学习 InfluxDB 的命令行操作至关重要,它不仅是与数据库直接交互的工具,也是理解 InfluxDB 核心概念的关键途径。通过命令行,用户可以高效地执行数据库管理、数据查询和插入等任务,深入掌握 InfluxQL 的语法及功能。这对于调试、快速验证想法以及日常运维来说不可或缺。此外,熟练使用命令行有助于提升对 InfluxDB 工作原理的理解,为更复杂的应用开发和系统优化打下坚实基础。
目录
数据库操作
数据库表操作
新建表
显示所有表
删除表
数据保存策略
查看保存策略
创建保存策略
修改保存策略
删除保存策略
数据查询操作
普通数据查询
聚合函数查询
分页查询
数据库操作
连接InfluxDB
进入InfluxDB的命令行终端,再连接InfluxDB
# 进入InfluxDB的命令行终端
docker exec -it influxdb /bin/bash# 连接InfluxDB
influx
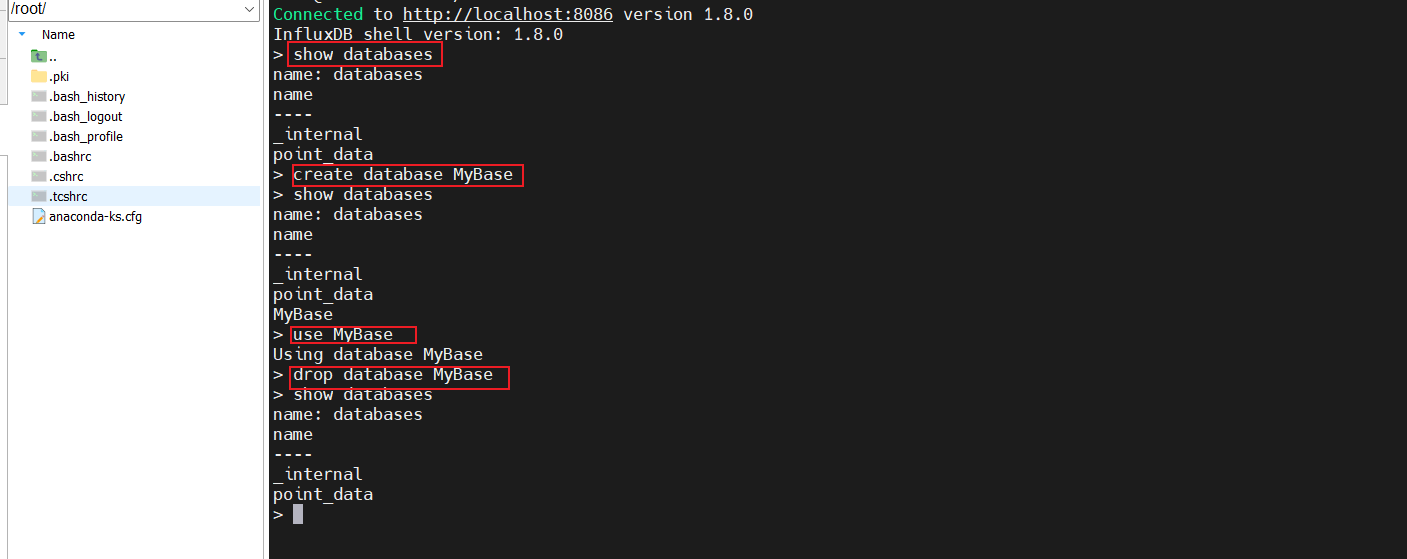
对于数据库的操作:
# 显示数据库
show databases# 创建数据库
create database MyBase# 删除数据库
drop database MyBase# 使用数据库
use MyBase操作效果如下:
数据库表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是MEASUREMENTS,MEASUREMENTS的功能与传统数据库中的表一致,因此我们也可以将MEASUREMENTS称为InfluxDB中的表。
# 显示所有的 measurement
show measurements新建表
InfluxDB中没有显式的新建表的语句,只能通过insert数据的方式来建立新表。语法如下:
insert measurement+","+tag1=value1,tag2=value2 + 空格 + field1=value1,field2=values2-- 例如:对measurement为tb_user的插入数据;有一个tag索引名为region,值为北京;有三个field分别是age,high,weight 对应的值分别为25、175、130
insert tb_user,region=北京 name="萧炎",age=25,high=175,weight=130注意:
measurement与 tag 之间使用逗号分隔
如果有多个tag,那么tag之间使用逗号分隔
tag 与 field 之间使用空格分隔
tag的值都是string类型,value不需要引号包裹
field如果是string类型的值,需要使用引号包裹
显示所有表
# 显示所有的 measurement
show measurements删除表
-- 删除语法
drop measurement 表名-- 例如:删除名为 tb_user 的measurement
drop measurement tb_user数据库表操作效果如下:

数据保存策略
InfluxDB是一般不建议直接删除数据记录的;其提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
查看保存策略
show retention policies on 数据库名称-- 例如:查看 MyBase 数据库的保存策略
show retention policies on MyBase
-
name:这是保留策略的名称。每个数据库可以有多个保留策略,
autogen是默认的保留策略名称,如果你没有为特定的数据点指定保留策略,它将自动使用autogen。用户也可以自定义其他名称的保留策略。 -
duration:表示数据保留的时间长度。这个值决定了数据在数据库中最多能保存多久。时间单位通常是小时(h)、分钟(m)、秒(s),如
72h表示数据将被保留72小时。如果设置为0s,则表示数据保留期无限制。 -
shardGroupDuration:分片组的持续时间。InfluxDB使用分片组来组织和存储数据,每个分片组覆盖一个特定的时间范围,这个值定义了每个分片组的时间跨度。查询效率和资源管理在很大程度上取决于这个参数的设定,因为它影响着数据如何被索引和分布(不影响数据的删除与否)。时间单位同样使用小时、分钟、秒。168h 表示 168小时也就是一周
-
replicaN:副本数量。这表示数据在集群中的复制份数。例如,如果设置为
1,则每份数据只有一份副本(数据只存在一份,没有其它);如果是2,则每份数据会有两个副本,以此类推。增加副本数量可以提高数据的持久性和可用性,但也会增加存储需求。 -
default:标记此保留策略是否为数据库的默认策略。如果此列为
true,则表示当写入数据时未明确指定保留策略,则会使用这个作为默认策略。如果为false,则表明这是一个非默认策略,需要在写入数据时显式指定才会应用。
创建保存策略
-- 语法
create retention policy 策略名 on 数据库名 duration 保留时长 replication 副本个数 [default]-- 示例:创建MyBase数据库的默认保存策略名字为 my_retention ,保留时长为24小时,副本数1个
create retention policy my_retention on MyBase duration 24h replication 1 default-- 示例:同样的,但是保存时长设置为3天,但是不设置为默认的保存策略的话就不加default
create retention policy my_retention2 on MyBase duration 3d replication 1
修改保存策略
-- 语法
alter retention policy 策略名 on 数据库名 duration 时长 default(可选)-- 例如:修改MyBase数据库中的my_retention策略,保留时长为2天,并设置为默认
alter retention policy my_retention on MyBase duration 2d default

删除保存策略
drop retention policy 策略名 on 数据库名-- 例如:删除MyBase数据库中策略名为 my_retention 的策略
drop retention policy my_retention on MyBase--- 删除保存策略如果是默认的;则不会自动的指定一个策略为默认;不过可以修改
alter retention policy autogen on MyBase default
数据查询操作
普通数据查询
InfluxDB基本查询操作和MySQL的基本查询是类似,综合使用如下所示:
#----综合使用
书写顺序
select distinct * from '表名' where '限制条件' group by '分组依据' having '过滤条件' order by limit '展示条数'
执行顺序
from -- 查询(来源)
where -- 限制条件 使用单引号,否则无数据返回或报错
group by -- 分组 只能对tags和time进行分组
having -- 过滤条件--》对分组内的数据
select -- 查询的结果
distinct -- 去重
order by -- 排序 只能对time进行排序
limit -- 展示条数数据查询演示效果如下:

聚合函数查询
其实和MYSQL差不多,使用一些函数进行查询,修改查询范围与结果。
count()函数:返回一个(field)字段中的非空值的数量。
mean() 函数:返回一个字段(field)中的值的算术平均值(平均值)。字段类型必须是长整型或float64。
median()函数:从单个字段(field)中的排序值返回中间值(中位数)。用于计算一组数值的中位数。中位数是将一组数值按大小顺序排列后处于中间位置的数。如果数值集合中有奇数个数,中位数就是正中间的那个数;如果有偶数个数,则中位数是中间两个数的平均值。
spread()函数:返回字段的最小值和最大值之间的差值。数据的类型必须是长整型或float64。
sum()函数:返回一个字段中的所有值的和。字段的类型必须是长整型或float64。

分页查询
在InfluxDB中,要实现分页效果,通常你会使用 LIMIT 和 OFFSET 这两个关键字结合使用。LIMIT 用于限制返回的结果数量,而 OFFSET 用于指定从结果集中的哪一个位置开始返回结果。这种方式类似于在其他数据库系统中使用 LIMIT m, n 来实现分页,其中 m 是偏移量,n 是每页的数量。
-- 语法
SELECT * FROM measurement_name WHERE condition GROUP BY ... LIMIT n OFFSET m
measurement_name:你想要查询的measurement名称。
condition(可选):用于过滤数据的条件表达式。
GROUP BY ...(可选):根据需要对结果进行分组。
LIMIT n:每页显示的记录数。
OFFSET m:从结果集中的第m条记录开始返回,用于实现分页。











![记录vite引入sass预编译报错error during build: [vite:css] [sass] Undefined variable.问题](https://i-blog.csdnimg.cn/direct/733518a0eb514899be645a5b3a9f2738.png)







