前言
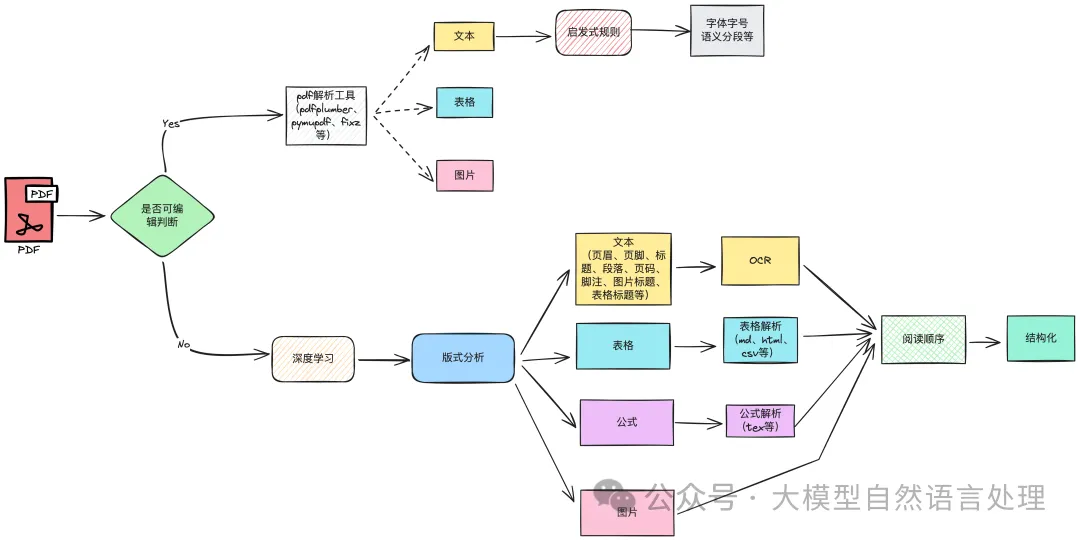
OCR技术作为文档智能解析链路中的核心组件之一,贯穿整个技术链路,包括:文字识别、表格文字识别、公式识别,参看下面这张架构图:
前期介绍了很多关于文档智能解析相关核心技术及思路,本着连载的目的,本次迎来介绍整个链路中的最后一块拼图-OCR。本文简要介绍OCR常见落地的算法模型-DBNet、CRNN,并基于这两个模型,简单介绍文字识别在表格识别中参与的角色;并且额外介绍TrOCR这个端到端的模型,基于这个模型引入公式识别解析的思路及微调方法。
DBNet
DBNet是一种基于分割的文本检测算法,算法将可微分二值化模块(Differentiable Binarization)引入了分割模型,使得模型能够通过自适应的阈值图进行二值化,并且自适应阈值图可以计算损失,能够在模型训练过程中起到辅助效果优化的效果。DBNet在效果和性能上都有比较大的优势,是目前最常用的文本检测算法之一。
模型结构
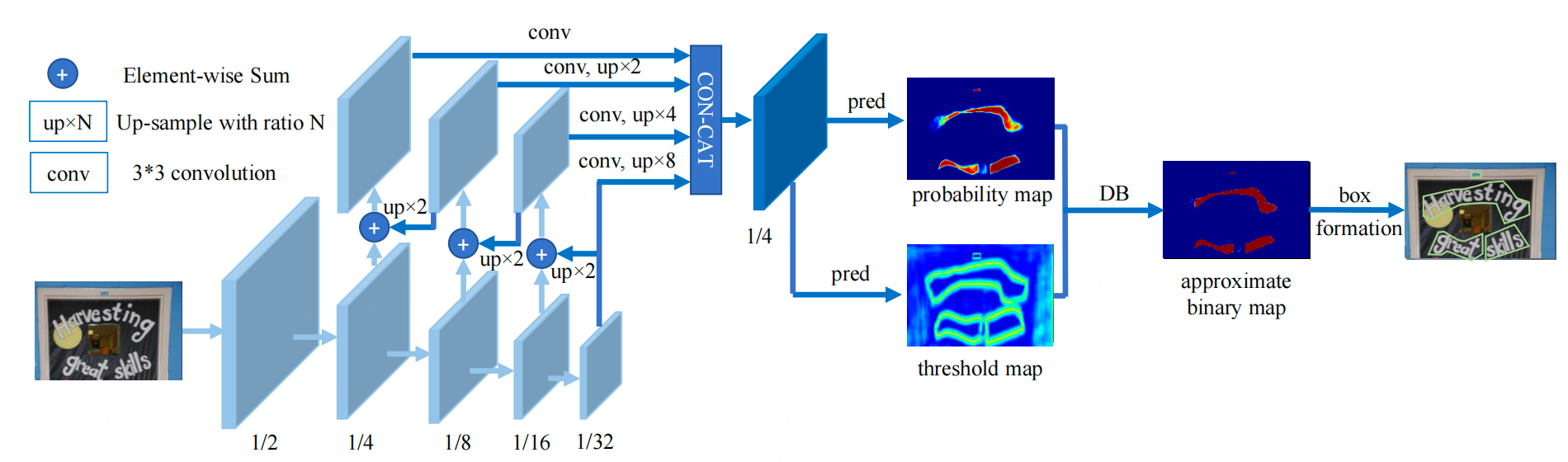
DB文本检测模型由三个部分组成:Backbone网络、FPN网络、Head网络
- Backbone网络
负责提取图像的特征。Backbone部分采用的是图像分类网络,论文中分别使用了ResNet50和ResNet18网络。输入图像[1,3,640, 640] ,进入Backbone网络,先经过一次卷积计算尺寸变为原来的1/2, 而后经过四次下采样,输出四个尺度特征图:
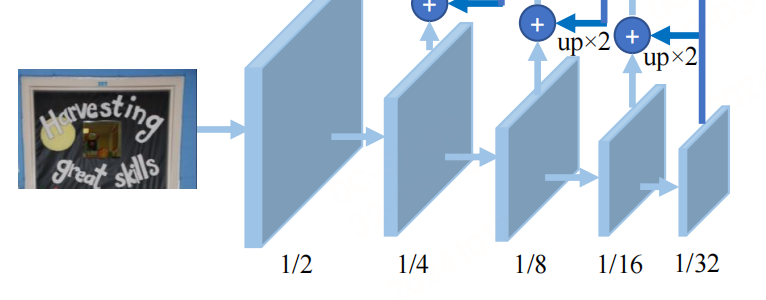
- FPN网络
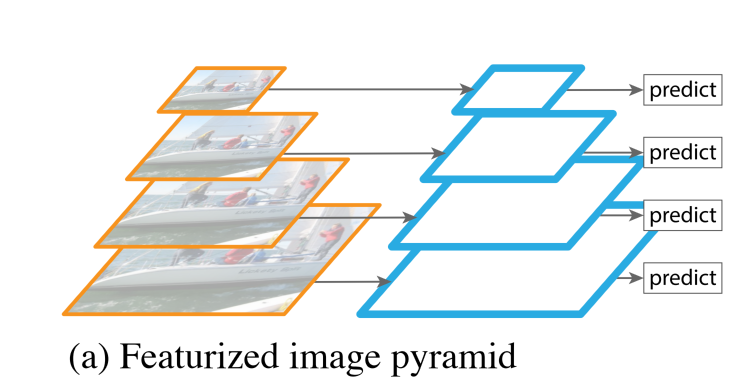
特征金子塔,Featurized image pyramid。负责结构增强特征。特征金字塔结构FPN是一种卷积网络来高效提取图片中各维度特征的常用方法。FPN网络的输入为Backbone部分的输出,经FPN计算后输出的特征图的高度和宽度为原图的1/4, 即[1, 256, 160, 160] 。
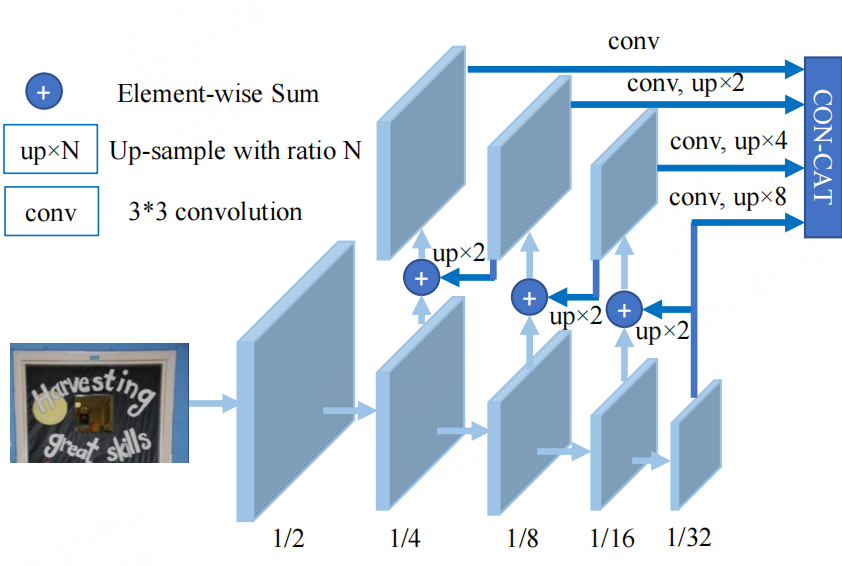
DBNet中FPN特征提取融合过程:
- 1/32特征图: [1, N, 20, 20] ===> 卷积 + 8倍上采样 ===> [1, 64, 160, 160]
- 1/16特征图:[1, N, 40, 40] ===> 加1/32特征图的两倍上采样 ===> 新1/16特征图 ==> 卷积 + 4倍上采样 ===> [1, 64, 160, 160]
- 1/8特征图:[1, N, 80, 80] ===> 加新1/16特征图的两倍上采样 ===>新1/8特征图 ===> 卷积 + 2倍上采样 ===> [1, 64, 160, 160]
- 1/4特征图:[1, N, 160, 160] ===> 加新1/8特征图的两倍上采样 ===> 新1/4特征图 ===> 卷积 ===> [1, 64, 160, 160]
- 融合特征图:[1, 256, 160, 160] # 将1/4,1/8, 1/16, 1/32特征图按通道层合并在一起
- Head网络
负责计算文本区域概率图的 Head 网络,基于 FPN 特征进行上采样,将 FPN 特征从原来的 1/4 尺寸映射回原图尺寸。最终,Head 网络会生成文本区域概率图、文本区域阈值图,并将这些图合并,得到一个输出大小为 [1, 3, 640, 640] 的结果。
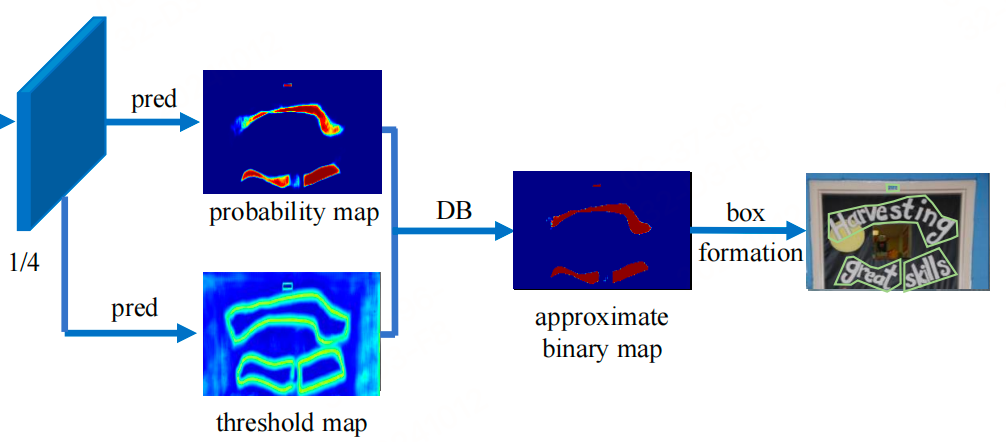
标签生成
DB算法在进行模型训练的时,需要根据标注框生成两幅图像:概率图和阈值图。生成过程如下图所示:
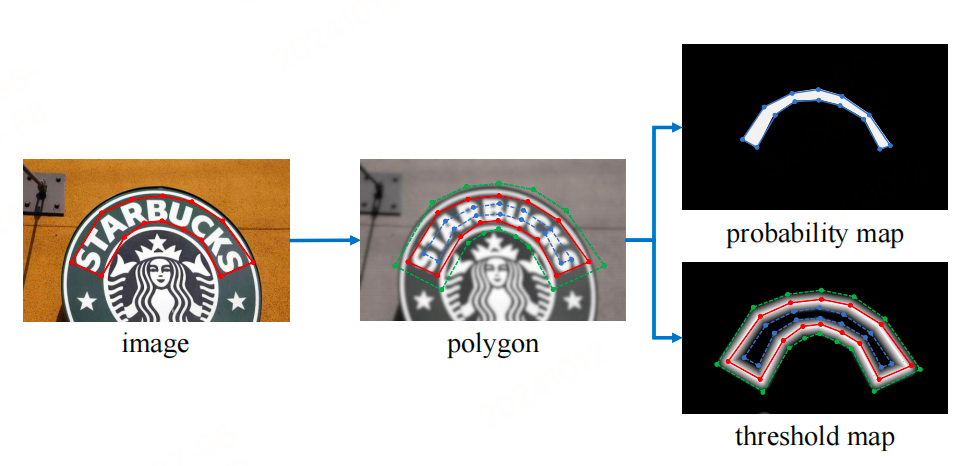
image图像中的红线是文本的标注框,文本标注框的点集合用如下形式表示:
G = { S k } k = 1 n G=\{S_k\}_{k=1}^n G={Sk}k=1n
其中,n表示顶点的数量。
1.概率图标签$ G_s $
在polygon图像中,将红色的标注框外扩distance得到绿色的polygon框,内缩distance得到蓝色的polygon框。论文中标注框内缩和外扩使用相同的distance,其计算公式为:
D = A ( 1 − r 2 ) L D=\frac{A(1-r^2)}L D=LA(1−r2)
L代表周长,A代表面积,r代表缩放比例,通常r=0.4
多边形轮廓的周长L和面积A通过Polygon库计算获得。

得到上述效果简单示例:
code ref:https://blog.csdn.net/yewumeng123/article/details/127503815
import cv2
import pyclipper
import numpy as np
from shapely.geometry import Polygondef draw_img(subject, canvas, color=(255,0,0)):"""作图函数"""for i in range(len(subject)):j = (i+1)%len(subject)cv2.line(canvas, subject[i], subject[j], color)# 论文默认shrink值
r=0.4
# 假定标注框
subject = ((100, 100), (250, 100), (250, 200), (100, 200))
# 创建Polygon对象
polygon = Polygon(subject)
# 计算偏置distance
distance = polygon.area*(1-np.power(r, 2))/polygon.length
print(distance)
# 25.2# 创建PyclipperOffset对象
padding = pyclipper.PyclipperOffset()
# 向ClipperOffset对象添加一个路径用来准备偏置
# padding.AddPath(subject, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
# adding.AddPath(subject, pyclipper.JT_SQUARE, pyclipper.ET_CLOSEDPOLYGON)
padding.AddPath(subject, pyclipper.JT_MITER, pyclipper.ET_CLOSEDPOLYGON)# polygon外扩
polygon_expand = padding.Execute(distance)[0]
polygon_expand = [tuple(l) for l in polygon_expand]
print(polygon_expand)
# [(75, 75), (275, 75), (275, 225), (75, 225)]
# polygon内缩
polygon_shrink = padding.Execute(-distance)[0]
polygon_shrink = [tuple(l) for l in polygon_shrink]
print(polygon_shrink)
# [(125, 125), (225, 125), (225, 175), (125, 175)]# 作图
canvas = np.zeros((300,350,3), dtype=np.uint8)
# 原轮廓用红色线条展示
draw_img(subject, canvas, color=(0,0,255))
# 外扩轮廓用绿色线条展示
draw_img(polygon_expand, canvas, color=(0,255,0))
# 内缩轮廓用蓝色线条展示
draw_img(polygon_shrink, canvas, color=(255,0,0))cv2.imshow("Canvas", canvas)
cv2.waitKey(0)2.阈值图标签$ G_d $
通过类似的过程,为阈值图生成标签。在 DBNet 中,阈值图标签的生成过程可以概述如下:
-
多边形文字区域扩张与收缩:首先,将原始的多边形文字区域 $ G $ 进行扩张,得到扩张后的区域 $ G_d $(绿线表示)。同时,将文字区域以偏移量 $ D $ 为标准进行收缩,得到收缩后的区域 $ G_s $(蓝线表示)。其中,偏移量 $ D $ 与概率图中的偏移量相同。
-
边界区域定义:收缩区域 $ G_s $ 和扩张区域 $ G_d $ 之间的间隙被视为文本区域的边界。在这个边界区域内,计算每个像素点到原始文字区域边界$ G $(红线表示)的归一化距离。这个距离是通过找到该像素点到最近的 $ G $ 边界线段的距离来计算的。
-
归一化处理:
- 计算得到的归一化距离显示出:扩张框 $ G_d $ 和收缩框$G_s $ 上的像素点距离值最大,而原始边界 $ G $ 上的距离值最小(为 0)。
- 随着从 $ G $ 向 $ G_s $ 和 $ G_d $移动,距离值逐渐变大。
-
距离转换与二次归一化:
- 计算完距离后,对这些距离值进行归一化,即除以偏移量 $ D ,此时, ,此时, ,此时, G_s $ 和 $ G_d $ 上的距离值均变为 1,而 $ G $ 上的值为 0,表现为以 $ G $ 为中心向 $ G_s $ 和 $ G_d $ 两侧的距离逐渐减小。
- 接着,对这些归一化值再进行一次变换,使用 $ 1 $ 减去这些距离值,最终得到:$ G $ 上的值为 1,$ G_s $ 和 $ G_d $ 上的值为 0。这样,$ G_s $ 和 $ G_d $ 区域内的像素值范围变为 [0, 1]。
-
最终标签生成:在完成上述操作后,我们再次对这些值进行归一化,得到像 [0.2, 0.8] 等不同范围的标签值。最终,这些值将作为阈值图的标签,帮助模型更好地学习文本区域与边界之间的精确关系。
通过该过程生成的阈值图标签,结合 DBNet 的差分二值化策略,能够有效提升文本检测的边界处理能力。
损失函数
损失函数为概率图的损失 L s L_s Ls 、二值化图的损失 L b L_b Lb和阈值图的损失 L t L_t Lt的和:
L = L s + α × L b + β × L t L=L_s+\alpha\times L_b+\beta\times L_t L=Ls+α×Lb+β×Lt
采用BCE Loss,为平衡正负样本的比例,使用OHEM进行困难样本挖掘,正样本:负样本=1:3:
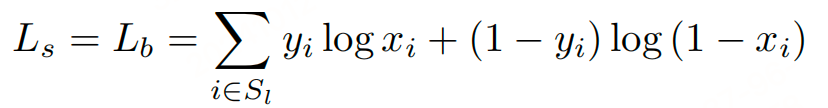
损失函数代码ref:https://github.com/MhLiao/DB/blob/master/decoders/seg_detector_loss.py
文本识别算法-CRNN
模型包括三个部分,分别称作卷积层、循环层以及转录层。
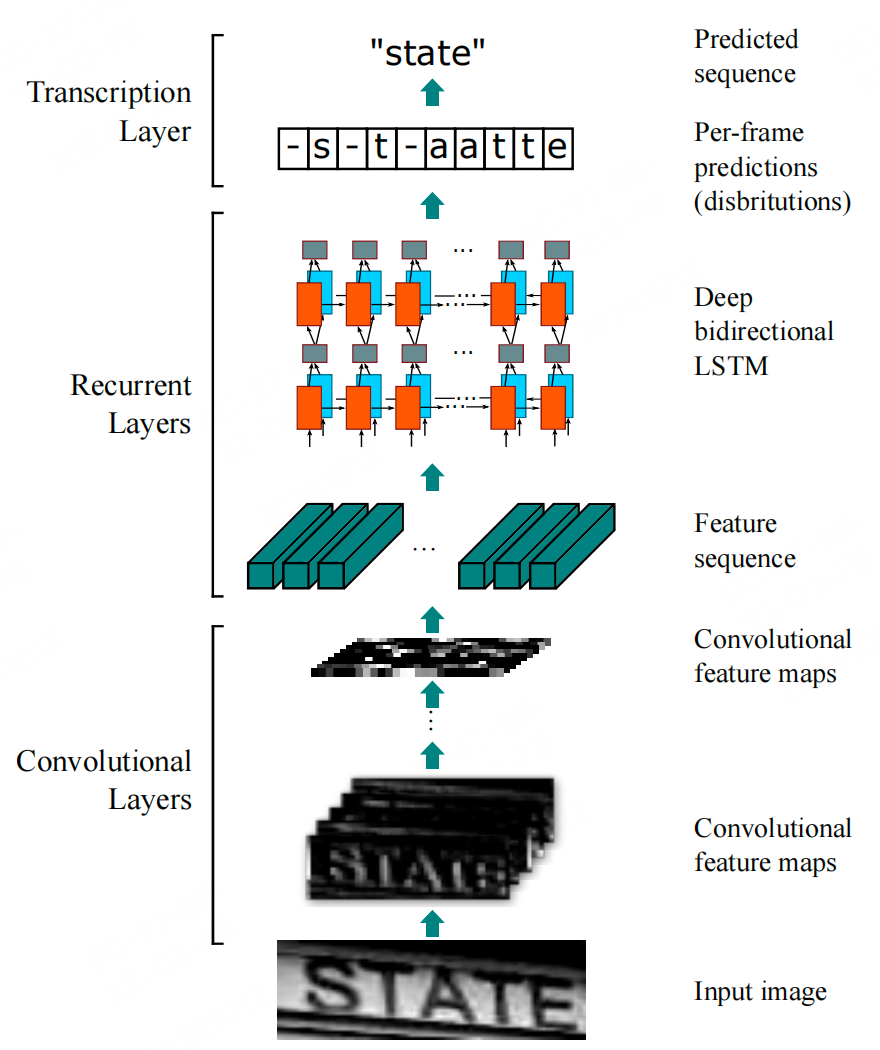
卷积层由CNN构成,它的作用是从输入的图像中提取特征。提取的特征图将会输入到接下来的循环层中,循环层由RNN构成,它将输出对特征序列每一帧的预测。最后转录层将得到的预测概率分布转换成标记序列,得到最终的识别结果,它实际上就是模型中的损失函数。通过最小化损失函数,训练由CNN和RNN组成的网络。
1.卷积层
CRNN模型中的卷积层由一系列的卷积层、池化层、BN层构造而成。就像其他的CNN模型一样,它将输入的图片转化为具有特征信息的特征图,作为后面循环层的输入。当然,为了使提取的特征图尺寸相同,输入的图像事先要缩放到固定的大小。
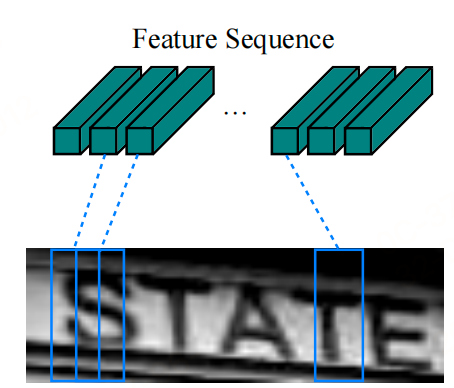
由于卷积神经网络中卷积层和最大池化层的存在,使其具有平移不变性的特点。卷积神经网络中的感受野指的是经过卷积层输出的特征图中每个像素对应的原输入图像区域的大小,它与特征图上的像素从左到右,从上到下是一一对应的,如下图所示。因此,可以将特征图作为图像特征的表示。
2.循环层
在CRNN(Convolutional Recurrent Neural Network)模型中,循环层通常位于卷积层(Convolutional Layers)之后,用于处理卷积层提取的特征序列。
作用:
- 捕捉序列中的上下文信息:循环层能够记住之前处理过的信息,并利用这些信息来辅助当前的预测任务。
- 处理任意长度的序列:与卷积神经网络(CNN)不同,循环层可以处理变长的序列数据,因为它们可以逐个时间点地处理输入。
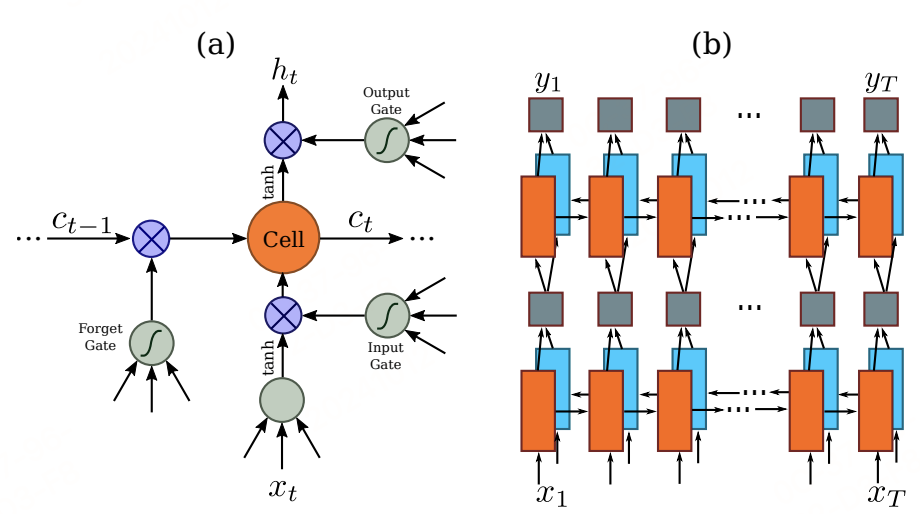
3.转录层
转录层的作用是将前面通过CNN层和RNN层得到的预测序列转换成标记序列,得到最终的识别结果。简单来说,就是选取预测序列中每个分量中概率最大的索引对应的符号作为识别结果,最终组成序列作为最终的识别序列。CRNN转录算法使用的是CTC算法,涉及原理可以自行查阅。
端到端的文本识别模型-TrOCR
TrOCR使用Transformer架构构建,包括用于提取视觉特征的图像Transformer和用于语言建模的文本Transformer。在TrOCR中采用了普通的Transformer编码器-解码器结构。编码器被设计为获得图像块的表示,而解码器被设计为在视觉特征和先前预测的指导下生成单词片段序列。
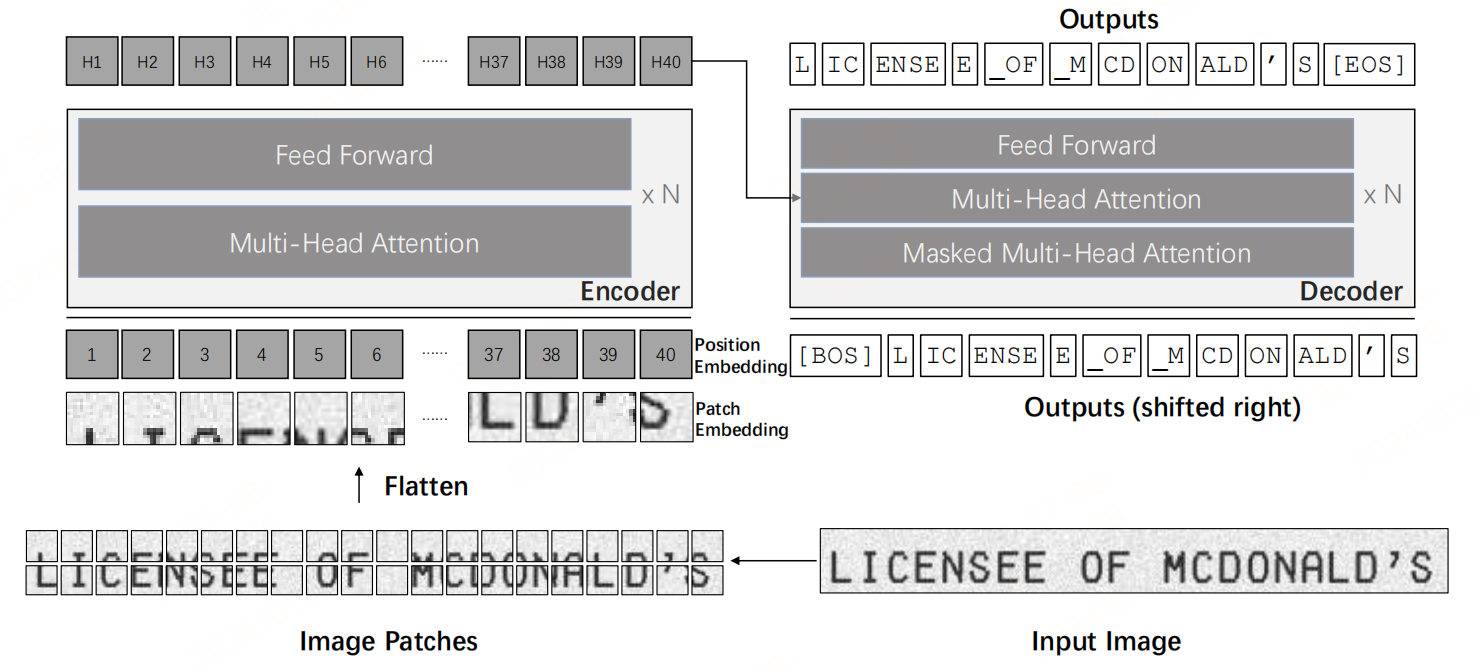
1.编码器
编码器接收输入图像 P 3 × H 0 × W 0 \mathfrak{P}^{3\times H_0\times W_0} P3×H0×W0,并将其大小调整为固定大小(H,W)。由于Transformer编码
器无法处理原始图像,除非它们是一系列输入tokens,因此编码器将输入图像分解为一批
N = H W / P 2 N=HW/P^2 N=HW/P2个固定大小为 (P,P) 的正方形patches,同时保证调整大小的图像的宽度W和
高度H可被patch大小P整除,将patches展平为向量并线性投影到D维向量,即patch
embeddings。D是Transformer在其所有层中的隐藏尺寸。
与ViT 和DeiT类似,论文保留了通常用于图像分类任务的特殊标记"[CLS]“。”[CLS]"标记将来自所有patch embeddings的所有信息汇集在一起,并表示整个图像。同时,当使用DeiT预训练模型进行编码器初始化时,论文还将蒸馏token保持在输入序列中,这允许模型从教师模型学习。patch embeddings和两个特殊tokens根据其绝对位置被赋予可学习的1D位置嵌入。
2.解码器
使用TrOCR的原始Transformer解码器。标准Transformer解码器也有一个相同的层堆栈,其结构与编码器中的层相似,只是解码器在多头自注意力和前馈网络之间插入“encoder-decoder attention”,以在编码器的输出上分配不同的关注。在编码器-解码器注意模块中,键(K)和值(V)来自编码器输出,而查询(Q)来自解码器输入。此外,解码器利用自注意力中的注意力掩码来防止自己在训练期间获得未来的信息。基于解码器的输出将从解码器的输入向右移位一个位置,注意力掩码需要确保位置i的输出只和先前的输出相关,即小于i的位置上的输入:
h i = P r o j ( E m b ( T o k e n i ) ) h_i=\mathrm{Proj}(\mathrm{Emb}(\mathrm{~Token~}_i)) hi=Proj(Emb( Token i))
σ ( h i j ) = e h i j ∑ k = 1 V e h i k f o r j = 1 , 2 , … , V \\\sigma\left(h_{ij}\right)=\frac{e^{h_{ij}}}{\sum_{k=1}^Ve^{h_{ik}}}\quad\mathrm{for~}j=1,2,\ldots ,V σ(hij)=∑k=1Vehikehijfor j=1,2,…,V
来自解码器的隐藏状态通过线性层从模型维度投影到词汇大小V的维度,而词汇上的概率通过softmax函数计算。使用beam search来获得最终输出。
性能效果
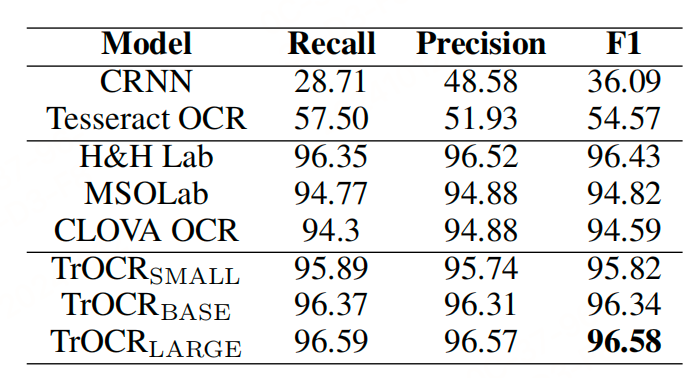
微调
- 数据处理,helper.py
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import Dataset
from PIL import Image
from transformers import TrOCRProcessordf = pd.read_csv('dataset/tex.csv')train_df, test_df = train_test_split(df, test_size=0.1, shuffle=True, random_state=42)
# we reset the indices to start from zero
train_df.reset_index(drop=True, inplace=True)
test_df.reset_index(drop=True, inplace=True)model_path = 'microsoft/trocr-base-stage1'class IAMDataset(Dataset):def __init__(self, root_dir, df, processor, max_target_length=512):self.root_dir = root_dirself.df = dfself.processor = processorself.max_target_length = max_target_lengthdef __len__(self):return len(self.df)def __getitem__(self, idx):# get file name + textfile_name = self.df['file_name'][idx]text = self.df['text'][idx]# prepare image (i.e. resize + normalize)image = Image.open(self.root_dir + file_name).convert("RGB")pixel_values = self.processor(image, return_tensors="pt").pixel_values# add labels (input_ids) by encoding the textlabels = self.processor.tokenizer(text,padding="max_length",max_length=self.max_target_length,truncation=True).input_ids# important: make sure that PAD tokens are ignored by the loss functionlabels = [label if label != self.processor.tokenizer.pad_token_id else -100 for label in labels]encoding = {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}return encodingprocessor = TrOCRProcessor.from_pretrained(model_path)
train_dataset = IAMDataset(root_dir='./dataset/trainning_set/',df=train_df,processor=processor,max_target_length=512)
eval_dataset = IAMDataset(root_dir='./dataset/trainning_set/',df=test_df,processor=processor,max_target_length=512)print("Number of training examples:", len(train_dataset))
print("Number of validation examples:", len(eval_dataset))
- train.py
from helper import *from transformers import VisionEncoderDecoderModelmodel = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-stage1")# set special tokens used for creating the decoder_input_ids from the labels
model.config.decoder_start_token_id = processor.tokenizer.cls_token_id
model.config.pad_token_id = processor.tokenizer.pad_token_id
# make sure vocab size is set correctly
model.config.vocab_size = model.config.decoder.vocab_size# set beam search parameters
model.config.eos_token_id = processor.tokenizer.sep_token_id
model.config.max_length = 64
model.config.early_stopping = True
model.config.no_repeat_ngram_size = 3
model.config.length_penalty = 2.0
model.config.num_beams = 4from transformers import Seq2SeqTrainer, Seq2SeqTrainingArgumentstraining_args = Seq2SeqTrainingArguments(predict_with_generate=True,evaluation_strategy="steps",per_device_train_batch_size=8,per_device_eval_batch_size=8,fp16=True,output_dir="./",logging_steps=2,save_steps=1000,eval_steps=200,
)from datasets import load_metriccer_metric = load_metric("cer")def compute_metrics(pred):labels_ids = pred.label_idspred_ids = pred.predictionspred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_idlabel_str = processor.batch_decode(labels_ids, skip_special_tokens=True)cer = cer_metric.compute(predictions=pred_str, references=label_str)return {"cer": cer}from transformers import default_data_collator# instantiate trainer
trainer = Seq2SeqTrainer(model=model,tokenizer=processor.feature_extractor,args=training_args,compute_metrics=compute_metrics,train_dataset=train_dataset,eval_dataset=eval_dataset,data_collator=default_data_collator,
)
trainer.train()应用思路
1.文字识别在表格识别中的角色
表格识别主要包含三个模型
- 单行文本检测-DB
- 单行文本识别-CRNN
- 表格结构和cell坐标预测-SLANet(《【文档智能】轻量级级表格识别算法模型-SLANet》)
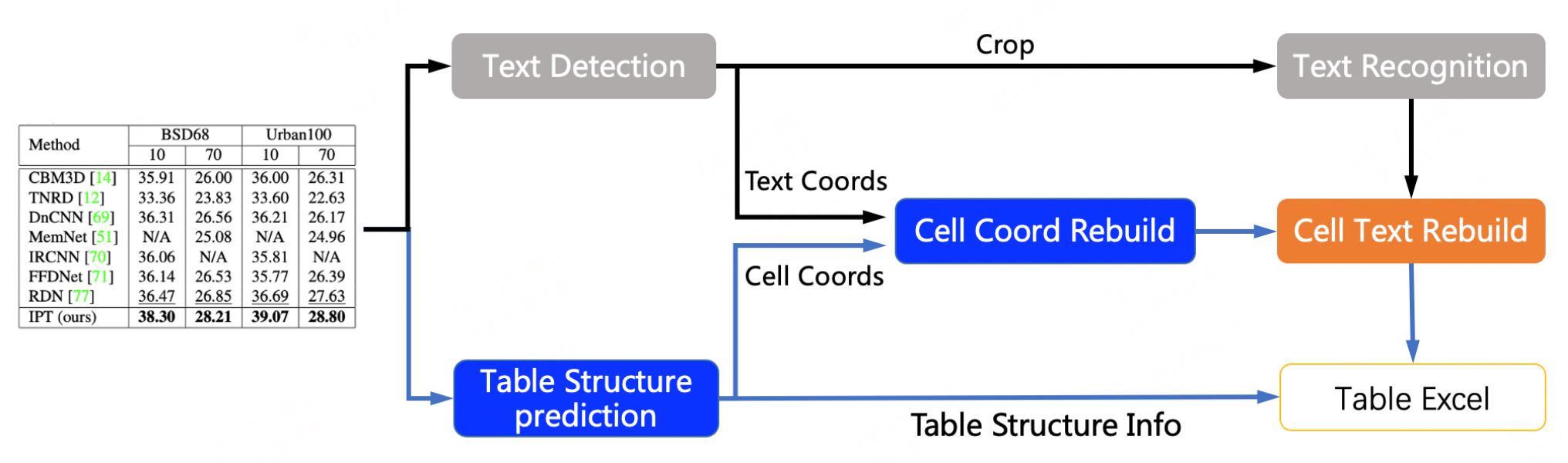
流程说明:
- 图片由单行文字检测模型检测到单行文字的坐标,然后送入识别模型拿到识别结果。
- 图片由SLANet模型拿到表格的结构信息和单元格的坐标信息。
- 由单行文字的坐标、识别结果和单元格的坐标一起组合出单元格的识别结果。
- 单元格的识别结果和表格结构一起构造表格的html字符串。
2.TrOCR公式识别微调后效果
通过微调TrOCR模型,端到端的得到公式latex格式字符串。
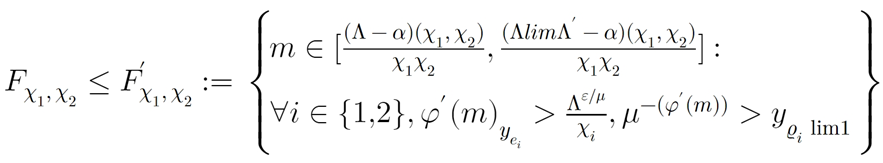

参考文献
- Real-time Scene Text Detection with Differentiable Binarization,https://arxiv.org/pdf/1911.08947
- An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition,https://arxiv.org/pdf/1507.05717
- TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models,https://arxiv.org/pdf/2109.10282
- https://github.com/PaddlePaddle/PaddleOCR