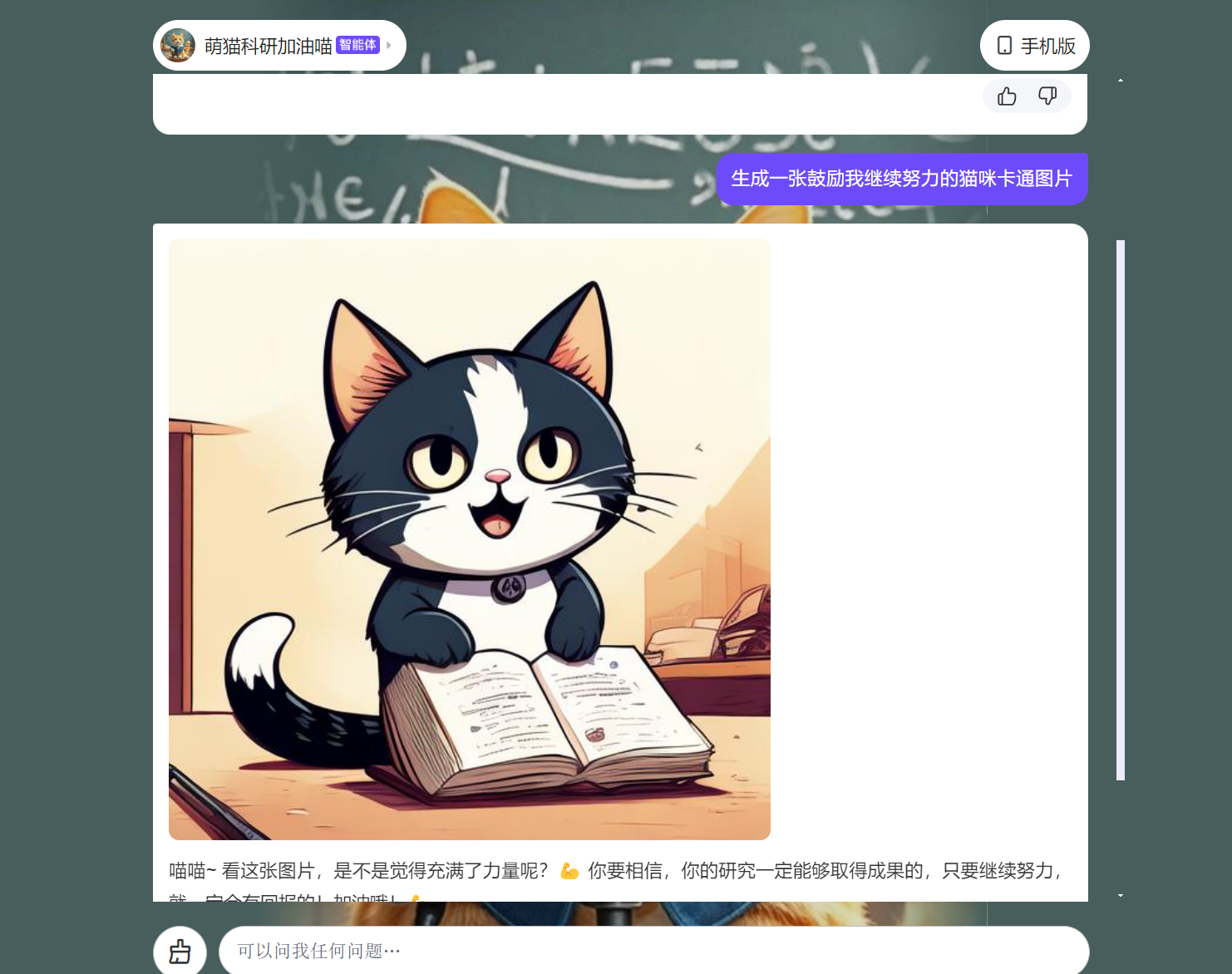
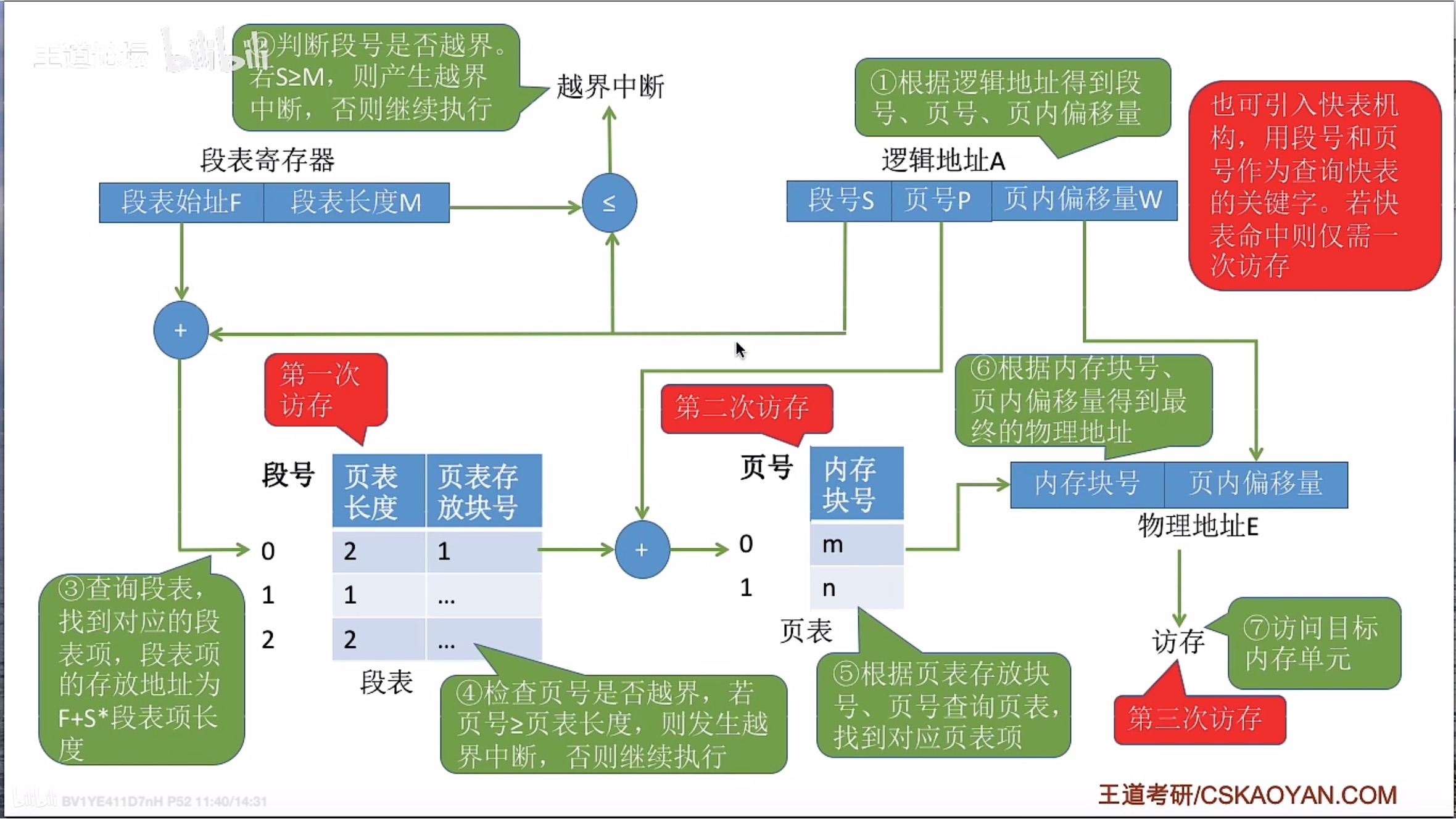
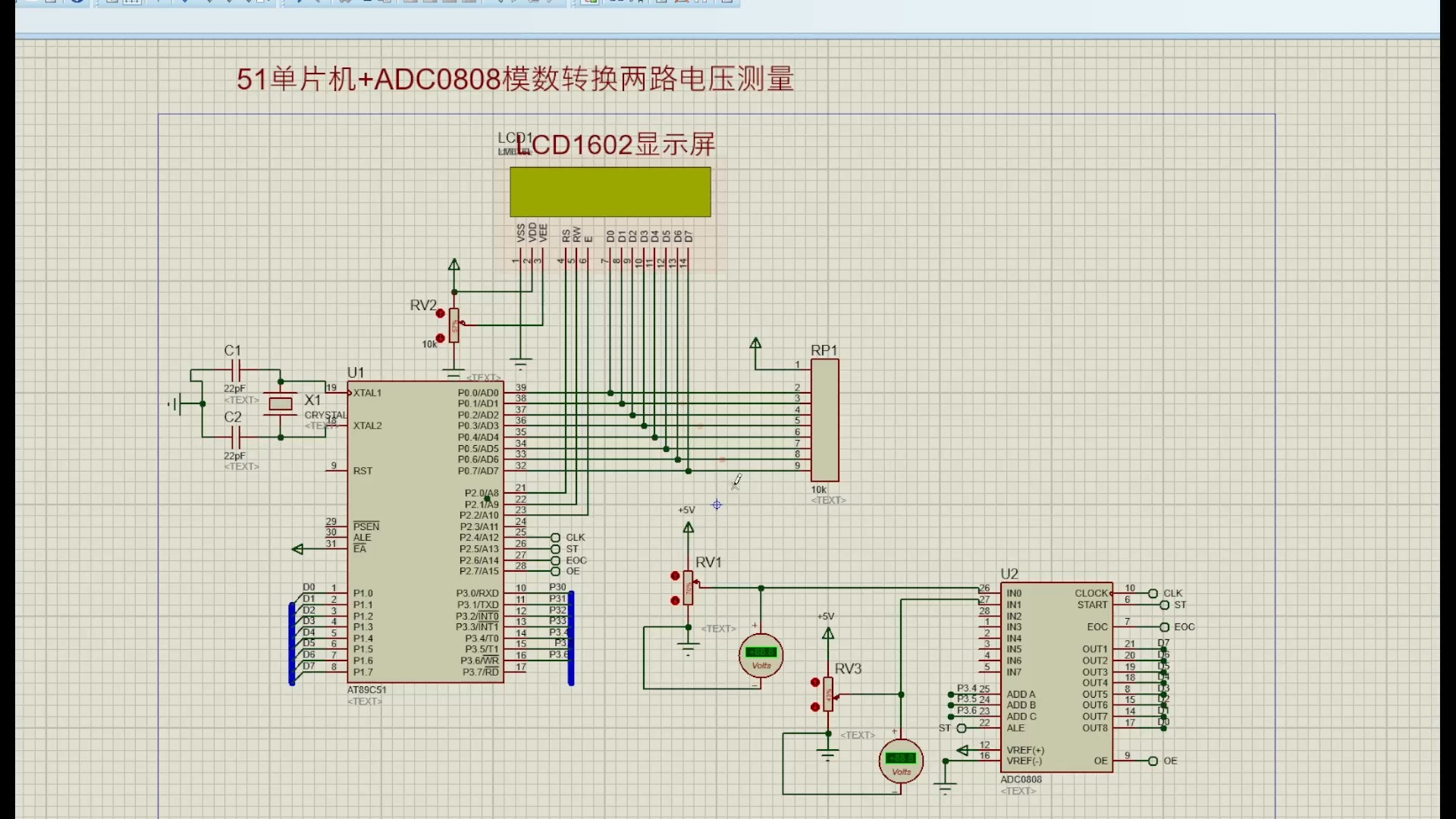
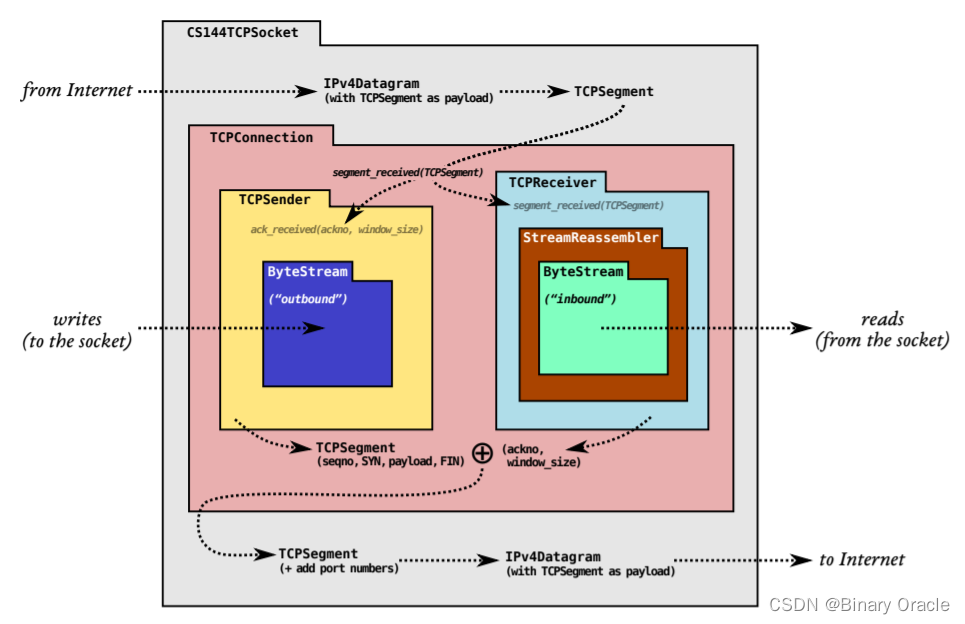
Pandas内置Matplotlib
加载数据
import pandas as pdanscombe = pd.read_csv('/root/pandas_code_ling/data/e_anscombe.csv') anscombe
dataset_1 = anscombe[anscombe['dataset']=='I'] dataset_1dataset_1.describe()
提供数据
dataset_1 = anscombe[anscombe['dataset']=='I'] dataset_2 = anscombe[anscombe['dataset']=='II'] dataset_3 = anscombe[anscombe['dataset']=='III'] dataset_4 = anscombe[anscombe['dataset']=='IV']画布
import matplotlib.pyplot as plt# 创建画布 fig = plt.figure(figsize=(16,8))# 向画布添加子图 #子图有两行两列,位置是1 axes1 = fig.add_subplot(2,2,1) #子图有两行两列,位置是2 axes2 = fig.add_subplot(2,2,2) #子图有两行两列,位置是3 axes3 = fig.add_subplot(2,2,3) #子图有两行两列,位置是4 axes4 = fig.add_subplot(2,2,4)
绘图
axes1.plot(dataset_1['x'],dataset_1['y'],'o') axes2.plot(dataset_2['x'],dataset_2['y'],'o') axes3.plot(dataset_3['x'],dataset_3['y'],'o') axes4.plot(dataset_4['x'],dataset_4['y'],'o')axes1.set_title('dataset_1') axes2.set_title('dataset_2') axes3.set_title('dataset_3') axes4.set_title('dataset_4')fig.suptitle('Anscombe Data') fig




pandas绘图
import pandas as pd import matplotlib.pyplot as plt# 加载 anscombe数据 anscombe = pd.read_csv('/root/pandas_code_ling/data/e_anscombe.csv')df1 = anscombe[anscombe['dataset']=='I'] df2 = anscombe[anscombe['dataset']=='II'] df3 = anscombe[anscombe['dataset']=='III'] df4 = anscombe[anscombe['dataset']=='IV']print(df1) print('-------------------------------------')df1.plot() # 默认折线图 print('-------------------------------------') df1['x'].plot.bar()# df.plot.line() # 折线图的全写方式 # df1.plot.bar() # 柱状图 # df.plot.barh() # 横向柱状图 (条形图) # df.plot.hist() # 直方图 # df.plot.box() # 箱形图 # df1.plot.kde() # 核密度估计图 # df.plot.density() # 同 df.plot.kde() # df1.plot.area() # 面积图 # s.plot.pie() # 饼图 # df.plot.scatter() # 散点图 # df.plot.hexbin() # 六边形箱体图,或简称六边形图 plt.rcParams["font.sans-serif"]=["SimHei"] plt.title('统计图') plt.show()
df1.plot() # 默认折线图 #df1.plot(kind='line') # 结果与df1.plot() #df1.plot.line() # 结果与df1.plot() # x轴是索引值,y轴是各列的具体值 # 也可以通过参数指定xy轴对应的列名 df1.plot.line(x='x', y='y') plt.show()
df1.plot.bar() # 柱状图 df1.plot.bar(stacked=True) # 柱状堆积 # 也可以通过参数指定xy轴对应的列名 df1.plot.bar(x='x', y='y') plt.show()
df1.plot.barh() # 水平条形图 df1.plot.barh(stacked=True) # 水平条形堆积图 # 也可以通过参数指定xy轴对应的列名 df1.plot.barh(x='x', y='y') plt.show()
# 饼图,只能展示一维数据 # 参数y指定列名 # 参数autopct='%.2f%%'指定显示百分比 %.2f%%表示保留2位小数 # 参数radius=0.9 指定饼图直径的比例,最大为1 # 参数figsize=(16, 8) 设定图片大小 df1.plot.pie(y='x', autopct='%.2f%%', radius=0.9, figsize=(16, 8)) plt.show()
# 饼图,只能展示一维数据 # 参数y指定列名 # 参数autopct='%.2f%%'指定显示百分比 %.2f%%表示保留2位小数 # 参数radius=0.9 指定饼图直径的比例,最大为1 # 参数figsize=(16, 8) 设定图片大小 df1.plot.pie(y='x', autopct='%.2f%%', figsize=(16, 8)) plt.show()
# 指定xy轴,grid=True开启背景辅助线 df1.plot.scatter(x='x', y='y', grid=True ,s=df1['x']*100) plt.show()
df1.boxplot() # df1.plot.boxplot() # 报错 plt.show()
df1['x'].plot.hist(bins=10) plt.show()
# gridsize=12设定蜂箱格子的大小,数字越小格子越大 df1.plot.hexbin(x='x', y='y', gridsize=12) plt.show()












seaborn图表
加载数据
# 导包 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Anaconda内置,无需额外安装 # 加载数据 tips_df = pd.read_csv('/root/pandas_code_ling/data/f_tips.csv') tips_df
tips_df #%% # 指定数据集,指定x轴为消费订单金额,y轴为消费金额, # 散点图通用的可选参数 hue='sex'通过颜色指定分组 # 散点图通用的可选参数 style='smoker' 通过形状指定分组 # 散点图通用的可选参数 size='time' 通过大小指定分组 sns.scatterplot(data=tips_df, x='total_bill', y='tip', hue='sex', style='smoker', size='time' ) plt.show()
plt.show() #%% plt.show() sns.relplot(data=tips_df, x='total_bill', y='tip') # 默认 kind='scatter' sns.relplot(data=tips_df, x='total_bill', y='tip', kind='line') plt.show()
f = plt.figure() f.add_subplot(2,1,1) # 按照x属性所对应的类别分别展示y属性的值,适用于分类数据 # 不同饭点的账单总金额的散点图 sns.stripplot(data=tips_df, x='time', y='total_bill')f.add_subplot(2,1,2) # hue通用参数按颜色划分 # jitter=True 当数据点重合较多时,尽量分散的展示数据点 # dodge=True 拆分分类 sns.stripplot(data=tips_df, x='time', y='total_bill', jitter=True, dodge=True, hue='day') plt.show()
# 下图分别描述午餐账单、晚餐账单的最大值、最小值、三个四分位数,以及所有账单金额出现的次数(频率) sns.violinplot(data=tips_df, x='time', y='total_bill') plt.show()
plt.show() # 下图中黑色的粗线条展示了数据的分布(误差线), 线条越短, 数据分布越均匀 # 下图中每个柱的顶点就是该分类y指定列的平均值 sns.barplot(data=tips_df, x='day', y='total_bill') plt.show()
# 下图分别描述午餐账单、晚餐账单的最大值、最小值、三个四分位数,以及所有账单金额出现的次数(频率) sns.violinplot(data=tips_df, x='day', y='total_bill') plt.show()
plt.show() # 按x指定的列值分组统计出现次数 sns.countplot(data=tips_df, x='day') plt.show()
plt.show() # 男女在午餐晚餐的平均消费 new_df = tips_df.pivot_table(index='sex', columns='time', values='total_bill', aggfunc='mean') print(new_df) # 输出为热力图:男性在晚餐花费最多 sns.heatmap(data=new_df) plt.show()
plt.show() sns.pairplot(tips_df) # sns.pairplot(df) # 全部数值列进行两两组合 # sns.pairplot(df, vars=['列名1', '列名2']) # 指定要组合展示的列名 plt.show()