
将 MinIO 的高性能、可扩展企业对象存储的强大功能与 Polars(闪电般快速的 DataFrame 库)的快速内存数据处理功能相结合,可以显著提高数据管道的性能。在 AI 工作流中尤其如此,其中预处理大型数据集和执行特征选择是关键步骤。在这篇文章中,我们将探讨将 MinIO 与 Polars 集成如何简化您的数据工作流程并优化性能,尤其是对于复杂的分析工作负载。
为什么选择 Polars 进行 AI 数据预处理?
Polars 是一个专为速度而设计的 DataFrame 库。与 Pandas 等基于 Python 的传统库不同,Polars 是用 Rust 构建的,使其能够高效处理大型数据集。Polars 采用急切执行模型,通过立即执行操作而不是等待延迟计算来提供快速结果。这使得 Polars 对于实时分析和时间敏感型数据处理特别有用。
Polars 的主要功能:
-
速度: Polars 使用 Rust 构建,速度非常快,可以处理远远超出 Pandas 管理能力的大型数据集。
-
延迟执行:Polars 有一个延迟 API,它通过重新排序和组合操作来优化查询计划以获得更好的性能。
-
多线程:Polars 利用多线程进行并行计算,使其能够比单线程解决方案更快地处理数据。
MinIO 的主要功能:
-
性能:作为市面上最快的对象存储,MinIO 的高性能与 Polars 的速度完美互补,能够检索和存储海量数据集。
-
规模:MinIO 的分布式架构可水平扩展,与您不断增长的 AI/ML 工作负载保持同步,同时 Polars 可以有效地处理数据。
-
数据持久性和冗余性: MinIO 的纠删码和对象锁定以现代、真正有效的方式保护您的数据。
-
与 AI/ML 框架集成:通过 MinIO 对 S3 API 的严格合规性和强大的 SDK,MinIO 支持各种 AI/ML 框架,如 TensorFlow 和 PyTorch。通过这些集成,您可以使用 Polars 检索预处理的数据,直接进行训练和推理,而不会遇到任何问题。
使用 GPU 加速 Polars 工作流程(可选)
对于那些寻求更高性能的用户,Polars 为由 RAPIDS cuDF 提供支持的 GPU 引擎提供了测试版,可在 NVIDIA GPU 上提供高达 13 倍的处理速度。这在处理数亿行时特别有用,因为即使是很小的性能提升也可以显著减少处理时间。要访问此 GPU 加速,您只需安装支持 GPU 的 Polars 并在收集数据时指定 GPU 引擎。
pip install polars[gpu] --extra-index-url=https://pypi.nvidia.com其他集成信息将相同。
将 MinIO 与 Polars 集成
让我们探索如何将 MinIO 集成到一个有凝聚力的数据处理管道中。无论您是处理大规模时间序列数据、日志文件还是 AI/ML 模型训练数据集,MinIO 都提供了存储基础,而 Polars 则快速高效地处理这些数据。
第 1 步:确保已安装 Docker
安装 Docker(如果尚未完成):请遵循官方 Docker 安装指南。
第 2 步:在无根 Docker 容器中部署 MinIO
运行 MinIO 容器:接下来,以无根模式启动 MinIO 容器。您将指定数据目录以及访问密钥和 Secret 密钥。根据需要调整端口和目录。
mkdir -p ${HOME}/minio/data
docker run \-p 9000:9000 \-p 9001:9001 \--user $(id -u):$(id -g) \--name minio1 \-e "MINIO_ROOT_USER=ROOTUSER" \-e "MINIO_ROOT_PASSWORD=CHANGEME123" \-v ${HOME}/minio/data:/data \quay.io/minio/minio server /data --console-address ":9001"-
-p 9000:9000:在端口 9000 上公开 MinIO 的 API。
-
-p 9001:9001:在端口 9001 上公开 Web 控制台。
-
-v ~/minio/data:/data:挂载主机上的 ~/minio/data 目录以存储数据。
-
MINIO_ROOT_USER 和 MINIO_ROOT_PASSWORD 用于身份验证。
第 3 步:访问 MinIO
容器启动后,打开 Web 浏览器并转到:http://localhost:9001
使用 MINIO_ROOT_USER 和 MINIO_ROOT_PASSWORD 凭证登录。
第 4 步:创建存储桶并上传 Parquet 文件
根据以下说明在 MinIO 中创建存储桶:
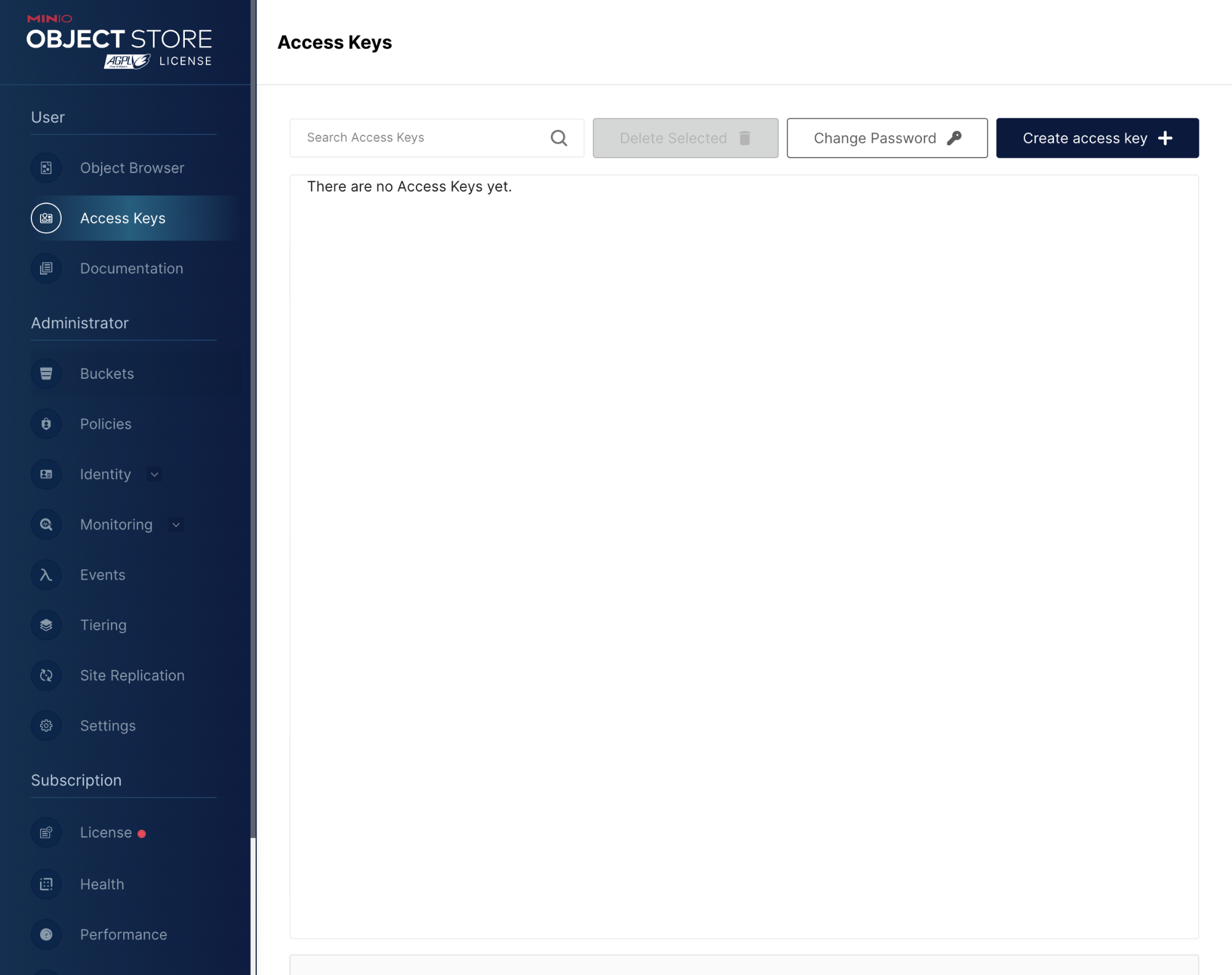
接下来,将 Parquet 文件添加到您的存储桶中。
第 5 步:在 Polars 中从 MinIO 访问数据
要将 MinIO 中的数据读取到 Polars DataFrame 中,您可以将 MinIO 的 S3 兼容 API 与 Python 中的 requests 库一起使用。使用您的 MinIO 用户名 (访问密钥) 和密码 (密钥) 进行身份验证。假设您的数据存储在 Parquet 文件中;您首先需要 pip 安装 MinIO 和 Polars。
pip install minio
pip install polars以下是将这些数据直接读取到 Polars 的方法:
import polars as pl
from minio import Minio
import io# Configure MinIO S3 access
minio_url = "localhost:9000"
access_key = "ROOTUSER"
secret_key = "CHANGEME123"# Initialize MinIO client
client = Minio(minio_url,access_key=access_key,secret_key=secret_key,secure=False # Set to True if you're using HTTPS
)# Retrieve the parquet file from the bucket
bucket_name = "ducknest"
object_name = "wild_animals.parquet"# Download the object as a stream
response = client.get_object(bucket_name, object_name)# Read the file content into a Polars DataFrame
data = io.BytesIO(response.read())
df = pl.read_parquet(data)# Perform your data analysis
print(df.describe())第 6 步:使用 Polars 处理大型数据集
Polars 在处理大型数据集时确实大放异彩。它的内存效率和多线程功能使其能够比 Pandas 等传统库更快地处理筛选、分组和聚合等复杂操作。MinIO 通过提供完美的高性能存储层来处理这些海量数据集而发挥作用。无论您的数据集有多大,数据检索都可以保持快速和高效。这是因为 MinIO 的速度仅受底层硬件的限制。Polars 和 MinIO 协同工作,形成强大的组合,实现顺畅的数据处理并最大限度地减少 AI/ML 管道中的瓶颈。例如,以下是对 Polars DataFrame 执行聚合操作的方法:
# Group by the correct column names (as per the schema)
result = df.group_by("category").agg([pl.col("value").count().alias("total_value"), # Count the number of animals in each habitatpl.col("quantity").mean().alias("avg_quantity") # Calculate the average species value (after casting to numeric)]
)# Print the result
print(result)当您准备好部署时
当您准备好部署时,MinIO 的可扩展性将大放异彩,轻松管理海量数据集,而 Polars 可加速数据处理,确保流畅的端到端性能。与传统的块存储解决方案相比,MinIO 的 Enterprise Object Store (EOS) 不仅具有成本效益,而且还大大提高了性能。对于寻求更多控制和洞察力的组织,MinIO Enterprise Console 是一个强大的工具。它提供了一个统一的“单一管理平台”来管理您的所有 MinIO 部署,无论是在本地、云中还是在边缘。MinIO Enterprise Object Store 的另一个突出功能是 Enterprise Catalog,它支持实时搜索和查询 EB 级的对象元数据。使用 GraphQL 界面,管理员可以轻松执行合规性检查、操作审计和管理空间利用率。这些只是一整套企业工具中的两个,这些工具可用于专为 MinIO 的大规模部署而构建。当您准备好同时部署 MinIO 和 Polars 时,您将拥有所需的一切。
结论
通过将 MinIO Enterprise Object Store 与 Polars 集成,您可以构建能够轻松处理海量数据集的高性能、可扩展的数据管道。无论您是在处理实时分析、大规模 AI/ML 工作负载,还是只处理大型数据湖,这种组合都能提供速度和效率。随着对更快数据处理和可扩展存储的需求不断增长,利用 MinIO 和 Polars 等技术对于现代数据基础设施将变得越来越重要。






![[Python学习日记-31] Python 中的函数](https://i-blog.csdnimg.cn/direct/162340e3427b45ecb1fe5cf328876971.png)





![ERROR [internal] load metadata for docker.io/library/openjdk:8](https://i-blog.csdnimg.cn/direct/397c9b0a0e1946c1bae6df7bde592099.png)

