【Flask】Flask数据库
- 1.概述
- 2.使用Flask-SQLAlchemy管理数据库
- 3.定义模型
- 4.关系
- 5.数据库操作
- 创建表
- 插入行
- 修改行
- 删除行
- 查询行
1.概述
大多数的数据库引擎都有对应的 Python 包,包括开源包和商业包。Flask 并不限制你使用何种类型的数据库包,因此可以根据自己的喜好选择使用 MySQL、Postgres、SQLite、Redis、MongoDB 或者 CouchDB
如果这些都无法满足需求,还有一些数据库抽象层代码包供选择,例如 SQLAlchemy 和MongoEngine。你可以使用这些抽象包直接处理高等级的 Python 对象,而不用处理如表、文档或查询语言此类的数据库实体
抽象层,也称为对象关系映射(ORM)或对象文档映射(ODM),在用户不知觉的情况下把高层的面向对象操作转换成低层的数据库指令,ORM 和 ODM 把对象业务转换成数据库业务会有一定的损耗,但在一般情况下,ORM 和 ODM 对生产率的提升远远超过了这一丁点儿的性能降低
2.使用Flask-SQLAlchemy管理数据库
Flask-SQLAlchemy 是一个 Flask 扩展,简化了在 Flask 程序中使用 SQLAlchemy 的操作。SQLAlchemy 是一个很强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy 提供了高层 ORM,也提供了使用数据库原生 SQL 的低层功能。
1、pip安装
pip install flask-sqlalchemy
2、在 Flask-SQLAlchemy 中,数据库使用 URL 指定。最流行的数据库引擎采用的数据库 URL格式如下:
- MySQL:
mysql://username:password@hostname/database - PostgreSQL:
postgresql://username:password@hostname/database - SQLite (Unix):
sqlite:absolute/path/to/database - SQLite (Windows):
sqlite:///c:/absolute/path/to/database
配置数据库:
app = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'data.sqlite')
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = Truedb = SQLAlchemy(app)
db 对象是 SQLAlchemy 类的实例,表示程序使用的数据库,同时还获得了 Flask-SQLAlchemy提供的所有功能
3.定义模型
模型这个术语表示程序使用的持久化实体。在 ORM 中,模型一般是一个 Python 类,类中的属性对应数据库表中的列,如下面的例子,定义 Role 和 User 模型:
class Role(db.Model):__tablename__ = 'roles'id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(64), unique=True)def __repr__(self):return '<Role %r>' % self.nameclass User(db.Model):__tablename__ = 'users'id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(64), unique=True, index=True)def __repr__(self):return '<User %r>' % self.username
类变量 __tablename__ 定义在数据库中使用的表名。如果没有定义 __tablename__,Flask-SQLAlchemy 会使用一个默认名字,但默认的表名没有遵守使用复数形式进行命名的约定,所以最好由我们自己来指定表名。其余的类变量都是该模型的属性,被定义为 db.Column 类的实例
db.Column 类构造函数的第一个参数是数据库列和模型属性的类型:
Integer: 普通整数,一般是 32 位有符号整数。- Python 类型:
int
- Python 类型:
SmallInteger: 取值范围小的整数,一般是 16 位有符号整数。- Python 类型:
int
- Python 类型:
BigInteger: 不限制精度的整数。- Python 类型:
int或long
- Python 类型:
Float: 浮点数。- Python 类型:
float
- Python 类型:
Numeric: 定点数。- Python 类型:
decimal.Decimal
- Python 类型:
String: 变长字符串。- Python 类型:
str
- Python 类型:
Text: 变长字符串,对较长或不限长度的字符串做了优化。- Python 类型:
str
- Python 类型:
Unicode: 变长 Unicode 字符串。- Python 类型:
unicode
- Python 类型:
UnicodeText: 变长 Unicode 字符串,对较长或不限长度的字符串做了优化。- Python 类型:
unicode
- Python 类型:
Boolean: 布尔值。- Python 类型:
bool
- Python 类型:
Date: 日期。- Python 类型:
datetime.date
- Python 类型:
Time: 时间。- Python 类型:
datetime.time
- Python 类型:
DateTime: 日期和时间。- Python 类型:
datetime.datetime
- Python 类型:
Interval: 时间间隔。- Python 类型:
datetime.timedelta
- Python 类型:
Enum: 一组字符串。- Python 类型:
str
- Python 类型:
PickleType: 自动使用 Pickle 序列化。- Python 类型: 任何 Python 对象
LargeBinary: 二进制文件。- Python 类型:
str
- Python 类型:
SQLAlchemy 中常用的列选项及其含义:
primary key: 如果设为 True,这列就是表的主键。unique: 如果设为 True,这列不允许出现重复的值。index: 如果设为 True,为这列创建索引,提升查询效率。nullable: 如果设为 True,这列允许使用空值;如果设为 False,这列不允许使用空值。default: 为这列定义默认值。
虽然没有强制要求,但这两个模型都定义了 __repr()__ 方法,返回一个具有可读性的字符串表示模型,可在调试和测试时使用
4.关系
关系型数据库使用关系把不同表中的行联系起来,一对多关系在模型类中的表示方法如示例所示:
class Role(db.Model):# roles表# 其他列的定义...users = db.relationship('User', backref='role')class User(db.Model):# users表# 其他列的定义...role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
关系使用 users 表中的外键连接了两行。添加到 User 模型中的 role_id 列被定义为外键,就是这个外键建立起了关系。传给 db.ForeignKey() 的参数’roles.id’ 表明,这列的值是 roles 表中行的 id 值
添加到 Role 模型中的 users 属性代表这个关系的面向对象视角。对于一个 Role 类的实例,其 users 属性将返回与角色相关联的用户组成的列表。db.relationship() 的第一个参数表明这个关系的另一端是哪个模型。db.relationship() 中的 backref 参数向 User 模型中添加一个 role 属性,从而定义反向关系。这一属性可替代 role_id 访问 Role 模型
这样一来,当你查询一个角色对象时,你可以通过 role.users 属性访问与该角色相关联的所有用户对象,而且当你查询一个用户对象时,你也可以通过 user.role 属性访问该用户所属的角色对象。这种关系的建立使得在查询时能够方便地获取到相关联的对象,提高了数据的访问效率和代码的可读性
定义关系时常用的配置选项:
backref: 在关系的另一个模型中添加反向引用,以便从另一个方向访问这个关系。primaryjoin: 明确指定两个模型之间使用的联结条件。通常在模棱两可的关系中需要指定。lazy: 指定如何加载相关记录。可选值有 select(首次访问时按需加载)、immediate(源对象加载后就加载)、joined(加载记录,但使用联结)、subquery(立即加载,但使用子查询)、noload(永不加载)和 dynamic(不加载记录,但提供加载记录的查询)。uselist: 如果设为 False,不使用列表,而使用标量值指定关系中记录的排序方式。常用于一对一关系中。- order_by: 指定关系中记录的排序方式。
- secondary: 指定多对多关系中关系表的名字。
- secondaryjoin: 在 SQLAlchemy 无法自行决定时,指定多对多关系中的二级联结条件。
除了一对多之外,还有几种其他的关系类型。一对一关系可以用前面介绍的一对多关系表示,但调用 db.relationship() 时要把 uselist 设为 False,把“多”变成“一”。多对一关系也可使用一对多表示,对调两个表即可,或者把外键和 db.relationship() 都放在“多”这一侧。最复杂的关系类型是多对多,需要用到第三张表,这个表称为关系表。
5.数据库操作
创建表
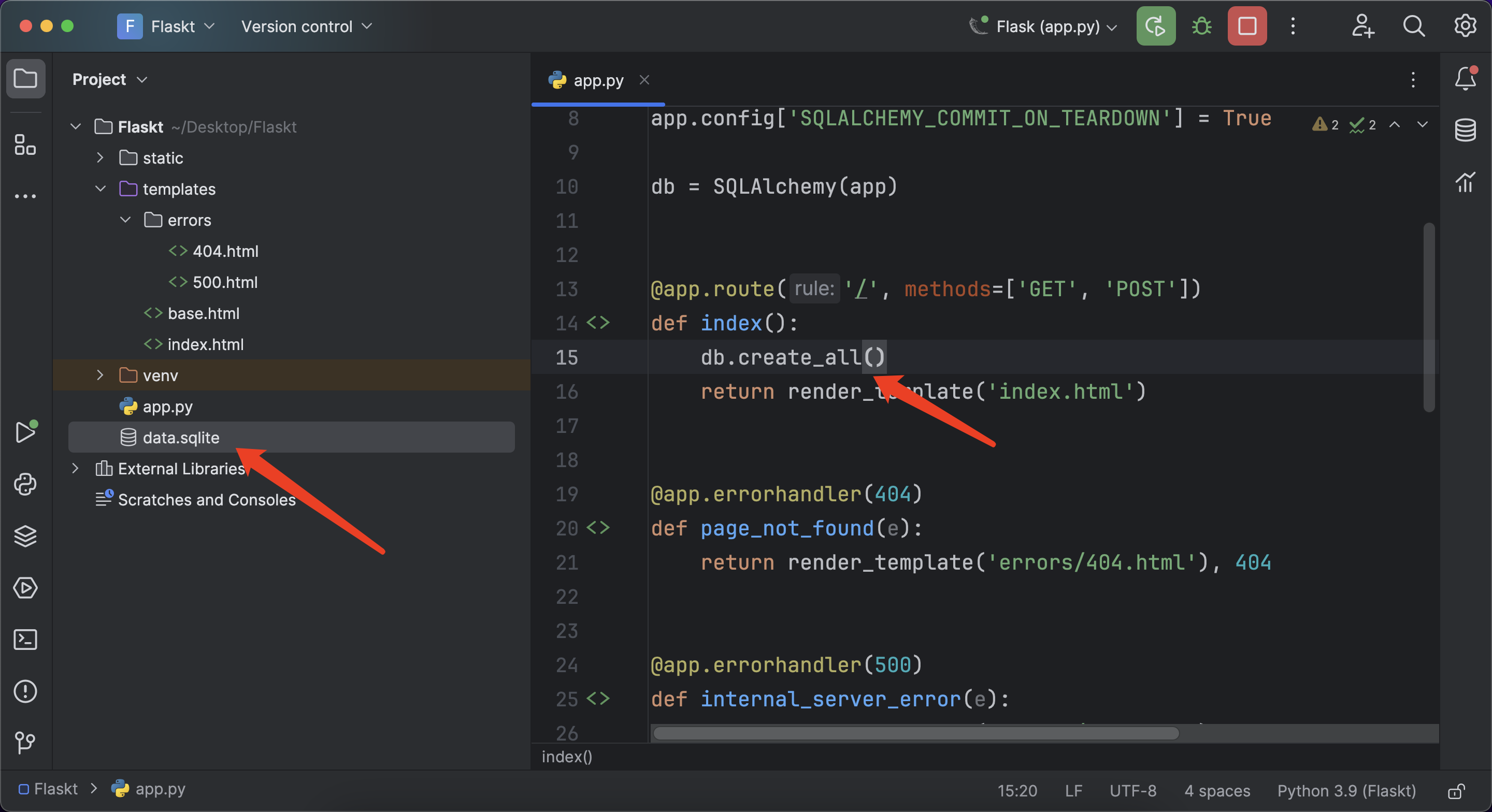
我们要让 Flask-SQLAlchemy 根据模型类创建数据库。方法是使用db.create_all()函数:
db.create_all()
如果你查看程序目录,会发现新建了一个名为 data.sqlite 的文件。这个 SQLite 数据库文件的名字就是在配置中指定的。如果数据库表已经存在于数据库中,那么db.create_all()不会重新创建或者更新这个表
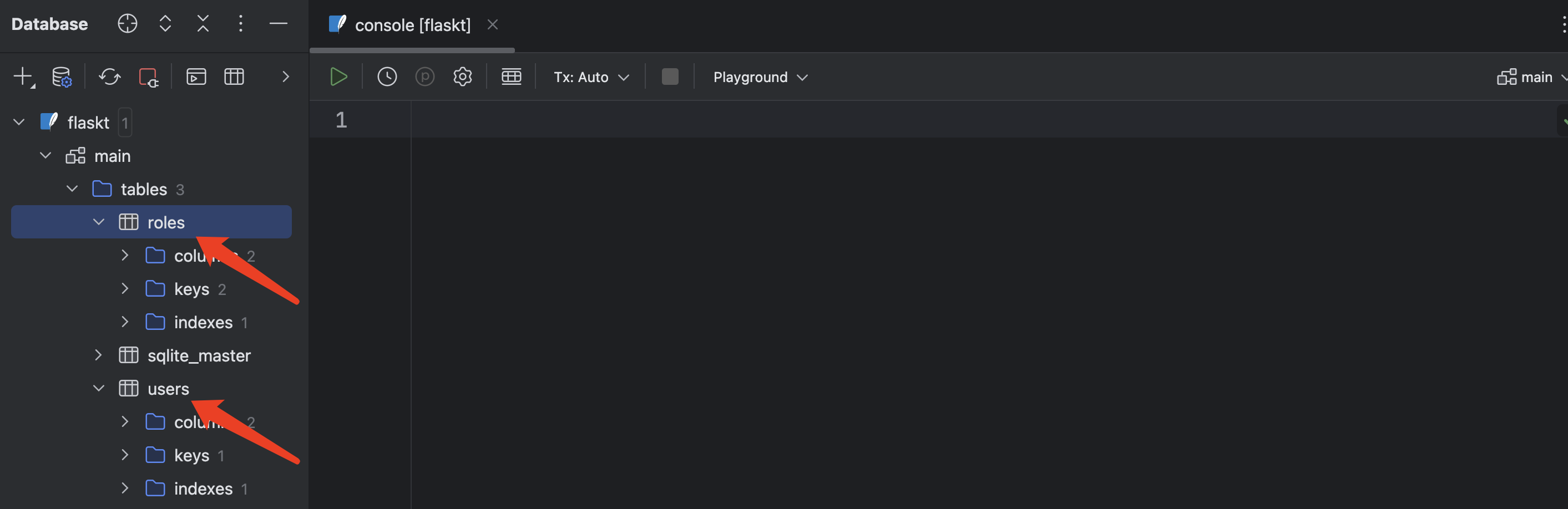
连接data.sqlite,可以看到创建好的roles表和users表:
插入行
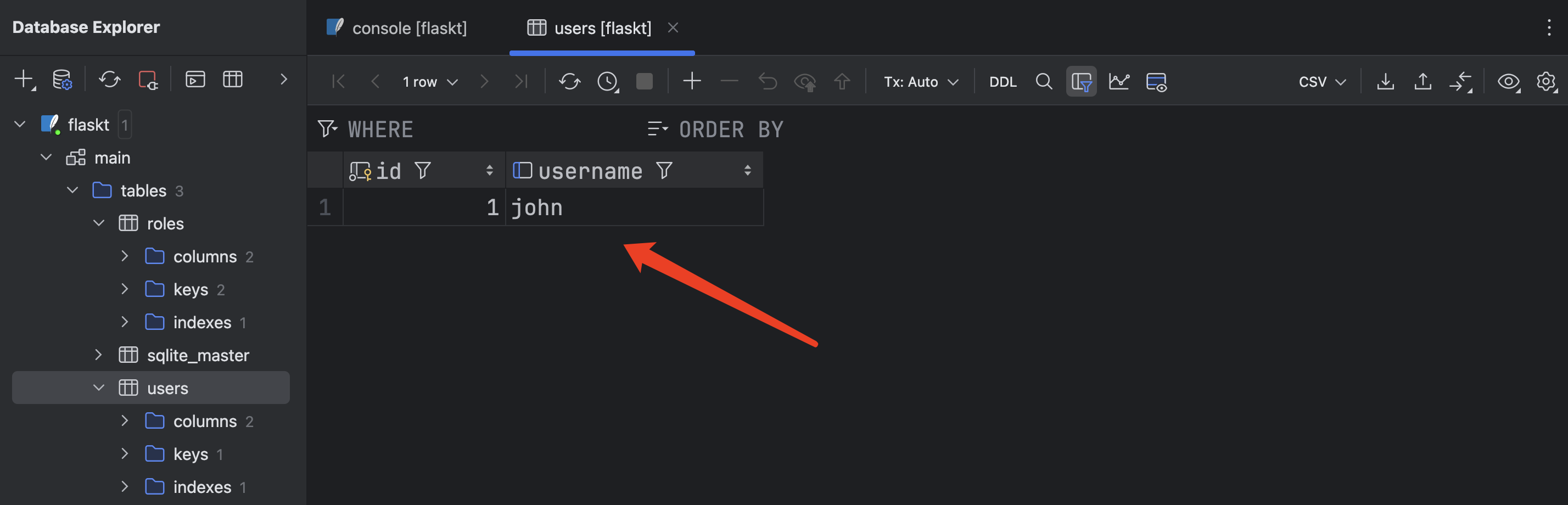
在这个示例中,我们定义了一个名为 User 的数据库模型类,并创建了一个名为 new_user 的新用户对象。我们使用 db.session.add() 将新用户对象添加到会话中,并使用 db.session.commit() 提交会话,将数据插入到数据库中
@app.route('/', methods=['GET', 'POST'])
def index():new_user = User(username='john')db.session.add(new_user)db.session.commit()return render_template('index.html')
在数据库中可以看到插入的新数据(主键自动递增):
修改行
要修改已存在的用户信息,你可以首先查询到该用户对象,然后修改其属性,最后提交会话:
@app.route('/', methods=['GET', 'POST'])
def index():user_to_modify = User.query.filter_by(username='john').first()user_to_modify.username = 'tom'db.session.commit()return render_template('index.html')
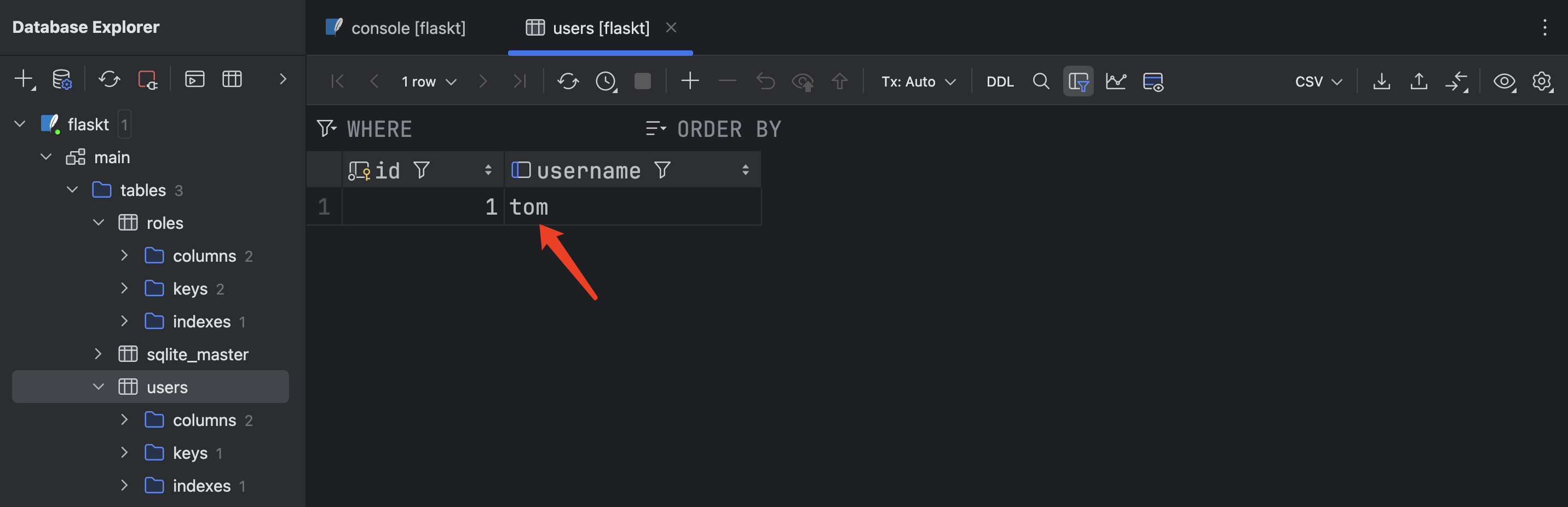
在数据库中可以看到修改的新数据:
删除行
数据库会话还有个 delete() 方法,删除与插入和更新一样,提交数据库会话后才会执行:
@app.route('/', methods=['GET', 'POST'])
def index():user_to_delete = User.query.filter_by(username='tom').first()db.session.delete(user_to_delete)db.session.commit()return render_template('index.html')
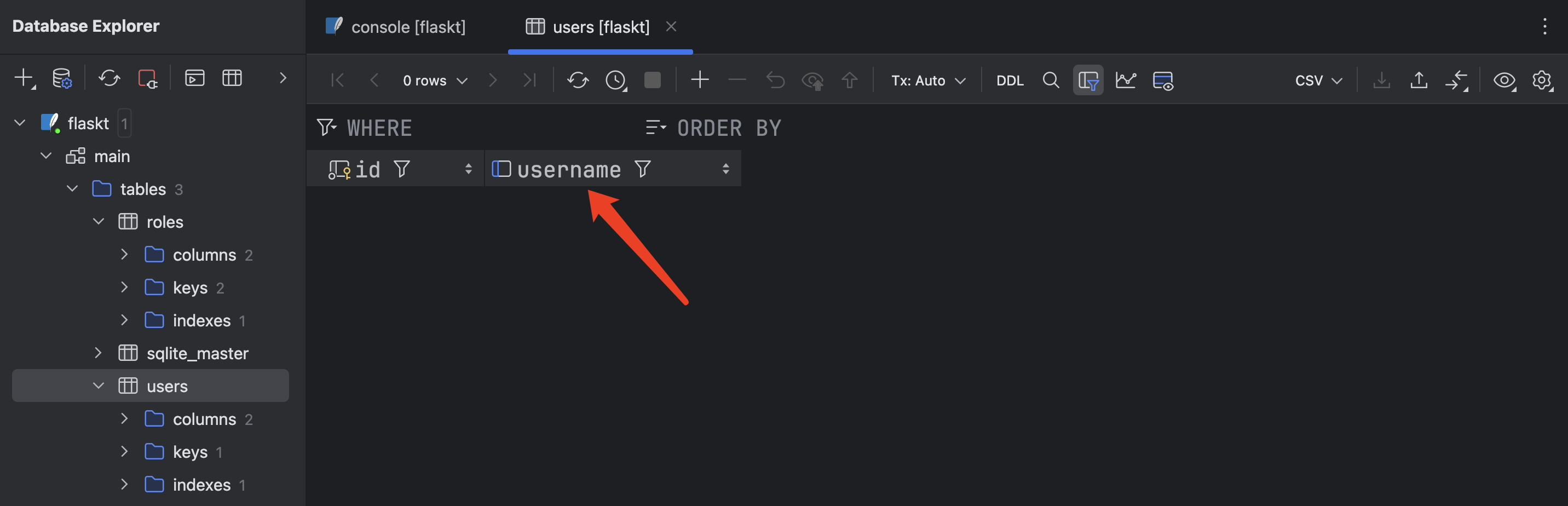
在数据库中可以看到,用户已经被删除了:
查询行
Flask-SQLAlchemy 为每个模型类都提供了 query 对象。最基本的模型查询是取回对应表中的所有记录:
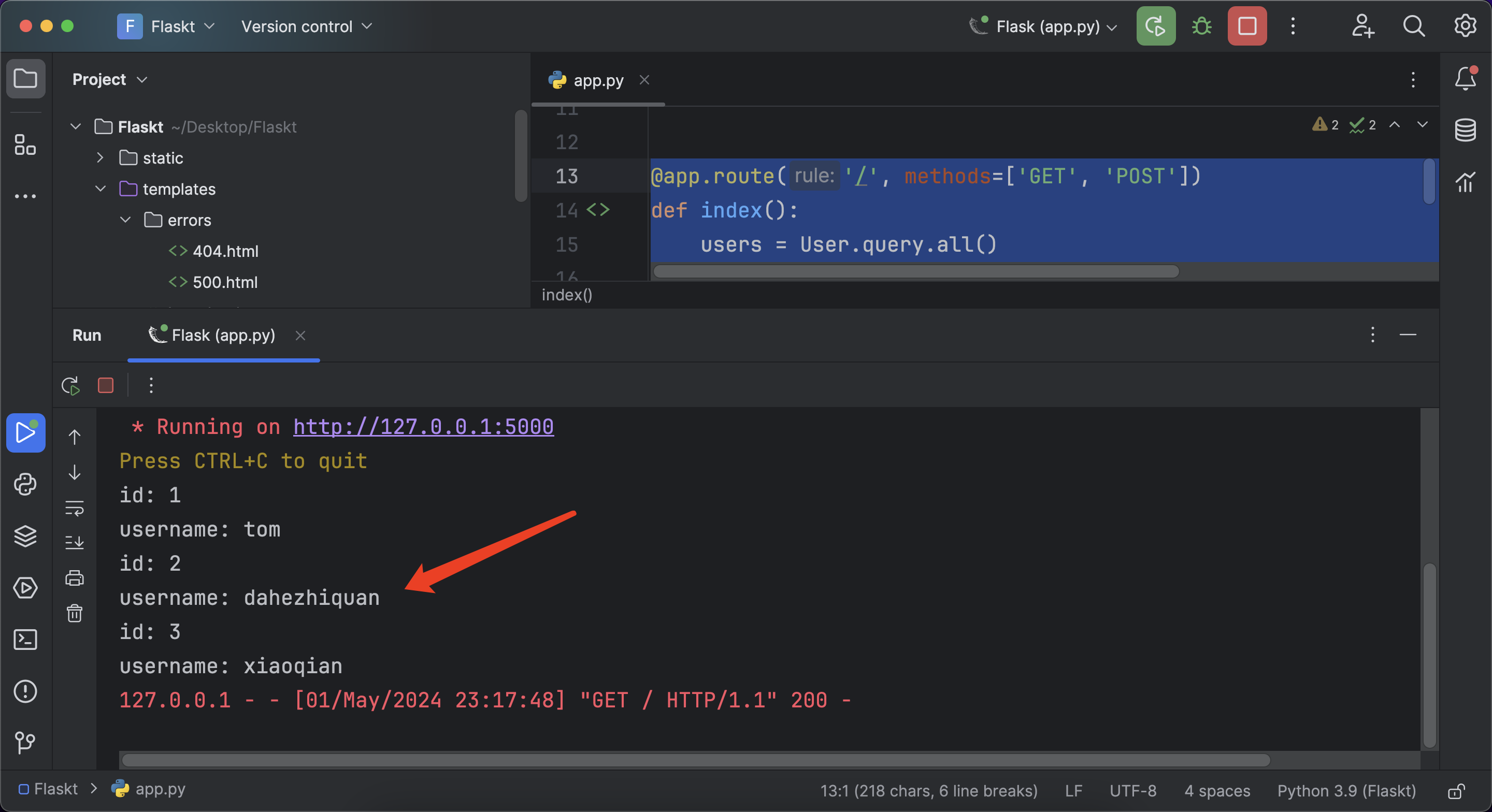
@app.route('/', methods=['GET', 'POST'])
def index():users = User.query.all()for user in users:print("id:", user.id)print("username:", user.username)return render_template('index.html')
使用过滤器可以配置 query 对象进行更精确的数据库查询:
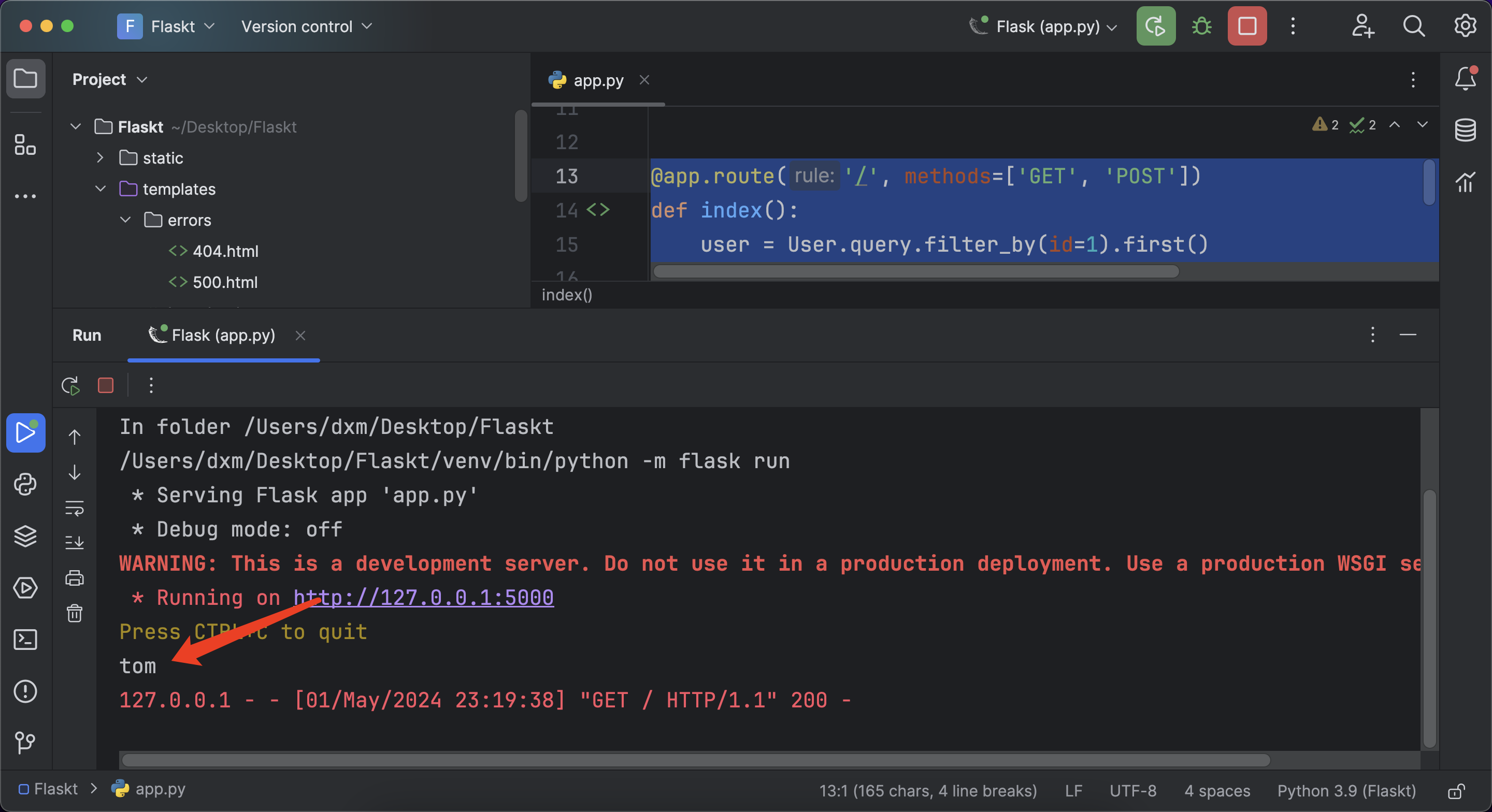
@app.route('/', methods=['GET', 'POST'])
def index():user = User.query.filter_by(id=1).first()print(user.username)return render_template('index.html')
若要查看 SQLAlchemy 为查询生成的原生 SQL 查询语句,只需把 query 对象转换成字符串:
@app.route('/', methods=['GET', 'POST'])
def index():print(User.query.filter_by(id=1))return render_template('index.html')
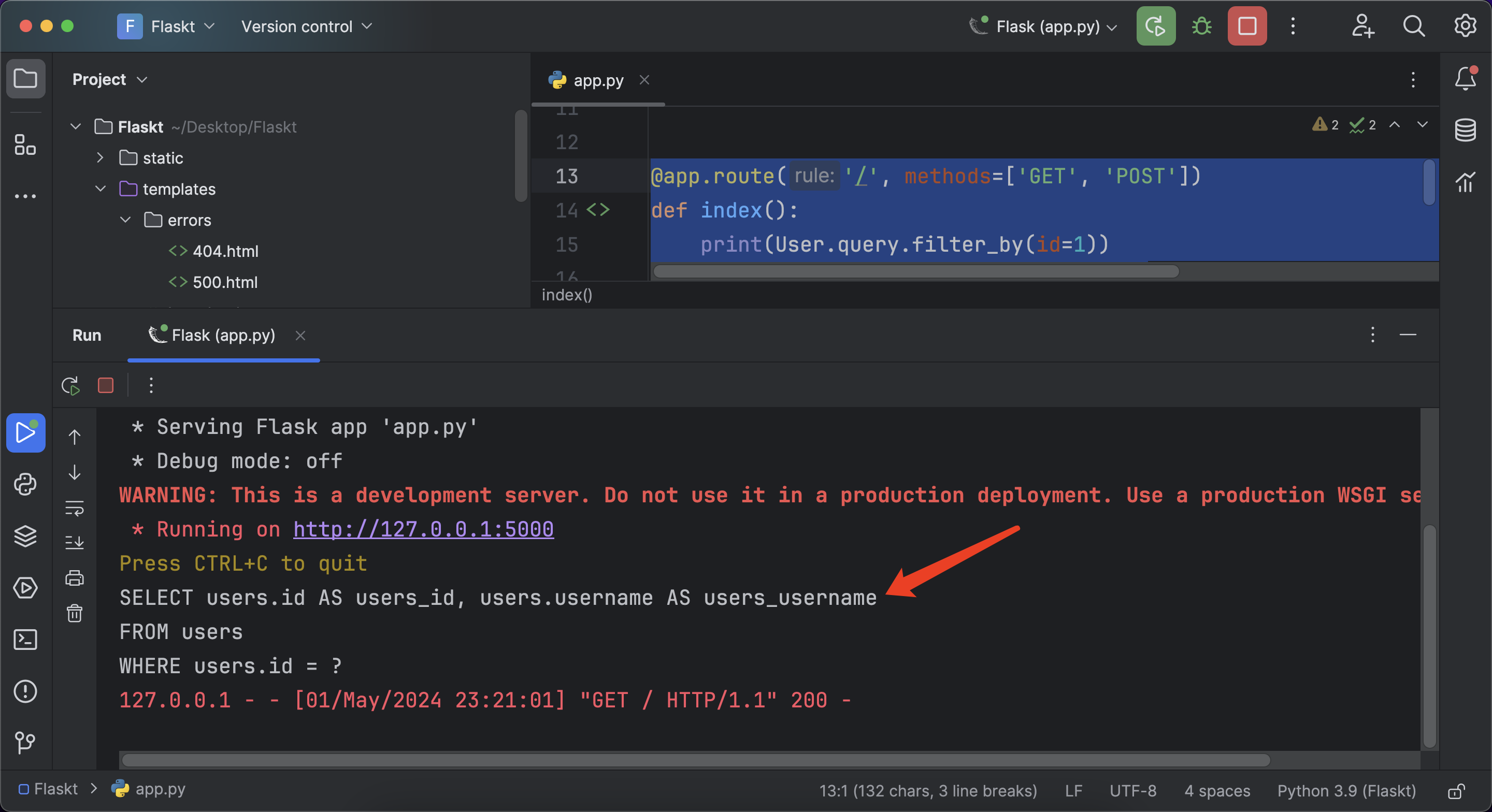
在 query 对象上调用的常用过滤器。完整的列表如下:
filter():把过滤器添加到原查询上,返回一个新查询。可以使用各种条件来过滤结果集,比如相等、不等、大于、小于、包含等等。filter_by():把等值过滤器添加到原查询上,返回一个新查询。通常用于根据指定的属性值来过滤结果集。limit():使用指定的值限制原查询返回的结果数量,返回一个新查询。可以控制查询结果的数量,常用于分页查询。offset():偏移原查询返回的结果,返回一个新查询。通常与 limit() 结合使用,用于分页查询中指定偏移量。order_by():根据指定条件对原查询结果进行排序,返回一个新查询。可以按照一个或多个属性进行升序或降序排序。group_by():根据指定条件对原查询结果进行分组,返回一个新查询。通常与聚合函数一起使用,用于统计分组数据。
all() 之外,还有其他方法能触发查询执行,列表如下:
all():以列表形式返回查询的所有结果。返回一个包含查询结果的列表。first():返回查询的第一个结果,如果没有结果,则返回 None。first_or_404():返回查询的第一个结果,如果没有结果,则终止请求,返回 404 错误响应。get():返回指定主键对应的行,如果没有对应的行,则返回 None。常用于根据主键获取单个对象。get_or_404():返回指定主键对应的行,如果没有找到指定的主键,则终止请求,返回 404 错误响应。count():返回查询结果的数量。paginate():返回一个 Paginate 对象,它包含指定范围内的结果。通常用于分页查询,可以指定返回结果的页数和每页的数量。