论文标题:CARD: Channel Aligned Robust Blend Transformer for Time Series Forecasting
论文链接:https://arxiv.org/abs/2305.12095
代码链接:https://github.com/wxie9/CARD
前言
Transformer取得成功的一个关键因素是通道独立(CI)策略,包括Patch TST在内的很多模型都使用了该策略。然而,CI策略忽略了不同通道之间的相关性,这会限制模型的预测能力。在Channel Aligned Robust Blend (CARD)中,作者针对通道独立进行改进。首先,CARD引入了一种通道对齐的注意力结构,使其能够捕捉信号之间的时间相关性以及多个变量随时间的动态依赖性。其次,为了有效利用多尺度知识,作者设计了一个token混合模块来生成不同分辨率的token。第三,引入一种鲁棒损失函数,以减轻潜在的过拟合问题。这种新的损失函数根据预测不确定性对有限时间范围内的预测重要性进行加权。我们在多个长期和短期预测数据集上的评估表明,CARD显著优于现有的时间序列预测方法。
本文工作
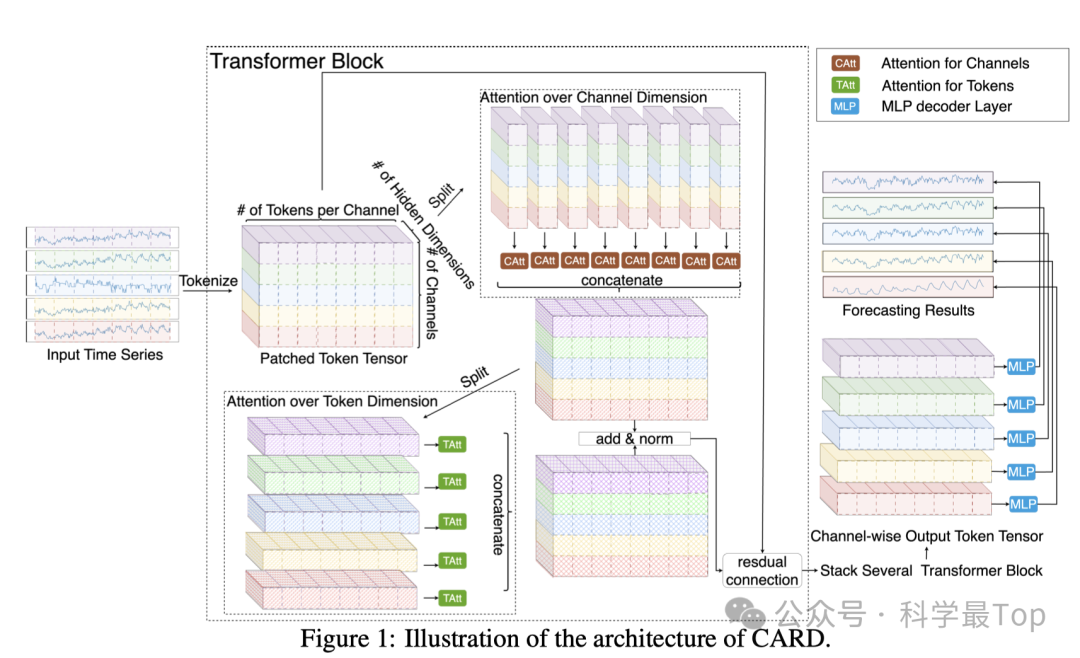
CARD的架构图示见图1。设 𝑎𝑡∈𝑅^𝐶为时间 t 的时间序列观测值,其中通道数 𝐶≥1。我们的目标是使用最近 L 个历史数据点,来预测未来 T 步的观测值。
一、TOKENIZATION
这里作者也是采用了patching的思想,将输入时间序列转换为Token。假设A ∈ ℝ^{C×L}表示输入数据矩阵,S和P分别表示步长和patch长度。作者将矩阵A展开为原始Token张量 ˜X ∈ ℝ^{C×N×P},其中N = ⌊(L-P)/S + 1⌋。这里将时间序列转换为多个长度为P的patch,每个原始Token都保留了部分序列级别的语义信息。
然后,通过一个包含额外静态Token和位置嵌入的MLP层来生成最终的Token,这个矩阵用于后续的注意力机制。这一块包含的公式比较多,可以参考原文,由于patch不仅保留了序列级别的语义信息,还通过引入额外的静态信息增强了模型对长期历史特征的捕捉能力。
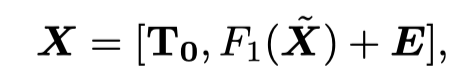
二、CARD ATTENTIONS OVER TOKENS
当对tokens进行注意力操作时,将第 𝑖 个注意力头的查询 𝑄、键 𝐾 和值 𝑉在通道维度上分割成 {𝑄},(𝑁+1)×𝑑{𝐾} 和 {𝑉},其中 𝑄,𝐾,𝑉 ∈ 𝑅 且 𝑐=1,2,...,𝐶。除了标准的标记注意力外,作者还引入了一个额外的在隐藏维度上的注意力结构,有助于捕获每个局部区域内的信息。在token和隐藏维度上的注意力计算如下:
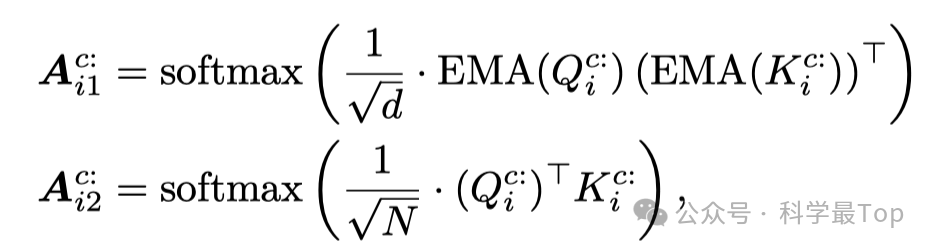
通过对 𝑄 和 𝐾 应用指数移动平均(EMA),每个查询token能够对更多的键标记获得更高的注意力得分,从而使输出结果更加稳定。每个通道的总token数量大约是 𝑂(𝐿/𝑆),沿标记的注意力复杂度上界是 𝑂(𝐶⋅𝑑2⋅𝐿2/𝑆2),这比普通逐点标记构造的 𝑂(𝐶⋅𝑑2⋅𝐿2) 复杂度要小。
三、CARD ATTENTION OVER CHANNELS
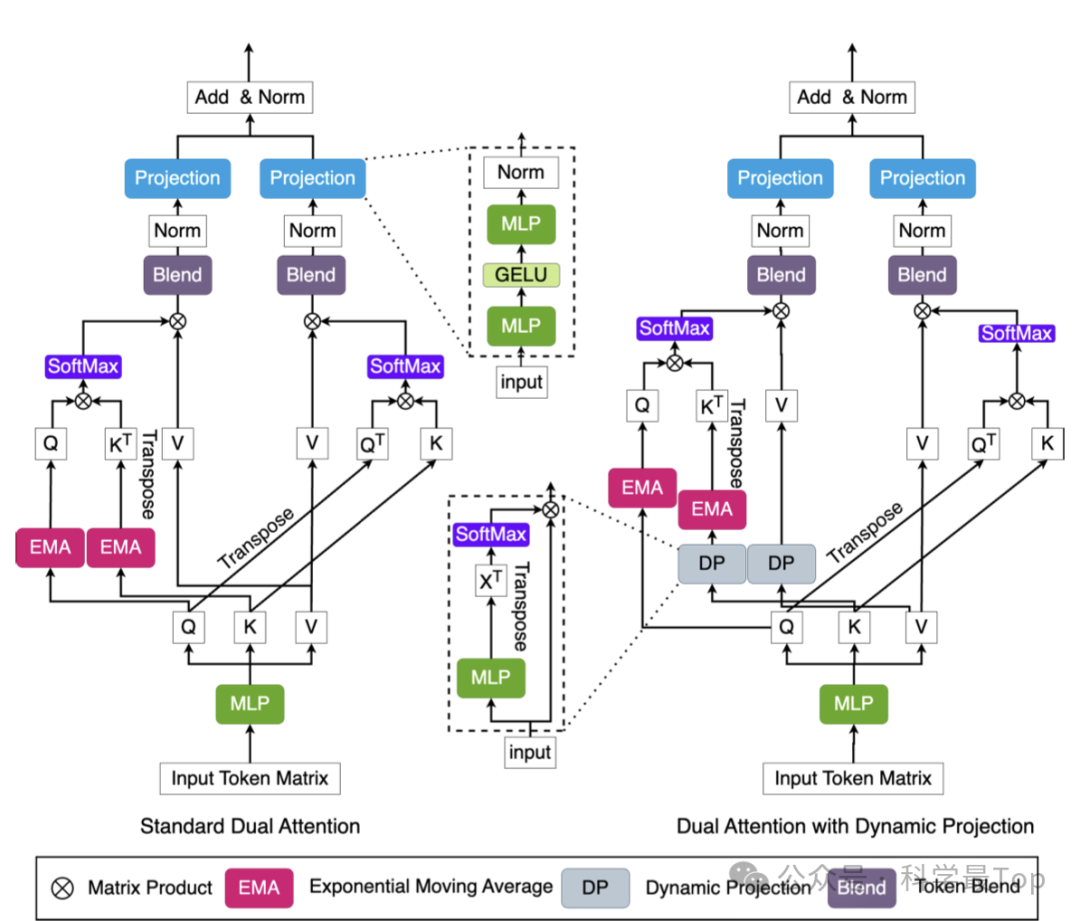
这一部分公式较多,还是建议阅读原文。如图2所示,使用动态投影技术来获取对第n个token维度的 𝐾和 𝑉的“summarized” token,我们首先使用MLP层将头维度从 𝑑ℎ𝑒𝑎𝑑 投影到某个固定的 𝑟,其中 𝑟≪𝐶,然后我们使用softmax函数来归一化投影后的张量。
四、CARD ATTENTION OVER CHANNELS
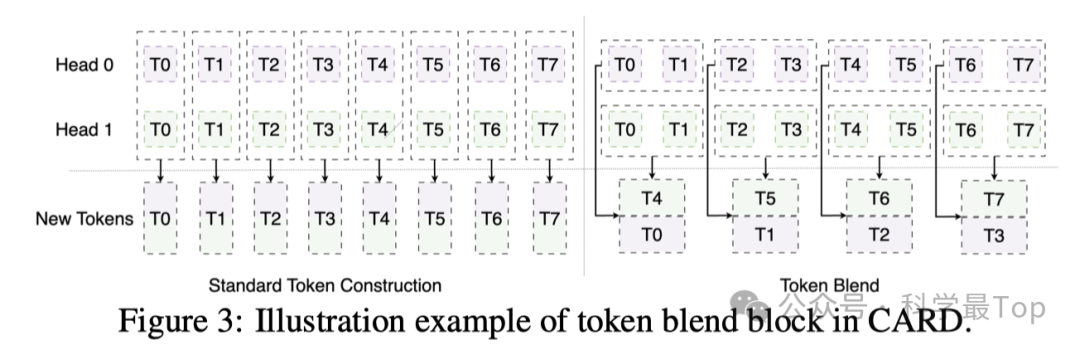
作者提出了一种特别设计的token混合机制,以利用多尺度结构知识,同时避免了额外的计算成本。该机制通过合并多头注意力中同一头内的相邻token,来取代标准token重建过程,从而为下一阶段生成新的token。输出token张量 𝑂 经过重塑和解耦,形成新的3-D张量,进而通过调整混合大小来控制token的合并程度。与先前工作中的分层合并不同,我们的方法在头级别进行合并,保持了输出token序列的形状,并且大小更为灵活。这种方法在不增加额外显式信号解耦过程的情况下,增强了对多尺度信息的提取能力。
实验和总结
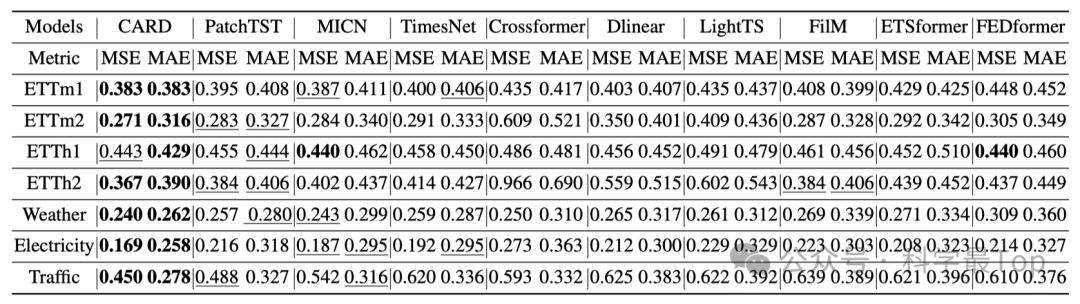
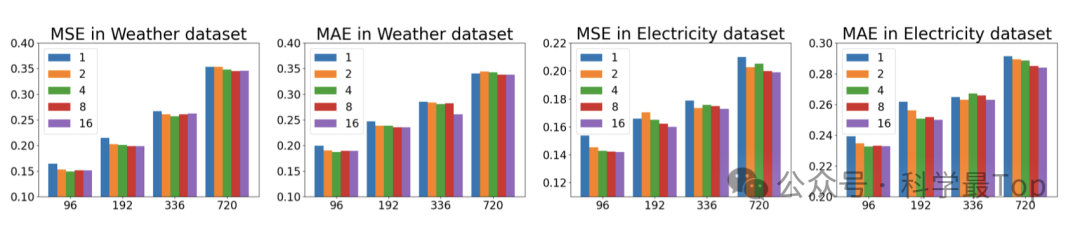
在本文中,作者提出了一种新颖的Transformer模型,CARD,用于时间序列预测。CARD是一个依赖于通道的模型,能够有效地对不同变量和隐藏维度之间的信息进行对齐。CARD通过同时对token和通道应用注意力机制,改进了传统Transformer。新设计的注意力机制有助于探索每个token内的局部信息,使其在时间序列预测中更加有效。还提出了一个token混合模块,以利用时间序列中的多尺度信息知识。对比实验表明作者提出的模型超越了现有的最先进模型。
大家一定要关注我的公众号【科学最top】,第一时间follow时序高水平论文解读!!!