文章目录
- 1. 特殊值
- 2. 函数命名空间
- 3. 数学函数
- 4. 统计函数
- 5. 插值函数
- 6. 多项式拟合函数
- 7. 自定义广播函数
- 7.1.使用np.frompyfunc定义广播函数
- 7.2 使用np.vectorize定义广播函数
1. 特殊值
NumPy有两个很有趣的特殊值,np.nan 和 np.inf。nan 是 not a number 的简写,意为不是数字,inf 是 infinity 的简写,意为无穷大。np.nan 也可以写作 np.Nan、np.NaN 或者 np.NAN,np.inf 也可以写作 np.Inf 或 np.Infinity。
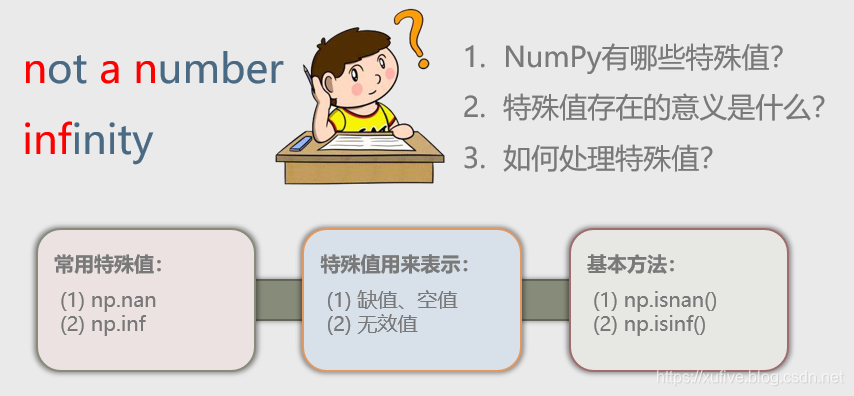
先在IDLE里面看看它们的真实面貌。
>>> a = np.array([1, 2, np.nan, np.inf])
>>> a.dtype
dtype('float64')
>>> a[0] = np.nan
>>> a[1] = np.inf
>>> a
array([nan, inf, nan, inf])
>>> a[0] == a[2] # 两个np.nan不相等
False
>>> a[1] == a[3] # 两个np.inf则相等
True
>>> np.isnan(a[0]) # 判断一个数字是否是np.nan
True
>>> np.isinf(a[1]) # 判断一个数字是否是np.inf
True
NumPy 用特殊值来表示缺值、空值和无效值。想一想,Python 和 C 语言如何表示数组中的缺值、空值和无效值呢?Python 因为数组元素不受类型限制,可以用 None 或者 False 等表示缺值、空值和无效值。对 C 语言来说,恐怕也只能在数据的值域范围之外,选一个特定值来表示吧?比如,假定数组存储的是学生的成绩,成绩一般都是正值,所以C语言可以用-1表示缺考。在NumPy数组中,因为有了nan和inf这两个特殊值,我们就不用在意数据的值域范围了。说到这里,你也会问,这两个特殊值,一个不是数字,一个无穷大,数组运算的时候怎么处理呢?这就是NumPy神奇的地方,我们根本不用担心这个问题。下面的代码,演示了在数组相邻的两个元素之间插入它们的算术平均值——尽管数组元素包含 np.nan,但这并不影响数值计算。
>>> a = np.array([9, 3, np.nan, 5, 3])
>>> a = np.repeat(a,2)[:-1]
>>> a[1::2] += (a[2::2]-a[1::2])/2
>>> a
array([ 9., 6., 3., nan, nan, nan, 5., 4., 3.])
2. 函数命名空间
刚开始使用NumPy函数的时候,你一定会有这样的困惑:
-
都是求和、求极值,下面这两种写法有什么区别吗?
>>> a = np.random.random(10) >>> a.max(), np.max(a) (0.8975052328686041, 0.8975052328686041) >>> a.sum(), np.sum(a) (5.255303938070831, 5.255303938070831) -
同样是复制,为什么深复制 copy() 两种写法都行,而浅复制 view() 则只有数组的方法?
>>> a = np.random.random(10) >>> a.copy() array([0.14712593, 0.05692805, 0.41679214, 0.62755199, 0.58272166,0.88131178, 0.26184716, 0.30175671, 0.78588028, 0.50557561]) >>> np.copy(a) array([0.14712593, 0.05692805, 0.41679214, 0.62755199, 0.58272166,0.88131178, 0.26184716, 0.30175671, 0.78588028, 0.50557561]) >>> a.view() array([0.14712593, 0.05692805, 0.41679214, 0.62755199, 0.58272166,0.88131178, 0.26184716, 0.30175671, 0.78588028, 0.50557561]) >>> np.view(a) Traceback (most recent call last):File "<pyshell#61>", line 1, in <module>np.view(a) AttributeError: module 'numpy' has no attribute 'view' -
为什么 where() 不能作为数组 ndarray 的函数,而必须作为 NumPy 的函数?
>>> np.where(a>0.5) (array([3, 4, 5, 8, 9], dtype=int64),) >>> a.where(a>0.5) Traceback (most recent call last):File "<pyshell#65>", line 1, in <module>a.where(a>0.5) AttributeError: 'numpy.ndarray' object has no attribute 'where'
以上这些差异,取决于函数在不同的的命名空间是否有映射。数组的大部分函数在顶层命名空间有映射,因此可以有两种用法。数组的一小部分函数,没有映射到顶层命名空间,只能有一种用法。而顶层命名空间的大部分函数,也都只有一种用法。下表是我整理出来的常用方法的和命名空间的关系,仅供参考。
| 顶层命名空间和数组对象均支持 | 仅数组对象均支持 | 仅顶层命名空间支持 |
|---|---|---|
| np/ndarray.any()/all() | ndarray.astype() | np.where() |
| np/ndarray.max()/min() | ndarray.fill() | np.stack() |
| np/ndarray.argsort() | ndarray.view() | np.rollaxis() |
| np/ndarray.mean() | ndarray.tolist() | np.sin() |
| … … | … … | … … |
3. 数学函数
如果不熟悉 NumPy,Python 程序员一般都选择使用 math 模块来应对数学问题。从现在开始,我们可以放弃 math 模块了,因为 NumPy 的数学函数比 math 的更方便。我把这两个模块的数学函数整理了一下,分成5类,汇总在这里。其他诸如求和、求差、求积的函数,我把它们归类到统计函数。
- 数学常数
- 舍入函数
- 快速转换函数
- 幂函数、指数函数和对数函数
- 部分三角函数。
| NumPy函数 | math函数 | 功能 |
|---|---|---|
| np.e | math.e | 自然常数 |
| np.pi | math.pi | 圆周率 |
| np.ceil() | math.ceil() | 进尾取整 |
| np.floor() | nath.floor | 去尾取整 |
| np.around() | 四舍五入到指定精度 | |
| np.rint() | 四舍五入到最近整数 | |
| np.deg2rad()/radians() | math.radians | 度转弧度 |
| np.rad2deg()/degrees() | math.degrees() | 弧度转度 |
| np.hypot() | math.hypot() | 计算直角三角形的斜边 |
| np.square() | 平方 | |
| np.sqrt() | math.sqrt() | 开平方 |
| np.power() | math.pow() | 幂 |
| np.exp() | math.exp() | 指数 |
| np.log()/log10()/log2() | math.log()/log10()/log2() | 对数 |
| np.sin()/arcsin() | math.sin()/asin() | 正弦/反正弦 |
| np.cos()/arccos() | math.cos()/acos() | 余弦/反余弦 |
| np.tan()/arctan() | math.tan()/atan() | 正切/反正切 |
下面,我们一起来试用一下这些常用数学函数。
>>> import numpy as np
>>> import math
>>> math.e == np.e # 两个模块的自然常数相等!
True
>>> math.pi == np.pi # 两个模块的圆周率相等!
True
>>> np.ceil(5.3)
6.0
>>> np.ceil(-5.3)
-5.0
>>> np.floor(5.8)
5.0
>>> np.floor(-5.8)
-6.0
>>> np.around(5.87, 1)
5.9
>>> np.rint(5.87)
6.0
>>> np.degrees(np.pi/2)
90.0
>>> np.radians(180)
3.141592653589793
>>> np.hypot(3,4) # 求平面上任意两点的距离
5.0
>>> np.power(3,1/2)
1.7320508075688772
>>> np.log2(1024)
10.0
>>> np.exp(1)
2.718281828459045
>>> np.sin(np.radians(30)) #正弦、余弦函数的周期是2pi
0.49999999999999994
>>> np.sin(np.radians(150))
0.49999999999999994
>>> np.degrees(np.arcsin(0.5)) # 反正弦、反余弦函数的周期则是pi
30.000000000000004
刚才咱们演示的时候,使用的函数参数都是单一的数值,实际上,这些函数都可以用到NumPy数组上。比如,平面直角坐标系中,有1000万个点,x坐标和y坐标都是分布在[0,1),哪一个点距离点(0.5,0.5)最近呢?
>>> p = np.random.random((10000000,2))
>>> x, y = np.hsplit(p,2)
>>> d = np.hypot(x-0.5,y-0.5)
>>> i = np.argmin(d)
>>> print('距离(0.5,0.5)最近的点坐标是(%f,%f),距离%f'%(p[i][0], p[i][1], d[i]))
距离(0.5,0.5)最近的点坐标是(0.499855,0.499877),距离0.000190
4. 统计函数
NumPy 的统计函数有很多,我整理了一下,大约可以分成4类:
- 查找特殊值
- 求和差积
- 均值和方差
- 相关系数
| 函数 | 功能 |
|---|---|
| np.max/min(a, axis=None) np.nanmax/nanmin(a, axis=None) | 返回数组中的最大值/最小值 忽略nan返回数组中的最大值/最小值 |
| np.argmax/argmin(a, axis=None) np.nanargmax/nanargmin(a, axis=None) | 返回数组中最大值和最小值的索引 忽略nan返回数组中最大值和最小值的索引 |
| np.ptp(a, axis=None) | 返回数组中元素最大值与最小值的差 |
| np.median(a, axis=None) np.nanmedian(a, axis=None) | 返回数组元素的中位数 忽略nan返回数组元素的中位数 |
| np.sum(a, axis=None) np.nansum(a, axis=None) | 按指定的轴求元素之和 忽略nan按指定的轴求元素之和 |
| np.cumsum(a, axis=None) np.nancumsum(a, axis=None) | 按指定的轴求元素的累进和 忽略nan按指定的轴求元素的累进和 |
| np.diff(a, axis=-1) | 按指定的轴返回相邻元素的差 |
| np.prod(a, axis=None) np.nanprod(a, axis=None) | 按指定的轴求元素之积 忽略nan按指定的轴求元素之积 |
| np.mean(a, axis=None) np.nanmean(a, axis=None) | 按指定的轴返回元素的算数平均值 忽略nan按指定的轴返回元素的算数平均值 |
| np.average() | 根据权重数据,返回数据数组所有元素的加权平均值 |
| np.var(a) np.nanvar(a) | 返回数组方差 忽略nan返回数组方差 |
| np.std() np.nanstd() | 返回数组标准差 忽略nan返回数组标准差 |
| np.corrcoef(a, b) | 返回两个数组的皮尔逊积矩相关系数 |
我们先以求最大最小值为例,演示一下忽略 nan 的必要性:
>>> a = np.random.random(10)
>>> np.max(a), np.min(a)
(0.9690291560970601, 0.19240165472992765)
>>> a[1::2] = np.nan
>>> a
array([0.80138474, nan, 0.8615121 , nan, 0.19240165,nan, 0.61915229, nan, 0.96902916, nan])
>>> np.max(a), np.min(a) # 此时,min()和max()失效了
(nan, nan)
>>> np.nanmax(a), np.nanmin(a) # 必须使用nanmax()和nanmin()
(0.9690291560970601, 0.19240165472992765)
统计学上,方差和标准差使用比较频繁,我们来演示一下:
>>> a = np.random.randint(0,50,(3,4))
>>> np.sum(np.square(a-a.mean()))/a.size # 用方差定义就方差
238.25
>>> np.var(a) # 用方差函数求方差,结果相同
238.25
>>> np.sqrt(a.var()) # 对方差开方,即是标准差
15.435349040433131
>>> a.std() # 用标准差函数求标准差,结果相同
15.435349040433131
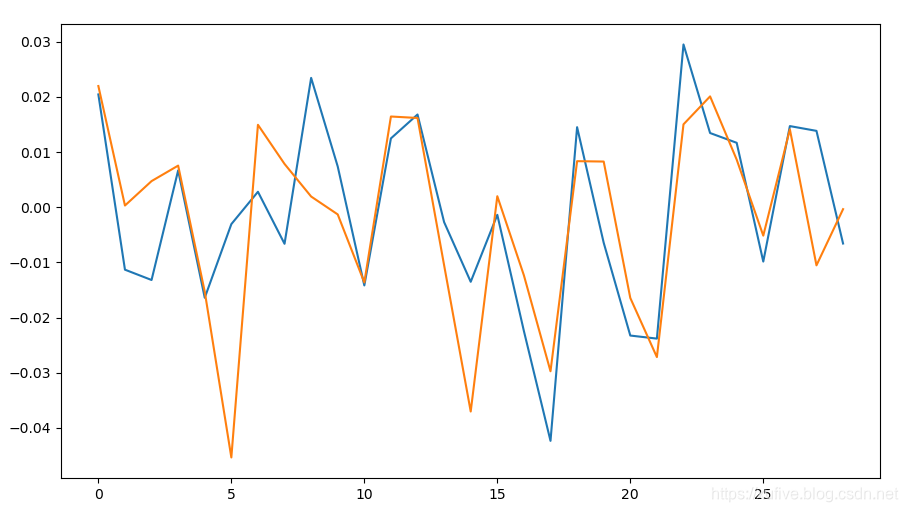
最后,我们综合运用统计函数,分析两只股票的关联关系和收益率。pa 和 pb 是两只股票连续30个交易日的股价数组。每日股价收益率定义为当日股价与前一个交易日股价差除以最后一个交易日的股价。
>>> pa = np.array([79.66, 81.29, 80.37, 79.31, 79.84, 78.53, 78.29, 78.51, 77.99, 79.82, 80.41, 79.27, 80.26, 81.61, 81.39, 80.29, 80.18, 78.38, 75.06, 76.15, 75.66, 73.90, 72.14, 74.27, 75.27, 76.15, 75.40, 76.51, 77.57, 77.06])
>>> pb = np.array([30.93, 31.61, 31.62, 31.77, 32.01, 31.52, 30.09, 30.54, 30.78, 30.84, 30.80, 30.38, 30.88, 31.38, 31.05, 29.90, 29.96, 29.59, 28.71, 28.95, 29.19, 28.71, 27.93, 28.35, 28.92, 29.17, 29.02, 29.43, 29.12, 29.11])
>>> np.corrcoef(pa, pb) # 两只股票的相关系数为0.867,关联比较密切
array([[1. , 0.86746674],[0.86746674, 1. ]])
>>> pa_re=np.diff(pa)/pa[:-1]
>>> pb_re=np.diff(pb)/pb[:-1]
>>> import matplotlib.pyplot as plt
>>> plt.plot(pa_re)
[<matplotlib.lines.Line2D object at 0x000002262AEBD9C8>]
>>> plt.plot(pb_re)
[<matplotlib.lines.Line2D object at 0x000002262BB96408>]
>>> plt.show()
两只股票的收益率变化曲线如下图所示:
5. 插值函数
数据插值是数据处理过程中经常用到的技术,常用的插值有一维插值、二维插值、高阶插值等,常见的算法有线性插值、B样条插值、临近插值等。不过,NumPy只提供了一个简单的一维线性插值函数 np.interp(),其他更加复杂的插值功能放到了SciPy中。
下面用一个实例来演示NumPy一维线性插值函数的使用方法。假定_x和_y是原始的样本点x坐标和y坐标构成的数组,总数只有11个点。如果想在_x的值域范围内插值更多的点,如增加到33个点,就需要在_x的值域范围内生成33个点的 x坐标构成的数组x,再利用插值函数np.interp()得到对应的33个点的y坐标构成的数组y。
>>> import matplotlib.pyplot as plt
>>> _x = np.linspace(0, 2*np.pi, 11)
>>> _y = np.sin(_x)
>>> x = np.linspace(0, 2*np.pi, 33)
>>> y = np.interp(x, _x, _y)
>>> plt.plot(x, y, 'o')
[<matplotlib.lines.Line2D object at 0x0000020A2A8D1048>]
>>> plt.plot(_x, _y, 'o')
[<matplotlib.lines.Line2D object at 0x0000020A2A5ED148>]
>>> plt.show()
下图中橘黄色(浅色)的点是原始样本点,蓝色(深色)的点是进行一维线性插值后的点。

6. 多项式拟合函数
拟合与插值看起来有一些相似,所以初学者比较容易混淆,实际上二者是完全不同的概念。拟合又称回归,是指已知某函数的若干离散函数值,通过调整该函数中若干待定系数,使得该函数与已知离散函数值的误差达到最小。
多项式拟合是最常见的拟合方法。对函数 f ( x ) f(x) f(x),我们可以使用一个 k k k阶多项式去近似。
f ( x ) ≈ g ( x ) = a 0 + a 1 x + a 2 x 2 + a 3 x 3 + . . . + a k x k f(x) \approx g(x) = a_0 + a_1x + a_2x^2 + a_3x^3 + ... + a_kx^k f(x)≈g(x)=a0+a1x+a2x2+a3x3+...+akxk
通过选择合适的系数(最佳系数),可以使函数 f ( x ) f(x) f(x)和 g ( x ) g(x) g(x)之间的误差达到最小。最小二乘法被用于寻找多项式的最佳系数。NumPy提供了一个非常简单易用的多项式拟合函数np.polyfit(),只需要输入一组自变量的离散值,和一组对应的函数 f ( x ) f(x) f(x),并指定多项式次数 k k k,就可以返回一组最佳系数。函数np.poly1d(),则可以将一组最佳系数转成函数 g ( x ) g(x) g(x)。
下面的例子首先生成了原始数据点_x 和_y,然后分别用4次、5次、6次和7 次多项式去拟合原始数据,并计算出每次拟合的误差。
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定字体以保证中文正常显示
>>> plt.rcParams['axes.unicode_minus'] = False # 正确显示连字符
>>> _x = np.linspace(-1, 1, 201)
>>> _y = ((_x**2-1)**3 + 0.5)*np.sin(2*_x) + np.random.random(201)/10 - 0.1
>>> plt.plot(_x, _y, ls='', marker='o', label="原始数据")
[<matplotlib.lines.Line2D object at 0x0000011D87DFFC08>]
>>> for k in range(4, 8):g = np.poly1d(np.polyfit(_x, _y, k)) # g是k次多项式loss = np.sum(np.square(g(_x)-_y)) # g(x)和f(x)的误差plt.plot(_x, g(_x), label="%d次多项式,误差:%0.3f"%(k,loss))[<matplotlib.lines.Line2D object at 0x0000011D87FDAA08>]
[<matplotlib.lines.Line2D object at 0x0000011D8A2A9A88>]
[<matplotlib.lines.Line2D object at 0x0000011D87FE0AC8>]
[<matplotlib.lines.Line2D object at 0x0000011D87FE5348>]
>>> plt.legend()
<matplotlib.legend.Legend object at 0x0000011D87FE00C8>
>>> plt.show()
下图是分别用 4 次、5 次、6 次和 7 次多项式拟合的效果,可以看出 7 次多项式拟合的误差最小。

7. 自定义广播函数
前面讲过,广播是NumPy最具特色的特性之一,几乎所有的NumPy函数都可以通过广播特性将操作映射到数组的每一个元素上。然而NumPy函数并不能完成所有的工作,有些工作还需要我们自己来定义函数。如何让我们自己定义的函数也可以广播到数组的每一个元素上,就是自定义广播函数要做的事情。
假定a和b是两个结构相同的数组,数据类型为8位无符号整型。我们希望用a和b生成一个具有相同结构的新数组c,生成规则是:同一位置的元素,若a或b任何一方等于0,则c等于0;若a等于b,则c等于0;若a和b均等于2的整数次幂,则c取a和b中的较大者;若a或b只有一方等于2的整数幂,则c等于满足条件的一方;以上条件都不满足时,c取a和b中的较大者。
很显然,现有的NumPy函数都无法实现这个计算功能,因此需要自定义函数,其代码如下。
>>> def func_demo(x, y):if x == 0 or y == 0 or x == y:return 0elif x&(x-1) == 0 and y&(y-1) == 0: # x和y都是2的整数次幂return max(x, y)elif x&(x-1) == 0: # 仅有x等于2的整数次幂return xelif y&(y-1) == 0: # 仅有y等于2的整数次幂return yelse:return max(x, y
将自定义函数变成广播函数的方法有两个,下面分别进行详细讲解。
7.1.使用np.frompyfunc定义广播函数
使用 np.frompyfunc( ) 将数值函数转换成数组函数需要提供三个参数:数值函数、输入参数的个数和返回值的个数。另外,np.frompyfunc() 返回的广播函数,其返回值是object类型,最终需要根据实际情况显式地转换数据类型,其代码如下。
>>> uf = np.frompyfunc(func_demo, 2, 1)
>>> a = np.random.randint(0, 256, (2,5), dtype=np.uint8)
>>> b = np.random.randint(0, 256, (2,5), dtype=np.uint8)
>>> a
array([[118, 33, 164, 187, 48],[ 41, 128, 242, 225, 34]], dtype=uint8)
>>> b
array([[170, 207, 35, 61, 251],[251, 206, 70, 208, 85]], dtype=uint8)
>>> c = uf(a, b)
>>> c
array([[170, 207, 164, 187, 251],[251, 128, 242, 225, 85]], dtype=object)
>>> c = c.astype(np.uint8)
>>> c
array([[170, 207, 164, 187, 251],[251, 128, 242, 225, 85]], dtype=uint8)
7.2 使用np.vectorize定义广播函数
np.frompyfunc( ) 适用于多个返回值的函数。如果返回值只有一个,使用 np.vectorize( ) 定义广播函数更方便,并且还可以通过 otypes 参数指定返回数组的元素类型,其代码如下。
>>> uf = np.vectorize(func_demo, otypes=[np.uint8])
>>> a = np.array([[118, 33, 164, 187, 48],[ 41, 128, 242, 225, 34]], dtype=np.uint8)
>>> b = np.array([[170, 207, 35, 61, 251],[251, 206, 70, 208, 85]], dtype=np.uint8)
>>> c = uf(a, b)
>>> c
array([[170, 207, 164, 187, 251],[251, 128, 242, 225, 85]], dtype=uint8)
自定义广播函数并不是真正的广播函数,其运行效率和循环遍历几乎没有差别,因此除非确实必要,否则不应该滥用自定义广播函数。事实上,总有一些技巧可以不用遍历数组也能实现对数组元素的操作,如对数组元素分组操作等。