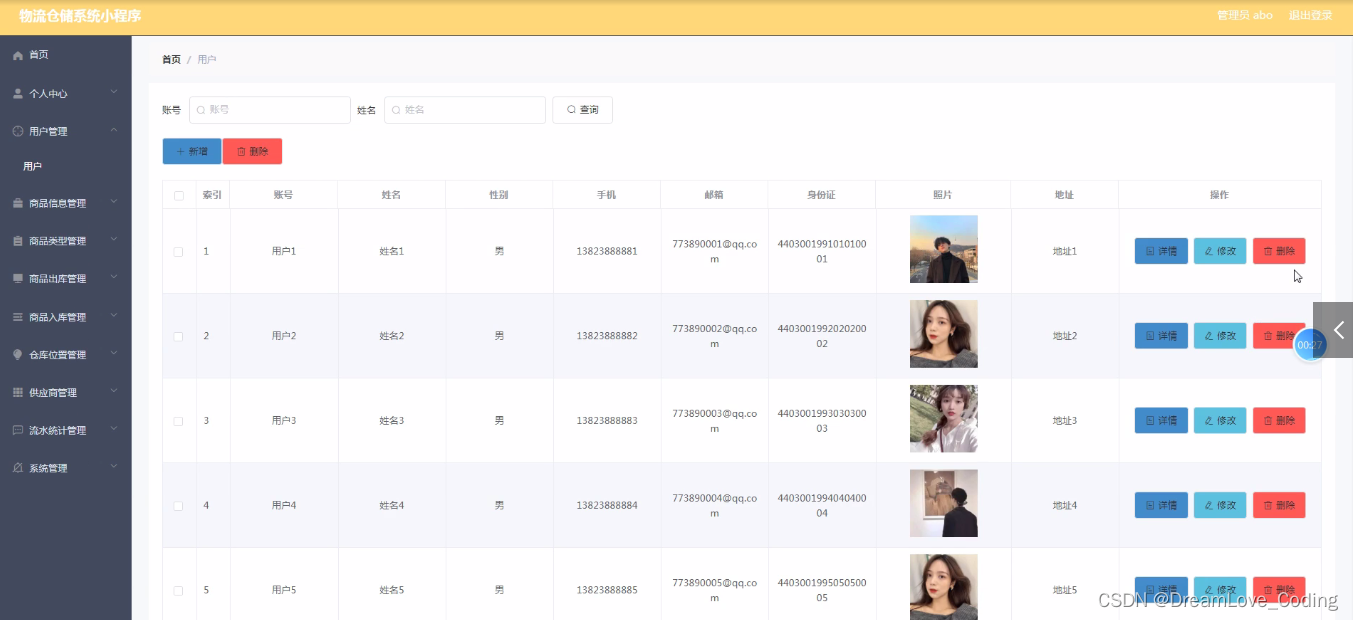
初识elasticsearch
官方网站:Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Elasticsearch是做什么的?
Elasticsearch 是一个分布式搜索和分析引擎,专门用于处理大规模数据的实时搜索、分析和存储。它基于 Apache Lucene 构建,能够快速、高效地执行全文搜索、结构化搜索以及数据分析任务。由于其强大的功能,Elasticsearch 常用于以下几种场景:
1. 全文搜索
Elasticsearch 提供快速、精确的全文搜索,支持复杂查询如模糊匹配、短语搜索、词条权重,广泛用于内容管理系统、电子商务、社交平台等。
2. 数据分析
通过聚合功能,Elasticsearch 可高效进行实时数据分析,支持多维聚合查询,适用于日志分析、业务数据分析等场景。
3. 日志与监控
结合 Elastic Stack(Logstash、Kibana),Elasticsearch 实现实时日志采集、分析和可视化,常用于系统监控、错误检测等。
4. 数据存储
作为分布式文档存储,Elasticsearch 可水平扩展,处理海量数据,保证高可用性和故障冗余。
5.地理位置查询
支持地理空间查询,适用于地图应用、物流、外卖等基于位置的服务场景。
核心特点
倒排索引:Elasticsearch 使用倒排索引来快速查找文档中包含特定词语的条目,特别适合全文搜索场景。
分布式架构:它天生支持水平扩展,允许在集群中分布和存储数据,保证性能和高可用性。
实时性:数据索引和搜索可以在毫秒级内完成,非常适合需要实时响应的数据查询场景。
RESTful API:通过简单的 RESTful API 进行操作,便于与其他系统集成。
典型应用场景
- 搜索引擎:用于内容搜索、产品搜索(如电商网站)、文档搜索等。
- 日志分析:通过 Elastic Stack(包括 Logstash 和 Kibana),构建日志管理和监控系统。
- 推荐系统:电商、流媒体、社交平台等使用 Elasticsearch 进行个性化推荐。
- 实时数据分析:企业实时分析海量数据,用于业务决策。
倒排索引是什么?和MySQL数据库有什么不同?
倒排索引(Inverted Index)是一种数据结构,广泛用于全文搜索引擎中。它的主要作用是将文档与其包含的单词进行关联,从而实现快速的文本检索。
基本原理:
文档与词汇表的映射:倒排索引将每个单词(或词项)映射到包含该单词的文档列表中。相比于传统的正排索引(即存储文档到词汇的映射),倒排索引更加高效。
结构:倒排索引通常包括两个主要部分:词汇表和文档列表。
假设有三个文档:
文档1:我 爱 编程
文档2:我 爱 学习
文档3:编程 很有趣
构建倒排索引后的结构如下:

倒排索引与 MySQL 数据库的不同:
-
数据存储结构:
- 倒排索引:主要用于存储词项与文档之间的映射,更加适合文本搜索。
- MySQL:使用行或列存储数据,通常是基于表的关系型数据库。
-
查询性能:
- 倒排索引:在处理全文搜索时,可以快速查找包含特定词项的所有文档,支持复杂的查询。
- MySQL:虽然支持索引(如B树索引),但在处理复杂的文本搜索时性能不如倒排索引。
-
更新效率:
- 倒排索引:对于频繁更新的文档,重建索引的开销较大。
- MySQL:支持行级更新,但对于大量数据的复杂查询,性能可能下降。
倒排索引的搜索流程如下(以搜索"华为手机"为例),如图:

流程描述:
1.用户输入条件"华为手机"进行搜索。
2.对用户输入条件分词,得到词条:华为、手机。
3.拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4.拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。