Data-Free Quantization Through Weight Equalization and Bias Correction
高通的训练后量化,提高性能
量化的不同水平
水平1:无需数据和反向传播
水平2:需要数据但不需要反向传播,例如IAO的校准
水平3:需要数据也需要反向传播,即模型量化之后需要微调,而且量化方法可以适用于所有模型
水平4:需要数据和反向传播,但是针对特殊的模型,其会先寻找模型的量化友好结构,比如针对mobilenet的量化,通过去除每个通道的BN和非线性激活函数减少通道之间的差异。
思路
动机
在使用纯整型量化方法对MobileNetV2进行量化时,精度从70.9%降到了0.1%,google白皮书中使用逐通道量化和感知训练的方法提高性能,作者则想用无数据的量化来提高精度
权重张量范围
MobileNetV2的结果表明,输出通道之间权重分布差异非常大,作者推测,量化后模型的性能可以通过调整每个输出通道的权重来提高

有偏量化误差
作者认为量化后模型与原模型输出存在偏置,而不能通过平均每个通道的偏置消除,因此作者想对偏置进行评估,并且校正偏置

跨层范围均衡
理想情况下,每个通道的权重范围等于这个张量或者整层的权重范围,就可以达到很好的结果。
设定比例系数矩阵S改变各个通道的权重分布,对于相邻两层:
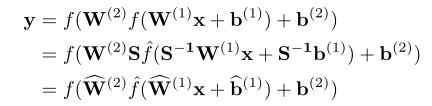
使得两层各个通道权重分布率pi(通道权重分布除总权重分布)之和最大:
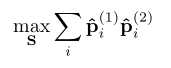
经过求解获得:
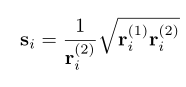
即令相邻两层权重范围均衡。
由于S的引入不仅改变了权重,也改变了偏置,
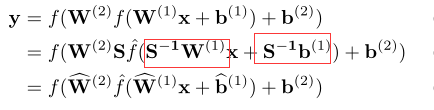
因此会改变激活层的范围,当S小于1时,激活层的范围会变大,需要去除这个偏差。用了类似的办法:
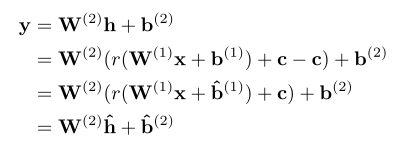
相邻两层使用偏置参数C来调节激活层的范围。
为了在无数据的条件下获得C,其利用BN层的β和γ,令C=max(0,β-3γ),假设激活层满足高斯分布,c就能满足大部分输入。
意思就是如果激活层本来比较大,就减去一个值。
每相邻两层进行均衡,不断迭代,直到获得最优量化误差
量化偏差校正
获得每个通道的偏差比较简单,比较输出就可以:
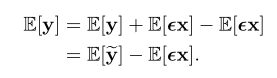
同时
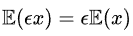
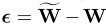
因此需要获得输入的均值,为了不使用数据,其利用BN层的值。由于BN层后的ReLU,需要对均值μ和方差 σ进行调整:
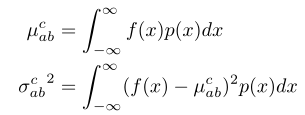
f(x)为ReLU,p(x)为均值为μ,方差为 σ的正态分布。
输入结果:
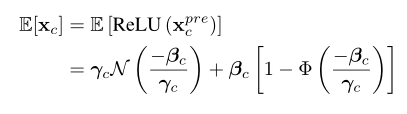
极其复杂,还要求分部积分
这样就能评估每个通道的偏差了。
结果还是很牛皮的,还能做目标检测和语义分割