嘉宾介绍
张松昕,南方科技大学统计与数据科学系研究学者,UCloud 顾问资深算法专家,曾任粤港澳大湾区数字经济研究院访问学者,主导大模型高效分布式训练框架的开发,设计了 SUS-Chat-34B 的微调流程,登顶 Open LLM Leaderboard、Opencompass 同参数量级模型榜首。
内容摘要
Scaling law 表明,大模型需要在互联网级别的海量数据上进行训练, 但现有的大模型训练方案基本上仍然采用过去小规模数据的简单训练范式, 难以匹配现有需求。我们从底层训练框架出发,重新设计了数据在训练过程中的生命周期, 使数据开发与模型训练解耦, 改善了大模型训练中大规模数据处理及治理的难题。从而将数据和算法在大模型开发周期中可以在同等层次上对待,还为大模型训练提供了更加灵活和智能的解决方案。这项研究为未来的大模型训练开辟了新的方向,不仅在理论上具有重要意义,也在实际应用中展现出巨大的潜力。
观看完整分享
大数据技术在经历了十几年的发展之后,进入到了大模型时代。于是,我们回过头来反思在数据端做的一些事情,可以对大模型当前的困境或是训练的基础架构上遇到的瓶颈做出哪些优化和赋能。
在 2022 至 2024 年的两年间,我们看到从 GPT2,GPT3 到现在几百上千B的模型越来越多,模型增长(包括智能增长)的速度都非常快,而 GPT3.5 和 GPT4 的诞生直接带来了这一波大模型的浪潮。

随着模型智能的提高以及模型大小的增长, Scaling laws 告诉我们模型需要的数据也是越来越多的。我们知道 GPT3 和 BLOOM,训练的数据量是100多B token,但到了今年上半年的 LLaMa-3 8B 模型训练了 15T token,这在 Scaling laws 看来其实是一个 overtrain 的过程。目前大家的一致认知是模型越大效果越好,模型训的 token 数越多效果也越好。但是模型大了的问题是在我们后面部署或者客户使用代价太大,所以大家更希望在小模型上训练大量的 token 来满足场景,即使它不是那么符合 Scaling laws。

就文本模型来讲,训练数据已经非常多了,SORA 以及 Gemini 的出现,让大家觉得多模态也是一个非常崭新的天地。这种类型的模型训练需要的数据就更多了,比如一个可供对比的数据量是:每分钟上传至 YouTube 的视频是 500h 的量级,则近五年的 YouTube 上的视频数据总量为:13亿小时(788亿分钟)。由于 Diffusion 模型训练 text to video 需要高质量的标注视频,因此我们可以估计 Sora 训练的视频量级为1亿分钟左右,大概的数据使用量至少是几十到几百 PB 这个级别的原始数据(raw data)。根据我们以及业界做视频生成模型的经验,大约能留下 1/ 1000 到 1/100 这个级别的真正用来训练的有效数据(trained data),真正用来训练的数据也是在 PB 级。
随着模型数据量的增长,模型变得越来越大,模型训练的 token 数也越来越多。可供对比的数据是如果要训大概一分钟视频的 token 数,大概要训 1.0M 的数据。所以我们对数据来到训练的 IO 速度要求是越来越高的。

当前多模态时代我们遇到的最大问题在两个方面:第一是我们怎么去训练 internet-scale 的 multi-modal data。Internet-scale 不仅是语言模型所见到的,比如 text、HTML,更多的是 YouTube 上的视频,开源出来的数据集以及 internet 上的图片;第二是数据处理工作流程变得越发多样和复杂。如上面所说,我们要从 500 PB 的数据里面挑选出 1/100到 1/ 1000 真正用来训练的数据,意味着我们的数据管线是异常复杂的。正常来讲训练一个视频生成模型,比如希望能达到可灵质量,在数据流水线里面,需要经过至少几十到两百个小模型来给数据做打标、过滤等处理。然后,还需要经过一些大模型去处理数据,比如视频要抽取某些帧去做 recaption,甚至对整个视频做一个描述。最后,得到一条真正可以用来训练的数据,这跟将训练的数据与原来的模型存到本地硬盘里,然后把它们 load 出来,过程是完全不一样的,需要经过一个非常漫长的流水线,最终到达训练的 GPU。一条合格的训练数据可能是前面很多模型所处理出来的结果。
自然而然的想法是如果数据处理管线特别长,那么我们就用流式的方法来做。据我所知,很多大厂并没有采用这个模式,主要原因有两点:
- 模型训练和数据处理往往是分离的,是在两个不同的集群上去做,那么构建跨两个集群的桥梁就会有比较大的 gap;
- 从深度学习的角度来讲,因为相对于原来的分布式系统,它有非常强的一致性要求。比如一个大模型切成几百份,那么这几百份在每时每刻见到的数据必须完全一样,这个顺序必须是完全一样的。
所以说这个 stream data flow 现在很多人在想,大家真正把它做出来的其实是很少,或者做了各式各样的取舍。
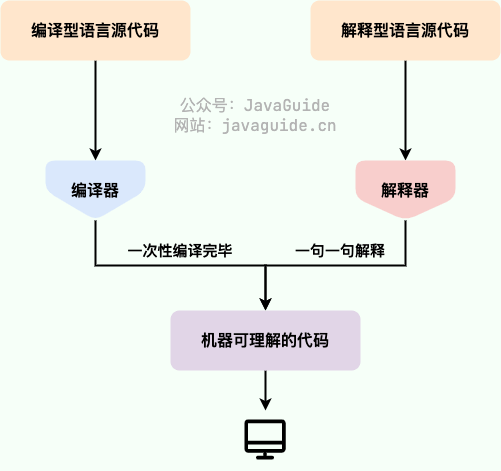
我们原来的做法是先下载数据集,通过 split ,把数据输入到模型开始训练,这样就得到了一个模型。

这种简单明了的方式在原来是可行的,因为数据都存在本地, IO 速度也很快,数据量也不大,一般的语言模型训练也就几十 TB,对于一个几百节点的分布式系统来讲,提供几十个 TB 的存储是非常简单的, IO 速度也在我们可以接受的范围之内。那这个 ETL 就会非常短,包括 read 进来的时间,只要稍微跟训练做 overlap,开几个进程把数据 prefetch 一下,训练整体是完全可以接受的。但问题是由于多模态的出现,尤其是引入了文本以外,信息密度没有那么高的模态以后,ETL 就会变得非常复杂。

第一是存储占用非常高。几百到几十 PB 的存储很难以纯 RDMA 网络接入到真正的训练单元上,由于训练数据的处理流程非常长,意味着没有办法通过一个简单的 IO 优化,就把数据放到训练集群上做训练,这个也是做不到的。

甚至数据的形式都是不能确定的,比如视频生成领域一个流传比较广泛的数据集——Shuttlestock,它是以 URL 的形式分发,全部数据可能要几十到100 TB,但是它真正分发出来就 10 GB,其实就是链接。这种情况下,如果存储在我们最终端的数据是链接的形式,整个数据处理流程(甚至还包括了下载数据)显然没有办法通过一个简单的硬盘 IO 把数据落到本地,然后稍微异步一下就能把事情解决。

另外,还有一些更耗时的流程,比如对视频会做 recaption。因为从互联网下载下来的视频往往只带一个标题,或者一个相关的文字描述,很简短,有很多是文不达意。对于语言、生成或理解模型,关键是要理解给出这个图之后应该生成什么话,或者给出一段话之后应该生成什么图。经验表明对图片或者模态信息描述的越完善,模型的表现就会越好,无论是 stable diffusion、Imagen,或者是多模态理解和生成模型都是一样的道理。
这意味着我们要对视频中间的某些帧,甚至需要对整个视频进行 recaption,就是重新的去做 labeling。这个过程很难说是一个很快速、简单的流程,因为势必要把数据 load 到推理引擎中,然后让推理引擎把数据再输出出来。比如我们以 Yi-34B 开源的 VL 模型为例,大约一条数据就处理一张图片或者多图的一个推理,生成这一段话大约需要 3 秒,这是一个非常庞大的数据量,非常天量的时间消耗。

为什么说我们没有能力搭建适应视频预训练的存储设施呢?现在 GPU 节点主要是由 A800 或者 H100 组成,一般 9 个IB 网口会留1个去跟其他存储节点或者存储网络做 RDMA 组网,意味着一般的响应数据中心是没有能力对这么大级别的数据完全做 RDMA 组网,公有云服务提供商也很难在一个正常的方案下提供出这样大的存储。

这种情况下,我们需要解决的是把前面整个数据处理流程的复杂性,弥散在这几十天(训练时间是其实更长的,因为你可能有 1, 000 张 GPU,但这么多数据可能要训练几十天)里面,然后让整个训练管线和数据是 overlap 的。
现在的问题主要有:数据来源复杂,不能被立即获取;数据处理的流程很复杂,数据处理和模型训练还是耦合的(我们说一次模型的训练需要提取的数据是一致的,比如我们需要知道训练 stable diffusion,需要过滤掉一些敏感信息,或者过滤掉一些图片,这是跟训练目标结合的,对于下一次做多模态理解或安全模型,同样的数据可能就要去保留,然后去打一些这个 negative 的 level,然后去让它训练。在这种情况下,这些数据不是永远没有用,它可能在这次训练里有用,在下次训练里没有用,或者本来这次是要被过滤掉,下次它是重要的数据,这就意味着我们要依靠数据处理的 pipeline 做出是否要将数据给到训练集群的判断。)
同时还有个问题就是数据量太大,没有办法一次处理,因为这种情况势必会存算分离,很难再把数据传回到存储单元里,成本太高了。

那么我们的 ETL 就会变成这样,Read 传送会耗费巨量的时间,真正 Train 所花的时间其实跟 ETL 是可比的。如上面所说,数据存到本地,然后慢慢的把它 load 上来,或者说用同步的方式,等着把它 load 上来,然后再去训练,Checkpoint 也是一样的道理。这是没有问题的,但一旦数据处理的管线非常长,意味着 ETL 的时间和 Training 的时间是可比的了,比如千卡 GPU 集群,让它空等 30 天的数据处理,然后再去做训练,这是不可接受的。

所以我们就用流式训练的方法来解决这个问题。流式数据的思路非常简单,因为在大数据或者说在整个计算机发展史上已经做过很多次了。通过把事物解耦开,将存算进行分离,计算是在 GPU 上,数据的 load 过程变成异步的处理单元,然后让训练的同学从某个约定的接口或是中间层把数据再 load 出来。假设有一个不知道从哪里来的数据源,所有分布式进程从这个数据来源 load 数据。面临的另一个问题是,比如现在的高性能消息队列或分布式存储,往往都是通过 partition 的方式,会有一个哈希槽,通过这种方式来做负载均衡和高并发。
很多时候我们对一致性的并不是强保证,这对 AI 训练是不可接受的。比如我们在训一个模型,但接触到的数据不一样,梯度立马就会爆炸,loss 就飞了,这种情况大家就不会愿意去采用这样的形式。很多厂商所选方案是折中的,会考虑把存储堆高,买非常多的高性能并行存储系统 ,比如一次可能训练几百个TB 的数据,这个成本是可以接受的。但这是一种暴力的方式,终究有一天你的物理硬件设施没有办法支撑你的想法,那只能接受 ETL 的时间变得漫长,比如等数据 ETL 完了再让 GPU 卡工作,这就带来了时间和金钱上的浪费。

一个简单的想法,是在 streaming 的训练框架里加入中间层,可以是 SharedMemory,也可以是混了 SharedMemory 与本地存储的中间层。然后,我们把数据流式的给到中间层,由它来做统一的分发,这样会有一个鲜明的界限,就在于前面的数据可以不一致,而一致性可以由 K8S 上的中间件去保证。无论我们是用 SharedMemory 还是用 ALLUXIO,一致性是由真正靠近计算节点的的最后一层存储来保证,在架构前面,我们就可以利用到现有的分布式的流式分发系统,流式的数据处理系统,以及大数据生态里这些组件的优势。

这样做的好处是什么呢?
- 首先对于模型训练来讲,是零启动开销的。比如当满足一分钟训练的数据到达训练节点,就可以训练启动了。由于不需要等数据,数据处理进程和模型训练进程完全分离,意味着模型不需要写非常复杂的dataloader,只需要从模型训练或算法定义好的 endpoint 里抽取数据就可以了。
- 节点内本身通过 SharedMemory通信,会降低节点间的网络负载,我们希望在数据分发的过程中,对高性能网络压力小一些,那么我们尽量以节点为单位分发,然后节点内再去酌情分发。比如用8 张卡在训练一个模型,把一个数据 broadcastBuffer 到 8 张。
- 本身引入数据库是为了让模型存 checkpoint 过程变得简单,因为 checkpoint无非就是数据的位置、模型位置、模型及优化器的参数。
这是我们的数据切片方式,用来保证数据分发的一致性。

这样的解耦可以让我们方便的迁移到不同的云平台上做不同规模的训练。因为我们首先解决了物理训练的问题,训练最终获得的是数据集的位置,模型参数及优化器参数,后面两个对网络来讲是一次性的传输成本,但是数据集的位置往往要先把数据搬到某个公共云的 S3 上,然后再去慢慢做。因为跨境 S3 复制,尤其有一些海外数据,我们要想入境或者把一些几百 TB 大的数据集下载下来,外网带宽(包括境内的专线和跨境专线,还有境外带宽)的成本是很高的。
当数据量比较大,外网带宽的成本开销跟训练集群甚至是可比的,这个时候我们希望数据托管商,比如 AWS、阿里云等会提供 CDN 服务,本身也会有 GPU 集群,我们可以在上面租 GPU 集群。如果能够在离数据比较近的地方去训练,然后把我们这套方案放进去,就可以节省下网络带宽以及专线的开销。
需要做的迁移只是对数据做定时的 Sync,或者在训练到某个节点,把上面的数据消耗完了以后,再把模型移回来,或者把模型 checkpoint 的数据搬回来,就可以接着在另一个云平台上训练。

当我们的训练和数据这两件事做到完全解耦,就可以实现真正对大规模负载的高效、低成本的解决方案。

这里模型训练一直在训,数据源源不断到达,这个前提是什么呢?模型训练还是很慢,如刚才讲了一个非常漫长的数据处理流程,甚至一条数据过一个节点要花费 3 秒。首先,模型训练的水平扩展方式是堆卡,这跟前面数据处理堆的卡的成本相比是完全不可比的,因为模型训练要堆一些高性能的 GPU,而推理只需要 4090卡 就可以了。所以说,模型的数据处理的 scale up 能力是非常高且简单的,不需要做什么三维并行等,只要 8 张卡能推,那么扩展 8 份,吞吐量就能完全提高 8 倍。
在这种情况下,模型训练的速度一定会慢于数据处理的速度,甚至会远远低于你的网络带宽。比如我们取 stable diffusion,一张图片进来可能是 512 × 512 分辨率,但真正落实到模型,过完 VAE 和 encode 之后,其实分辨率是降低了的。模型训练真正接触到的数据,本身是一个经过精简处理以后的,比如视频模型一般需要去做抽帧,一个 60 LPS 的视频可能会抽成 20 或者 10 LPS,这样信息和数据量就会减少。如果训练远低于数据处理的进度,而且数据处理集群可以方便的 scale up,那么我们的训练就是一个可以和数据处理完全 overlap 的状态,也就是 ETL 会变成完全重合的状态。

核心是我们有一个湖仓,前面有个数据库。数据库会存整个训练单元或是这次训练的 Meta 信息,然后我们把复杂的数据处理变成从数据库获得元信息,跟湖仓去交互,把数据提取出来,做完了以后把数据的修改和 metadata 再存回到湖仓,有效数据返回到训练集群,这样的 infrastructure。然后再用这个 infrastructure 去做多模态的 modeling。

这个架构是把数据和模型训练分离开来,提供了一个跟大数据生态相结合的方案。原来云厂商提供的底层存储就是 S3、NFS、高性能并行文件系统或是 Ceph。如果可以把训练和存储或者说数据的单元分离开来,底层可以是任意存储,比如可以去买云厂商提供的 Hadoop HDFS,把数据存进去,然后不用管数据处理流程是什么样的。如果是显示的数据,就是表格的形式,如果是视频,就是流式的二进制。数据往上层走,到顶层才是训练单元,在中间,我们会有一些中间件去做。统一的存储有一些解决方案,Alluxio 就是推荐方案之一。
有一些云厂商也会提供面向云原生的 CSI 解决方案,这些方案结合起来,我们往上去提供真正面向整个数据处理流 pipeline 的存储,然后由存储上面的中间件去往训练集群分发。由于 AI 与数据的分离,大数据组件与我们这个 streaming infrastructure 结合起来,这样我们在数据处理端就可以专注的使用丰富的大数据经验,得到的解决方案就可以平滑的搬到 AI 里。

Scaling Law 主要是说数据量和计算量越大,模型的效果会越好。Hoffmann 指出了最优的模型数据比。在这个数据比下,当模型和数据同步放大,loss 会下降更多(无监督学习理论里的 loss 是一个压缩率,压缩率越高意味着表现会越好)。

Scaling Law 本身是有上限的,比如按照最优比下降的话,计算和数据同步增长,loss 大概是这样一个趋势。但如果数据涨不动,或者没有那么多数据了,亦或光变大模型,数据增长不够,它最终会收敛到一条这样的线上,导致出现嵌拟合的情况,这就是所谓的 overtraining,模型与数据没有达到最优的配比。

从 2022 到 2024 年,模型的大小扩张了成百上千倍,但数据量的大小扩张远比模型要大,这样非常容易出现过拟合或是 overtraining 的情况。

当人类的数据将被耗尽,而模型越来越大,但没有那么多好的数据给模型训练,解决方案是怎么样用我们这套 Infrastructure 去扩展 Scaling Law,去真正赋能有用的好数据。

这里有个背景,过多使用合成数据不会对模型有好的增益,所以我们没有办法通过合成数据来扩张数据量。

这就需要用到我们这套框架去进一步挖掘数据,那么我们现在训练,比如 15T token 里面很多是没有用的,或是脏数据。现在如果要处理这15T 数据,可能需要花45天,100个数据工程师把它处理出来,最后再存到并行文件系统里,让算法去训练。在这种情况,数据和模型的交互仅限于人类自己的判断,可能在某种意义接近正确答案,但肯定不是最接近正确答案的方式。

同时,开源数据集里本身就有一些非常离奇的错误,比如有事实性错误幻觉,还有没有输出的,如 AIPACA 里面依然存在这样的问题,甚至 ImageNet 里也有 3% 可能有问题的数据,说明至少人类挑出来这些数据里面依然是有大量问题的。

DeepSeekMath 讲了一个故事,我们可以通过反复的 loop 和迭代,把数据一遍一遍的萃取,最后萃取出一个比较少的token 数,但依然可以让模型的效果得到非常大的提升,意味着我们缺乏的是跟模型领域有关亦或是性能有关的数据挖掘,需要一个跟数据和模型交互的框架。

真正有利于模型的数据处理是什么样的呢?
模型应该可以根据当前的状态去了解它应该去学什么。比如这是一本数学书,一般学习过程是非线性、从易到难的过程,模型的学习也应该是这样。那对于模型什么内容是简单,什么是难,其实很难定义。语言文本还尚可定义,但到了 CV 或者图片模型,是完全无法定义的,因为图片分很多种,做个傅里叶变化,会发现有高频信息和低频信息,人的肉眼是无法辨识的,无法判断哪些东西是模型应该学的会,或应该早点学,这是判断不了。

一个好的数据筛选框架应该是模型能感知的,并且模型本身可以筛选出数据的排序。我们 streaming 框架本身因为中间有一个数据库,或是有个屏障来隔绝数据层和模型层,这样模型只管拿数据,但是什么样的数据可以过来,完全是由数据屏障来决定的。这个屏障原来接收的是数据流的单向流入,现在完全可以做非常简单的扩展。
因为数据库可以从模型这一侧获得模型当前的状态和输出,无论是从 loss 还是从优化器的状态,甚至是我们统计一些矩阵的普特征信息,完全可以往数据端的屏障里面去扔,由于屏障本身作为数据层和模型层的隔离,它现在担任了计算的角色,去做 dynamic 和 data sample。

我们用这种方式通过模型不断的训练,把状态反馈给数据处理单元,让数据管线适配模型当前的状态。这个是我们做的科研工作,基本框架是这样:我们有一个 evaluate,这个 evaluate 用一个 Dynamic Threshold 去控制语言模型的学习。这个 Dynamic Threshold 本身也可以是语言模型,可以是一个正在前面训练的小模型,通过 Scaling Law 摘出数据来喂给大模型。相当于我们在数据层和模型层中间加了一层动态的数据控制层,这个数据控制层本身可以有一些计算能力。

这是一个简单的实验,在很多领域我们的 data selection 的方法在同样的数据集下可以用更小的数据达到比较好的效果。

刚才讲的方案里这个动态数据层,可以是数据控制层,也可以是一个小的模型(SLMs),完全可以引导大模型去学。比如 SLM 训得很快,我们拿一个 A100 节点去训练,训练 100 步以后我们看它的效果。它在前面探索,完了以后,通过我们的数据控制系统,把数据返回给大模型,让它照着这个小模型的轨迹去训练。
这个框架的名字叫做 navigation,寓意是希望成为领航员的角色,希望可以引导算法方面的一些工作,而我们解决的难点是保证数据的一致性。

我们利用这套框架能够更多的帮助到上层去做算法,以及应对目前大模型出现的各种问题。