用到的模块
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.metrics import mean_squared_error
from keras.callbacks import ReduceLROnPlateau
from sklearn.preprocessing import MinMaxScaler
载入数据
dataframe = read_csv('china.csv',encoding='utf-8' ,usecols=[6],skiprows=5)
dataset = dataframe.values
plt.plot(dataset)#查看趋势
plt.show()

m = numpy.argmax(dataset)#找到异常值位置
dataset[m] = 0.5*(dataset[m-1]+dataset[m+1])#平均插值
dataset_or = dataset
为后续lstm的输入创建一个数据处理函数
def create_dataset(dataset, look_back=1):#look_back为滑窗
dataX, dataY = [], []
for i in range(len(dataset)-look_back):
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
设置随机种子,标准化数据
numpy.random.seed(7)
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
train = dataset
设置时间滑窗,创建训练集
look_back = 7
trainX, trainY = create_dataset(train, look_back)
对训练集x做reshape
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
搭建lstm网络
model = Sequential()
model.add(LSTM(25, input_shape=(1, look_back)))#输出节点为25,输入的每个样本长度为look_back
model.add(Dense(1))#添加一个全连接层,输出维度为1
model.compile(loss='mean_squared_error', optimizer='adam')#使用均方差做损失函数。优化器用adam
reduce_lr = ReduceLROnPlateau(monitor='val_loss', patience=10, mode='max')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2, callbacks=[reduce_lr])#训练模型,100epoch,批次为1,每一个epoch显示一次日志,学习率动态减小
预测
trainPredict = model.predict(trainX)#预测训练集
预测后7天
testx = [0.]*(7+look_back)
testx[0:look_back] = train[-look_back:]
testx = numpy.array(testx)
testPredict = [0]*7
for i in range(7):
testxx = testx[-look_back:]
testxx = numpy.reshape(testxx, (1, 1, look_back))
testy = model.predict(testxx)
testx[look_back+i] = testy
testPredict[i] = testy
testPredict = numpy.array(testPredict)
testPredict = numpy.reshape(testPredict,(7,1))
反标准化
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
输出训练RMSE
trainScore = math.sqrt(mean_squared_error(trainY[0,:], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
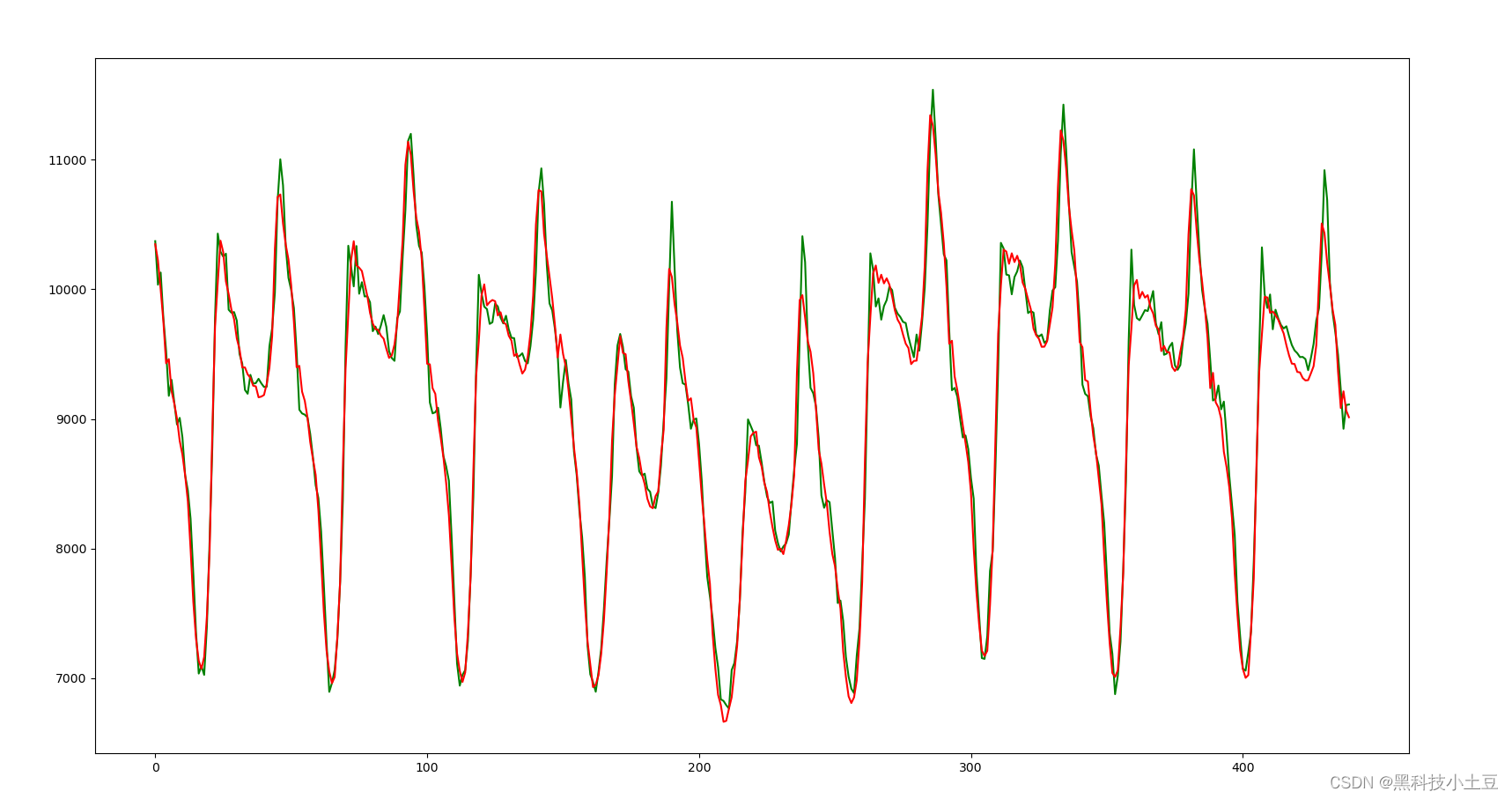
画图查看模型预测结果
trainPredictPlot = numpy.reshape(numpy.array([None]*(len(dataset)+7)),((len(dataset)+7),1))
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
testPredictPlot = numpy.reshape(numpy.array([None]*(len(dataset)+7)),((len(dataset)+7),1))
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(dataset):(len(dataset)+7), :] = testPredict
plt.plot(dataset_or,label='true')
plt.plot(trainPredictPlot,label='trainpredict')
plt.plot(testPredictPlot,label='testpredict')
plt.legend()
plt.show()

其实总体来说效果一般,而且这么少的数据其实不适合用lstm,我是看着钟南山院士在论文中用了lstm来做预测我才用的,不过钟院士用了sas的数据做了预训练。