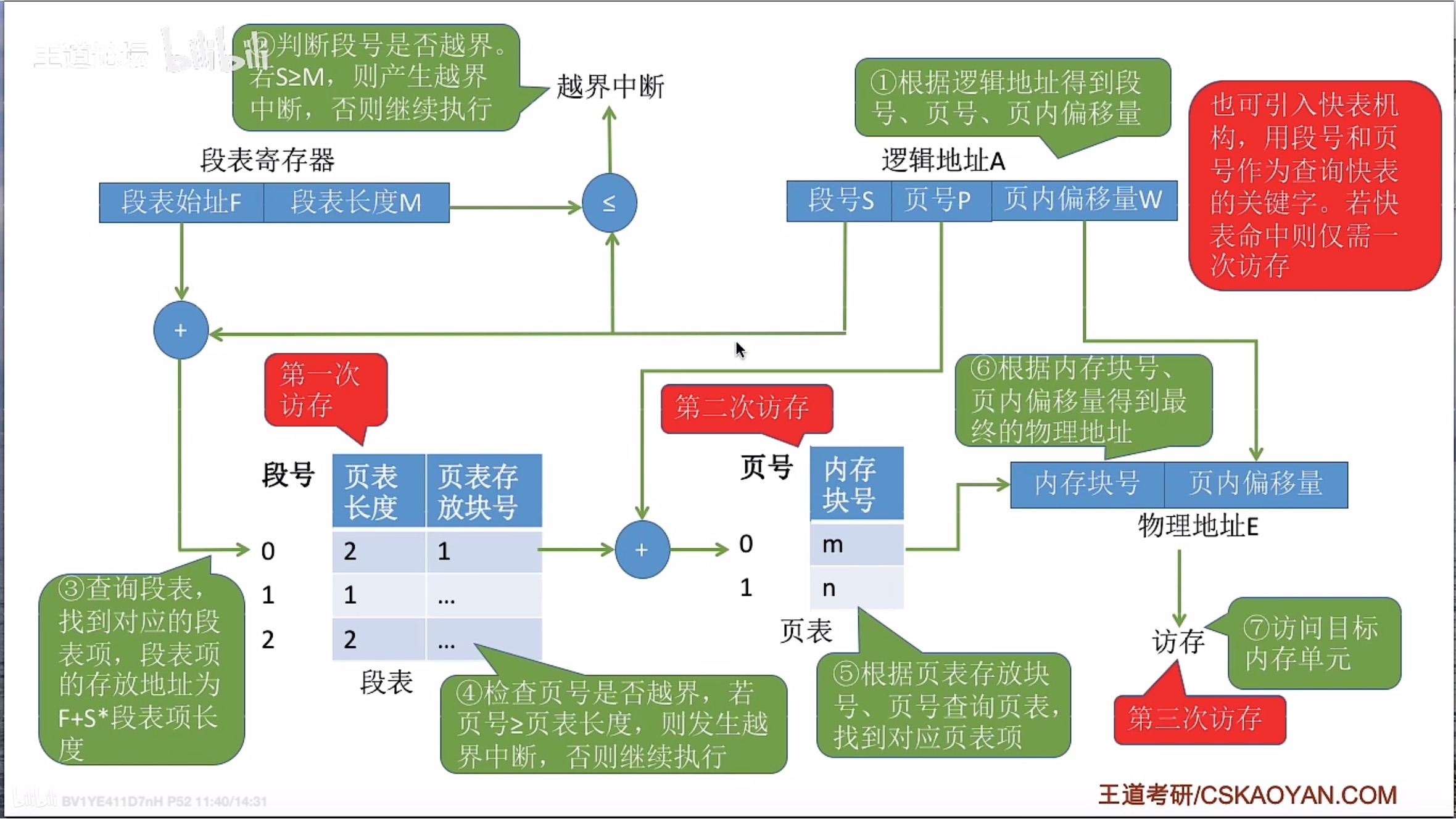
1.如何获取网站信息?
(1)调用requests库、bs4库
#检查库是否下载好的方法:打开终端界面(terminal)输入pip install bs4,
如果返回的信息里有Successfully installed bs4 说明安装成功(requests同理)
from bs4 import BeautifulSoup
import requests(2)访问网站
import requests
response = requests.get("https://movie.douban.com/top250")
print(response.status_code) #HTTP状态响应码
if response.ok:print(response.text)
else:print("请求失败")输出结果:
418
请求失败
无法访问原因:
有些网站会检查请求的 User-Agent,如果没有提供合适的 User-Agent,可能会拒绝访问。
(3)添加 User-Agent 头部
打开网站->右键->检查->network

刷新网页—>点击任意一个模块—>在headers一栏找到"User-Agent"—>复制冒号后面的内容

headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0"
}
response = requests.get("https://movie.douban.com/top250",headers=headers)(4)判断网站是否响应
如果状态码为200说明访问成功
import requests
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0"
}
response = requests.get("https://movie.douban.com/top250",headers=headers)
print(response.status_code) #HTTP状态响应码
if response.ok:print(response.text)
else:print("请求失败")2.如何筛选出标题?
(1)分析网站的html文本
找出标题所在html文本的特点:

使用findAll函数筛选
response = requests.get("https://movie.douban.com/top250",headers=headers)
content = response.text
soup = BeautifulSoup(content, "html.parser")
all_titles = soup.findAll("span", attrs={"class": "title"})
for t in all_titles:print(t.string)输出结果:此时输出的标题不仅有中文标题还有原版标题
肖申克的救赎
/ The Shawshank Redemption
霸王别姬
阿甘正传
/ Forrest Gump
泰坦尼克号
/ Titanic
千与千寻
/ 千と千尋の神隠し
这个杀手不太冷
/ Léon
美丽人生
/ La vita è bella
星际穿越
/ Interstellar
盗梦空间
/ Inception
楚门的世界
/ The Truman Show
辛德勒的名单
/ Schindler's List
忠犬八公的故事
/ Hachi: A Dog's Tale
海上钢琴师
/ La leggenda del pianista sull'oceano
三傻大闹宝莱坞
/ 3 Idiots
放牛班的春天
/ Les choristes
机器人总动员
/ WALL·E
疯狂动物城
/ Zootopia
无间道
/ 無間道
控方证人
/ Witness for the Prosecution
大话西游之大圣娶亲
/ 西遊記大結局之仙履奇緣
熔炉
/ 도가니
教父
/ The Godfather
触不可及
/ Intouchables
当幸福来敲门
/ The Pursuit of Happyness
寻梦环游记
/ CocoProcess finished with exit code 0
如何筛选出中文标题:
all_titles = soup.findAll("span", attrs={"class": "title"})for t in all_titles:str = t.stringif "/" not in str: #筛选出中文标题print(str)
运行结果:
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
千与千寻
这个杀手不太冷
美丽人生
星际穿越
盗梦空间
楚门的世界
辛德勒的名单
忠犬八公的故事
海上钢琴师
三傻大闹宝莱坞
放牛班的春天
机器人总动员
疯狂动物城
无间道
控方证人
大话西游之大圣娶亲
熔炉
教父
触不可及
当幸福来敲门
寻梦环游记
3.如何爬取250个电影标题?
首先观察网址链接,找出不同点:
“https://movie.douban.com/top250?start=0&filter=”
“https://movie.douban.com/top250?start=25&filter=”
“https://movie.douban.com/top250?start=50&filter=”
......
“https://movie.douban.com/top250?start=175&filter=”
“https://movie.douban.com/top250?start=200&filter=”
“https://movie.douban.com/top250?start=225&filter=”
特点:网站总共有十页,每一页网址链接只有"start="后面的数字不一样
而数字正是每一页网页的第一个电影的索引,而每一页一共25个电影,因此可以才用for循环来访问这十个不同的网址:
for start_num in range(0,250,25): #第一个电影索引是0,第二个电影索引是249,每页网页有25个电影response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)最终代码:
from bs4 import BeautifulSoup
import requests
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0"
}
for start_num in range(0,250,25): #第一个电影索引是0,第二个电影索引是249,每页网页有25个电影response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)content = response.textsoup = BeautifulSoup(content, "html.parser")all_titles = soup.findAll("span", attrs={"class": "title"})for t in all_titles:str = t.stringif "/" not in str: #筛选出中文标题print(str)
response.close() #关掉response