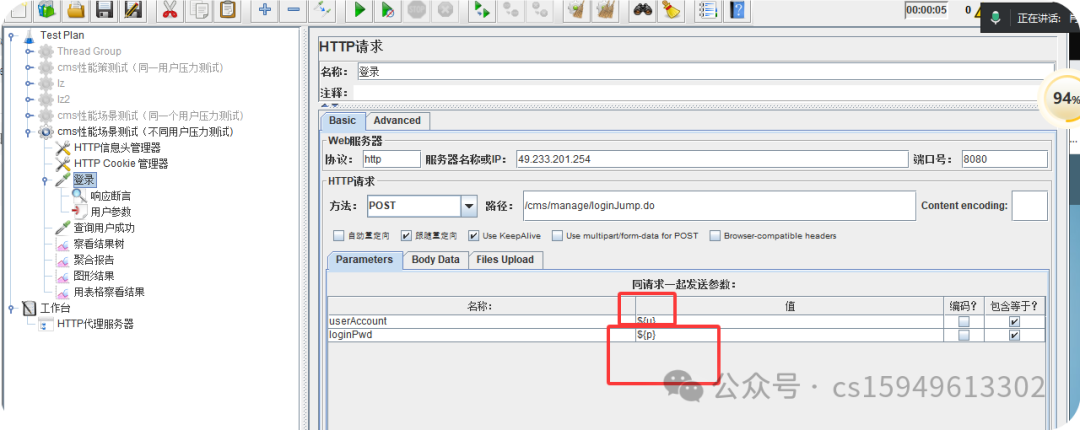
一个场景:登录接口,
POST http://49.233.201.254:8080/cms/manage/loginJump.do
POST data:
userAccount=admin&loginPwd=123456
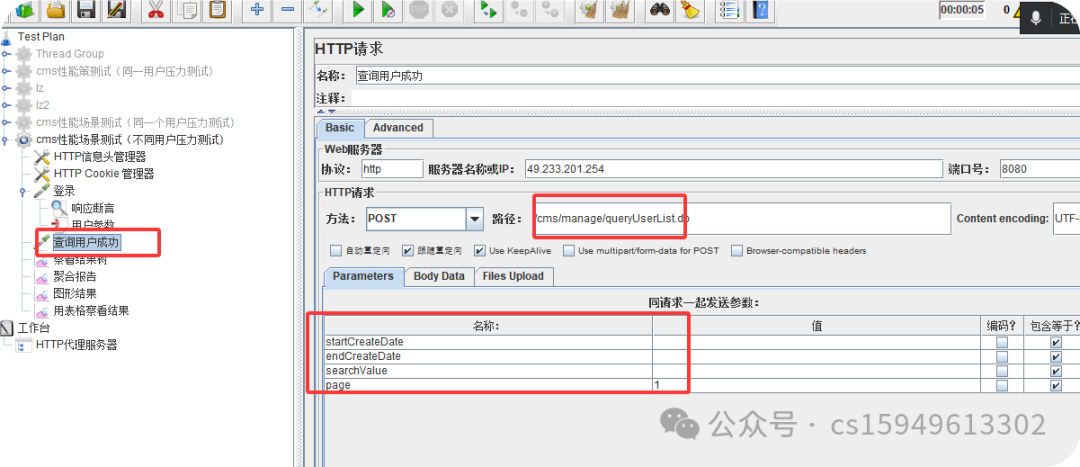
用户查询成功
POST http://49.233.201.254:8080/cms/manage/queryUserList.do
POST data:
startCreateDate=&endCreateDate=&searchValue=&page=1
(1)将两个接口填入到jmeter 或录制到jmeter中
(2)将接口调通:
加cookie,加请求头等
(3)填写虚拟用户数和等待时间
性能场景测试
一、不同用户一个场景压力测试
1.更改变量
2.前置处理中添加用户参数,导入用户

3.填写查询用户接口
4.接口有依赖关系,添加cookie值
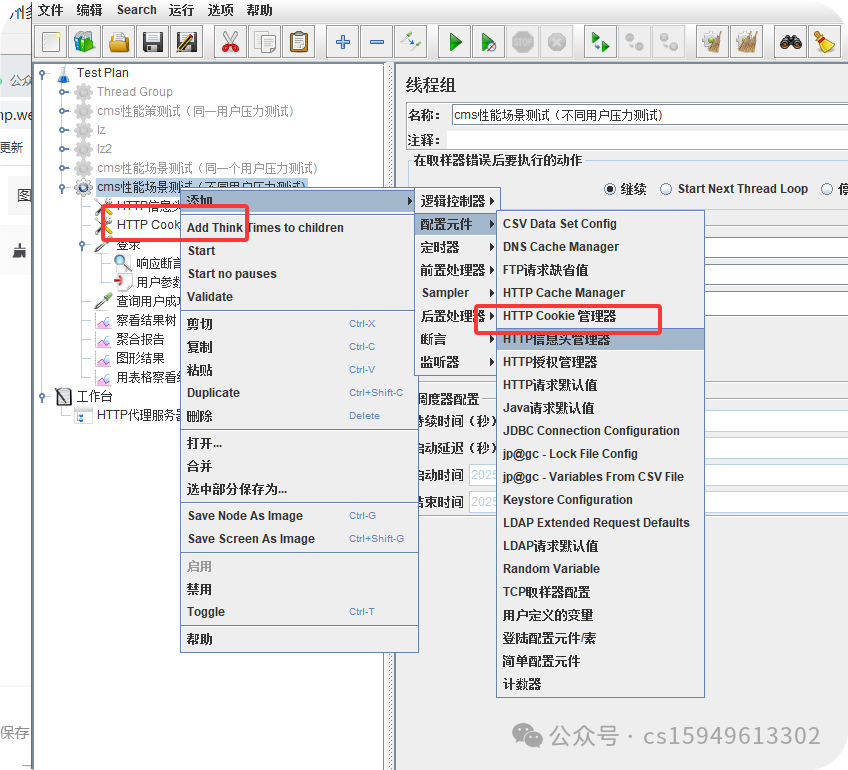
5.添加查看结果树,聚合报告等
二. 并发测试
同一时间,同一个点进行接口测试
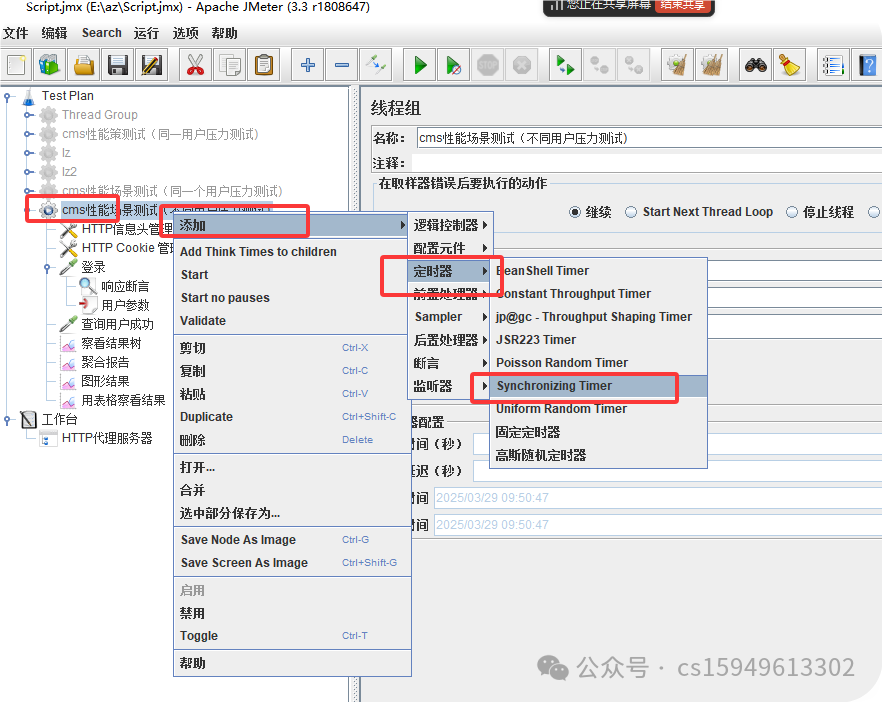
集合点的概念:
loadrunner中集合点可以设置多个虚拟用户等待到一个点,同时触发一个事务,以达到模拟真实环境下多个用户同时操作实现性能测试的最终目的。jmeter
中使用Synchronizing Timer实现Lr中集合点的功能,模拟多用户并发测试,即多个线程在同一时刻并发请求。
1、线程组右键 -> 定时器 -> Synchronizing Timer
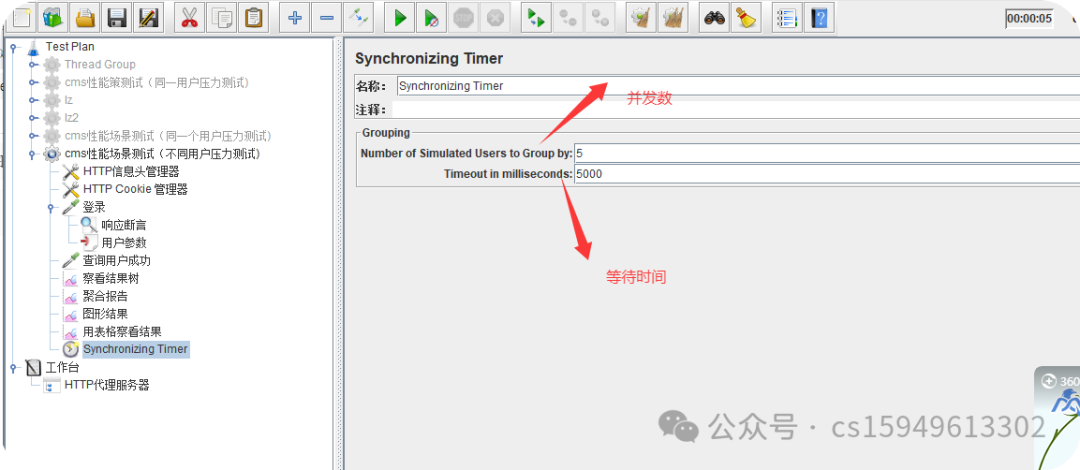
2、参数设置
a. Number of Simulated Users to Group by: 此处填写并发数量
b. Timeout in milliseconds: 超时时间设置
Jmeter默认没有超时时间,如果没有设置,一旦没有达到集结数量的请求系统就一直
等待。
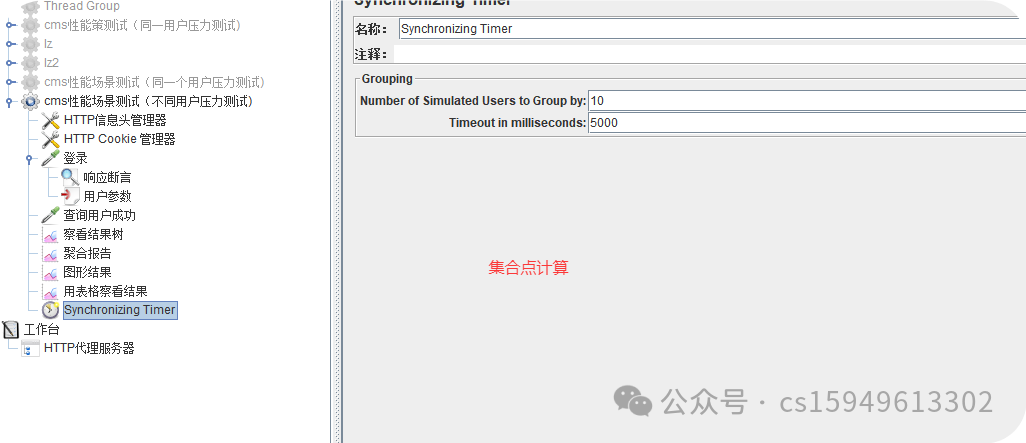
计算超时时间方法参考:
并发数量 * 1000毫秒/ 线程数/在多少时间启动这么多线程
10*1000/(10/10)=10000
定时器作用域:
作用于该定时器之后的所有请求,也就是说定时器实在请求执行前起作用的并发数和线程数一致时,并发启动时间,一定要大于线程组启动,如果小于这个时间,并发数量不准确。
(注意:线程组整理的启动时间单位是秒,定时器里的等待时间是:毫秒 ,哟啊注意单位换算,1秒=1000毫秒)
三.基准测试
较小的压力进行性能测试
四.稳定性测试