FaceFusion 是一种利用人工智能技术将两张或多张人脸融合在一起的图像处理技术。这种技术通过面部特征的识别和重构,将不同的人脸混合成一张新的脸,生成的图像看起来像是这些人脸的融合体。
FaceFusion使用深度学习算法,来捕捉人脸的细节和特征,并确保融合后的图像保持逼真和自然。FaceFusion 技术可用于多种应用场景,比如娱乐(生成混合脸型的趣味照片)、艺术创作、甚至身份保护和隐私遮盖等。
重要的是,Facefusion不仅支持图片换脸,还能处理视频文件,实现动态的面部替换。
3
获取方法
关注wēi xìn gōng zhòng hào :小言Ai工具箱,回复【facefusion】关键字获取整合包下载链接。
无需自己安装和部署,下载即用
使用教程
解压整合包,双击 start.exe

进入CMD界面,稍等待一段时间。

待程序打开后出现如下主界面:

先简单介绍下一些常用的设置。
帧处理器

这里有六个选项:
-
face_swapper(换脸模式)必须勾选的,不然无法进行换脸。 -
face_debugger(调试模式)用来开启遮罩时调试用的。正常换脸时不需要勾选。 -
face_enhancer(脸部增强)比较常用,开启后可以提升转换后的视频中人物面部的清晰度。 -
frame_enhancer(画面增强)比较常用,开启后可以提升转换后的视频整体清晰度。(此选项会大大增加处理时间,根据你的硬件酌情勾选)。 -
frame_colorizer(着色器)对视频的单帧进行自动上色。 -
lip_syncer(对口型)实现嘴唇与音频或语音同步。
人脸交换器模型

下拉选择换脸模型:
-
inswapper_128和inswapper_128_fp16
默认选择为
inswapper_128_fp16,该模型已能有效应对绝大多数换脸场景。此处的“128”表示处理图像的分辨率为 128x128 像素,而“fp16”则指该模型采用 16 位浮点数(FP16)进行计算。这种计算方式通常在保持足够精度的同时,显著降低计算资源的需求,从而提高处理速度,尤其适用于资源有限或需要实时处理的应用场景。 -
blendswap_256
该模型主要用于将两张图像中的面部进行混合与交换操作,其中“256”表示图像处理或输出的分辨率为256x256像素。此分辨率较适合处理较小的图像,并能够满足对处理速度要求较高的应用场景。
-
simswap_256
这个模型采用了相似性交换算法,
256指的是模型处理的分辨率为256x256像素。这种模型在保持原图像质量的同时,能够实现高质量的面部交换效果。 -
simswap_512_unofficial
该模型与
simswap_256类似,但“512”表明该版本支持更高的分辨率,即512x512像素,能够生成更高清晰度的面部交换结果。“unofficial”意味着该版本并非官方发布,而是由社区成员基于原始模型进行的修改或扩展。 -
Uniface_256
这个模型以256维度的特征向量表示人脸特征,能够在不同角度、光照和姿势下对人脸进行准确识别。相比一些更复杂的人脸识别模型,
Uniface_256在保持较高识别率的同时,计算效率较高,适合嵌入到需要快速处理的大规模系统中。根据具体项目需求选择合适的模型非常关键。使用16位浮点数(如
inswapper_128_fp16)是一种优化策略,能够在不显著影响输出质量的情况下加速模型运行。而更高的分辨率(如simswap_512)则可以提供更丰富的细节表现,但相应地也会消耗更多的计算资源和处理时间。运行模式选择

-
此处提供了三个选项:如果您使用NVIDIA显卡,请选择Cuda;如果您使用AMD显卡或集成显卡,请选择CPU。
执行线程数
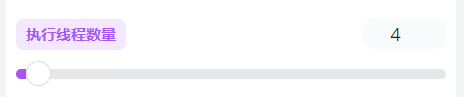
此设置应根据您的显卡性能进行调整。如果显存低于8GB,建议保持默认配置;若显存超过8GB,可以将参数提高至8-10。此建议仅供参考,具体调整应依据显卡的实际性能。
执行队列数
“执行队列数”参数仅在使用脚本进行批量换脸时需要设置;通过网页操作时无需调整该参数,保持默认设置即可。
视频内存策略、系统内存限制
此处无需进行调整,请保持默认设置,由程序自动控制。
输出路径
该路径用于存放程序在换脸过程中生成的临时图片,处理完成后程序会自动清除这些文件,因此无需进行修改。
常见选项

-
keep-temp
不建议勾选此选项。一旦选中,换脸过程中生成的临时图片将会保存至所设置的临时目录,这可能会占用大量硬盘空间。
-
skip-audio
跳过音频处理后,输出的视频将不包含音频。
-
skip-download
建议勾选此选项。由于我们的模型已完成下载,您可以选择跳过下载检查步骤。
下面讲解实操步骤说明。
简单换脸
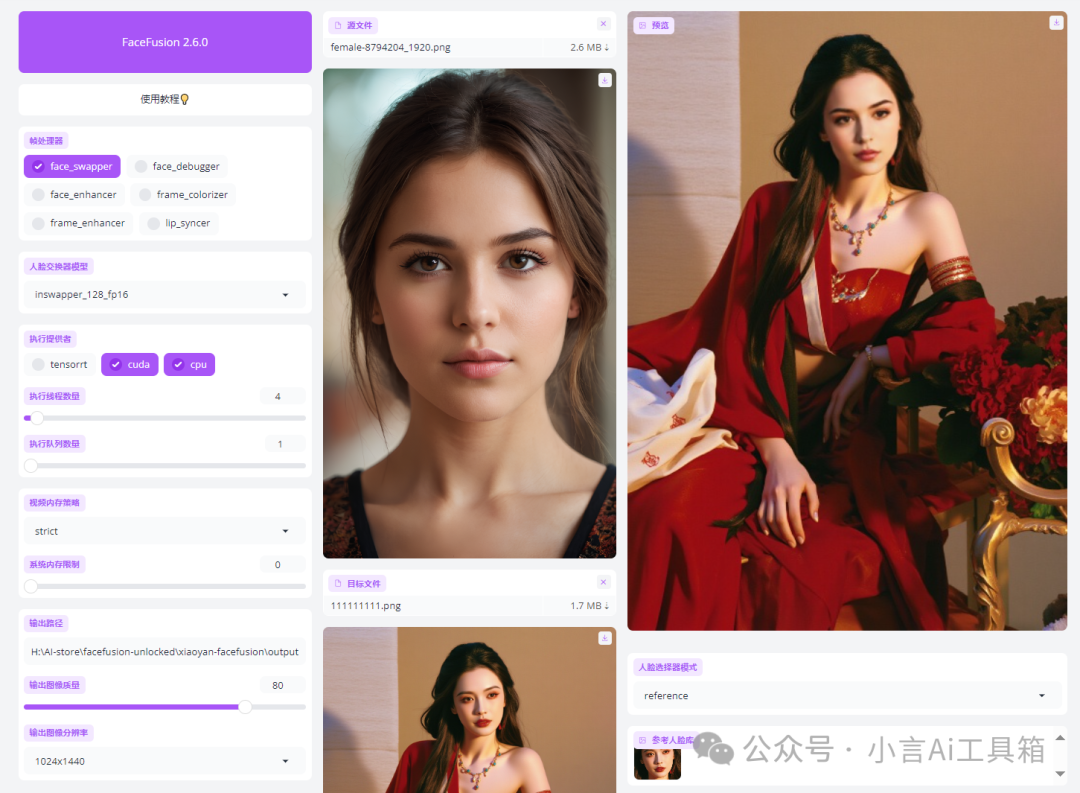
点击源文件,请选择一张人脸照片,最佳选择为清晰的正面照,确保面部没有任何遮挡。特别注意,文件名不能含有中文!
再点击目标文件,选择需要换脸的图片或者视频。特别注意,文件名不能含有中文!
右上角为预览区,以下设置将在稍后进行详细介绍。对于单张图片的换脸操作,这些设置通常不适用。点击“开始”按钮开始替换,替换完成后,点击此处即可下载并保存到您的电脑上。
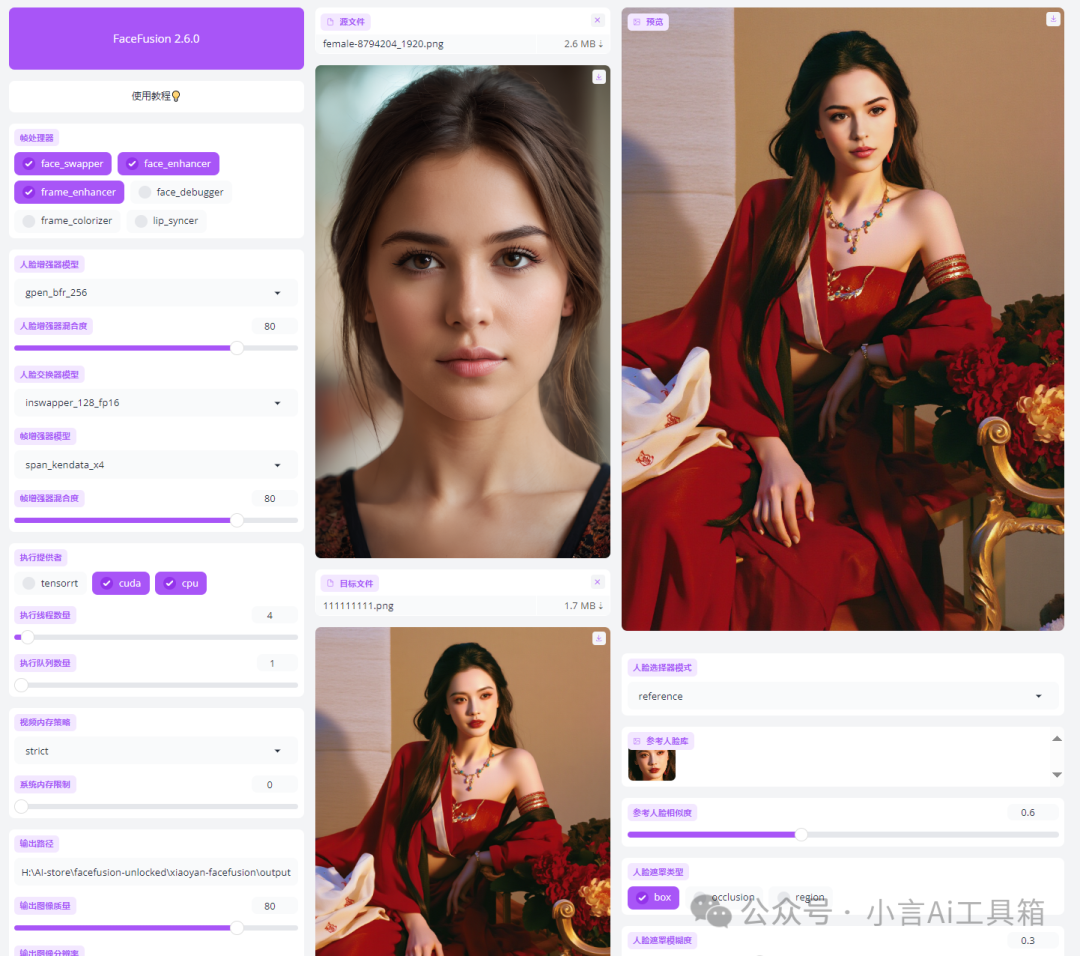
若希望获得更清晰的效果,请勾选“脸部增强”选项,然后再次进行替换。
以上便是最简便的单张面部替换流程。
多人换脸
 人脸选择器模式
人脸选择器模式

-
reference
在默认模式下,系统从左向右检测人脸,检测到的第一个人脸将列在此处。如需更换替换的人脸,只需点击相应的人脸图标即可。
-
one
“One模式”仅会替换检测到的第一个人脸。
-
many
“Many模式”将替换检测到的所有人脸。
参考人脸相似度

在大多数情况下,使用默认值0.6即可满足需求。只有在无法识别出人脸的情况下,例如视频中存在较大角度的低头侧脸镜头时,检测到的人脸匹配度较低,您可以考虑将该值调高。
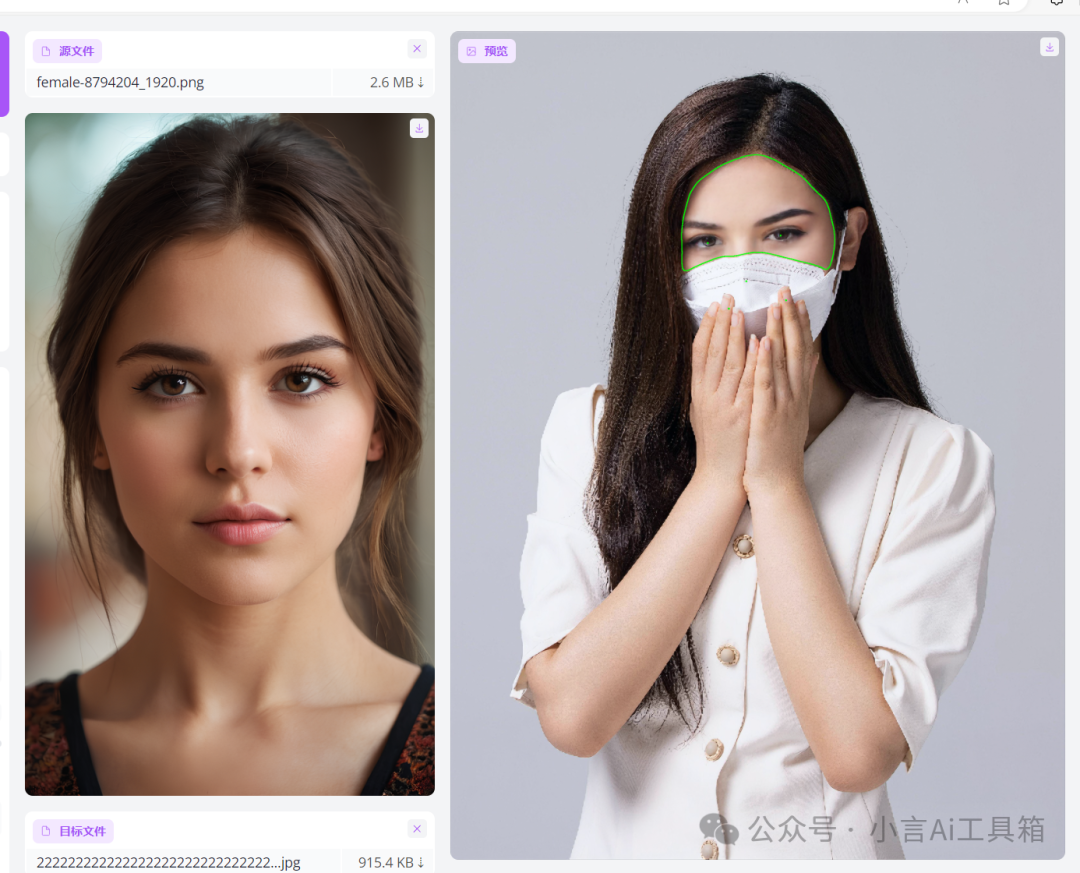
遮罩换脸
例如,对于这张面部受到物体遮挡的图片,需要选择合适的遮罩模式,以实现更优质的面部融合效果。

在使用遮罩时,建议启用调试模式。预览画面中的绿色框架表示程序默认的框架模式遮罩。
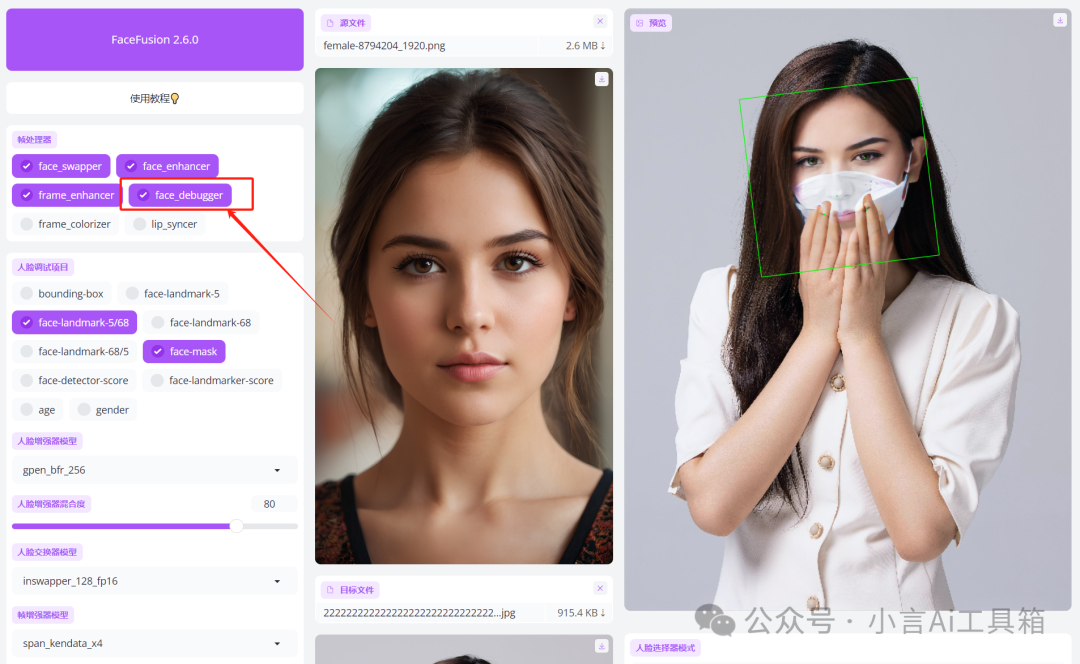
可以观察到口罩部分会露出人脸,因此需要对此进行处理。请勾选第二个遮罩类型。
 可以看到,在此模式下,系统计算了剩余的面部范围(绿色框部分)。
可以看到,在此模式下,系统计算了剩余的面部范围(绿色框部分)。
遮罩模糊
 默认值为0.3,用于调节遮挡物体的透明度。如果不是透明物体,可以调整至0.5以上。在执行前,请务必关闭“
默认值为0.3,用于调节遮挡物体的透明度。如果不是透明物体,可以调整至0.5以上。在执行前,请务必关闭“face_debugger”调试选项,以防止换脸后视频中的人脸被曲线遮挡。需要注意的是,使用封闭遮罩模式时,遮罩模糊值的合适设置可能需要多次尝试。值得一提的是,该值并非越大越好,对于透明物体(如眼镜或玻璃杯),适当减小该值往往能够获得更真实的融合效果。。
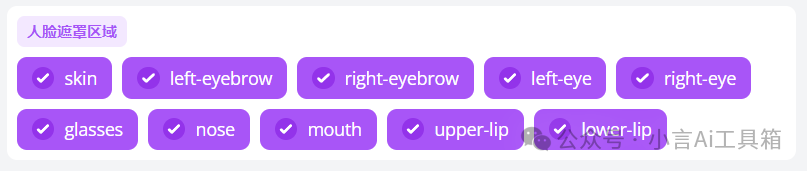
region脸部区域模式

勾选“region”后,下方将出现两排参数,涵盖眉毛、鼻子、眼睛、嘴巴等部位。默认情况下,这些部位均被勾选,将全部进行替换。如果不希望替换原视频中某个特定部位,可以取消对该部位的勾选。。
项目总结
功能特性
-
新增直播模式,新增照片/视频上色功能,优化口型同步!
-
框架着色器的引入:集成了ddcolor和deoldify模型,引入了帧着色器功能,能够为黑白视频帧添加颜色,使其看起来更加生动。
-
口型同步质量提升:通过从音频中提取语音特征,优化了口型同步器的准确性,使得视频中的口型与声音同步更加自然。
-
人脸特征点估计:进行了实验性的功能拓展,支持5到68个人脸特征点的估计,增强了面部追踪的精度。
-
面部增强器模型:添加了新的面部增强器模型gpen_bfr_1024和gpen_bfr_2048,用以提高面部图像的清晰度和质量。
-
帧增强器模型:引入了real_esrgan_x2和real_hatgan_x4模型,用于提升视频帧的分辨率和质感。
换脸步骤
1、设置人脸(Source)
拖入新的人脸图片。
2、设置目标(Target)
拖入要替换的视频。
3、效果预览 (Preview)
可以自由拖动选择
4、 开始换脸(Start)
一切就绪之后,就可以点击“开始”按钮开始正式换脸了。
总结
持续更新的开源换脸项目,支持多种模式:脸部高清修复、画质增强、口型同步等。功能过于强大,大家慢慢探索哈!~







![Android -- [SelfView] 多动画效果图片播放器](https://i-blog.csdnimg.cn/direct/1c84c5cf1fb14c8ea1eb8fb8ce7f7f69.gif#pic_center)