本文由readlecture.cn转录总结。ReadLecture专注于音、视频转录与总结,2小时视频,5分钟阅读,加速内容学习与传播。
大纲
-
神经网络概述
-
神经网络的概念
-
神经网络的应用方式
-
-
序列建模与神经网络架构
-
循环神经网络(RNN)在长序列建模中的应用
-
卷积神经网络(CNN)在N-gram处理和高效计算中的优势
-
Transformer的出现及其在机器翻译中的性能
-
-
大模型及其问题解决
-
大模型的出现及其应用
-
大模型产品如对话聊天
-
大模型在计算机视觉领域的发展
-
-
语言任务与模型训练
-
语言任务类型(情感分析、垃圾邮件分类、机器翻译等)
-
实体抽取任务
-
语言模型训练过程
-
-
有监督学习与监督数据问题
-
监督数据标注的成本和耗时
-
监督数据不足的问题
-
模型大小限制
-
模型泛化性不足
-
-
迁移学习
-
迁移学习的概念
-
迁移学习在模型泛化性提升中的应用
-
迁移学习与域训练技术
-
-
自监督学习
-
自监督学习的概念
-
对比学习在自监督学习中的应用
-
-
语言理解与Word2Vec
-
语言理解的本质
-
Word2Vec模型及其工作原理
-
词向量与语义关联关系
-
-
预训练大模型
-
预训练大模型的概念
-
预训练大模型的发展历程
-
大模型在知识迁移和模型参数增大中的作用
-
-
大模型的认知能力
-
大模型的世界知识和常识知识
-
大模型的逻辑推理能力
-
大模型的零样本和少样本学习能力
-
-
大模型的多领域应用
-
大模型在文本、图像、DNA等领域的应用
-
大模型的全面覆盖能力
-
-
总结与展望
-
深度学习与知识迁移的进步
-
大模型的通用能力
-
内容总结
一句话总结
本文深入探讨了神经网络、大模型及其在语言任务中的应用,分析了大模型的发展历程、认知能力和多领域应用。
观点与结论
-
神经网络在序列建模和语言任务中发挥着重要作用。
-
大模型的出现推动了自然语言处理的发展,提高了模型的效果。
-
迁移学习和自监督学习有助于提升模型的泛化能力。
-
大模型在多领域应用中展现出强大的能力。
自问自答
-
什么是神经网络?
-
神经网络是一种模拟人脑神经元结构的计算模型,用于处理和分析数据。
-
-
什么是大模型?
-
大模型是一种基于深度学习的模型,通过大量数据训练,能够处理复杂的任务。
-
-
什么是迁移学习?
-
迁移学习是一种将已学习到的知识应用于新任务的方法。
-
-
什么是自监督学习?
-
自监督学习是一种利用未标记数据训练模型的方法。
-
-
大模型在哪些领域有应用?
-
大模型在自然语言处理、计算机视觉、语音识别等领域有广泛应用。
-
关键词标签
-
神经网络
-
大模型
-
迁移学习
-
自监督学习
-
语言任务
-
预训练模型
适合阅读人群
-
深度学习爱好者
-
自然语言处理研究者
-
计算机视觉从业者
-
人工智能开发者
术语解释
-
神经网络:模拟人脑神经元结构的计算模型,用于处理和分析数据。
-
大模型:基于深度学习的模型,通过大量数据训练,能够处理复杂的任务。
-
迁移学习:将已学习到的知识应用于新任务的方法。
-
自监督学习:利用未标记数据训练模型的方法。
-
预训练模型:在大量数据上预训练的模型,可以用于解决特定任务。
-
泛化能力:模型对未知输入的判断能力。
视频来源
Lecture 3 神经网络与大模型基础 Part 2_哔哩哔哩_bilibili
讲座回顾

然后,我们主要介绍了神经网络的概念及其应用方式。

-
训练过程关注神经网络对序列的建模。
-
探讨了循环神经网络(RNN)在处理长序列的能力。
-
分析了卷积神经网络(CNN)在处理N-gram和高效计算方面的优势。
-
提出了Transformer模型,用于解决机器翻译问题,并指出其性能优于RNN。
我们的训练过程涉及如何利用神经网络对序列进行建模,以及探讨传统神经网络架构,如循环神经网络(RNN)在建模长序列方面的能力,以及卷积神经网络(CNN)在快速处理N-gram和进行高效计算方面的优势。此外,Transformer的出现是为了解决机器翻译问题,其性能优于RNN。

-
Transformer与RNN的区别:主要源于Attention机制的差异,这种差异决定了运算方式并带来优势。
-
大模型的出现及其解决的问题:大模型能够进行对话聊天,解决了一系列问题。
-
时间背景:大约一两年前,实际情况与现在有所不同。
同时,Transformer与RNN之间的区别主要源于Attention机制的差异,这种机制决定了其运算方式,并带来了相应的优势。接下来,我将讲解大模型的出现及其如何解决问题,包括现在大家所看到的大模型产品,如能进行对话聊天。在此之前,大约一两年前,实际情况是这样的。

-
AlphaGo问世引发热议:人们开始讨论AI何时能通过图灵测试。
-
时间预期变化:起初认为通过图灵测试需要很长时间,但现在似乎任何东西都能进行类似对话。
-
大模型技术贡献:大模型技术的出现是推动这一变化的主要原因。
-
神经网络与语言模拟:使用神经网络模拟语言是语言建模的关键。
-
语言任务发展:语言任务从最初相对有限,如情感分析、垃圾邮件分类和机器翻译,逐渐扩展。
当时在计算机视觉领域,随着AlphaGo的问世,人们热议AI何时能通过图灵测试。起初,许多人认为这可能需要相当长的时间。然而,如今似乎任何东西都能进行类似对话,尽管有些生硬。这主要得益于大模型技术的出现。我们之前讨论了如何使用神经网络来模拟语言。在语言建模完成后,首要任务是解决语言任务。最初的语言任务相对有限,常见的有情感分析、垃圾邮件分类和机器翻译等。

实体抽取,例如从一段简历中提取姓名、出生日期等信息。这类任务相对简单,通常不需要使用如RN等高级机器翻译方法。实际上,这类抽取任务可以通过编写简单的正则表达式来实现。

-
神经网络模型最初设计用于解决条件判断等任务。
-
与情感分析不同,神经网络模型不直接用于判断句子的情感倾向。
-
该模型有助于商品分析,如新软件的推出,通过分析用户留言和评价,快速识别正面评价。
条件判断等任务都可以从中提取,神经网络模型本质上最初也是为了解决这类问题。并非像情感分析、情感判断那样,输入一个句子,判断其情感倾向是正面还是负面。这有助于进行商品分析,例如推出新软件。通过分析用户留言和评价,可以更快地判断哪些是正面评价。
-
语言模型的产生源于特定需求。
-
早期语言模型训练过程简单。
-
训练过程包含输入数据和期望输出数据。
-
使用公式拟合数据,涉及x、y、x_i和y_i的关系。
-
训练数据是有监督数据,即带有人工标注标签的数据。
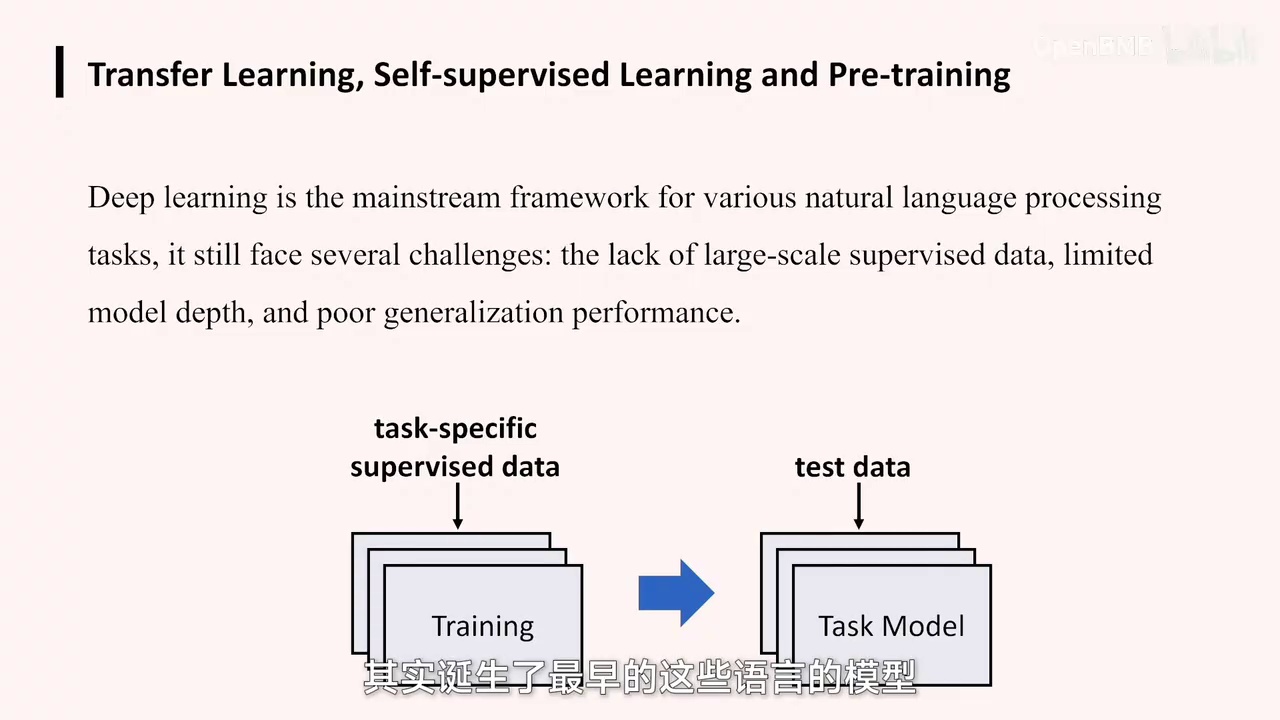
这样一些需求催生了最早的这些语言模型。最初,我们进行语言模型训练的过程相对简单。正如我之前所述,我们按照既定的方法进行训练。训练过程需要包含两个要素:实际的输入数据和期望的输出数据。然后,将这些数据套入我们最初的公式中,即x和y与x_i与y_i的关系。通过一系列训练方法,使模型不断拟合这些数据。我们称这种数据为有监督数据,即带有人工标注标签的数据。

这个如何理解呢?即YI,即需让模型学会对句子进行判断,如情感分类、好坏判断等。

-
任务学习方式:通过大量示例学习,人工标注好坏标签,属于有监督学习。
-
模型训练:使用如RN、CN等模型,通过梯度下降法进行训练。
-
模型应用:训练好的模型用于实际测试数据,通过特定方法输出结果。
-
方法特点:过程清晰明确,是早期任务处理的常见做法。
让他学会这个任务,需要提供大量示例,告诉他哪些句子是好的,哪些是坏的。这些好坏标签由人工标注,属于有监督学习。最初,人们将标注好的数据输入到如RN、CN等模型中进行训练。随后进行梯度下降,最终得到训练好的模型。此时,我们可以将实际测试数据输入模型,模型通过特定方法输出结果。这种方法是早期任务处理的一种常见做法,其过程清晰明确。

-
监督数据标注成本高,需要人工进行,导致成本上升。
-
早期CV研究中,数据标注工作由博士完成,耗时且辛苦。
-
缺乏足够的监督数据,尤其是对于简单任务,如分类任务。
明显存在几个较为棘手的问题,首先是监督数据。拥有监督数据需要人工标注,这导致成本大幅上升。例如,在早期进行计算机视觉(CV)研究时,研究者们通常需要攻读博士学位,在前几年进行数据标注,之后进行模型训练,最终发表学术论文。当时,许多数据集的标注工作都是由几位博士花费一年时间完成的,过程相当辛苦。
另一个大问题是缺乏足够的监督数据。这种标注工作非常耗时,尤其是对于简单任务而言,如分类任务。

这些更复杂的任务,例如翻译,对于人工输入文字的专业性要求更高,因此也更为繁重,这是该方法的一个显著问题。

-
模型大小限制其效果提升,数据量小增大小模型效果有限,规模过小则影响应用效果。
-
模型泛化性不足,对未知输入的判断能力有限,可能导致处理不同类型文本时表现不佳。
第二,模型的大小限制了其上限。当数据量较小时,增大模型规模能带来微小的效果提升,但收益有限。若模型规模过小,效果不佳,会导致翻译错误频发,影响实际应用。例如,在垃圾邮件分类中,若十个邮件中分错一个,就可能误删重要邮件。
第三,模型泛化性不足。泛化性指的是模型对未知输入的判断能力。例如,若输入均为传统文学,模型在处理其他类型文本时可能表现不佳。

我们拥有丰富的传统文学资源,包括国外的经典文学作品以及国内的诸多译本,这些资源可用于训练模型。

-
语料来源:翻译的是贴吧语料。
-
数据分布问题:训练数据和测试数据分布不同,即概率分布不同。
-
数据内容差异:训练数据体现为良好的文学和文艺表达,测试数据为贴吧特有的表达风格。
-
影响:导致测试数据在训练数据中出现的概率极低,降低模型泛化性。
-
泛化性概念:泛化性好的模型能适应不同的数据分布。
它翻译的是贴吧语料。这种语料通常表现较差,原因在于训练数据和测试数据分布不同。从数据分布的角度理解,即概率分布不同。训练数据更多体现为良好的文学和文艺表达,而测试数据则呈现为贴吧特有的表达风格。这种差异会导致测试数据在训练数据中出现的概率极低,从而降低模型的表现,即泛化性不佳。泛化性好的概念是指模型能够较好地适应不同的数据分布。

我教授了一种方法,你能够由此推导出三个类似的东西,这体现了良好的泛化能力。因此,后来出现了一些新的方法,即迁移学习。迁移学习的作用在于,通过传统方法,它并不十分……

将模型规模扩大,对方表示数据不足。第三点是模型的泛化性相对较差,如何解决呢?我们可以尝试先对模型进行训练。

-
目标:掌握通用能力并通过迁移学习应用于具体任务。
-
技术:域训练技术,Protraining技术。
-
过程:在大规模无标注数据上训练,获得通用能力。
-
局限性:通用能力可能不适用于所有领域,域训练中解决的问题可能与实际任务存在差异。
-
迁移学习:将A任务的能力迁移至B任务,提高B任务表现。
-
Fine Tuning:在下游任务中进行微调,形成最终模型,提高测试效果。
他旨在掌握一种通用的能力,并通过迁移学习将其应用于具体任务。这种方法允许将能力从更大任务迁移至更小任务,从而在较小任务上体现基础水平——这实际上是一种域训练技术。其主要工作是在大规模无标注数据上,利用Protraining技术,从而获得一种通用能力。然而,这种能力可能无法直接解决下一个任务的问题,因为它可能适用于其他领域。在域训练中解决的问题可能与实际任务存在差异。
因此,通过迁移方法,将原本只擅长A任务的能力迁移至B任务,相较于从头构建B任务的能力,由于已经掌握了A任务且能力较强,它在B任务上更容易达到更高水平。最终,在下游任务中进行Fine Tuning,形成最终模型,并在测试中达到更好的效果。
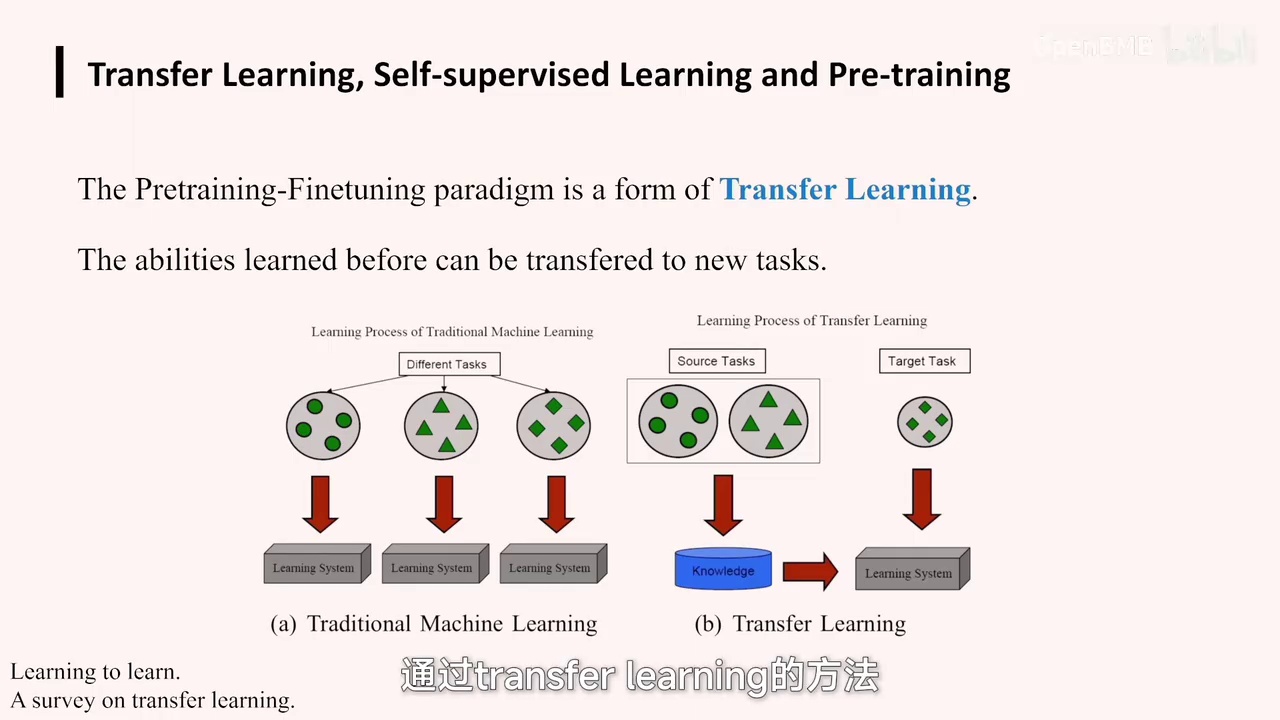
-
传统学习方法:针对不同任务独立学习,如圆圈任务学习圆圈模型,三角形任务学习三角形模型。
-
新方法视角:通过迁移学习,将旧任务知识应用于新任务,如情感分类能力可用于垃圾邮件分类。
-
迁移学习方法:通过预训练-微调范式,实现知识迁移,提高新任务的效果。
这是一个典型的传统学习方法示例。在传统方法中,针对不同任务,我们会在各自的任务上进行独立学习。例如,针对圆圈任务,我们学习圆圈模型;针对三角形任务,学习三角形模型;针对菱形任务,学习菱形模型。
然而,在新的方法视角下,我们有了另一种思路。即,如果个体已经掌握了圆圈和三角形的能力,并具备了一定的知识基础,我们可以通过某些方法,将个体在旧任务上获得的知识迁移到新任务上。
由于任务之间存在相关性和相似性,例如,如果能够进行情感分类,也许就能在一定程度上解决垃圾邮件分类问题。
通过这种方法,我们可以利用更多已有数据,在具体任务上通过迁移学习,带来更大的效果增益。
这一部分是通过迁移学习方法实现的,通过预训练-微调(pre-training by tuning)范式,我们可以实现迁移学习,将已学习到的任务知识转化为新任务。

-
韩旭是清华大学计算机系的助理研究员。
-
韩旭的研究方向与大型模型紧密相关。
-
韩旭将和国阳一起介绍大模型的背景知识。
-
未来还将分享更多关于大型模型的内容。
今天,我将与大家进行一次沟通与交流。我是韩旭,目前担任清华大学计算机系助理研究员。我的研究方向与大型模型密切相关,因此此次将和国阳一起为大家简要介绍大模型的背景知识,后续还将分享更多相关内容。

其实我之前也提到过,今天大家所学的许多内容都与神经网络相关,即如何构建一个网络模型,以及如何对其进行训练。传统方法通常是对每个特定任务进行单独的学习。
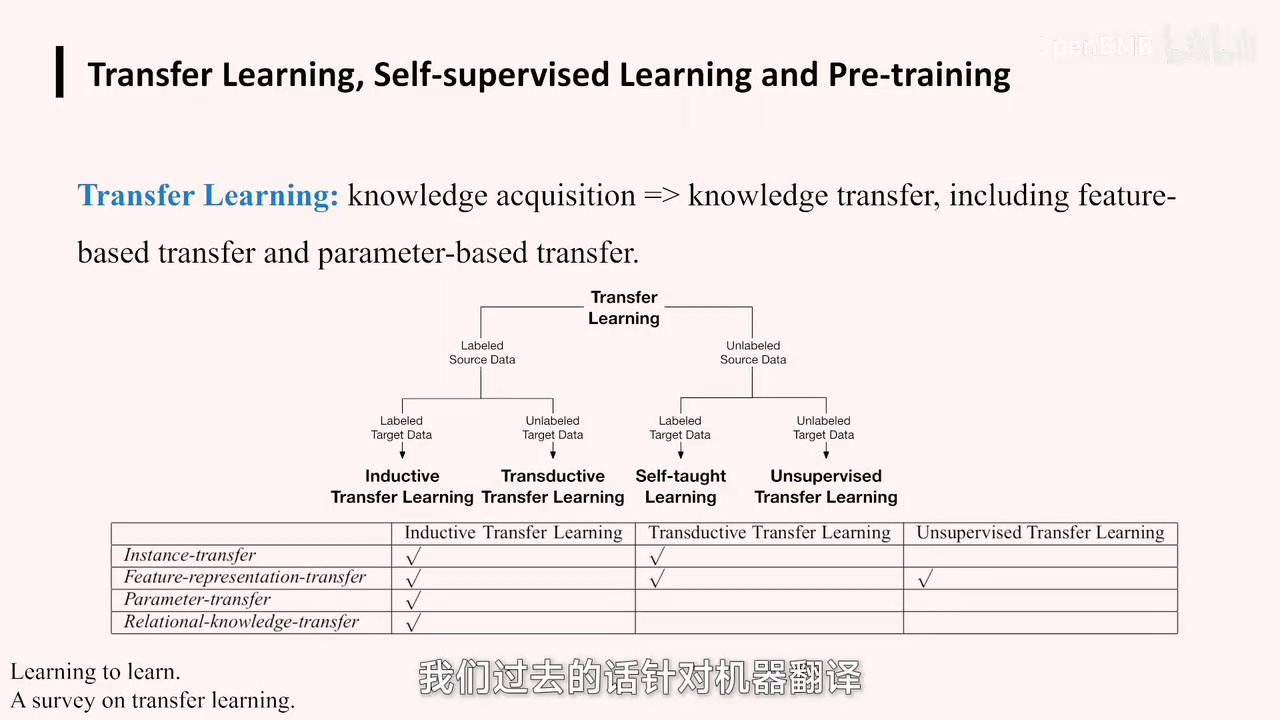
-
研究中针对机器翻译任务,通常使用专门的机器翻译模型。
-
早期模型如RN模型和Transformer是专门为机器翻译任务设计的。
在我们以往的研究中,针对机器翻译任务,通常会训练一个专门的机器翻译模型。例如,之前大家所看到的RN模型或Transformer等早期模型,它们都是针对机器翻译任务进行设计的。

-
模型训练区别:利用大量无监督或有监督数据,通过多种数据学习,具备众多潜在能力。
-
迁移学习比喻:类似于“读书百遍,其义自见”,通过积累知识,在后续任务中游刃有余。
-
迁移学习类型:包括基于特征和基于参数的迁移。
-
大模型迁移学习:基于参数的迁移,学习时模型结构和内部参数包含特定信息,应用于下游任务需微调参数。
然后,在训练模型方面,与传统模型最大的区别在于,它首先会利用大量的无监督数据或有监督数据,通过多种数据学习。学习完成后,模型内部具备众多潜在能力,可通过特定方式激发或诱发这些能力,以执行后续任务。以一个形象的例子来说,这类似于中国古代的“读书百遍,其义自见”,即通过阅读大量书籍,积累了知识,之后在解题、写作等活动中能够游刃有余。这体现了迁移学习中的“transfer能力”。迁移学习在分类方面有多种类型,其迁移方法也包括基于特征和基于参数的迁移。我们的大模型属于基于参数的迁移,即学习一个模型时,其结构和内部参数本身就包含特定信息。若要将模型应用于下游任务,需要微调参数,这属于参数层面的迁移。在此,我们简要介绍迁移学习,大家可进一步深入了解。核心思想在于大模型的迁移学习。回顾整个AI发展历程,

其实这与迁移学习密切相关,包括深度学习早期的一些工作,都是基于这种迁移学习范式进行拓展的。以计算机视觉领域为例,早期的研究者们进行了一些工作,例如……

-
研究者们在图像识别和人脸识别领域使用深度卷积神经网络(CNN)。
-
利用大量标注数据,如ImageNet数据集,进行模型训练。
-
ImageNet包含多种目标识别数据,如花卉、鱼类、昆虫、汽车等。
-
模型在ImageNet上训练后,能够进行图像分类,并有效辅助人脸识别任务。
-
这种将图像识别能力迁移至人脸识别的方法称为知识迁移或迁移学习。
-
ImageNet数据集中存在未标注图片,给进一步应用带来挑战。
-
深度学习模型的训练需要明确的目标、输入和输出。
在图像识别、人脸识别等领域,研究者们的一个核心思想是构建一个深度卷积神经网络(CNN)。他们利用大量已标注的有监督数据进行训练,例如构建了超大规模数据集ImageNet,其中包含了各种花卉、鱼类、昆虫、汽车等目标识别数据。将此数据集输入模型后,理论上模型能够学会对给定图像进行分类,如判断其为汽车或其他动物。然而,当将此模型与其他人脸识别数据结合时,它能够有效地辅助人脸识别任务。这实际上是一种知识迁移,即通过在ImageNet上训练的CV模型获得图像识别能力,并将其迁移至人脸识别。这种迁移学习是一个典型的应用案例。
此外,尽管ImageNet是一个有标注的数据集,但其中也存在大量未标注的图片,这给基于已有学习成果的进一步应用带来了一定的挑战。在课程开始时,我们了解到大模型或深度学习模型的训练需要明确目标、输入,并输入模型以获取输出。

与标准输出进行对比后,我们将得到损失函数等相关内容。通过优化该损失函数,使模型在给定输入后能够得到预期的输出。

-
问题:在输入数据无标注的情况下,如何训练模型。
-
解决方案:提出自监督学习。
-
自监督学习核心:利用未标记数据的内部信息来训练模型。
-
典型代表:对比学习。
-
对比学习操作:未具体描述。
但是如果输入数据没有任何标注,即我不知道其输出类型,那么如何训练模型呢?因此,他们提出了自监督学习。自监督学习的核心原理是,如何利用未标记数据的内部信息,尽可能挖掘这些信息来训练模型。其中,对比学习是一个典型的代表。对比学习具体操作如下:

-
研究者提出一种方法,通过多种形式的图片改写(如添加噪声、旋转等)来增强模型识别能力。
-
改写后的图片与原始图片一同输入模型,让模型判断是否为同一张,以此构造对比标签。
-
这种方法允许模型利用大量未标注数据,实现无监督学习,学会辨别图片一致性。
-
类似方法可应用于语言理解,语言模型通过建模句子概率来理解语言。
大家思考这样一个问题:当仅有一张图片或一组图片,且这些图片没有标注信息时,如何让模型具备良好的识别能力。研究者们提出了一种方法:对图片进行多种形式的改写,如添加噪声、旋转等。随后,将改写后的图片与原始图片一同输入模型,询问模型这两张图片是否为同一张。通过这种方式,人为构造出对比标签,并随机选取两张图片,让模型判断它们是否为同一张。这样,即使是大量未标注的数据也能被利用,从而实现所谓的“无监督学习”,使模型学会辨别两张图片是否一致。
在整个计算机视觉(CV)的发展过程中,研究者们在这方面做了大量工作,最终使得计算机视觉中的各种模型能够基于大量无标注图片选择基础模型,并在此基础上进行各种视觉任务。
在语言理解方面,我们能否也尝试类似的方法呢?答案是肯定的。回顾我们之前对语言模型的简单介绍,语言模型本质上是建模一句话的概率。

-
字监督与处理图片有相似之处。
-
拥有大量人类语言数据,但捕捉有效监督信号是关键。
-
定义模型理解人类语言的标准是判断模型是否真正理解语言的关键。
-
提出的最佳定义是:模型理解句子时,其概率是否大于或等于其他语言出现的概率。
其实,在文本中进行字监督的本质与处理图片相似。我们拥有大量的人类语言数据,包括书籍和文本,这些数据可以从互联网上获取。面对这些海量数据,如何捕捉有效的监督信号,使其有助于模型理解人类语言,是一个关键问题。这又引出一个基本问题:若认为模型能够理解人类语言,我们如何在数据上定义模型理解人类语言的标准?
他们提出了一个最佳定义:如果一个模型能理解给定的自然语言句子,其概率是否大于或等于其他语言出现的概率。通过这种方式,可以判断模型是否真正理解人类语言。

-
人类交流中,语言错误或语序不当会被立即察觉。
-
电脑若能识别哪些是人类应该说的,哪些不应该说,则意味着它理解了人类自然语言。
-
研究者从这一角度出发,探讨如何验证人类所有语言。
就好比两个人交谈,若我说错话或语序不当,人们会立刻察觉这不是正常人的表达。但对于电脑而言,若它能识别哪些话是人类应该说的,哪些不应该说,那么这也意味着它已经理解了人类自然语言。
因此,他们从这个角度出发,考虑如何验证人类所有语言。
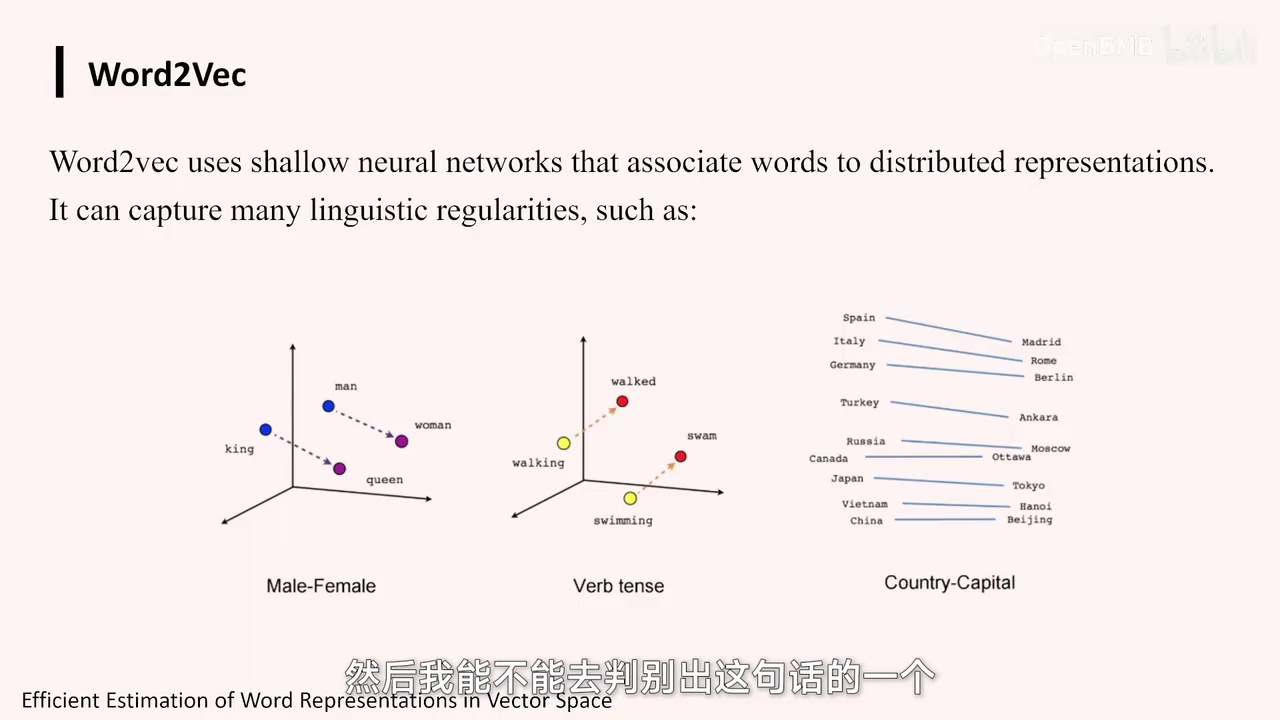
一句话的整体概率判别,他们基于此出发,最早进行的工作是构建所谓的Word2Vec,即词向量,研究如何学习大量词汇的向量表示。他们的具体做法相对简单,总体而言,他们采用了两套模型。

-
CBOW模型原理:通过提取句子中的词窗口,移除一个词,根据上下文预测该词,为每个词分配向量,形成加和向量来代表局部词的语意信息。
-
自监督学习:无需标注,通过在文章中划取窗口并移除词作为填空题,帮助模型学习和掌握语言。
-
模型评估:类似于老师通过填空题评估学生,模型通过预测准确性来学习,每个字最终得到良好的表示。
这两个模型在本质上是一致的。以左边的CBOW模型为例,其原理是:给定一句话,从中提取一个窗口,例如“我爱北京天安门”。然后,模型会从窗口中移除一个词,例如移除“北京”,并要求根据剩余的上下文“我爱空格天安门”来填补空缺。这种做法为每个词分配一个向量,例如在“我爱北京天安门”中移除“北京”,就变成了“我爱天安门”。每个词的向量相加,形成加和向量,这个加和向量能够代表局部词的语意信息,并用于预测空缺处应填的内容。这就是该模型的建模过程。
显然,这种方式是一种自监督学习,无需任何标注。通过在文章中划取窗口,并在每个窗口中移除一个词,以此作为模型输出的目标,类似于小学时的挖字填空题。这种填空题在英语中应用较多,实际上,在训练大型模型时,这种填空题被广泛使用,以帮助模型学习和掌握人类语言。
从某种程度上讲,这与老师评估学生语文水平的方式相似,即通过填空题或类似题目来测试。对于深度学习模型来说,通过这种方式学习,如果模型预测准确,最终每个字都会得到一个相当好的表示。
-
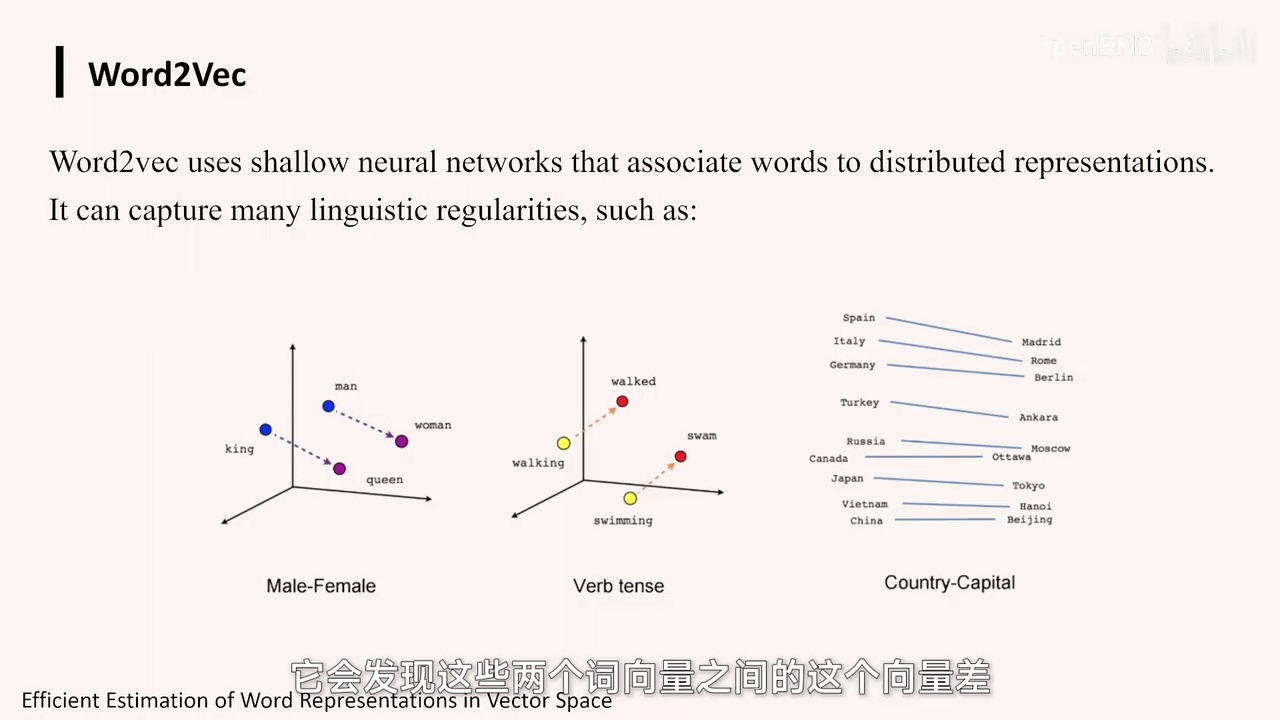
通过计算词项量之间的差值,可以揭示词之间的特定关系。
-
例如,“国王”与“皇后”的差值与“男人”与“女人”的差值一致。
-
动名词与过去时态的词项量差也表现出一致性。
-
这种填空方式帮助模型理解词间的语义关联,并以数据形式呈现。
-
这是AM模型进行语言理解的一个深层次机理。
这些项量学完之后,会发现这两个词项量之间的差值,能代表一些特定的关系。例如,国王与皇后这两个词项量之间的差值与男人与女人之间的差值非常一致。同理,右边的例子也是类似的,即每个动名词与过去时态的词项量差也很一致。换句话说,通过这种填空方式,模型能够理解词之间的一些语义关联关系,并以数据化的形式呈现出来。这实际上是我们让AM模型进行语言理解背后的一个较为深层次的机理。

-
利用海量文本数据学习词汇量可能存在一个问题。
-
问题在于难以捕捉人类语言中的二义性。
-
二义性是语言学中的重要概念,指一句话可能具有不同的含义。
-
例如,“意思”一词在不同语境下可能有赠送或拒绝的含义。
只是通过这种方式,利用海量的文本数据学习词汇量,可能会出现一个问题。其典型问题在于难以捕捉人类语言中的二义性。在语言学中,二义性是一个重要的概念,它指的是一句话可能具有不同的含义。例如,从中文的角度来看,“意思”这个词就非常有趣。比如,你说“意思意思一下”,这里的“意思”可能是指赠送。而当别人回答“真不好意思”时,这里的“意思”则表示拒绝。这些含义的词义都非常复杂。

-
人类的语言具有高度的二异性。
-
举例说明“bank”一词在不同语境中的歧义性。
-
指出学习语言时,词项的多义性给学习带来困难。
区分 人类的语言具有高度的二异性。郑喜举了一个例子,第一句话是“I go to bank for this money”,第二句是“I go to bank for fishing”。实际上,从第一句话中可以推断出第一个“bank”指的是银行,而第二个“bank”实际上指的是河岸。但由于两者都用“bank”表示,学习一个词项时很难同时表达两个语义。
区分: 人类的语言具有高度的二异性。郑喜举了一个例子,第一句话是“I go to bank for this money”,第二句是“I go to bank for fishing”。实际上,从第一句话中可以推断出第一个“bank”指的是银行,而第二个“bank”实际上指的是河岸。但由于两者都用“bank”表示,学习一个词项时很难同时表达两个语义。

第二个项目是关于使用滑动窗口预测中间词。假设仅提供如“the movie is sold”这样的句子,要求填充空白部分。

-
使用贝叶斯或贝尔的贝叶斯方法,词向量在空间中可能相似。
-
可能将“贝叶斯”替换为“贝尔”而不影响文章的语法错误。
-
单词的上下文或全局上下文未考虑时,词向量学习可能存在模糊性。
-
2018年的一项研究关注使用RNN进行语言建模,即逐词输出。
您可以使用贝叶斯或贝尔的贝叶斯方法,对吧?这意味着在词向量空间中,贝叶斯和贝尔的词向量很可能学得很相似。您想想看,您是否可以在所有文章中将贝叶斯都替换成贝尔,也许它的语义整体读下来也不会有太大的语法错误,对吧?这就意味着,如果不考虑一个词的上下文,或者全局的上下文,仅仅依靠一个小窗口滑动的话,它学到的词向量可能具有一些模糊性。
因此,他们在2018年做了一项非常有意思的研究,什么意思呢?就是刚才我们也提到,使用RNN进行语言建模,对吧?就是用RNN不断输出一个词,一个词一个词地往外蹦。比如给出第一个词生成第二个词,给出前两个词。

-
使用前三个或第四个词作为提示,模型可以生成完整的句子。
-
模型基于RNN(循环神经网络)技术,能够分解句子并生成对应文本。
-
模型可以处理如“中国银行认识”这样的句子,并生成相应的文本。
通过提供前三个词或第四个词,我实际上可以让模型将一句话完整地表达出来。例如,它可以将“我爱北京天安门”分解为“我”、“爱”、“北京”和“天安门”,并分别生成对应的文本。这样,我们可以将网络上所有人类生成的文本按照这种方式输入模型。
该模型是一个RNN(循环神经网络),它具有一个有趣的特点:给定一句话,如“中国银行认识”,它可以将其分解并生成相应的文本。
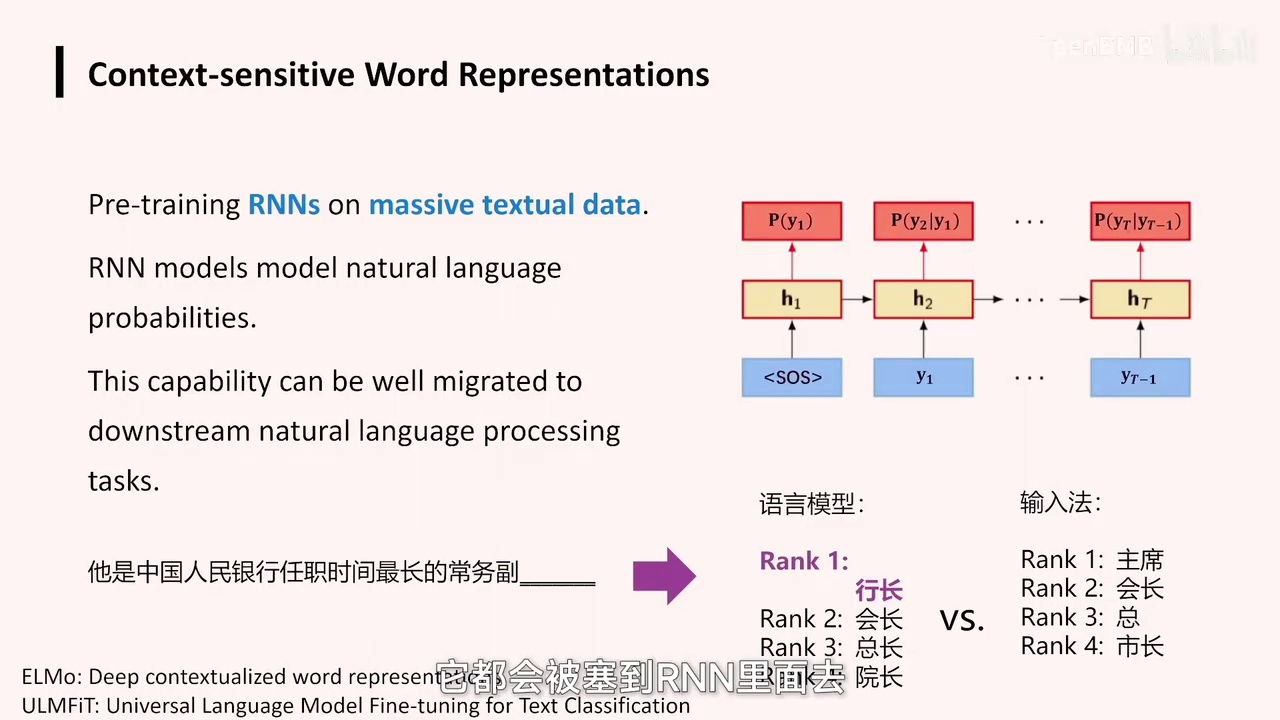
这句话的每个词都会被输入到RNN中,RNN在每一个步骤是否都能输出一个词向量呢?它将RNN输出的词向量视为词项量,并将其作为语言处理的一部分。

融合整个上下文语意的一个模型,然后使用该模型。

-
基础词汇扩展:某些词汇具有多重含义,如“bank”可指银行或核弹。
-
上下文赋予新义:词汇的含义通过上下文和与其他文字的交互而获得新的解释。
-
实例说明:“I go to the bank for phishing”中,“phishing”一词在特定语境下有特定含义。
最终,它呈现的效果是,我们有一些基础词汇的扩展,例如,某个词汇可能既指银行又指核弹。然而,通过上下文以及与其他文字的交互方式,每个词汇都会获得新的含义。例如,刚才提到的“I go to the bank for phishing”,其中的“phishing”一词。
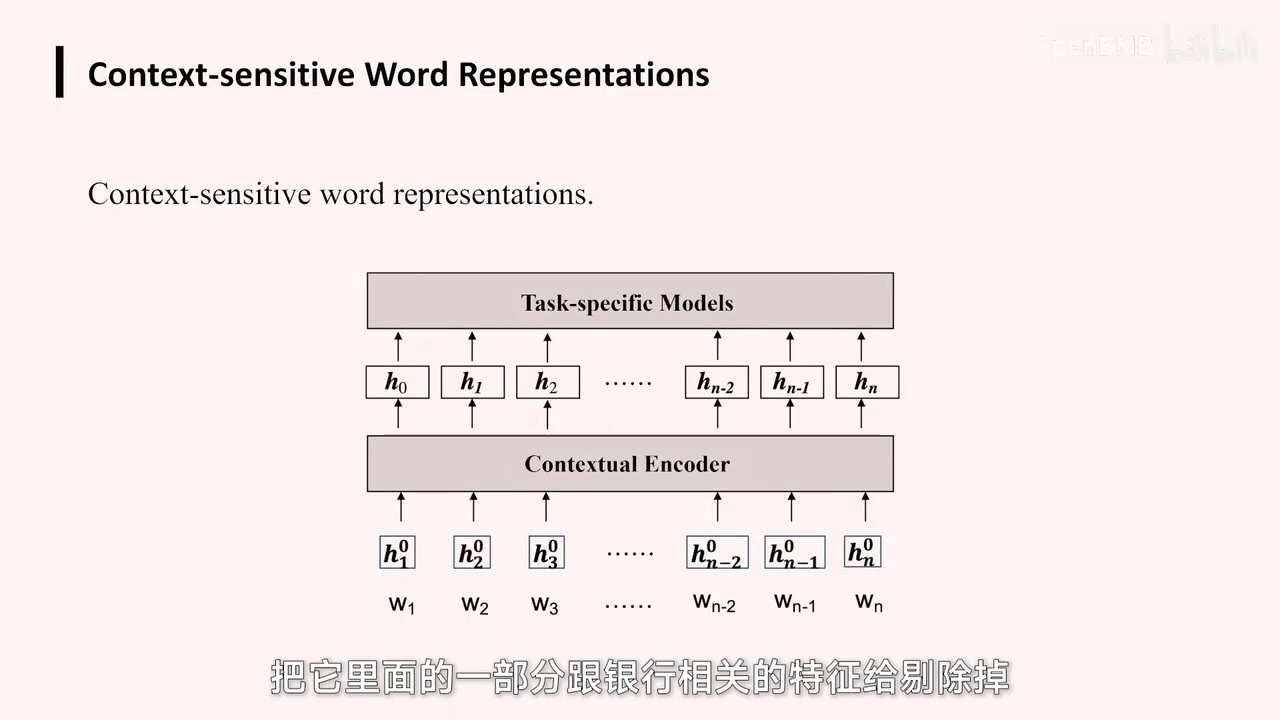
该Fishing模型会令Bank去除其中与银行相关的部分特征。剩余的特征仅与局部语境相关。利用这些具有语境的特征项,后续模型能够有效解决RA性问题。

-
模式起源:所述模式是预训练大模型的最初版本。
-
大模型核心:通过大量数据训练,使模型掌握包括语言在内的多种能力,并应用于后续任务。
-
训练阶段:分为两个阶段,首先是学习人类语言,其次是深入理解上下文并完成任务。
然后,这种模式实际上是我们整个预训练大模型的最初版本。我们之前所讲述的,大模型本质上是将大量数据输入模型进行训练,使其掌握包括语言在内的多种能力,并将这些能力应用于后续任务中。这正是大模型的核心所在。这一过程分为两个阶段:首先是广泛学习人类语言,其次是利用对人类语言的学习,实现对每个上下文的深入理解,并以此为基础完成后续任务。这便是最初的大模型理念。

-
介绍了一种从构建到应用的范式。
-
强调大模型通过学习人类数据,特别是语言数据,能够实现的功能。
-
提及了AOMO作为初步的语言学习模型的例子。
一个从构建到应用的范式。接下来,我们将简要介绍基于此范式,大模型能够实现的功能,旨在为大家建立基础认知。
大模型通过广泛学习各种人类数据,尤其是语言数据,能够达到的效果。例如,我们之前提到的基于RNA进行的一系列操作,即AOMO,它相当于是一种初步的语言学习模型。

或者是大型模型,我认为其发展历程可以类比于一个发端的过程。其关键节点在于2018年,之所以命名为AOMO,是因为美国动画片《芝麻街》中有一个名为AOMO的人工智能角色,即那个最前面的红色怪物。

您发现众多大型模型均取名为“芝麻街”中的角色,如谷歌的Bert。实际上,Bert即指芝麻街中的黄老先生,该角色名即来源于此。随后,众多模型名称均由此衍生。

-
芝麻街家族推出:提及了芝麻街家族的推出。
-
预训练模型影响:从2018年开始,预训练模型对自然语言处理(NLP)发展产生重大影响。
-
模型训练方式转变:从为每个任务单独训练模型转变为将大量知识注入到一个模型中。
-
性能提升:这种转变在多个文本评测任务上显著提升了表现。
然后推出了芝麻街家族。实际上,从2018年开始,预训练模型的出现极大地推动了自然语言处理(NLP)的发展。我们不再为每个任务单独训练模型,而是将大量知识注入到一个模型中,再激发出与任务相关的知识以解决具体问题。这种转变使得我们在多个文本评测任务上的表现显著提升。
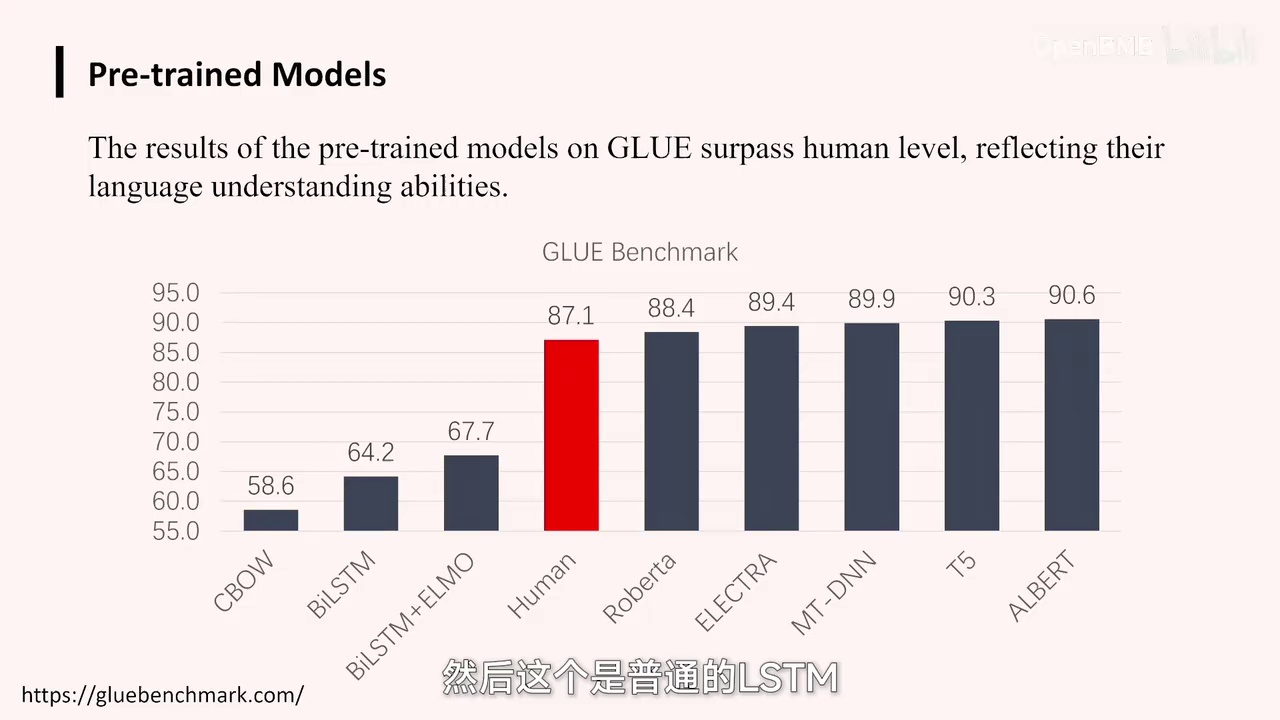
-
CBOW相当于磁效应量。
-
普通LSTM是LSTM模型加上AOMO。
-
Transformer预训练模型效果显著提升,有时超过人类水平。
-
2018-2020年间,模型效果随参数增大和数据增多而提升,类似于人体发育过程。
我们了解到,CBOW相当于我们最初提到的磁效应量,而普通的LSTM则是LSTM模型加上所谓的最基础的AOMO。然而,随着基于Transformer的预训练模型的出现,其效果呈现直线上升的趋势,很多时候甚至超过了人类水平,展现出强劲的发展势头。
从2018年到2020年,一个显著的现象是,随着模型参数的不断增大和学习数据的持续增多,模型的效果也随之提升,这与人体的发育过程有相似之处。

人类从原始人或灵长类祖先进化到现在,星岛容量在不断增大。然而,对应的模型参数也在不断增大。

第二个相当于说,目前教育时间呈增长趋势,所学知识量也随之增加。这实际上对应的是模型学习所需的数据量也在不断增长。
-
模型参数增大。
-
训练数据增多,模型能力显著提升。
-
2020年OpenAI推出GPT-3。
-
GPT-3的前身是GPT-2。
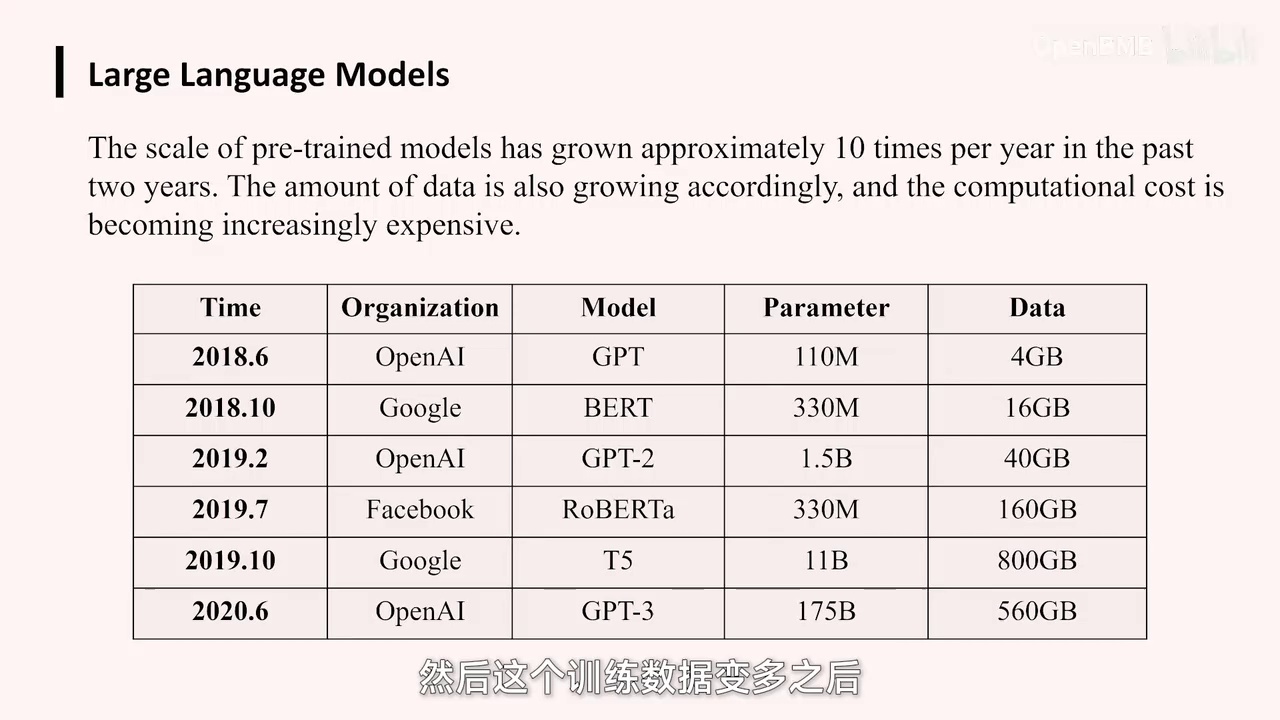
你会发现,经过这一系列操作,模型参数增大,随着训练数据的增多,模型能力得到了显著提升。最令人震惊的是在2020年,当时OpenAI推出的GPT-3,大家是否都了解GPT-3?是否使用过GPT-3?GPT-3的前身是GPT-2。它在2020年...

当时该模型规模庞大,拥有1750亿参数,之前均以赵莱集团参数为标准。
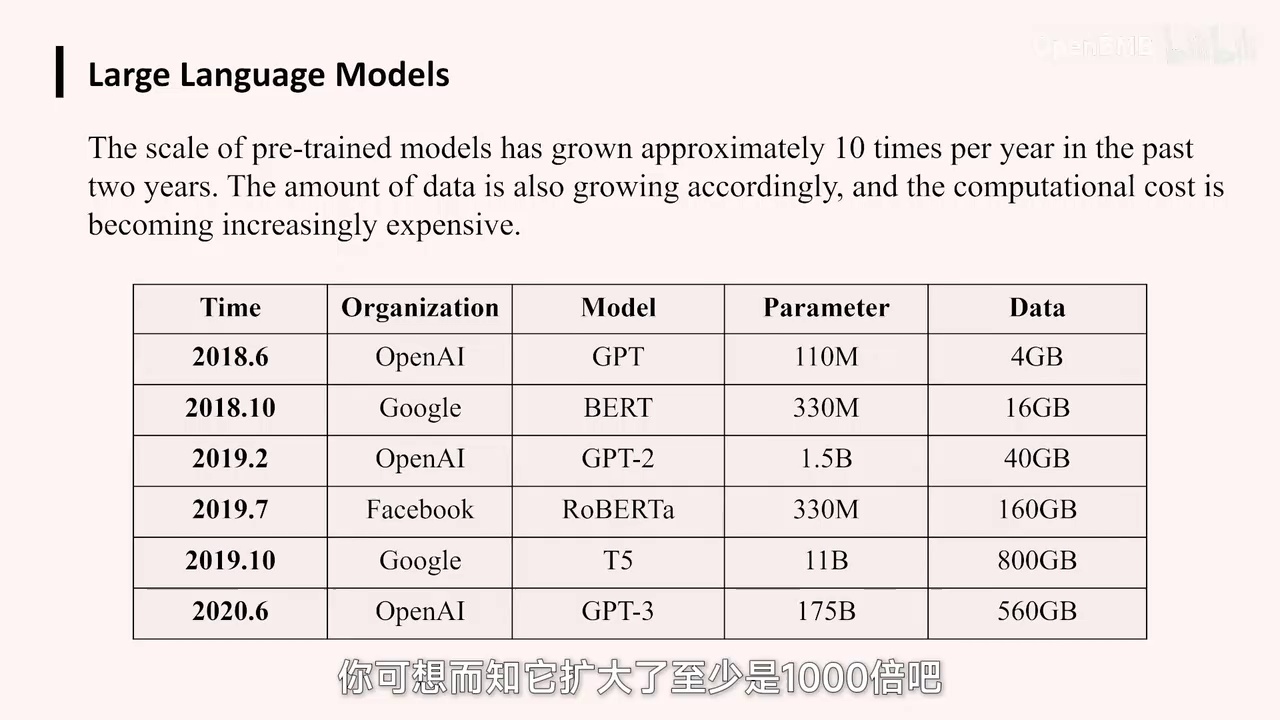
他们是按照模型参数进行扩展,规模整整扩大了,可以想见至少扩大了1000倍。在这样的规模下,模型效果达到了非常惊人的水平。然后这个地方就……

您可以看到,OpenAI当年的GPT-3在参数规模上相较于之前的模型有着显著提升。
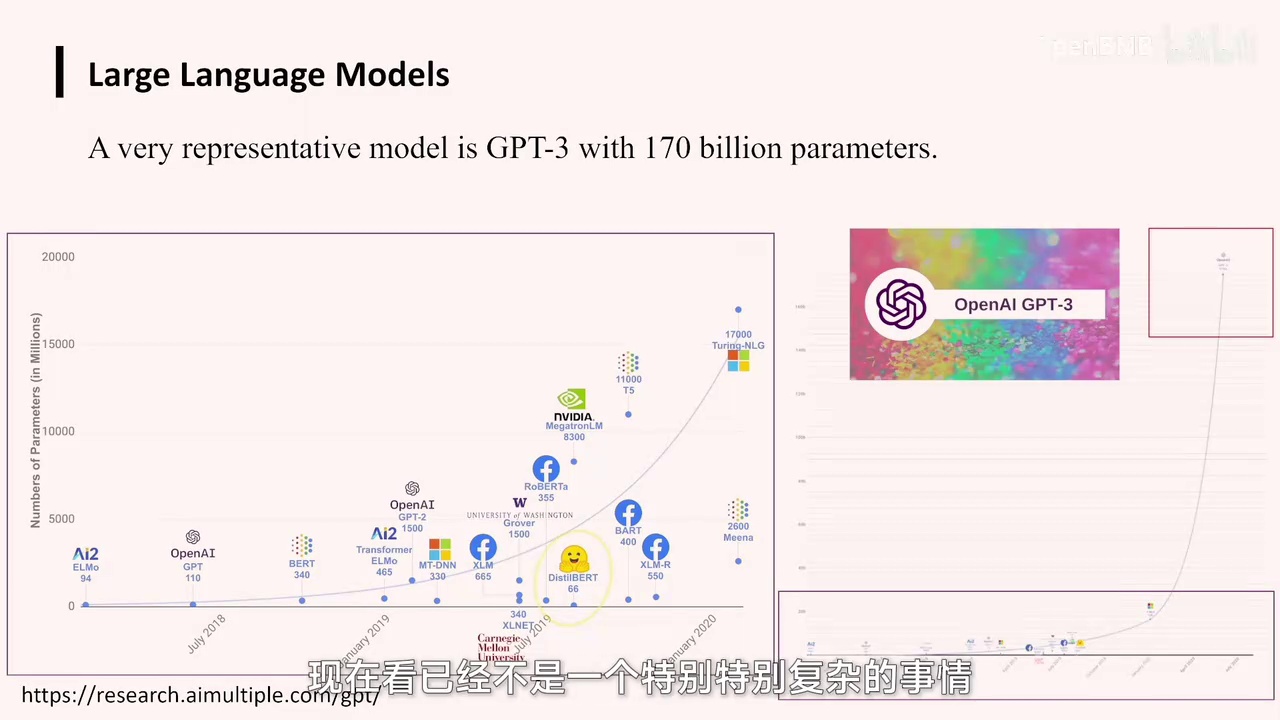
从当前视角来看,迅速迁移模拟技术已经变得相对简单,不再像当年那样具有挑战性。尽管当时众多研究者都在探索这一领域。

-
构建大模型是一项艰巨的任务,但效果显著。
-
早期研究认为,AI的逻辑推理和知识掌握需要采用符号化方法。
-
大模型通过大量数据学习,自发涌现出丰富的世界知识和常识知识。
在探索小模型的同时,尝试构建大模型是一项艰巨的任务,需要一定的勇气去进行反复试验。然而,其效果同样令人惊叹。
我早期的研究主要集中在与知识相关领域。当时我们认为,若要让AI具备逻辑推理或知识掌握能力,必须采用符号化的方法。例如,学习形式逻辑等,通过符号化的方式推导出A能推出B,B能推出C。
然而,大模型在大量数据输入后,会自发涌现出丰富的世界知识和常识知识。例如,询问1981年美国总统是谁,它能够正确回答是杰弗逊。这表明,大模型是通过大量数据学习,从而积累了丰富的知识。

-
世界知识和常识知识,如“青蛙有几条腿”,过去需要专门训练模型掌握。
-
现在模型能够进行简单的逻辑推理,无需专门训练。
-
过去认为这类任务需要通过符号推演完成。
-
神经网络采用的技术被称为Neurosymbolic。
这是世界知识和常识知识,例如,当被问及“一只青蛙有几条腿”时,它能够回答“四条腿”。这类知识过去需要通过专门训练才能让模型掌握,而现在它也能进行简单的逻辑推理。过去,我们通常认为这类任务需要通过符号推演来完成,当时神经网络所采用的技术被称为Neurosymbolic。

-
神经符号模型架构的逻辑推演过程类似于逐步进行,每一步可能涉及神经网络学习。
-
模型基于符号化构建。
-
大模型提出构建“大黑盒子”的观点,通过大量数据输入,模型自发展现复杂能力。
-
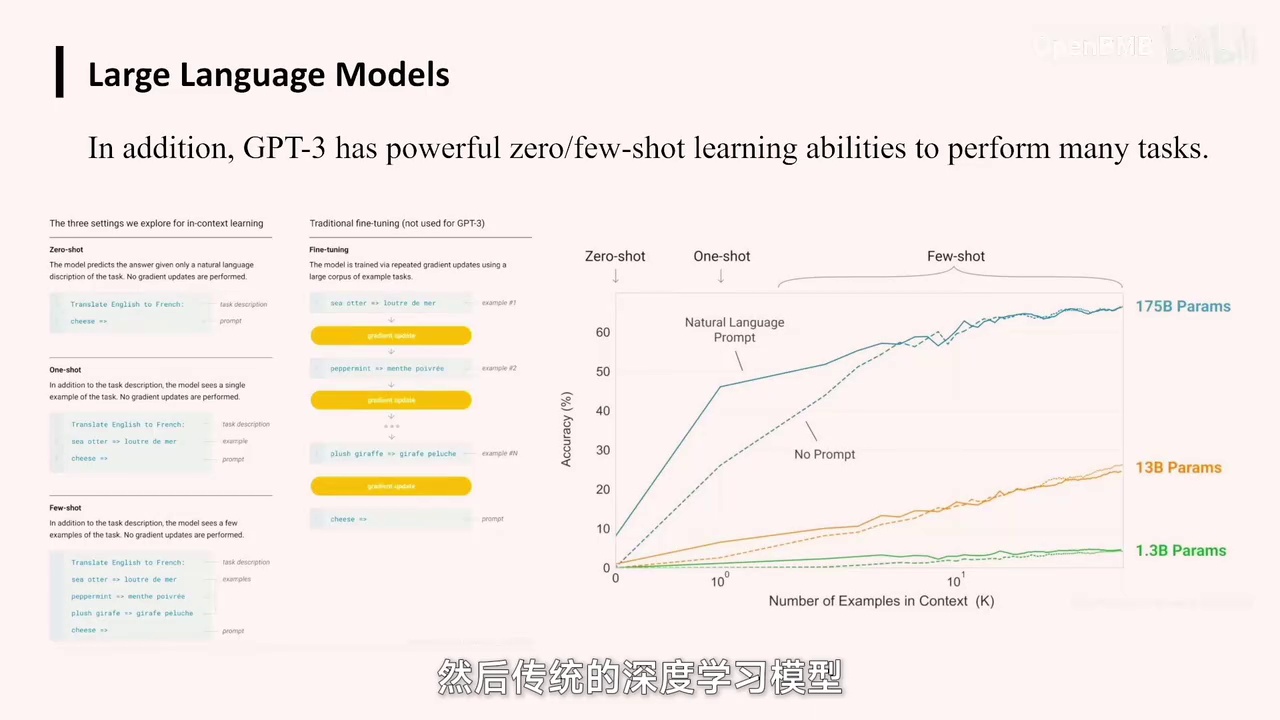
与传统深度学习模型相比,大模型在举一反三的能力上有所提升,GPT-3展示了这一特点。
这些神经符号模型架构,其逻辑推演过程类似于逐步进行,尽管每一步的推演可能涉及神经网络的学习。整体而言,它仍是一个基于符号化构建的网络。然而,大模型提出了一个观点,即可以构建一个“大黑盒子”,将大量数据输入其中,模型便会自发地展现出类似人类认知的复杂能力,这曾令大家感到震惊。此外,大模型还展示了一个有趣的现象:与传统的深度学习模型和神经网络相比,它们最大的问题在于缺乏举一反三的能力,需要学习大量数据才能掌握任务。但在GPT-3中,它展示了不同的能力。

-
ZRShort功能:仅提供任务内容描述,不提供教学案例,如直接告知马是四脚动物,展示照片让辨认。
-
FuseShort功能:在描述任务内容的基础上,提供辅助照片,帮助识别,如描述马的外观并提供多张照片。
它的ZRShort和FuseShort功能在于仅告知任务内容,而不提供教学案例。例如,若你从未见过马,我仅告诉你马是四脚动物,拥有长尾巴和较长的脖子,随后展示多张照片让你辨认哪张是马,这称为ZRShort。而FuseShort则不仅描述马的外观,还会提供三到四张照片辅助你进行识别。
-
马匹识别:GPT-3仅需少量任务描述或案例即可表现出色,实现零样本学习。
-
模型参数与学习能力:随着模型参数增大,零样本和少样本学习能力提升,模型可自发产生举一反三的能力。
-
GPT-3的认知能力:虽然被认为具有认知能力,但实际未达到进行符号推演的精确程度。
后面进行马匹识别,即所谓的figure short。传统深度学习模型可能需要成百上千张马的照片来学习识别,而GPT-3则不同,它只需少量任务描述或案例,就能表现出色。例如,进行语言翻译任务,只需提供少量示例,GPT-3便能胜任。这种能力被称为零样本学习。
此外,随着模型参数的增大,其零样本和少样本学习能力也在提升。这意味着当模型参数达到一定规模后,会自发产生举一反三的能力,这在我们之前看来是一种高级智能的表现。
然而,从近年来的发展来看,GPT-3的认知能力虽然被认为存在,但实际上并未达到进行符号推演的精确程度。
-
他的推演逻辑和能力依然存在。
-
人的思维推理过程与人脑运作相似。
-
人们交流时,不一定能进行完整的思维推理。
-
复杂情节构思或逻辑推理需要记录想法。
-
大模型不需要完全具备公式化推理方法,这样的能力并非绝对必要。
他的基本推演逻辑和能力依然具备,实际上这个过程与人脑运作颇为相似。你会发现,即便与周围的人交流,他们也不一定能够进行非常完整的思维推理。很多时候,如果不将想法记录下来,人们也很难进行复杂的情节构思或逻辑推理。因此,我们也不应该对大模型苛求其完全具备一套严谨的公式化推理方法,尽管这样的能力确实存在,但并非绝对必要。
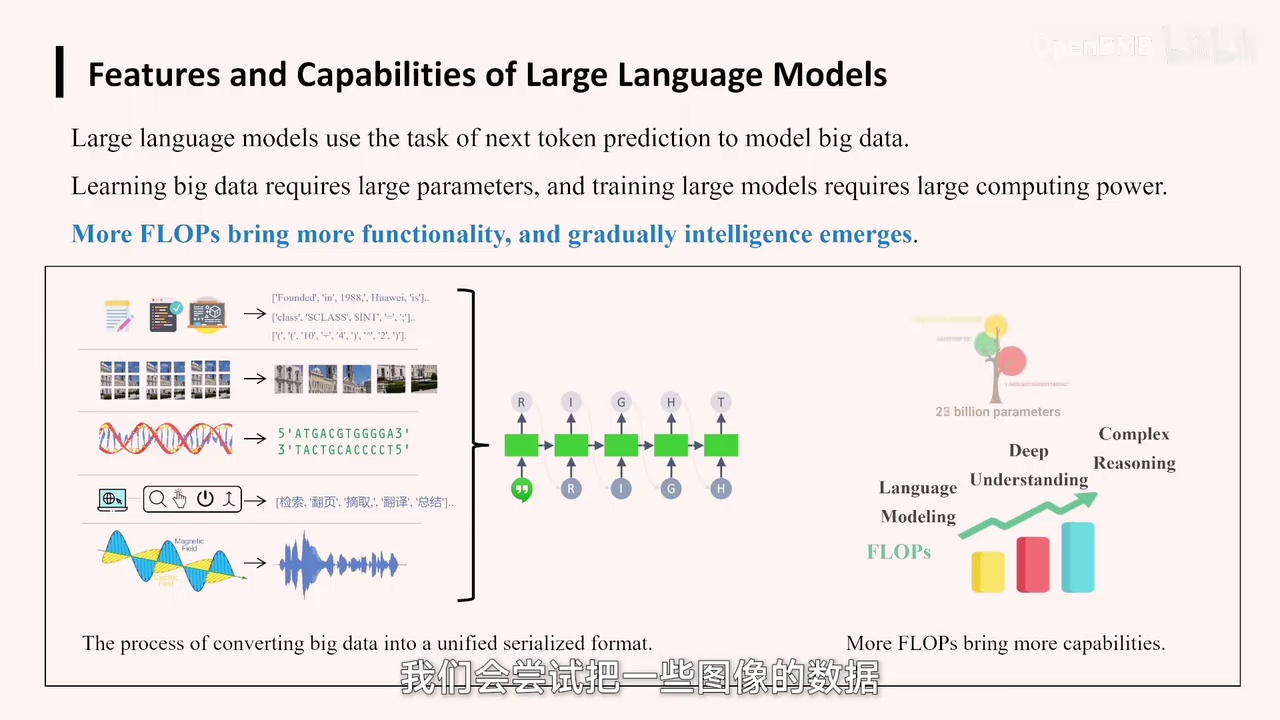
整体而言,我们在后续研究中不仅关注文本数据,还尝试将图像、DNA以及人类操作电脑产生的数据纳入研究范围。

甚至操作各种工具的顺序,包括一些更复杂的电磁序列数据,都将其转化为序列化数据,随后利用统一的序列化模型进行建模。
-
模型经过数据输入后达到极致智能状态,具备多领域全面覆盖能力。
-
课程旨在简单介绍深度学习进步,知识迁移和模型参数增大导致模型智能成长。
-
后续课程将详细介绍实现模型具备通用能力的方法。
-
本节课介绍了神经网络和大模型的基础知识。
这些数据输入模型后,模型便呈现出一种极致的智能状态,这种智能能够涵盖多个领域,实现全面覆盖。这在某种程度上是模型后续发展以及受到广泛关注的重要原因。
总体而言,本课程旨在向大家简单介绍,随着深度学习的不断进步,结合知识迁移和模型参数的增大,最终导致模型智能如树般不断成长,最终形成强大的能力。
后续课程将详细介绍实现这一过程的方法,即如何逐步将数据输入模型,使其具备解决人类各种需求的通用能力。
本节课主要介绍相关基础知识,包括神经网络和大模型的基础知识,基本内容已介绍完毕。

然后请各位提出疑问。