多场景建模: STAR(Star Topology Adaptive Recommender)
多场景建模(二): SAR-Net(Scenario-Aware Ranking Network)
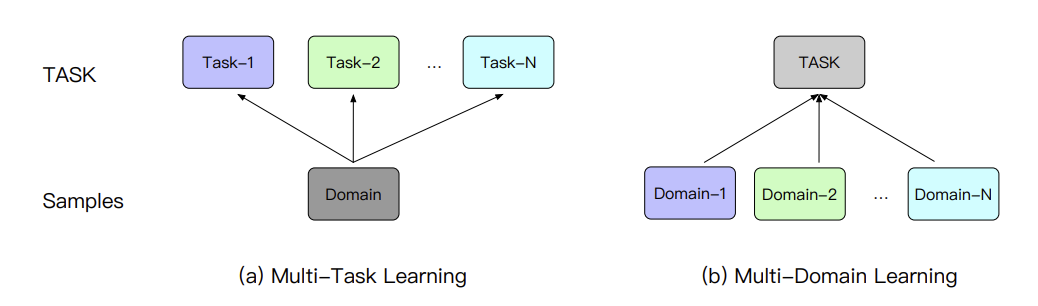
前面两篇文章,讲述了关于多场景的建模方案,其中可以看到很多关于多任务学习的影子,我们也介绍了两者的区别:
- 多任务学习通常是聚焦于单独一个domain(场景、领域)内的不同任务的处理,即不同任务的label空间是不同的;
- 而多场景建模则是关注于多个domain的同一个任务的建模,比如CTR,即不同场景的label空间是一样的,但数据分布是不同的。
然后,这两种在生产环境中其实是经常一起出现的,比如下面的场景,一个广告主可能会在多个场景下操作,并且会在这些场景下产生不同的行为,而模型便需要去预测广告主在对应场景下的多种行为,然后根据不同的行为去给他们提供不同的工具。

那么,今天这篇文章就在前面多场景建模的基础上,开启关于多场景多任务学习的扩展系列。
概述
Leaving No One Behind: A Multi-Scenario Multi-Task Meta Learning Approach for Advertiser Modeling
CIKM’22:https://arxiv.org/abs/2201.06814
这篇论文的业务场景与平常的用户点击率预估不同,不是针对用户建模,而是聚焦于广告主,目标在于理解广告主的需要和效果(performance),并且task是属于回归问题,但其实这两者的很多实践是互通,可以互相借鉴。
广告主建模通常涉及多种任务,比如预测广告主的消耗、活跃率和促销产品的曝光等等,并且电子商务平台往往提供多种营销场景,比如赞助搜索、展示广告和直播广告等,同时广告主在这些场景的行为是分散的。
这便催生了综合考虑多场景和多任务的广告主建模的必要性,但同时考虑多场景和多任务存在着一些挑战:
- 老生常谈的问题,每一个场景或者每一种任务单独建模,成本很高,难以扩展。即使是使用前面的多场景建模或者多任务学习,同样是存在这个问题的,因为仍然需要一个场景建模去一个多任务模型,或者一种任务去建模一个多场景模型
- 新的场景或者样本很少的小场景建模难度较高。对于小场景,样本数量很少很分散,难以训练一个可靠的模型,对新场景的预测存在更大的精度问题,因此如何迁移不同场景之间的信息,同时保持场景自己的特性便成了问题所在
- 场景间的多任务相关性是复杂的,难以精确捕获。给定一个任务,比如不同场景下的广告主的消耗,场景间的关联可能是正向、负向的,或者是没有关联的,更进一步,这些相关性还涉及多种任务,可能还会演变和变化。如下图:
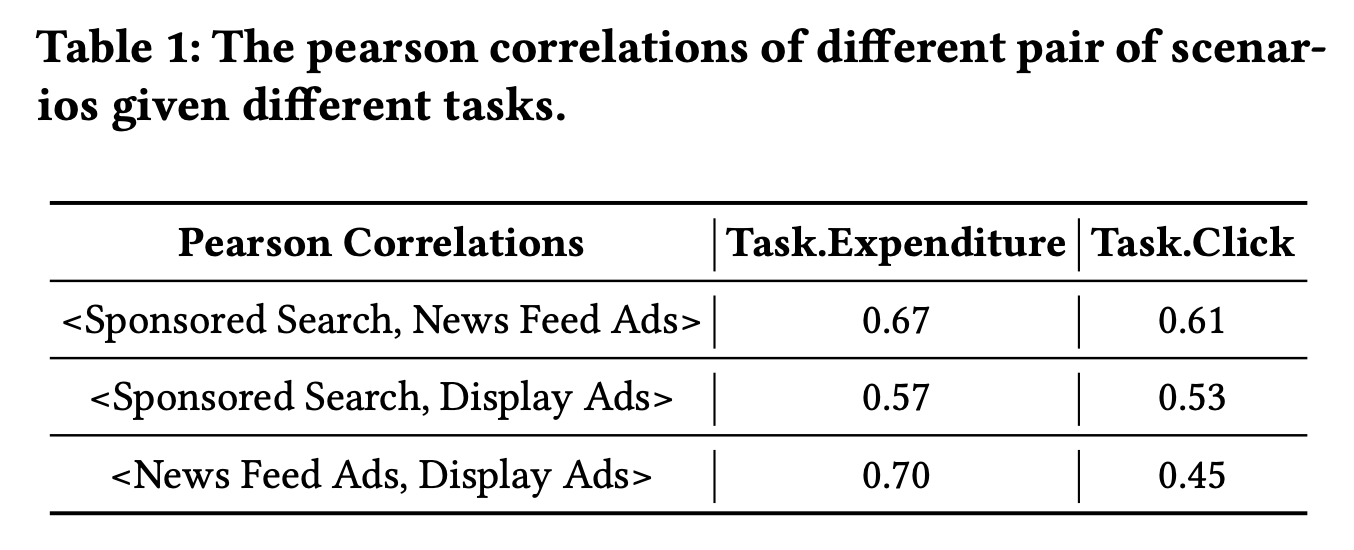
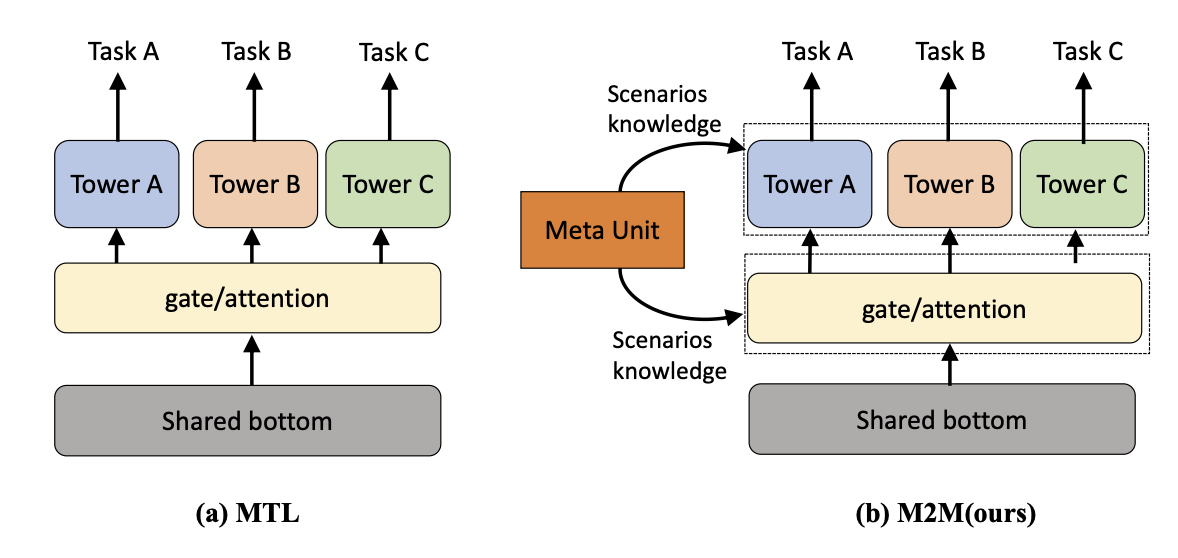
为了克服这些挑战,论文提出了M2M,一种多场景多任务的元学习模型,它的整体结构如下图所示:
- backbone network是来学习广告主相关的特征和任务特征的表征;
- 元学习机制包括一个元注意力层和一个元残差网络,分别来捕获复杂多样的场景间相关性和增强场景特定特征的表征能力
- 最后,还在多任务上使用了一种联合泊松损失(joint Poisson loss)来优化模型

这里的骨干网络(backbone network)是采用MTL的基础结构,多专家的门控/注意力机制,也就是M2M在MTL的基础下引入了元学习单元,如下图所示:
符号定义
- 场景属性集合: S = { s 1 , s 2 , . . . , s l } S=\{s_1,s_2,...,s_l\} S={s1,s2,...,sl},广告主在不同营销场景的场景相关信息
- 广告主画像集合: A = { a 1 , a 2 , . . . , a m } A=\{a_1,a_2,...,a_m\} A={a1,a2,...,am}
- 多类型的行为序列: X b = { X b t } t = 1 T X_b=\{X_b^t\}^T_{t=1} Xb={Xbt}t=1T,表示在一段时间T内的多种类型的行为信息, X b t = { x b 1 t , x b 2 t , . . . , x b m t } X_b^t=\{x^t_{b1},x^t_{b2},...,x^t_{bm}\} Xbt={xb1t,xb2t,...,xbmt} 表示在时间t广告主的特征
- 多类型的效果(performance)序列: X p = { X p t } t = 1 T X_p=\{X_p^t\}^T_{t=1} Xp={Xpt}t=1T,表示在一段时间T内的多种类型的执行信息, X p t = { x p 1 t , x p 2 t , . . . , x p m t } X_p^t=\{x^t_{p1},x^t_{p2},...,x^t_{pm}\} Xpt={xp1t,xp2t,...,xpmt} 表示在时间t广告主的特征
具体地可以参照下图:

1. Backbone Network
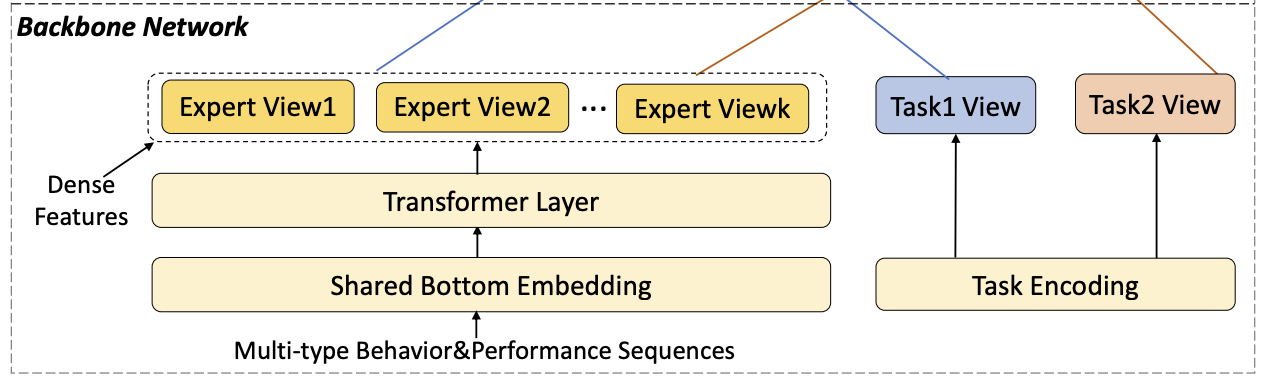
1.1 Shared Bottom Embedding.
这里还是常规做法,因为 { X b , X p } \{X_b,X_p\} {Xb,Xp} 包含连续值的特征,比如页面浏览、点击、消耗,第一步便是将这些连续值特征进行离散化,然后转化为高维的one-hot向量,接着使用embedding layer映射为低维的密集表征。
这样,每一个时间序列即每一个行为就对应得到了固定大小的低维向量,同时还加入位置embedding来捕获历史执行和行为序列的顺序或时间信息,但论文是将特征embedding与位置embedding进行拼接,而不是相加。
1.2 Transformer Layer.
上一步对特征映射到低维表征后,便使用transformer layer来学习每一个时间序列的更加深层次的表征,来捕获与其他时间序列的相关性,众所周知,相比于RNN和LSTM,transformer更高效和有效。
transformer layer仍然是常规的做法,由多个Self-attention Layer组成的multi-head self-attention。(论文的公式写错了,V是在softmax之后的)
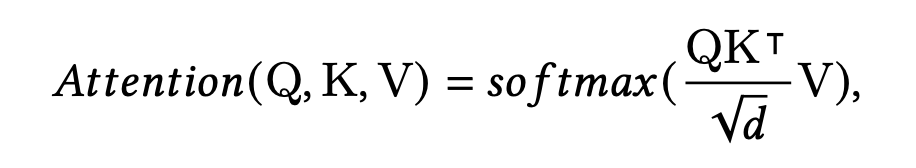
- Q,K,V分别表示输入embedding的query、key和value
- d为K的维度的缩放因子
- Q,K,V这三个矩阵是时间序列特征embedding的同等维度下的线性映射,如下式 h e a d i head_i headi
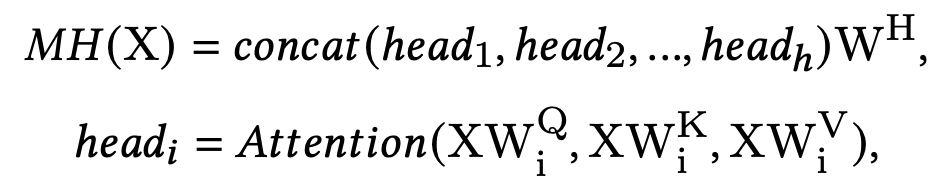
-
h是注意力头的数量
-
X为输入的时间序列特征embedding
-
W i Q , W i K , W i V W^Q_i,W^K_i,W^V_i WiQ,WiK,WiV 为上述提到的 h e a d i head_i headi 的Q,K,V线性映射的参数矩阵
-
并且,由于存在后面的Expert View Representation,transformer layer不加入额外的非线性单元
最后,将学习到行为序列和效果序列特征的表征进行拼接:
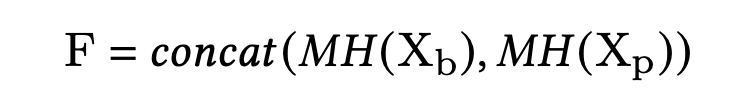
1.3 Expert View Representation.
经过transformer layer之后得到的序列特征表征会与其他特征表征进行拼接,然后输入到MMoE网络,构建拥有不同的共享表征的混合专家层:
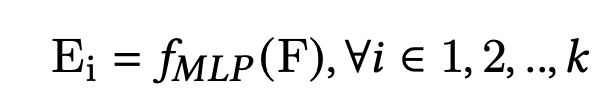
E i E_i Ei 是第i个专家的输出,k为专家的数量
1.4 Task View Representation.
除了embedding特征之外,论文还将所有task嵌入到相同的空间,扮演task的“锚点”来引入task的先验知识来影响特征信息的权重。由于没有在测试集中加入任何特定的label信息,因此提取的task表征是全局而非局部的。
具体地,将task信息的one-hot转换到低维的密集表征,然后输入到一个带有LeakyReLU激活函数的feed-forward layer:
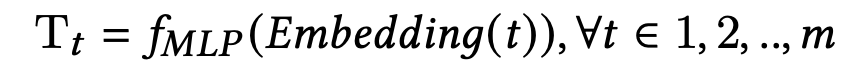
T t T_t Tt 是第t个task的锚点embedding,m是task的数量
1.5 Scenario Knowledge Representation.
场景知识表征是广告主的广告场景的知识表征,论文在这里不单使用广告主营销场景的属性,还加入广告主的画像信息,来更好地学习多任务,其表征层仍然是feed-forward layer:
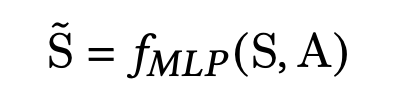
2. Meta Learning Mechanism
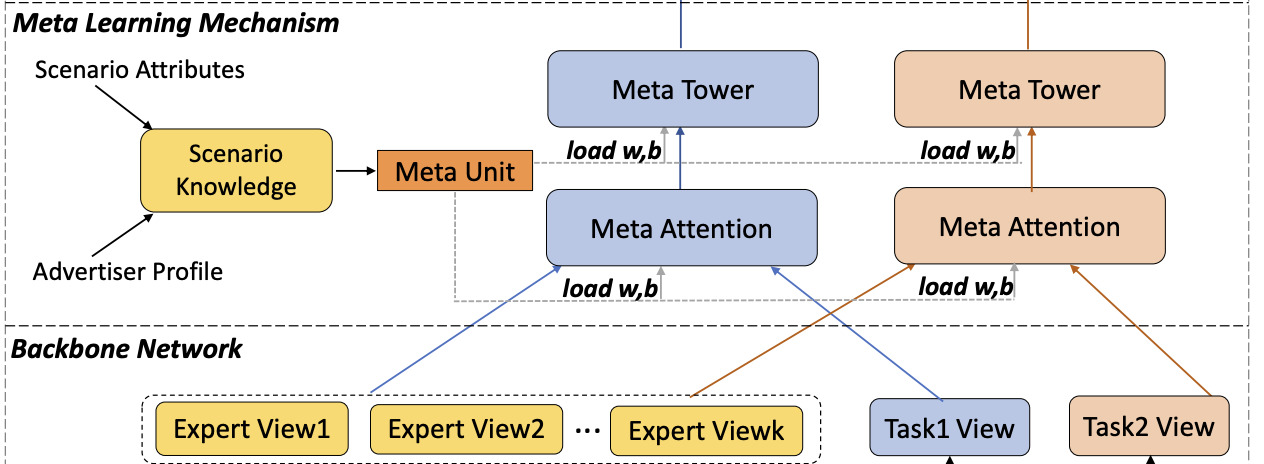
为了更好地从不同的序列特征中刻画场景特定的表征,论文提出了一种元学习机制,包含两个组件:
- 元注意力模块:meta attention module,放置在底层,来捕获多样的场景之间的关联
- 元残差塔模块:meta residual tower module,放置在上层,来增强捕获场景表征的能力
具体地,整个元学习机制架构如下图:
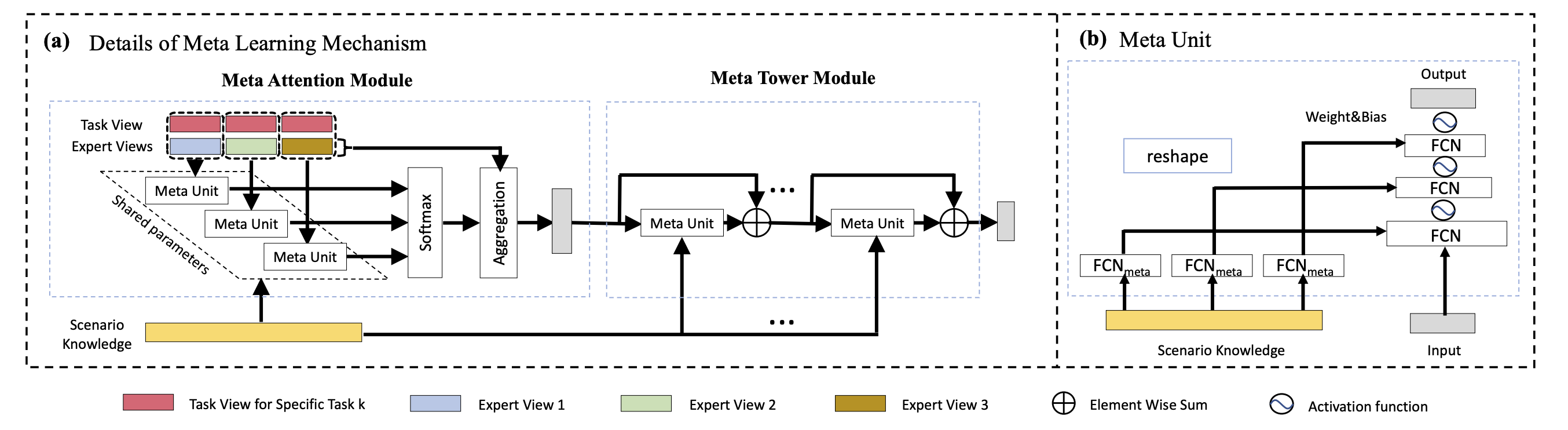
2.1 Meta Unit
在元学习机制中,Meta Unit是一个基础组件,充斥着整个元学习模块。
Meta Unit的作用是显式建模不同场景的相关信息。如上图[Meta Learning Mechanism]所示,使用场景知识 S ~ \tilde{S} S~作为输入,来更好地捕获场景间的关联。meta unit会将场景知识转换为动态的权重和偏置参数,用于后续的meta attention和meta tower,具体如下式:
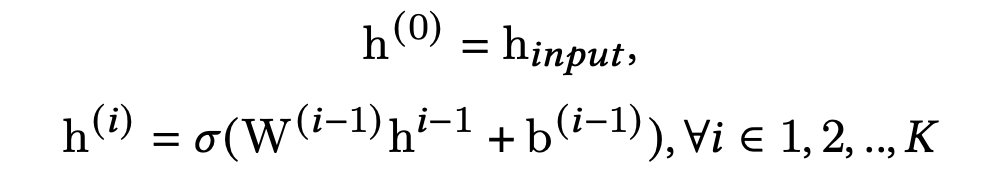
-
h i n p u t h_{input} hinput是d维的输入向量, σ \sigma σ是非线性激活函数,K是meta unit的层数
-
W ( i ) ∈ R d × d , b ( i ) ∈ R d W^{(i)} \in \mathcal{R}^{d \times d},b^{(i)} \in \mathcal{R}^d W(i)∈Rd×d,b(i)∈Rd 是projection参数,由场景知识生成,经过一层全连接网络,然后reshape改变维度得到,如下式:

最后,meta unit的输出可以使用 M e t a Meta Meta 函数来表示:

不同于常规的实现:将场景相关信息作为输入去建模,meta unit结合场景知识来为每个特定场景生成动态的参数权重,通过获得场景特定的表征,这种显式的建模方式,可以显著提升新场景或者小场景的表现。
2.2 Meta Attention Module
Meta Attention在元学习机制的底部,其目的在于为backbone network生成的多个专家特征学习不同的贡献权重。
直觉上来看,每一种task依赖于共享特征的不同部分,但是忽视场景因素,直接计算注意力分数是不准确的,因为不同场景的训练样本数量是不同的,并且对于某种特定的task,不同场景的数据分布可能是动态的,然而传统的注意力模块能够建模task和特征之间的关联,而场景特定的差异是被忽略的。
论文提出的meta attention致力于计算注意力分数的同时,能够捕获场景的信号,帮助注意力模块学习为不同的场景产生动态的注意力权重。
具体地,为了根据给定的场景相关信息来建模注意力分数的不同模式,论文在attention模块中加入了上一小节的meta unit:
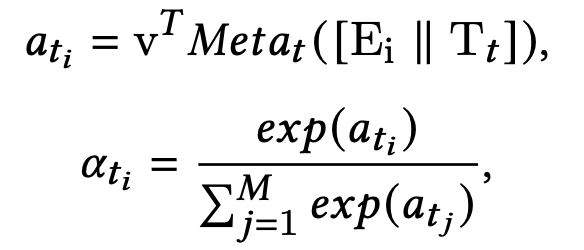
- E i , T t E_i,T_t Ei,Tt 分别是上一节中backbone network产出的专家特征表征向量和task锚点embedding,它们的维度分别是 d 1 d_1 d1和 d 2 d_2 d2
- 隐藏层向量 v ∈ R d 1 + d 2 v \in \mathcal{R}^{d_1+d_2} v∈Rd1+d2 将隐藏层向量映射为权重标量
最终的第t个task的表征 R t R_t Rt 便是由多个专家特征表征向量通过它们对应的注意力权重进行加权求和:
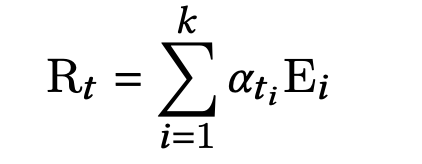
由于提取了场景知识,并且使用了这些信息去生成权重和偏置,因此meta attention模块不仅能够建模task和特征之间的相关性,也是具备捕获复杂的场景之间的关联的能力的。
2.3 Meta Tower Module
经过元注意力模块之后,获得聚合后的隐表征,M2M接着使用一个meta residual tower module来区分不同的场景,这个模块同样有着meta unit。
因为对于一个特定的task,特征模式会因场景而异,一个简单的共享feed-forward网络是无法有效捕获不同的场景信息,因此论文才引入了meta residual tower module:
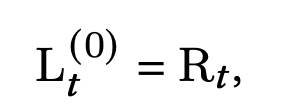
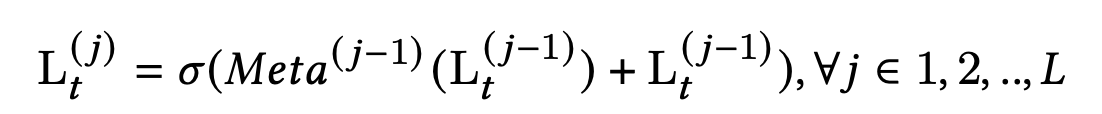
- R t R_t Rt 是上一个小节中第t个task的attention输出
- σ \sigma σ 是一个非线性激活函数
- L是残差网络的层数
3. Optimization
3.1 损失函数
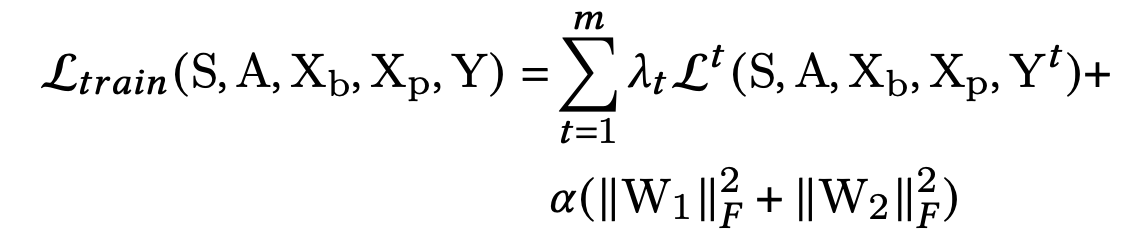
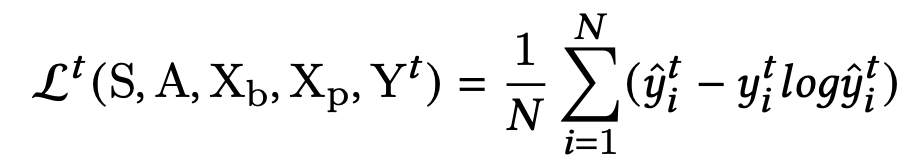
M2M的损失函数包括两部分:
- 第一部分是每个task的loss乘以权重 λ t \lambda_t λt,然后求和。loss使用了适用于labels服从泊松分布的Poisson Loss
- 第二部分是对 W 1 , W 2 W_1,W_2 W1,W2 的正则惩罚项, W 1 , W 2 W_1,W_2 W1,W2 分别指meta unit和其他网络的参数, α \alpha α 则表示正则惩罚项的权重
3.2 超参数
- 底层共享的embedding layer使用的维度为16
- transformer模块使用了2个注意力头
- feature views和task views表征的维度为256
- 全部激活函数都使用了LeakyReLU
- batch size为256,学习率为 2 × 1 0 − 3 2 \times 10^{-3} 2×10−3,Adam作为优化器,Adam的参数分别为: β 1 = 0.9 , β 2 = 0.998 , ε = 1 × 1 0 − 9 \beta_1=0.9,\beta_2=0.998,\varepsilon=1 \times 10^{-9} β1=0.9,β2=0.998,ε=1×10−9
- 梯度裁剪范围为:[3, -3],训练了10轮
3.3 metrics
常规的回归问题通常使用MAPE (Mean Absolute Percentage Error)来评估微观的平均效果,NMAE (Normalized Mean Absolute Error)来评估宏观的平均效果,但是部分task,比如曝光和点击等,会出现不可计算的MAPE,因此使用SMAPE (Symmetric Mean Absolute Percentage Error)来代替MAPE:
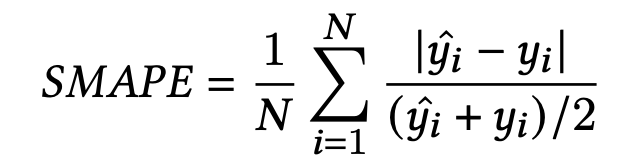
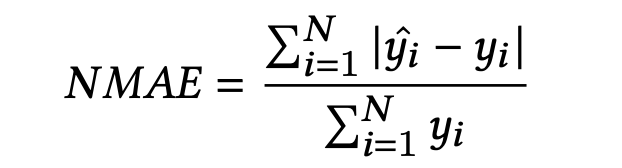
- N是广告主的数量, y ^ i , y i \hat{y}_i,y_i y^i,yi分别是第i个广告主的预估和真实标签。
实验结果
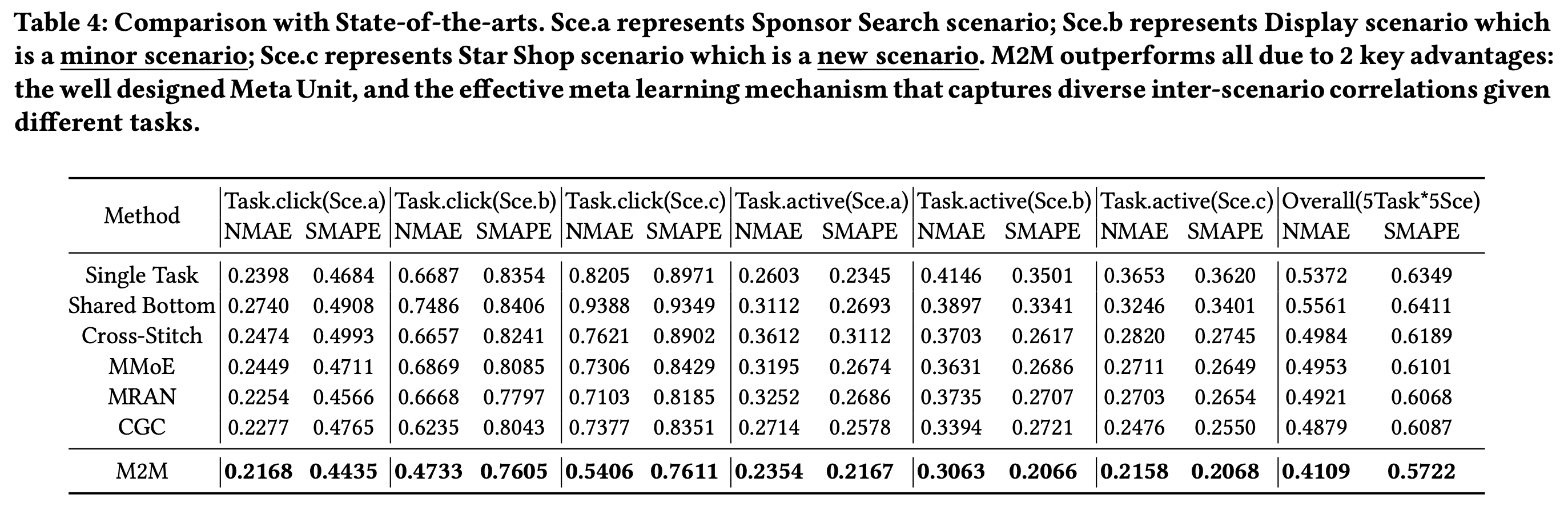
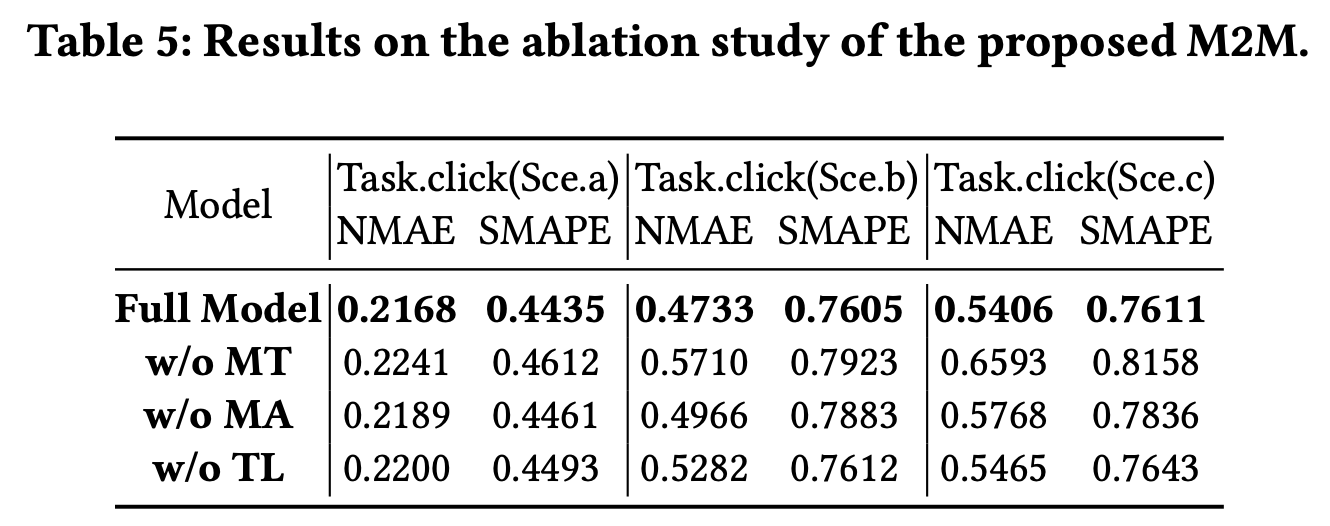


总结
M2M是针对多任务多场景业务而提出的框架,能够建模不同task与特征的关联的同时,引入场景知识来捕获场景间的关联:
1、底层的backbone network采用MTL结构+transformer layer
2、M2M提出了应对多任务多场景的高效的元学习机制:
- meta unit作为其中的基础组件,为不同场景产生动态的参数
- meta attention模块注入场景知识(meta unit)来为task计算不同场景下的多个experts的注意力分数
- meta tower模块为特定task进一步特征交叉的同时加入场景知识(meta unit)
3、可以应用于存在多种不同类型行为序列的场景,如论文中针对广告主的两种序列:登录、投标等行为序列以及GMV、RIO等效果序列
4、另外,发现论文对transformer layer后的序列embeddings聚合方式没有提及;并且在meta unit中,为了计算场景动态权重 W ( i ) ∈ R d × d W^{(i)} \in \mathcal{R}^{d \times d} W(i)∈Rd×d,需要的参数矩阵 V w V_w Vw 是 O ( N 3 ) O(N^3) O(N3) 级别的: d S ~ × ( d E × d E ) d^{\tilde{S}} \times (d^{E} \times d^{E}) dS~×(dE×dE),参数量是比较大的。
代码实现
transformer layer后的序列embeddings聚合方式:使用 S ~ \tilde{S} S~ 去做一个target attention,即 S ~ \tilde{S} S~作为Q,序列embeddings作为K和V。
recommendation/multidomain/m2m.py