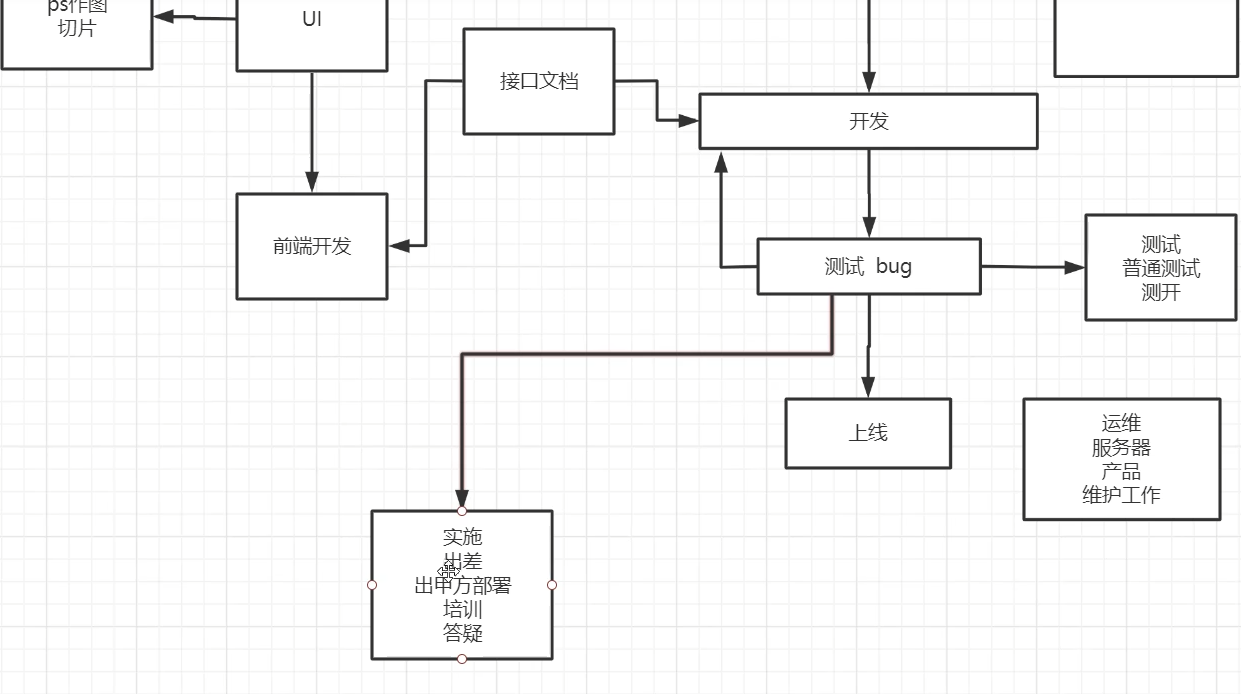
Unity打包图集相关


![]()


![]()


Draw Call
实验设置:
我们将创建两个场景,一个场景有高 Draw Call,另一个场景通过优化减少 Draw Call。然后对比它们的帧率(FPS)。
场景 1:高 Draw Call 场景(无优化)
- 目标:增加 Draw Call 数量。
- 对象:放置 100 个 Cube。
- 材质:给每个 Cube 分配不同的材质。
- 每个对象将生成一个新的 Draw Call。
- 使用简单材质即可,比如不同颜色的标准材质。
场景 2:低 Draw Call 场景(优化)
- 目标:减少 Draw Call。
- 对象:同样放置 100 个 Cube。
- 材质:给所有 Cube 使用相同的材质。
- Unity 会自动进行静态批处理(Static Batching)或动态批处理(Dynamic Batching),从而减少 Draw Call 数量。
数据对比:
| 场景 | Draw Call 数量 | FPS(高性能设备) | FPS(低性能设备) |
|---|---|---|---|
| 场景 1(高 Draw Call) | ~100 | 60+ | 30-40 |
| 场景 2(低 Draw Call) | ~1-10 | 60+ | 50-60 |
步骤:
- 创建两个场景:一个场景有 100 个使用不同材质的 Cube,另一个场景有 100 个使用相同材质的 Cube。
- 查看帧率:通过 Unity 的 Stats 窗口(在 Game 视图中点击 "Stats" 按钮)查看帧率(FPS)和 Draw Call 的数量。
- 记录 Draw Call 和 FPS:在两种场景中分别记录 Draw Call 和 FPS。
::: 这么多个drawcall才降这么点帧率?感觉还好啊
的确在高性能上,似乎表现的并不明显,但低端机型玩家也是同样存在的
不管drawcall就是在和低端机sayno


Java的迭代器和遍历的并发问题
![]()

迭代器天然知道有并发的遍历删除问题,所以这里用了很modcount去检测数量的不变,有变化就抛出异常



![]() 利用了匿名类对象
利用了匿名类对象


本质是,传入了一个类对象,这里面的泛型参数就是创建collection的时候带入的泛型参数,这里带入的T泛型是string类型,所以传入的consumer类里的泛型
配上 了通配符?super,只能用其父类级别或自己,
调用的是这个consumer类对象的里面的方法,然后让你重写,这里面的accept方法,而这个accept方法会在collection里面的foreach函数里面调用



前面为单个个体,: 后面是数组
数组.for就会补全

既可以遍历集合,也可以遍历数组

迭代器


Java的Collection<>



Java里所有泛型最后编译都会换成object来装
贯彻万物皆对象,于是有了包装类接基本数据类型



不能直接new后面(100)

换成方法复制,因为把常用的全部缓存了,不用额外new,这样常用的就不用多次占内存了
自动装箱,不需要调方法,把值对象转引用后给出

自动拆箱


但只是为了当对象做一个integer对象,很多程序员并不买单,所以在这个对象里又增加了额外的功能


《公路法》
《公路法》有明确规定,擅自在公路上打场晒粮、堆放杂物、设置障碍等行为属于违法行为。并且公路周边也是禁止放牧的。如果没有按照规定在公路放牧,牲畜所有人应当承担相应的法律责;造成人员伤的,牲畜所有人还需要赔偿对方的一切损失,保险公司对于牲畜伤亡不予赔偿。
碰撞到一般牲畜并进行赔偿后能否带走?
假设一名司机在驾车过程中碰撞到一头猪或一只羊并且直接将牲畜撞死,车主按照协商之后赔偿给牲畜所有人费用,之后能不能把撞死的牲畜带走以补偿损失呢?
这是一些汽车爱好者提出的问题。
正确答案:
不可以。
因为赔偿和买卖是两个概念,撇开所谓的动物防疫检测等相关事宜不谈,将牲畜撞死后进行赔偿只是赔偿牲畜所有人的损失。而想要获得被撞死的牲畜就不是赔偿而是买卖的行为,如果能与牲畜所有人协商为买卖,那么带走就是没有问题的。反之,如果牲畜所有人要求赔偿而不接受买卖的话,那么车主就只能接受赔偿的方案。
SQL用户权限和事务




小海豚会自动提交事务,关了也没用,所以要用事务就要用cmd
 rollback:回到开始
rollback:回到开始

mysql命令行登录

默认会自动commit,意思是如果改了就会立刻提交,如果想体现事务的同时性,就必须关掉自动提交,但是每次打开,默认都会把自动提交打开,所以每次打开如果想要用事务一样,就要重新把autocommit关一遍
子表查询综合练习
表的创建和信息的填入

create table students(
student_id int primary key,
name varchar(50),
age int,
gender varchar(10)
);

创建表结构之后,插入数据
insert into students(student_id,name,age,gender)
values(1,'alice',20,'女'),(2,'bob',22,'男'),(3,'charlie',21,'男');
 创建课程表
创建课程表
 插入信息again
插入信息again
 再建第三表,分数表
再建第三表,分数表
与学生表和课程表相关,设置了两个foreign key
foreign key(student_id) references students(student_id),
foreign key (course_id) references courses(course_id)
 分数表的插入
分数表的插入
表的查询操作

select name ,age, course_name,course_socre from students,(select course_name from courses where students.id=course.id)
需求分析为,外连接,学生表为主表

先把各需要查的表连接起来, from students stu left join scores sc on stu.student_id=sc.student_id
from students stu left join scores sc on stu.student_id=sc.student_id
left join courses cou on sc.course_id=cou.course_id
(学生表和分数表有主外键连接,分数表和课程表有主外键连接) ,学生表如果想拼上课程表,没有键的连接,拼不了
小补充:
在 SQL 中,如果你想给表中的所有行添加一个相同的列,并且为这个列设置相同的值,可以通过以下几个步骤来实现:
- 使用
ALTER TABLE添加新列。- 使用
UPDATE为新列的所有行设置相同的值。ALTER TABLE my_table
ADD new_column VARCHAR(255);
UPDATE my_table
SET new_column = 'default_value';
这条语句会将my_table中所有行的new_column列的值设置为'default_value'。如果你希望在添加列的同时为新列设置默认值,你可以使用
DEFAULT关键字。这会在添加列时立即为该列赋一个默认值。ALTER TABLE users
ADD status VARCHAR(10) DEFAULT 'active';
接下来,表之间的联系已经建立,构成了一张已经完整的大表,
接下来就是select后写要查的信息了

![]()
select stu.name,stu.age,cou.course_name,sc.score
执行结果


![]()


![]()


![]()
select avg(score) avgsc from scores group by student_id;
select name ,avgsc from students left join (select id,avg(score) avgsc from scores group by student_id) tmp on students.id=tmp.id
修改后
先连接一下分数表和学生信息表,得到了学生姓名,然后拿学生姓名分组,最后order by avs
desc降序排列



表的整个复制


等同于









![[论文阅读] DVQA: Understanding Data Visualizations via Question Answering](https://i-blog.csdnimg.cn/direct/65840da4a892402abcbad35fac3f137e.png)