文章链接:https://arxiv.org/pdf/2409.18938
亮点直击
- 追踪并总结从图像理解到长视频理解的MM-LLMs的进展;
- 回顾了各种视觉理解任务之间的差异,并强调了长视频理解中的挑战,包括更细粒度的时空细节、动态事件和长期依赖性;
- 详细总结了MM-LLMs在理解长视频方面的模型设计和训练方法的进展;
- 比较了现有MM-LLMs在不同长度视频理解基准上的表现,并讨论了MM-LLMs在长视频理解中的潜在未来方向。
将大语言模型(LLMs)与视觉编码器的集成最近在视觉理解任务中显示出良好的性能,利用它们理解和生成类人文本的固有能力进行视觉推理。考虑到视觉数据的多样性,多模态大语言模型(MM-LLMs)在图像、短视频和长视频理解的模型设计和训练上存在差异。本论文集中讨论长视频理解与静态图像和短视频理解之间的显著差异和独特挑战。与静态图像不同,短视频包含具有空间和事件内时间信息的连续帧,而长视频则由多个事件组成,涉及事件之间和长期的时间信息。在本次调研中,旨在追踪并总结从图像理解到长视频理解的MM-LLMs的进展。回顾了各种视觉理解任务之间的差异,并强调了长视频理解中的挑战,包括更细粒度的时空细节、动态事件和长期依赖性。然后,详细总结了MM-LLMs在理解长视频方面的模型设计和训练方法的进展。最后,比较了现有MM-LLMs在不同长度视频理解基准上的表现,并讨论了MM-LLMs在长视频理解中的潜在未来方向。
引言
大语言模型(LLMs)通过扩大模型规模和训练数据,展现了在理解和生成类人文本方面的卓越多功能性和能力。为了将这些能力扩展到视觉理解任务,提出了多种方法将LLMs与特定视觉模态编码器集成,从而赋予LLMs视觉感知能力。单张图像或多帧图像被编码为视觉tokens,并与文本tokens结合,以帮助多模态大语言模型(MM-LLMs)实现视觉理解。针对长视频理解,MM-LLMs被设计为处理更多的视觉帧和多样的事件,使其能够应用于广泛的现实场景,例如自动分析体育视频、电影、监控录像和在具身AI中的自我中心视频的精彩片段。例如,一台机器人可以通过长时间的自我中心视频学习如何制作咖啡。它需要分析长视频中的关键事件,包括:1)每6盎司水测量1到2汤匙的咖啡粉;2)将水加入咖啡机的水箱;3)将咖啡粉放入滤网;4)启动咖啡机并等待冲泡。建模具有复杂时空细节和依赖关系的长格式视频仍然是一个挑战性问题。
长视频理解与其他视觉理解任务之间存在显著差异。与仅关注静态图像空间内容的静态图像理解相比,短视频理解还必须考虑连续帧变化中的事件内时间信息。此外,超过一分钟的长视频通常包含多个场景和视觉内容不同的事件, necessitating捕捉显著的事件间和长期变化以实现有效理解。有效平衡有限数量的视觉tokens中的空间和时间细节,对长视频大语言模型(LV-LLMs)构成了相当大的挑战。此外,不同于仅持续几秒并包含数十个视觉帧的短视频,长视频往往涵盖数千帧。因此,LV-LLMs必须能够记忆并持续学习跨越数分钟甚至数小时的视频中的长期关联。MM-LLMs在全面长视频理解方面的进展,特别是在模型设计和训练上,值得特别关注。
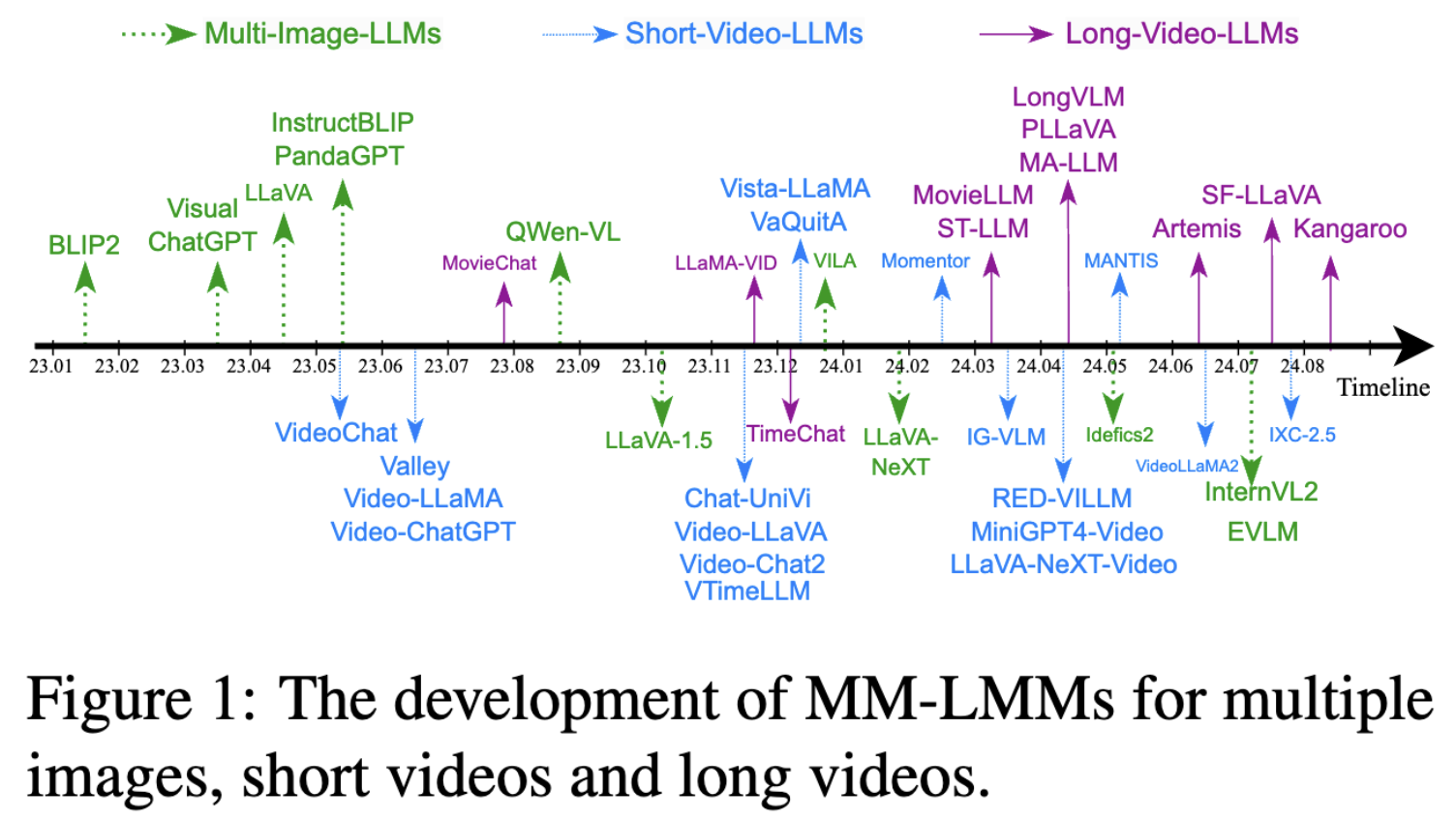
我们在图2中总结了MM-LLMs在图像、短视频和长视频理解方面的比较。除了上述讨论的长视频理解与其他视觉理解任务之间的继承和发展关系外,LV-LLMs还建立在多图像和短视频MM-LLMs的进展之上,具有相似的视觉编码器结构、LLM主干和跨模态连接器。为有效应对长视频理解任务中新引入的挑战,LV-LLMs设计了更高效的长视频级连接器,这些连接器不仅桥接跨模态表示,还将视觉tokens压缩到可管理的数量。此外,通常还会结合时间感知模块,以增强LV-LLMs中时间信息的捕获。在预训练和指令调优中,视频-文本对和视频-指令数据对MM-LLMs处理图像和视频具有重要意义,因其共享空间感知和推理能力。长视频训练数据集对于时间跨模态语义对齐和捕获长期相关性尤其有益,这对于LV-LLMs至关重要。本文调查将全面总结最近在模型设计和训练方法上的进展,追踪MM-LLMs从图像到长视频的演变。

近期关于视觉理解任务的调查通常采用单一视角,或从全局视角回顾MM-LLMs,或从局部视角关注图像或视频理解任务。虽然这些研究对研究主题进行了广泛的回顾,但未讨论不同任务和方法之间的开发和继承关系。此外,现有关于视频理解任务的评述往往更侧重于一般视频理解,而不是更具挑战性的长视频理解任务。超过一分钟的长视频被广泛应用于教育、娱乐、交通等领域,迫切需要强大的模型进行全面的自动理解。我们的工作是较早从发展视角总结和讨论长视频理解任务的研究之一。
长视频理解
由于长视频理解与图像或短视频理解之间的固有差异,包括存在多个事件、更多帧以及动态场景,长视频理解任务为视觉理解带来了额外的挑战。
视觉推理与理解
视觉推理要求模型理解和解释视觉信息,并将多模态感知与常识理解相结合。主要有三种类型的视觉推理任务:视觉问答(VQA)、视觉描述(VC)或说明(VD)、以及视觉对话(VDia)。VQA涉及基于输入的视觉数据和相关问题生成自然语言答案。VC和VD系统通常生成简洁的自然语言句子,总结视觉数据的主要内容,或者对相应视觉数据进行详细而全面的描述。VDia涉及多轮对话,由围绕视觉内容的一系列问答对组成。
图像理解。如图3(a)所示,图像理解任务涉及单张图像用于各种视觉推理任务,如图像标注和以图像为中心的问题回答。这些任务仅关注空间信息,包括对全球视觉上下文的粗略理解和对局部视觉细节的细致理解。
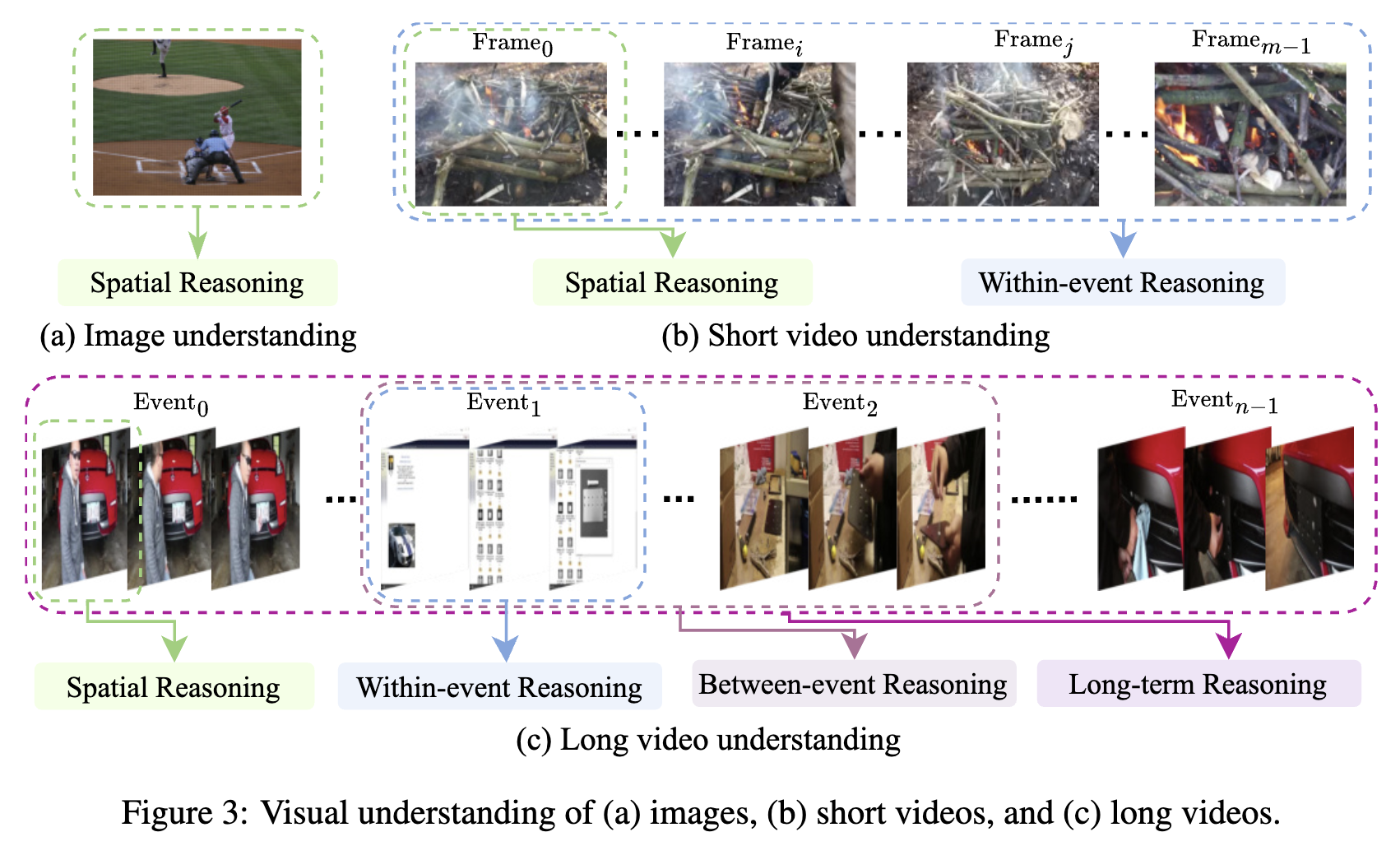
短视频理解。与仅涉及静态视觉数据的图像理解任务不同,短视频理解还结合了来自多个视觉帧的时间信息。除了空间推理,事件内的时间推理和跨帧的时空推理在短视频理解中发挥着至关重要的作用。
长视频理解。长视频通常持续数分钟甚至数小时,通常由多个事件组成,与短视频相比,包含更丰富的空间内容和时间变化。如图3©所总结,长视频理解不仅涉及空间和事件内的时间推理,还涉及事件间推理和来自不同视频事件的长期推理。
长视频理解的挑战
与图像和短视频相比,长格式视频为全面的视觉理解带来了新的挑战,具体如下:
丰富的细粒度时空细节。长视频涵盖了广泛的话题、场景和活动,包含了多样的细节,如物体、事件和属性。与静态图像和具有多个相似帧的短视频相比,这些细节更加丰富,使得长视频理解更加具有挑战性。例如,细粒度的空间问答可以在任何帧中引入,而时间问答可以在帧之间或帧内引入,以进行长视频推理任务。用于长视频理解的多模态大语言模型(MM-LLMs)必须从持续数分钟甚至数小时的视频帧中捕捉所有相关的细粒度时空细节,同时使用有限数量的视觉tokens。
动态事件与场景转换和内容变化。长视频通常包含各种动态事件,场景和内容存在显著差异。这些事件可能在语义上相关并且按照出现的顺序进行时间协调,或者由于情节转折而表现出显著的语义差异。涉及多事件的事件间推理,对于准确理解内容至关重要。对于MM-LLMs来说,区分语义差异并在不同事件之间保持语义一致性是长视频理解的关键。
长期关联与依赖关系。长视频通常包含跨越较长时间段的动作和事件。捕捉长期依赖关系并理解视频不同部分之间在长期内的关联是一个挑战。针对图像或短视频设计的视频大语言模型通常无法将当前事件与远离当前时刻的过去或未来事件进行上下文化,也难以进行长期决策。
模型架构的进展
在本节中,我们讨论了多模态大语言模型(MM-LLMs)从针对图像的模型到针对长视频的模型的进展,重点在于模型架构。正如图4所示,针对图像、短视频和长视频的MM-LLMs共享一个相似的结构,包括视觉编码器、LLM主干和中介连接器。与图像级连接器不同,视频级连接器对于整合跨帧视觉信息至关重要。在长视频大语言模型(LV-LLMs)中,连接器的设计更具挑战性,需要高效压缩大量视觉信息并融入时间知识以管理长期关联。
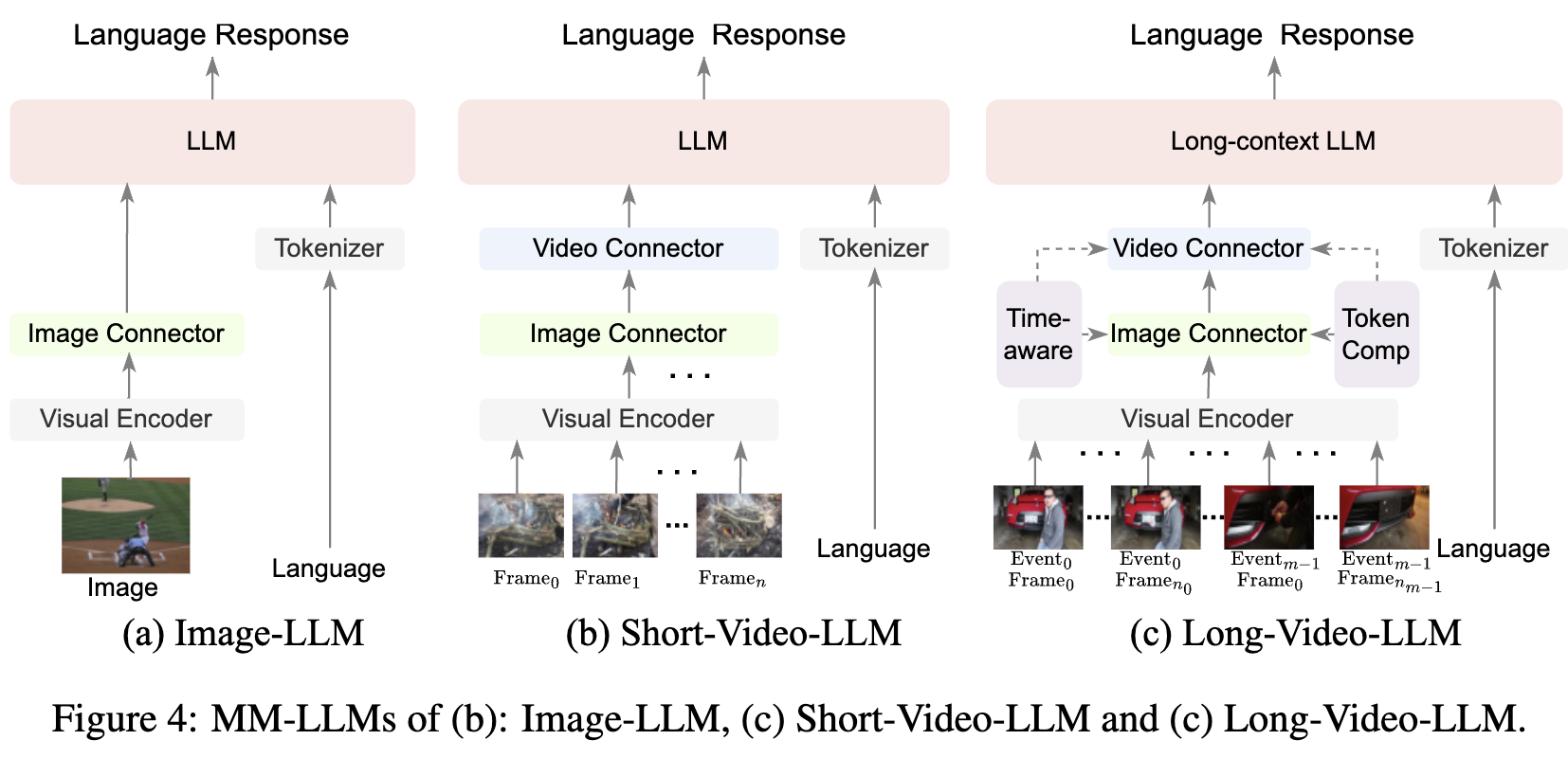
视觉编码器和LLM主干
MM-LLMs通常使用相似的视觉编码器来提取视觉信息。早期MM-LLM方法中的LLM主干通常是通用的,而现有的LV-LLMs倾向于在实现中使用长上下文LLMs。
视觉编码器。预训练的视觉编码器负责从原始视觉数据中捕获视觉知识。总结于表1中,像CLIP-ViT-L/14、EVA-CLIP-ViT-G/14、OpenCLIP-ViT-bigG/14和SigLIP-SO400M等图像编码器被广泛用于图像和视频目标LLMs。最近的研究表明,视觉表示(包括图像分辨率、视觉tokens的大小和预训练的视觉资源)在性能上比视觉编码器的大小更为重要。
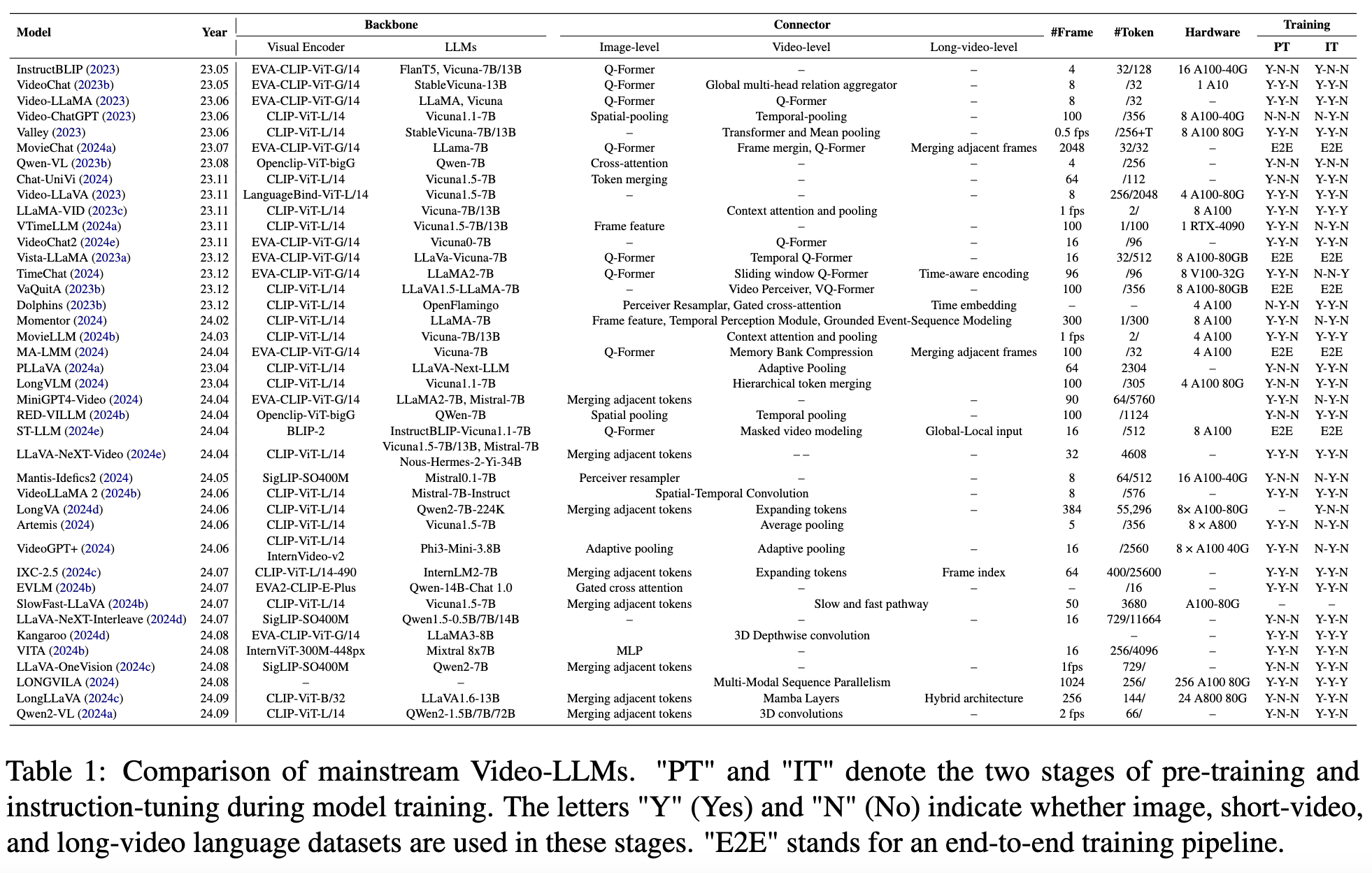
LLM主干。LLM是视觉理解系统的核心模块,继承了推理和决策能力的属性。与封闭源的LLMs(如GPT-3/和Gemini-1.5)相比,各种开源LLMs在实现视觉LLMs中更为常见。这些包括Flan-T5、LLaMA、Vicuna、QWen、Mistral、Openflamingo、Yi和InternLM。
LLM的强度通常与视觉LLMs中的多模态能力优越性相关。这意味着,对于相同规模的LLMs,语言能力更强的模型表现更好,而对于相同的LLMs,不同模型大小的情况,较大的模型往往产生更好的多模态性能。此外,长上下文LLMs将上下文长度扩展到数十万个tokens,支持更广泛的数据学习。最近的LV-LLMs有效地将LLM的长上下文理解能力转移到视觉模态中。
模态接口
视觉编码器与LLM之间的连接器充当模态接口,将视觉特征映射到语言特征空间。鉴于视觉数据源的多样性,这些连接器可以分为图像级、视频级和长视频级连接器。
图像级连接器
图像级连接器用于将图像特征映射到语言空间,以处理原始视觉tokens,广泛用于图像目标和视频目标的MM-LLMs。这些连接器可以分为三类:第一类直接使用单一线性层或多层感知器(MLP)将图像特征映射到语言嵌入空间。然而,这种保留所有视觉tokens的方法不适合涉及多个图像的视觉理解任务。为了解决保留所有视觉tokens的局限性,第二类采用各种基于池化的方法。这些方法包括空间池化、自适应池化、语义相似tokens合并和相邻tokens平均。第三类利用跨注意力或基于transformer的结构,如Q-Former和Perceiver Resampler,用于图像特征压缩。Q-Former是一种轻量级transformer结构,采用一组可学习的查询向量来提取和压缩视觉特征。许多视觉LLMs(Dai et al., 2023;Li et al., 2023b;Ma et al., 2023a;Liu et al., 2024e)遵循BLIP-2,选择基于Q-Former的连接器。其他视觉LLMs(Ma et al., 2023b;Jiang et al., 2024)则选择Perceiver Resampler,通过提取补丁特征来降低计算负担。
视频级连接器
视频级连接器用于提取顺序视觉数据并进一步压缩视觉特征。与图像目标MM-LLMs中的图像级连接器相比,视频级连接器对于视频目标MM-LLMs(包括LV-LLMs)至关重要。一些方法直接在输入LLMs之前连接图像tokens,使其对帧图像数量敏感。用于图像级连接器中的tokens压缩的类似结构可以适应视频级接口,如基于池化和基于transformer的结构。沿时间序列维度的池化是一种减少时间信息冗余的简单方法。基于transformer的方法,如Video Q-Former和Video Perceiver,在提取视频特征的同时减少数据复杂性。此外,基于3D卷积的方法可以从空间和时间维度提取和压缩视觉数据。
长视频级连接器
专为长视频LLMs设计的连接器考虑了两个特殊因素:高效的视觉信息压缩以处理长格式视觉数据,以及时间感知设计以保留时间信息。高效压缩视觉信息不仅需要减少输入视觉tokens到可接受数量,还需保留长视频中包含的完整时空细节。视频中包含两种数据冗余:帧内的空间数据冗余和帧间的时空数据冗余。一方面,空间数据冗余是在帧内区域级像素相同时产生的,这导致通过完整的视觉tokens表示冗余视觉帧时效率低下。为减少空间视频数据冗余,LLaVA-Next系列方法合并相邻帧的补丁tokens,而Chat-UniVi则合并相似帧的补丁tokens。另一方面,时空数据冗余包括跨帧像素冗余和运动冗余,其中这些冗余视频帧之间的语义信息相似。为减少时空视频冗余,MovieChat和MALMM在输入LLMs之前合并帧特征,以提高帧相似性。除了减少冗余信息外,保留更多视频时空细节对于准确的长视频推理至关重要。为了平衡全局和局部视觉信息并支持更多帧输入,SlowFast-LLaVA采用慢通道以低帧率提取特征,同时保留更多视觉tokens,并以较高帧率和较大空间池化步幅的快通道关注运动线索。
时间相关视觉数据
此外,时间相关的视觉数据高效管理长格式视频中固有的时间和空间信息。时间感知设计可以增强视频相关LLM的时间捕获能力,这对于长视频理解尤其有利。VTimeLLM和InternLM-XComposer-2.5(IXC-2.5)使用帧索引来增强时间关系。两者的区别在于方法:VTimeLLM通过训练包含帧索引的解码文本来学习时间信息,而IXC-2.5则将帧索引与帧图像上下文一起编码。TimeChat和Momentor将时间信息直接注入帧特征中,以实现细粒度的时间信息捕获。具体来说,TimeChat设计了一种时间感知帧编码器,以提取与帧级别相应时间戳描述的视觉特征,而Momentor则利用时间感知模块进行连续的时间编码和解码,将时间信息注入帧特征中。
模型训练的进展
用于视觉理解的多模态LLMs由两个主要阶段组成:预训练(PT)用于视觉与语言特征对齐,指令微调(IT)用于响应指令。
预训练
MM-LLMs的视觉语言预训练旨在使用文本配对数据将视觉特征与语言空间对齐。这包括对图像、短视频和长视频文本数据集的预训练。最初为专注于图像的视觉LLMs引入的图像文本预训练,也广泛应用于与视频相关的理解任务。粗粒度的图像文本对数据集,如COCO Captions和CC-3M,用于全球视觉语言对齐。细粒度的图像文本数据集,如ShareGPT4V-PT,则用于局部空间语义对齐。考虑到短视频语义内容的变化有限,短视频文本配对数据集,如Webvid-2M,也可以类似地用于短视频文本预训练。类似地,长视频文本预训练对于捕获长视频的时间语义对齐非常重要。由于图像文本和短视频文本对中缺乏长期跨模态关联,因此需要长视频文本预训练数据集,其中包含长视频及其对应的文本描述。此外,如图5(a)所示,长视频中的场景和事件在帧之间变化显著,因此需要事件级视觉语言对齐来进行长视频文本预训练,这与图像文本和短视频文本预训练显著不同。

指令微调
使用视觉语言源进行的指令微调使LLMs能够遵循指令并生成类人文本。多模态视觉语言指令跟随数据,包括图像文本和视频文本对,用于将多模态LLMs与人类意图对齐,从而增强其完成现实任务的能力。
与预训练阶段类似,图像文本指令微调也被应用于各种视觉理解任务,包括图像、短视频和长视频理解任务。基本的基于图像的指令跟随数据集,如ShareGPT4V-Instruct和LLaVA-Instruct,为基本的空间推理和聊天能力提供高质量的指令微调数据。对于视频相关的LLM,短视频文本指令微调是必要的,以使多模态LLM能够理解时间序列,这在Video-ChatGPT和VideoChat等模型中得以体现。短视频LLM需要同时进行空间和事件内推理的指令,以理解短视频的空间和小规模时间内容。然而,短视频中有限的内容和语义变化不足以支持长视频理解任务,因为长视频的帧数更多且变化显著。长视频文本指令微调的引入旨在更好地捕获和理解长视频。除了空间和事件内推理指令外,事件间和长期推理指令对于全面理解长视频也是必要的,如图5(b)所示。在引入的长视频指令格式数据集中,Long-VideoQA和Video-ChatGPT不具备时间意识,仅包含长视频及其对应数据。VTimeLLM、TimeIT和Moment-10M具备时间意识,加入额外的时间信息以增强时间相关性。
评估、性能与分析
在本节中,我们将对不同长度视频的流行评估数据集进行性能比较,并提供分析。比较从两个角度进行:首先,我们评估视频理解方法在视频长度从秒到分钟的任务上的表现;其次,我们特别比较超长视频数据集(视频长度从分钟到小时)的性能。
视频理解:秒到分钟
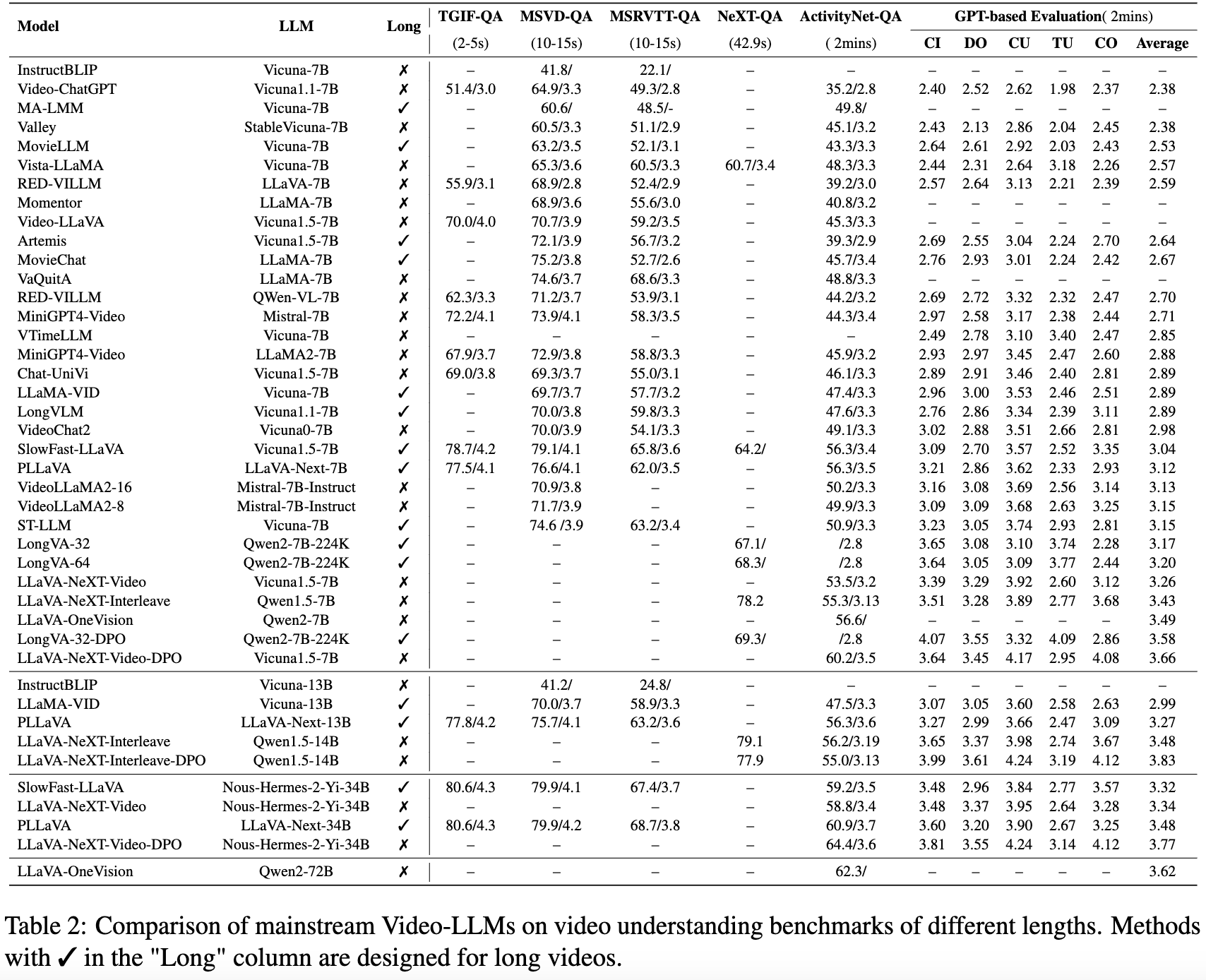
如表2所示,我们总结了各种视觉LLM在开放式视频问答基准测试上的一般视频理解性能,包括TGIF-QA、MSVD-QA、MSRVTT-QA、NEXT-QA和ActivityNet-QA。此外,我们还考虑了VideoChatGPT引入的视频生成性能基准,该基准评估视频文本生成的五个方面:信息正确性(CI)、细节导向(DO)、上下文理解(CU)、时间理解(TU)和一致性(CO)。
视频基准测试中长度少于1分钟的,如TGIF-QA、MSVD-QA、MSRVTT-QA和NEXT-QA,通常用于短视频理解。相比之下,长度超过一分钟的基准测试,如ActivityNet-QA和基于ActivityNet-200的生成性能基准,则用于长视频理解。
通过比较表2中的性能,我们可以得出以下结论:长视频理解具有挑战性,主要发现如下:(1)包含更多帧的视频推理引入了更复杂的视觉信息,挑战性更大。旨在支持长视频的方法,如LongVA(Zhang et al., 2024d),在同一视频数据集上与更少帧相比表现更好。然而,对于没有专门设计用于长视频的方法,如VideoLLaMA2,当输入更多帧时,性能则下降。(2)在秒级视频理解上表现良好的短视频理解方法,往往在分钟级中等长视频理解上表现不佳,例如RED-VILLM和MiniGPT4-Video。长视频理解方法在短视频和中等长视频基准测试上通常表现一致良好,例如ST-LLM、SlowFast-LLaVA、PLLaVA和MovieChat。这种改善可能源于专门设计的长视频理解方法更好地捕获了时空信息。
视频理解:分钟到小时
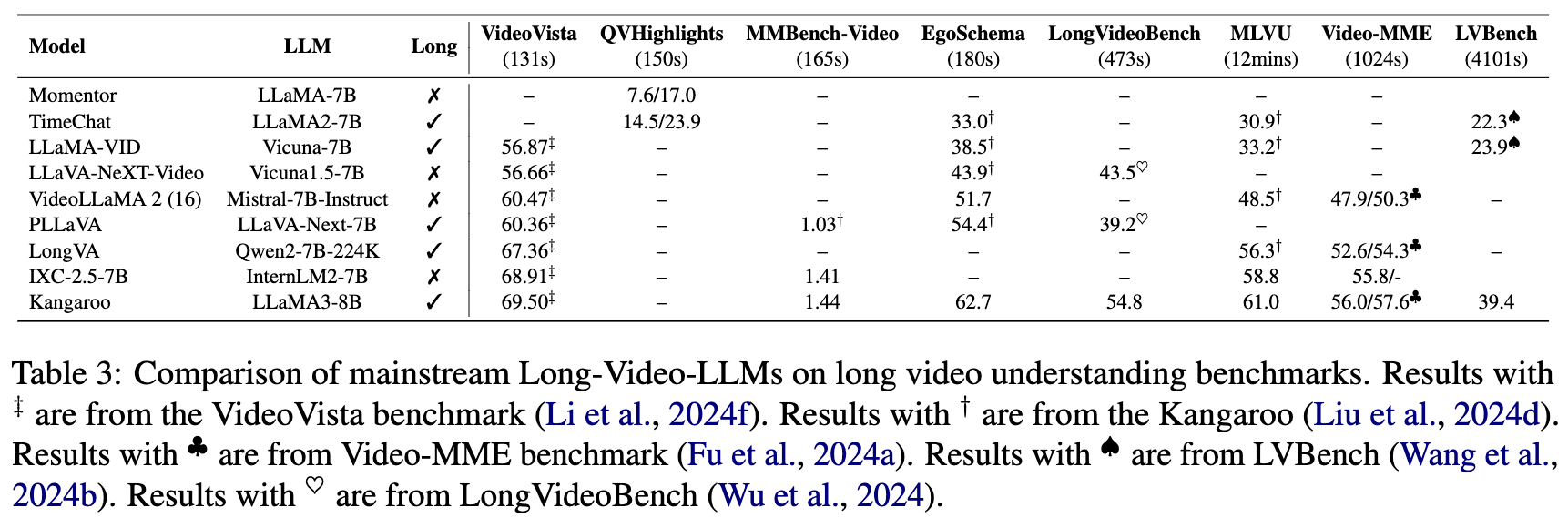
为了解决长视频的独特特征,近年来引入了多个长视频基准测试,视频长度从几百秒到几千秒不等。EgoSchema和QVHighlights是为多选问答和高亮检测而设计的长视频理解数据集,要求访问所有帧。VideoVista、MMBench-Video和MLVU涵盖各种主题,并旨在进行细粒度能力评估。LongVideoBench引入了指称推理问题,以解决长视频中的单帧偏差问题。Video-MME和LVBench包含大量小时级视频。Video-MME进一步将视频分类为短、中、长三类,而LVBench旨在挑战模型展示长期记忆和扩展理解能力。
如表3所示,我们进一步比较和分析长视频理解方法的性能,特别总结它们在长度从几百秒到几千秒的长视频基准测试上的表现。与第5.1节的发现不同,长视频理解方法通常优于短视频理解方法。这表明,专门设计的强大视频级连接器对于长视频理解至关重要。此外,视频长度较长的基准测试上的性能通常较差。例如,使用相同评估指标的VideoVista和MLVU、Video-MME和LVBench之间的方法性能随着视频长度的增加而下降。这表明,长视频理解仍然是一个具有挑战性的研究主题。
未来方向
如上所述,现有的长视频理解方法的效果不如图像或短视频理解方法。为了满足一个日益依赖AI的社会对越来越多和更长的多模态数据的需求,开发更强大的视觉大语言模型(LLM)以实现长视频理解至关重要。以下考虑事项应予以重视。
更多长视频训练资源
现有的两阶段训练流程——跨模态对齐预训练和视觉语言格式指令调优——广泛用于训练多模态LLM。然而,与常用的图像-语言和短视频-语言对比,缺乏细粒度的长视频-语言训练对。依赖图像-语言和短视频-语言资源的方法无法在预训练阶段捕捉长期关联。此外,新引入的长视频指令数据的视频长度仅限于分钟级,显著限制了长视频理解的有效推理应用场景。因此,需要创建具有更长(小时级)视频和高质量注释的长视频-语言配对预训练数据集和长视频指令数据集。
更具挑战性的长视频理解基准测试
在前面的部分中总结了各种视频理解基准测试,其中大多数是最近引入的。然而,这些基准主要集中在长视频理解的一个或多个方面,例如,LongVideoBench用于长上下文交错视频理解,QVHighlights用于基于语言的视频高亮理解,以及VideoVista和MLVU用于细粒度视频理解。需要全面的长视频基准测试,以覆盖具有时间和语言的帧级和片段级推理,但目前尚未探索以全面评估通用的长视频理解方法。此外,现有基准通常处于分钟级,无法充分测试方法的长期能力。长视频理解方法在处理大量连续视觉信息(例如小时级视频)时,常常会遭遇灾难性遗忘和时空细节的损失。最后,大多数现有的长视频理解基准仅关注视觉模态。结合额外的音频和语言等多模态数据,无疑会使长视频理解任务受益。
强大而高效的框架
视频的视觉大语言模型(LLM)需要支持更多的视觉帧,并在固定数量的视觉tokens下保留更多的视觉细节。在实现长视频LLM时,有四个主要考虑因素:
-
- 选择长上下文LLM作为基础模型。以往的方法受到LLM上下文容量的限制,必须特别微调LLM以支持更多的tokens。最近的长上下文LLM,如QWen2、LLaMA-3.1和DeepSeek-V2(DeepSeek-AI, 2024),具有128K的上下文窗口长度,可用于长视频LLM的设计。
-
- 更高效地压缩视觉tokens,减少信息损失。一些现有方法面临压缩不足的问题,例如Chat-UniVi采用多尺度tokens合并,而LongVA仅合并相邻tokens。其他方法则压缩过多视觉信息,例如LLaMA-VID使用上下文和内容tokens,MA-LMM合并相似帧tokens,导致帧细节显著损失。针对长视频的新框架必须高效压缩视觉tokens,以支持更多时间帧,并在全面的长视频理解任务中保留更多时空细节。
-
- 结合额外的时间感知设计(Ren et al., 2024; Qian et al., 2024),通过整合时间信息增强视频推理,从而提高长视频理解性能中的时间信息提取能力。
-
- 利用能够支持内存密集型长上下文训练的基础设施(Xue et al., 2024),提供在配备大量GPU设备时能够输入更多视觉数据的能力。
更多应用场景
使用大型模型的长视频理解面临多个关键挑战,以满足更多长视频应用的需求。上下文理解至关重要,因为长视频需要模型在较长时间内保持时间一致性和上下文意识。实时处理对监控、实时事件分析和具身AI等应用至关重要,需要开发能够实时处理视频流的低延迟模型。多模态整合是另一个前沿领域,因为长视频通常包含音频、文本和视觉信息。未来的模型应更好地整合这些模态,以增强理解并提供对视频内容的更全面分析。
结论
本文总结了视觉LLM从图像到长视频的进展。基于对图像理解、短视频理解和长视频理解任务差异的分析,我们识别了长视频学习的关键挑战。这些挑战包括捕捉动态序列事件中的更细粒度时空细节和长期依赖关系,同时压缩视觉信息,涉及场景转换和内容变化。接着,我们介绍了从图像LLM到长视频LLM的模型架构和模型训练的进展,旨在改善长视频理解和推理。随后,回顾了多种不同长度的视频基准测试,并比较了各种方法在视频理解上的表现。这一比较为长视频理解的未来研究方向提供了洞见。本论文首次聚焦于长视频LLM的发展与改进,以实现更好的长视频理解。我们希望我们的工作能够推动长视频理解和推理的进步。
限制
本文回顾了关于综合长视频理解的文献,包括方法、训练数据集和基准测试。由于篇幅限制,省略了实时处理和多模态任务等详细应用场景。我们将维护一个开源库,并添加这些内容以补充我们的调查。性能比较基于先前论文和官方基准的最终结果,这些结果在训练资源、策略和模型架构上存在差异,使得分析具体模型和训练差异变得困难。计划在公共基准上进行详细的消融研究,以便对模型设计、训练资源和方法进行更直接的分析。
参考文献
[1]From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding