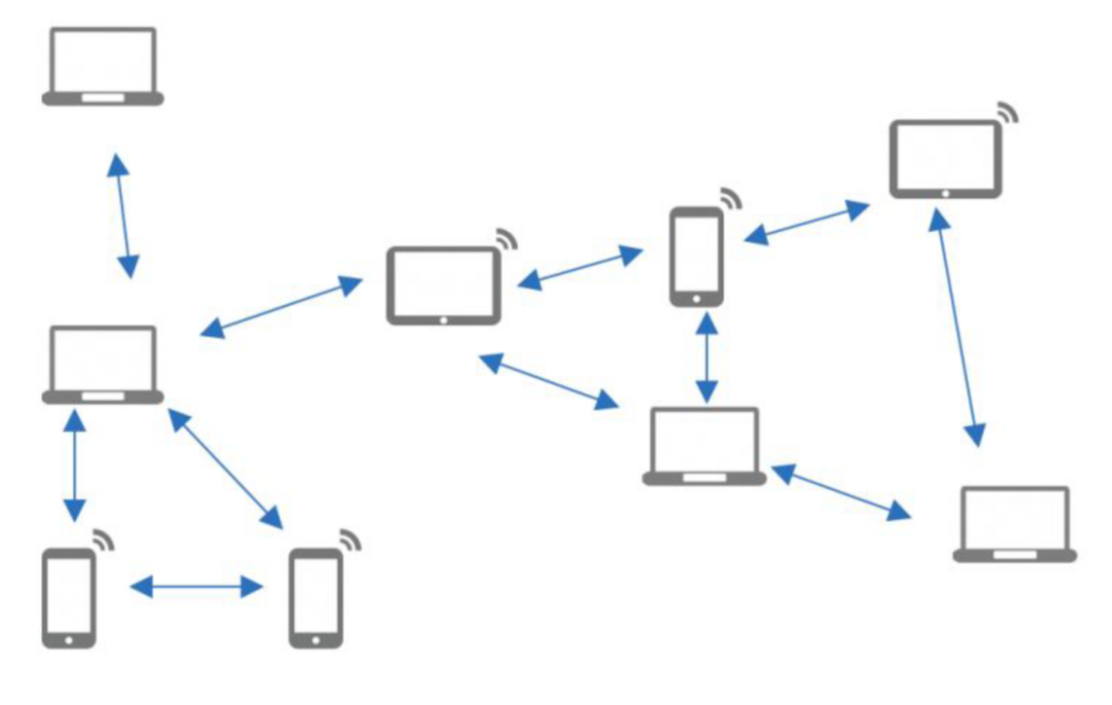
rag 需求产生的背景介绍:
在使用大模型时,一个常见的问题是模型会产生幻觉(即生成的内容与事实不符),同时由于缺乏企业内部数据的支持,导致其回答往往不够精准和具体,偏向于泛泛而谈。这些问题限制了大模型直接应用于特定业务场景的效果。通过引入RAG (Retrieval-Augmented Generation)机制,可以结合外部知识库或私有数据源来提高生成内容的准确性和相关性,有效缓解上述问题。
基于spring ai来做rag的优势介绍
我们使用了Spring AI来做检索增强,因为过去用Java写AI应用时面临的主要困境是没有标准的封装。现在Spring推出了Spring AI,它提供了一套可以兼容市面上主要生成任务的接口,极大地方便了开发工作。Spring AI不仅支持阿里云的通义大模型等服务,还能够通过简单的配置切换不同的AI提供商,使得开发者可以更加专注于业务逻辑而无需过多关注底层实现细节。这种标准化和模块化的设计,让Spring AI成为了构建AI应用程序的理想选择。
Spring AI alibaba介绍
Spring AI Alibaba 是一个针对 Spring AI 的实现,基于阿里云百炼系列云产品提供大模型接入。它主要支持包括对话、文生图、文生语音等在内的多种生成式AI功能,并且能够兼容市面上大部分基于流的机器人模型。通过使用 Spring AI Alibaba,开发者可以轻松地将这些强大的AI能力集成到自己的Java应用程序中。其核心优势在于提供了统一且标准化的接口来访问不同的AI服务提供商(如OpenAI、Azure和阿里云),从而减少了因切换不同服务商而带来的开发工作量。此外,Spring AI Alibaba 还支持通过简单的配置即可调整使用的具体模型,比如用于绘画或图像生成的通义万象模型,极大简化了AI应用开发流程。
检索增强的后端代码编写
为了通过检索增强的方式读取一个阿里巴巴的财务报表PDF,并对外提供服务,基于提供的知识内容,首先需要理解RAG(检索增强生成)的基本概念和技术实现。这里采用的是阿里云百炼平台与Spring AI Alibaba集成的技术栈来完成这个需求。下面将详细介绍具体的配置和代码实现步骤。
一、环境准备
- 确保JDK版本:必须使用JDK 17或更高版本。
- Spring Boot版本:项目应基于Spring Boot 3.3.x 版本。
- 获取API Key:访问阿里云百炼页面,按照指引开通“百炼大模型推理”服务后创建并保存好API key。
- 设置环境变量:在你的开发环境中设置
AI_DASHSCOPE_API_KEY为刚才获得的API key值。 - 项目依赖配置:
- 添加额外的Maven仓库以支持spring ai alibaba starter 的引入。
- 在pom.xml中加入spring ai alibaba starter以及指定Spring Boot的父级项目。
<repositories><repository><id>sonatype-snapshots</id><url>https://oss.sonatype.org/content/repositories/snapshots</url><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases></repository>
</repositories><dependencies><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>1.0.0-M2.1</version></dependency><!-- Spring Boot Parent --><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.4</version></parent>...other dependencies...
</dependencies>
二、服务端代码实现
根据上述配置完成后,接下来是具体的服务端逻辑编写,主要包括构建索引和查询两个部分。
1. 构建索引
此步骤用于从给定的PDF文件中提取文档数据并将其转换为向量存储到VectorStore中。只需要首次运行时调用一次。
public String buildIndex() {String filePath = "/path/to/your/alibaba_financial_report.pdf";DocumentReader reader = new DashScopeDocumentCloudReader(filePath, dashscopeApi, null);List<Document> documentList = reader.get();vectorStore.add(documentList);return "SUCCESS";
}
2. 提供查询接口
客户端可通过GET请求向/ai/steamChat发送消息参数input,服务器将返回基于上下文信息生成的回答。
@GetMapping("/steamChat")
public Flux<String> generate(@RequestParam("input") String message, HttpServletResponse httpResponse) {StreamResponseSpec chatResponse = ragService.queryWithDocumentRetrieval(message);httpResponse.setCharacterEncoding("UTF-8");return chatResponse.content();
}
三、启动应用并测试
完成以上步骤后,启动Spring Boot应用。第一次运行时,请先访问http://localhost:8080/ai/buildIndex来初始化索引。之后就可以通过访问http://localhost:8080/ai/steamChat?input=您的问题来进行问答了。
这样,我们就完成了基于RAG技术对阿里巴巴财务报告PDF文件的处理,并且能够通过简单的HTTP接口进行交互式问答。
检索增强的前端代码编写
基于我了解的信息中的内容,我们将使用React构建一个前端项目,该项目能够通过流式方式从前端向后端发送请求,并接收后端返回的flux<String>数据。根据题目要求,后端接口URL为http://localhost:8080/ai/steamChat?input=…,该接口会返回基于检索增强生成的内容。
构建并配置React项目
首先,确保你的开发环境已经安装了Node.js和npm(或yarn)。然后按照以下步骤创建一个新的React应用:
npx create-react-app frontend
cd frontend
npm install
此命令将帮助你快速搭建起基础的React项目结构,并自动安装所有必需的依赖项。
接下来,在public/index.html中保持默认设置即可,因为这个文件主要用于定义基本HTML文档结构。
修改关键组件
在src/App.js中引入我们即将编写的聊天组件ChatComponent:
import React from 'react';
import ChatComponent from './components/ChatComponent';function App() {return (<div className="App"><ChatComponent /></div>);
}export default App;
然后,我们需要重点实现src/components/ChatComponent.js,这是整个交互的核心所在。在这个组件里,我们将实现输入框、发送消息按钮以及展示从服务器接收到的消息的功能。
import React, { useState } from 'react';function ChatComponent() {const [input, setInput] = useState('');const [messages, setMessages] = useState('');const handleInputChange = (event) => {setInput(event.target.value);};const handleSendMessage = async () => {if (!input.trim()) return; // 确保不发送空消息try {const response = await fetch(`http://localhost:8080/ai/steamChat?input=${encodeURIComponent(input)}`);if (!response.ok) throw new Error('Network response was not ok');const reader = response.body.getReader();const decoder = new TextDecoder('utf-8');let done = false;while (!done) {const { value, done: readerDone } = await reader.read();done = readerDone;const chunk = decoder.decode(value, { stream: true });setMessages((prevMessages) => prevMessages + chunk);}// 请求完成后添加换行符以区分不同对话setMessages((prevMessages) => prevMessages + '\n\n=============================\n\n');} catch (error) {console.error('Failed to fetch', error);} finally {setInput(''); // 清除输入框}};const handleClearMessages = () => {setMessages('');};return (<div><inputtype="text"value={input}onChange={handleInputChange}placeholder="Enter your message"/><button onClick={handleSendMessage}>Send</button><button onClick={handleClearMessages}>Clear</button><div><h3>Messages:</h3><pre>{messages}</pre></div></div>);
}export default ChatComponent;
这里的关键点在于如何处理流式响应。我们使用了fetchAPI来发起请求,并利用TextDecoder解码每个读取的数据块。每次获取到新数据时,我们都更新状态变量messages,以便于实时显示最新消息。
运行项目
最后,启动你的React应用程序:
npm start
这将打开本地开发服务器,默认监听端口3000。你可以通过浏览器访问http://localhost:3000查看效果。
小结
上述过程展示了如何利用现代Web技术栈结合Spring AI Alibaba提供的流式接口功能,快速构建一个简单的支持流输出的聊天应用程序。用户界面非常直观,允许用户输入文本并通过点击“Send”按钮发送给后端进行处理,而前端则负责动态地展示接收到的信息。这样的设计非常适合需要即时反馈的应用场景,比如在线客服系统或智能助手等。













![Android -- [SelfView] 多动画效果图片播放器](https://i-blog.csdnimg.cn/direct/1c84c5cf1fb14c8ea1eb8fb8ce7f7f69.gif#pic_center)