人工智能 (AI) 在改变我们生活、工作和与技术互动的方式方面取得了令人难以置信的进步。最近,取得重大进展的领域是大型语言模型 (LLM) 的开发,例如GPT-3、ChatGPT和GPT-4。这些模型能够以令人印象深刻的准确性执行语言翻译、文本摘要和问答等任务。
虽然很难忽视 LLM 不断增加的模型规模,但同样重要的是要认识到,他们的成功很大程度上归功于用于训练他们的大量高质量数据。
在本文中,我们将从以数据为中心的 AI 角度概述 LLM 的最新进展,借鉴我们最近的调查论文 [1,2] 中的见解以及 GitHub 上的相应技术资源。特别是,我们将通过以数据为中心的 AI 的镜头仔细研究 GPT 模型,这是数据科学界中一个不断发展的概念。我们将通过讨论三个以数据为中心的 AI 目标:训练数据开发、推理数据开发和数据维护,来揭示 GPT 模型背后以数据为中心的 AI 概念。
一、大型语言模型 (LLM) 和 GPT 模型
LLM 是一种自然语言处理模型,经过训练可以在上下文中推断单词。例如,LLM 最基本的功能是在给定上下文的情况下预测缺失的标记。为此,LLM 接受了训练,可以从海量数据中预测每个候选代币的概率。

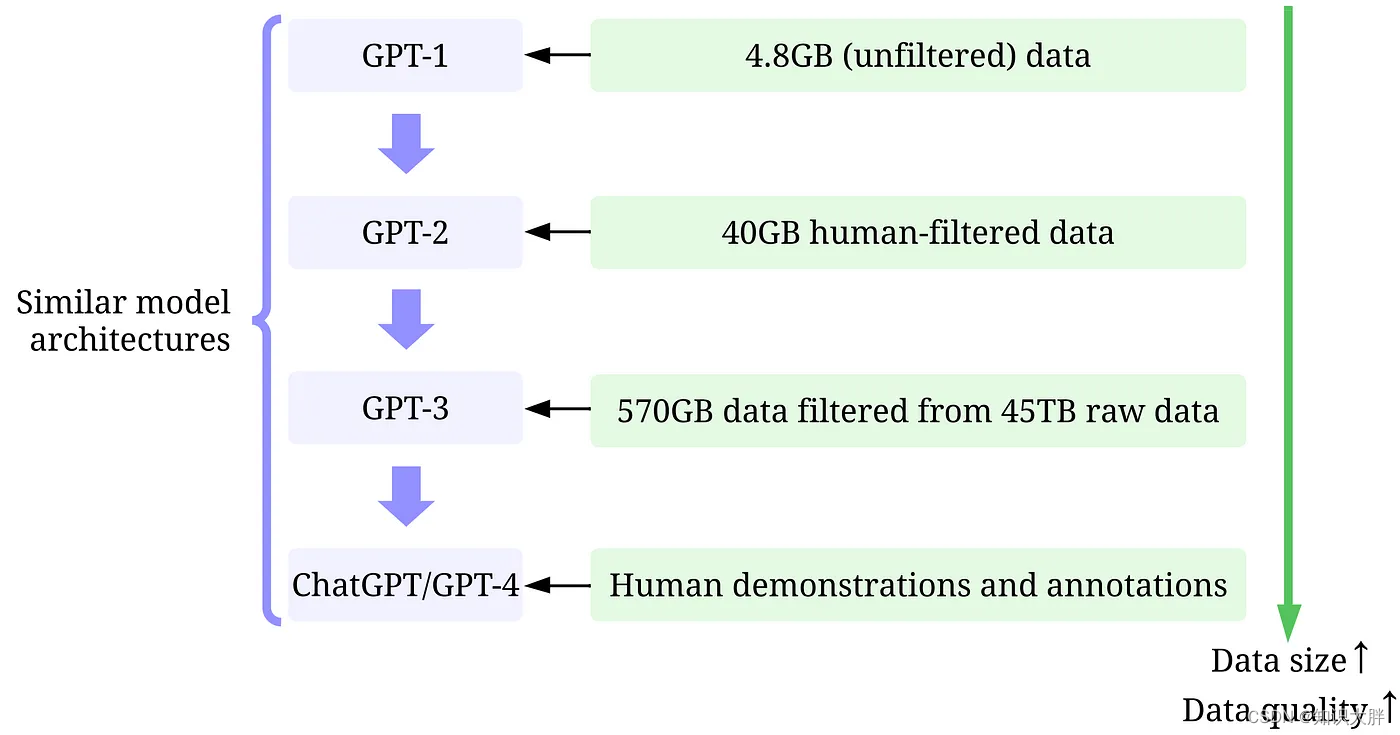
GPT模型是指OpenAI创建的一系列LLM,如GPT-1、GPT-2、GPT-3、InstructGPT、ChatGPT/GPT-4等。与其他 LLM 一样,G