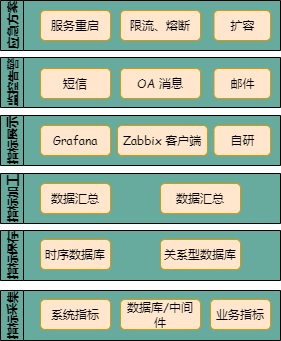
整理代码 1:DQN + CartPole_v1.ipynb
https://www.nature.com/articles/nature14236
Human-level control through deep reinforcement learning


文章目录
- 摘要
- 主体:要做什么 + 如何做的 + 要点keypoints
- 实验 与 评估
- 2 个指标
- 和 各游戏的最好方法比较
- t-SNE 可视化 DQN 的表征
- 总结
- METHODS 方法
- 预处理
- 代码开源
- 模型架构
- 训练细节
- 评估程序
- 算法
- DQN 的 训练算法
- DQN 伪代码
摘要
The theory of reinforcement learning provides a normative account, deeply rooted in psychological and neuroscientific perspectives on animal behaviour, of how agents may optimize their control of an environment. 【 指出本工作所属的研究领域 】
强化学习理论 为 代理agents 可以如何优化它们对环境的控制提供了一种规范的解释,这深深根植于动物行为的心理学和神经科学观点。
To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task: they must derive efficient representations of the environment from high-dimensional sensory inputs, and use these to generalize past experience to new situations. 【 要实现 … 面临困难… 】
然而,为了在接近现实世界复杂性的情况下成功地使用强化学习,agents 面临着一个困难的任务:它们必须从高维感官输入中获得环境的有效表示,并使用这些来将过去的经验推广到新的情境。
Remarkably, humans and other animals seem to solve this problem through a harmonious combination of reinforcement learning and hierarchical sensory processing systems, the former evidenced by a wealth of neural data revealing notable parallels between the phasic signals emitted by dopaminergic neurons and temporal difference reinforcement learning algorithms. 【 该工作是受什么启发的】
值得注意的是,人类和其他动物似乎通过强化学习和分层感觉处理系统的和谐结合来解决这个问题,前者得到了大量神经数据的证明,这些数据揭示了多巴胺能的神经元发出的相位信号 与 时序差分强化学习算法之间的显著相似之处。
While reinforcement learning agents have achieved some successes in a variety of domains, their applicability has previously been limited to domains in which useful features can be handcrafted, or to domains with fully observed, low-dimensional state spaces. 【 概括该问题当前的研究现状:有成功的例子吗,还有什么不足 】
虽然强化学习 agents 在很多领域取得了一些成功,但它们的适用性以前仅限于可以手工制作有用特征的领域,或者具有完全可观察的低维状态空间的领域。
Here we use recent advances in training deep neural networks to develop a novel artificial agent, termed a deep Q-network, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end reinforcement learning. 【 我们利用… 开发了…,可以… 】
在这里,我们利用训练深度神经网络的最新进展来开发一种新的人工 agent,称为 deep Q-network,它可以使用端到端强化学习直接从高维感官输入中学习成功的策略。
We tested this agent on the challenging domain of classic Atari 2600 games. 【 在 哪些基准 做评估】
我们在经典的 Atari 2600 游戏的挑战性领域测试了这个代理。
We demonstrate that the deep Q-network agent, receiving only the pixels and the game score as inputs, was able to surpass the performance of all previous algorithms and achieve a level comparable to that of a professional human games tester across a set of 49 games, using the same algorithm, network architecture and hyperparameters. 【 成果/评估实验结论】
我们证明了 深度 Q 网络 代理,只接收像素和游戏分数作为输入,能够超越所有以前的算法的性能,并在使用相同的算法、网络架构和超参数的情况下,在一组 49 个游戏中达到与专业人类游戏测试人员相当的水平。
This work bridges the divide between high-dimensional sensory inputs and actions, resulting in the first artificial agent that is capable of learning to excel at a diverse array of challenging tasks. 【 对研究领域的意义】
这项工作弥合了高维感官输入 和 动作之间的鸿沟,从而产生了第一个能够学习并擅长各种具有挑战性任务的人工 agent 。
主体:要做什么 + 如何做的 + 要点keypoints
We set out to create a single algorithm that would be able to develop a wide range of competencies on a varied range of challenging tasks—a central goal of
general artificial intelligence13 that has eluded previous efforts 81415.
我们着手创建一种单一的算法,能够在各种具有挑战性的任务上发展广泛的能力——这是通用人工智能的一个中心目标,此前的努力未能实现。
To achieve this, we developed a novel agent, a deep Q-network (DQN), which is able to combine reinforcement learning with a class of artificial neural network 16 known as deep neural networks.
为了实现这一目标,我们开发了一种新的 agent —— 深度 Q 网络 (deep Q-network, DQN),它能够将强化学习与一类被称为深度神经网络的人工神经网络相结合。
Notably, recent advances in deep neural networks 9 -11, in which several layers of nodes are used to build up progressively more abstract representations of the data, have made it possible for artificial neural networks to learn concepts such as object categories directly from raw sensory data.
值得注意的是,深度神经网络的最新进展,其中使用几层节点来逐步构建更抽象的数据表示,使得人工神经网络可以直接从原始感官数据中学习诸如对象类别之类的概念。
We use one particularly successful architecture, the deep convolutional network, which uses hierarchical layers of tiled convolutional filters to mimic the effects of receptive fields—inspired by Hubel and Wiesel’s seminal work on feedforward processing in early visual cortex 18—thereby exploiting the local spatial correlations present in images, and building in robustness to natural transformations such as changes of viewpoint or scale.
我们使用了一个特别成功的架构,深度卷积网络,它使用分层的平铺卷积滤波器来模拟感受野的效果——灵感来自 Hubel 和 Wiesel 在早期视觉皮层前馈处理方面的开创性工作,从而利用图像中存在的局部空间相关性,并建立对自然变换(如视点或尺度的变化)的鲁棒性。
↓ 【如何实现上述目标:关键 ideas 】
We consider tasks in which the agent interacts with an environment through a sequence of observations, actions and rewards.
我们考虑 agent 通过一系列观察、动作和奖励 与环境交互的任务。
The goal of the agent is to select actions in a fashion that maximizes cumulative future reward.
agent 的目标是以最大化累积未来奖励的方式选择动作。
More formally, we use a deep convolutional neural network to approximate the optimal action-value function
更正式地说,我们使用深度卷积神经网络来 近似 最优动作价值函数
~
Q ∗ ( s , a ) = max π E [ r t + γ r t + 1 + γ 2 r t + 2 + ⋯ ∣ s t = s , a t = a , π ] Q^*(s,a)=\max\limits_\pi{\mathbb E}\big[r_t+\gamma r_{t+1}+\gamma^2r_{t+2}+\cdots\big|s_t=s,a_t=a,\pi\big] Q∗(s,a)=πmaxE[rt+γrt+1+γ2rt+2+⋯ st=s,at=a,π]
~
这是在每个时间步 t t t 上,通过行为策略 π = P ( a ∣ s ) \pi= P(a|s) π=P(a∣s),在观察 ( s s s ) 和执行动作 ( a a a ) 之后 (见方法) ,可以实现的折扣为 γ \gamma γ 的奖励 r t r_t rt 的最大总和。
↓ 【需处理的问题 1 —— 可能不收敛:为什么会有这个问题 + 处理的关键要点 ( 方法 + 作用 )】
Reinforcement learning is known to be unstable or even to diverge when a nonlinear function approximator such as a neural network is used to represent the action-value (also known as Q) function.
众所周知,当使用非线性函数近似器 (如神经网络) 来表示 动作价值 (也称为 Q) 函数 时,强化学习是不稳定的,甚至是发散的。
This instability has several causes: the correlations present in the sequence of observations, the fact that small updates to Q may significantly change the policy and therefore change the data distribution, and the correlations between the action-values (Q) and the target values r + γ max a ′ Q ( s ′ , a ′ ) r + \gamma \max\limits_{a^\prime} Q(s',a') r+γa′maxQ(s′,a′).
这种不稳定性有几个原因:观测序列中存在的相关性,对 Q Q Q 的小更新可能显著改变策略从而改变数据分布的事实,以及 动作价值 ( Q Q Q ) 和 目标值 r + γ max a ′ Q ( s ′ , a ′ ) r + \gamma \max\limits_{a^\prime} Q(s',a') r+γa′maxQ(s′,a′) 之间的相关性。 【不稳定 的 3 个原因】
We address these instabilities with a novel variant of Q-learning, which uses two key ideas.
First, we used a biologically inspired mechanism termed experience replay21-23 that randomizes over the data, thereby removing correlations in the observation sequence and smoothing over changes in the data distribution (see below for details).
首先,我们使用了一种受生物学启发的机制,称为经验回放experience replay,该机制对数据进行随机化,从而消除观察序列中的相关性并平滑数据分布中的变化(详见下文)。
Second, we used an iterative update that adjusts the action-values (Q) towards target values that are only periodically updated, thereby reducing correlations with the target.
其次,我们使用迭代更新,将动作价值 (Q) 调整为仅定期更新的目标值,从而减少与目标的相关性。
While other stable methods exist for training neural networks in the reinforcement learning setting, such as neural fitted Q-iteration, thesemethods involve the repeated training of networks de novo on hundreds of iterations.
虽然存在其他稳定的方法来训练强化学习设置下的神经网络,如神经拟合 Q -迭代,但这些方法涉及在数百次迭代中重新开始重复训练网络。
Consequently, these methods, unlike our algorithm, are too inefficient to be used successfully with large neural networks.
因此,不同于我们的算法,这些方法效率太低,无法成功地用于大型神经网络。
我们使用图 1 所示的深度卷积神经网络参数化一个近似价值函数 Q ( s , a ; θ i ) Q(s,a;θ_i) Q(s,a;θi),其中 θ i θ_i θi 是迭代 i i i 时 Q-网络 的参数(即 权重)。
为了执行经验回放,我们将 agent 在每个时间步 t t t 的经验 e t = ( s t , a t , r t , s t + 1 ) e_t=(s_t, a_t,r_t,s_{t +1}) et=(st,at,rt,st+1) 存储在数据集 D t = { e 1 , ⋯ , e t } D_t=\{e_1,\cdots,e_t\} Dt={e1,⋯,et}中。
在学习过程中,我们对经验的样本(或小批量) ( s , a , r , s ′ ) ∼ U ( D ) (s,a,r,s') \sim U(D) (s,a,r,s′)∼U(D) 应用 Q-learning 更新,这些样本从存储的样本池中均匀随机抽取。
迭代 i i i 时的 Q-learning 更新使用以下损失函数:
~
L i ( θ i ) = E ( s , a , r , s ′ ) ∼ U ( D ) [ ( r + γ max a ′ Q ( s ′ , a ′ ; θ i − ) − Q ( s , a ; θ i ) ) 2 ] L_i(\theta_i)={\mathbb E}_{(s,a,r,s^\prime)\sim U(D)}\Big[\Big(r+\gamma\max\limits_{a^\prime} Q(s^\prime,a^\prime;\theta_i^-)-Q(s,a;\theta_i)\Big)^2\Big] Li(θi)=E(s,a,r,s′)∼U(D)[(r+γa′maxQ(s′,a′;θi−)−Q(s,a;θi))2]
~
其中, γ \gamma γ 是决定 agent 视界的折扣因子
θ i \theta_i θi 是迭代 i i i 时 Q -网络的参数,
θ i − \theta_i^- θi− 是迭代 i i i 时用于计算目标的网络参数。
目标网络的参数 θ i − \theta_i^- θi− 仅在每 C C C 步使用 Q-网络的参数 ( θ i \theta_i θi ) 更新,并且在每次更新之间保持固定(参见方法)。
实验 与 评估
2 个指标
To evaluate our DQN agent, we took advantage of the Atari 2600 platform, which offers a diverse array of tasks (n = 49) designed to be difficult and engaging for human players.
为了评估我们的 DQN 代理,我们利用了 Atari 2600 平台,该平台提供了一系列不同的任务 (n = 49),这些任务的设计对人类玩家来说既困难又吸引人。
We used the same network architecture, hyperparameter values (see Extended Data Table 1) and learning procedure throughout—taking high-dimensional data (210 × 160 colour video at 60 Hz) as input—to demonstrate that our approach robustly learns successful policies over a variety of games based solely on sensory inputs with only very minimal prior knowledge (that is, merely the input data were visual images, and the number of actions available in each game, but not their correspondences; see Methods).
我们使用相同的网络架构, 超参数值(见扩展数据的表 1 ) 和 学习过程 —— 高维数据 ( 210×160 彩色视频 60 Hz) 作为输入 ——来证明我们的方法 在各种游戏完全基于感官输入只有非常小的先验知识 (也就是说,仅输入的数据是视觉图像,和 每个游戏可用的动作数目,但不是他们的联系;见方法) 稳健地学习了成功的策略。
Notably, our method was able to train large neural networks using a reinforcement learning signal and stochastic gradient descent in a stable manner— illustrated by the temporal evolution of two indices of learning (the agent’saverage score-per-episodeandaverage predicted Q-values; see Fig. 2 and Supplementary Discussion for details).
值得注意的是,我们的方法能够以稳定的方式使用强化学习信号和随机梯度下降来训练大型神经网络,这可以通过两个学习指标的时间演变来说明(智能体的 平均每回合得分 和 平均预测的 Q 值;详见图 2 和补充讨论)。

Figure 2 | Training curves tracking the agent’s average score and average predicted action-value.
图 2 | 跟踪 agent 的 平均得分 和 平均预测动作价值 的训练曲线。
a, Each point is the average score achieved per episode after the agent is run with ε \varepsilon ε-greedy policy ( ε \varepsilon ε = 0.05) for 520 k frames on Space Invaders.
在 Space Invaders 的 520 k 帧中,agent 以 ε \varepsilon ε-greedy 策略 ( ε \varepsilon ε = 0.05) 运行后,每个点都是每回合的平均得分。
b, Average score achieved per episode for Seaquest.
Seaquest 每回合的平均得分。
c, Average predicted action-value on aheld-out setof states on Space Invaders.
Each point on the curve is the average of the action-value Q computed over the held-out set of states. Note that Q-values are scaled due to clipping of rewards (see Methods).
Space Invaders 中状态的 held-out set 的平均预测行动价值。
曲线上的每一个点都是动作价值 Q 在 状态 held-out set 上的平均值。
注意,Q 值由于奖励的裁剪而缩放(参见方法)。
d, Average predicted action-value on Seaquest. See Supplementary Discussion for details.
Seaquest 上的平均预测动作价值。详见补充讨论。
$\varepsilon$ ε ~~~~~~~~\varepsilon ε
- epsilon(ε)是原型写法,而 varepsilon(ϵ)是变体写法。
- 在现代希腊语中,epsilon 的写法是 ε,而在数学和物理等领域中,常用的写法是 ϵ,表示数学符号中的变量。
和 各游戏的最好方法比较
We compared DQN with the best performing methods from the reinforcement learning literature on the 49 games where results were available12,15.
我们将 DQN 与 在 49 个游戏中可获得结果的强化学习文献中表现最好的方法进行了比较。
In addition to the learned agents, we also report scores for a professional human games tester playing under controlled conditions and a policy that selects actions uniformly at random (Extended Data Table 2 and Fig. 3, denoted by 100% (human) and 0% (random) on y axis; see Methods).
除了学习代理,我们还报告了专业人类游戏测试人员在受控条件下的得分,以及随机均匀选择动作的策略 (扩展数据表 2 和 图 3,y 轴上表示 100% (人类) 和 0% (随机);见的方法)。
Our DQN method outperforms the best existing reinforcement learning methods on 43 of the games without incorporating any of the additional prior knowledge about Atari 2600 games used by other approaches (for example, refs 12, 15).
我们的 DQN 方法在 43 种游戏上的表现优于现有的最佳强化学习方法,而不包含其他方法所使用的关于 Atari 2600 游戏的任何额外先验知识(例如,参考文献 12,15)。
Furthermore, our DQN agent performed at a level that was comparable to that of a professional human games tester across the set of 49 games, achieving more than 75% of the human score on more than half of the games (29 games; see Fig. 3, Supplementary Discussion and Extended Data Table 2).
此外,我们的 DQN 代理在 49 款游戏中的表现水平与专业人类游戏测试人员相当,在超过一半的游戏( 29 款游戏;见图 3,补充讨论和扩展数据表 2)。
In additional simulations (see Supplementary Discussion and Extended Data Tables 3 and 4), we demonstrate the importance of the individual core components of the DQN agent—the replay memory, separate target Q-network and deep convolutional network architecture—by disabling them and demonstrating the detrimental effects on performance.
在其他模拟中( 参见补充讨论和扩展数据表 3 和 4 ),我们通过禁用 DQN 代理的各个核心组件(replay memory、单独的目标 Q-网络 和 深度卷积网络架构)并演示它们对性能的不良影响,证明了它们的重要性。

Figure 3 | Comparison of the DQN agent with the best reinforcement learning methods in the literature.
图 3 | DQN 代理 与文献中最佳强化学习方法的对比。
The performance of DQN is normalized with respect to a professional human games tester (that is, 100% level) and random play (that is, 0% level).
DQN 的性能是相对于专业人类游戏测试者(即 100% 水平)和随机游戏(即 0% 水平)进行标准化的。
Note that the normalized performance of DQN, expressed as a percentage, is calculated as: 100 × (DQN score - random play score)/(human score-random play score).
注意 DQN 的归一化性能以百分比表示,计算为:100 × ( DQN 得分 - 随机比赛得分) / (人类得分 - 随机比赛得分)。
It can be seen that DQN outperforms competing methods (also see Extended Data Table 2) in almost all the games, and performs at a level that is broadly comparable with or superior to a professional human games tester (that is, operationalized as a level of 75% or above) in the majority of games.
可以看出,DQN 在几乎所有游戏中都优于竞争对手的方法(参见扩展数据表 2),并且在大多数游戏中,DQN 的表现水平与专业的人类游戏测试人员相当或优于他们(即以 75% 或更高的水平运行)。
Audio output was disabled for both human players and agents.
人类玩家和代理的音频输出都被禁用。
Error bars indicate s.d. across the 30 evaluationd episodes, starting with different initial conditions.
误差条表示从不同初始条件开始的 30 个评估回合的 标准差。

Extended Data Table 2 Comparison of games scores obtained by DQN agents with methods from the literature1215 and a professionalhuman games tester
扩展数据表 2 DQN 代理 与 文献 1215 和 专业人类游戏测试人员的方法获得的游戏分数的比较
- Best Linear Learner is the best result obtained by a linear function approximator on different types of hand designed features.
最佳线性学习器 是通过 线性函数近似器 对不同类型的手工设计特征得到的最佳结果。
Contingency (SARSA) agent figures are the results obtained in ref. 15.
Contingency (SARSA) 代理 数字是参考文献 15 中获得的结果。
Note the figures in the last column indicate the performance of DQN relative to the human games tester, expressed as a percentage, that is, 100 x (DQN score-random play score)/(human score-random play score).
请注意,最后一列中的数字表明DQN相对于人类游戏测试人员的性能,以百分比表示,即 100 x (DQN 得分-随机游戏得分)/(人类得分-随机游戏得分)。

Extended Data Table 3 The effects of replay and separating the target Q-network
扩展数据表 3 回放和分离目标 Q 网络的影响
- DQN agents were trained for 10 million frames using standard hyperparameters for all possible combinations of turning replay on or off, using or not using a separate target Q-network, and three different learning rates.
DQN 代理使用标准超参数进行了 1000 万帧的训练,这些超参数用于所有可能的组合,包括 打开回放 或 关闭回放,使用或不使用单独的目标 Q - 网络,以及三种不同的学习率。
Each agent was evaluated every 250,000 training frames for 135,000 validation frames and the highest average episode score is reported.
在 135,000 个验证帧中,每 250,000 个训练帧对每个代理进行评估,并报告了最高的平均回合得分。
Note that these evaluation episodes were not truncated at 5 min leading to higher scores on Enduro than the ones reported in Extended Data Table 2.
请注意,这些评估回合没有被截断到 5 分钟,导致 Enduro 得分高于扩展数据表 2 中报告的得分。
Note also that the number of training frames was shorter (10 million frames) as compared to the main results presented in Extended Data Table 2 (50 million frames).
还要注意的是,与扩展数据表 2 中的主要结果(50 00 万帧)相比,训练帧的数量更短(10 00 万帧)。

Extended Data Table 4 Comparison of DQN performance with linear function approximator
扩展数据表 4 DQN 与线性函数近似器 性能比较
- The performance of the DQN agent is compared with the performance of a linear function approximator on the 5 validation games (that is, where a single linear layer was used instead of the convolutional network, in combination with replay and separate target network).
将 DQN 代理的性能与 线性函数近似器 在 5 个验证游戏(即使用单个线性层代替卷积网络,并结合 replay 和 分离目标网络) 上的性能进行比较。
Agents were trained for 10 million frames using standard hyperparameters, and three different learning rates.
使用标准超参数 和 三种不同的学习率 训练了 1000 万帧的 agent。
Each agent was evaluated every 250,000 training frames for 135,000 validation frames and the highest average episode score is reported.
在 135,000 个验证帧中,每 250,000 个训练帧对每个代理进行评估,并报告了最高的平均回合得分。
Note that these evaluation episodes were not truncated at 5 min leading to higher scores on Enduro than the ones reported in Extended Data Table 2.
值得注意的是,这些评估事件并没有在 5 分钟内被截断,从而导致 Enduro 得分高于扩展数据表 2 中报告的得分。
Note also that the number of training frames was shorter (10 million frames) as compared to the main results presented in Extended Data Table 2 (50 million frames).
还要注意的是,与扩展数据表 2 中的主要结果(5000 万帧)相比,训练帧的数量更短(1000 万帧)。
t-SNE 可视化 DQN 的表征
We next examined the representations learned by DQN that underpinned the successful performance of the agent in the context of the game Space Invaders (see Supplementary Video 1 for a demonstration of the performance of DQN), by using a technique developed for the visualization of high-dimensional data called t-SNE’25 (Fig. 4).
接下来,我们通过使用一种名为 `t-SNE’ 的高维数据可视化技术,研究了 DQN 学习到的表征,这些表征支撑了 agent 在游戏 Space Invaders 环境下的成功表现 (参见补充视频 1,以演示 DQN 的性能)。
As expected, the t-SNE algorithm tends to map the DQN representation of perceptually similar states to nearby points.
正如预期的那样,t-SNE 算法倾向于将感知相似状态的 DQN 表示 映射 到附近的点。
Interestingly, we also found instances in which the t-SNE algorithm generated similar embeddings for DQN representations of states that are close in terms of expected reward but perceptually dissimilar (Fig. 4, bottom right, top left and middle), consistent with the notion that the network is able to learn representations that support adaptive behaviour from high-dimensional sensory inputs.
有趣的是,我们还发现了 t-SNE 算法为状态的 DQN 表示生成类似 embeddings 的实例,这些状态在预期奖励方面接近,但在感知上不同(图 4,右下,左上和中间),这与网络能够从高维感官输入中 学习 支持自适应行为的表示 的意图一致。
Furthermore, we also show that the representations learned by DQN are able to generalize to data generated from policies other than its own—in simulations where we presented as input to the network game states experienced during human and agent play, recorded the representations of the last hidden layer, and visualized the embeddings generated by the t-SNE algorithm (Extended Data Fig. 1 and Supplementary Discussion).
此外,我们还表明,DQN 习得的表征能够推广到从策略生成的数据,而不是它自己的,在模拟中,我们将人类和 agent 在游戏过程中经历的网络游戏状态作为输入呈现,记录最后一个隐藏层的表征,并可视化 t-SNE 算法生成的嵌入embeddings (扩展数据图 1 和补充讨论)。
Extended Data Fig. 2 provides an additional illustration of how the representations learned by DQN allow it to accurately predict state and action values.
扩展数据图 2 提供了一个额外的说明,说明 DQN 习得的表示如何让它准确地预测状态和动作价值。


Figure 4 | Two-dimensional t-SNE embedding of the representations in the last hidden layer assigned by DQN to game states experienced while playing Space Invaders.
图 4 | DQN 为 Space Invaders 游戏状态分配的最后一层隐藏层表示的二维 t-SNE 嵌入。
The plot was generated by letting the DQN agent play for 2 h of real game time and running the t-SNE algorithm25 on the last hidden layer representations assigned by DQN to each experienced game state.
该图是通过让 DQN 代理玩 2 小时的真实游戏时间,并对 DQN 分配给每个体验游戏状态的最后一个隐藏层表示运行 t-SNE 算法 生成的。
The points are coloured according to the state values (V, maximum expected reward of a state) predicted by DQN for the corresponding game states (ranging from dark red (highest V) to dark blue (lowest V)).
根据 DQN 对相应游戏状态( 从深红色 (最高 V) 到深蓝色(最低 V )) 预测的状态价值(V,一种状态的最大奖励期望),这些点被着色。
The screenshots corresponding to a selected number of points are shown.
所选点数对应的屏幕截图显示。
The DQN agent predicts high state values for both full (top right screenshots) and nearly complete screens (bottom left screenshots) because it has learned that completing a screen leads to a new screen full of enemy ships.
DQN 代理 预测 完整屏幕(右上截图)和 接近完整屏幕(左下截图)的高状态值,因为它已习得完成一个屏幕会导致一个充满敌舰的新屏幕。
Partially completed screens (bottom screenshots) are assigned lower state values because less immediate reward is available.
部分完成的屏幕(底部截图)被分配较低的状态价值,因为即时奖励较少。
The screens shown on the bottom right and top left and middle are less perceptually similar than the other examples butd are still mapped to nearby representations and similar values because the orange bunkers do not carry great significance near the end of a level.
右下角、左上角 和 中间显示的屏幕在感知上的相似性不如其他例子,但仍然映射到附近的表示 和 相似的值,因为橙色掩体在关卡结束时没有太大意义。
With permission from Square Enix Limited.
It is worth noting that the games in which DQN excels are extremely varied in their nature, from side-scrolling shooters (River Raid) to boxing games (Boxing) and three-dimensional car-racing games (Enduro).
值得注意的是,DQN 擅长的游戏在性质上非常多样化,从横向卷轴射击游戏 ( River Raid ) 到拳击游戏 ( Boxing ) 和三维赛车游戏 ( Enduro )。
Indeed, in certain games DQN is able to discover a relatively long-term strategy (for example, Breakout: the agent learns the optimal strategy, which is to first dig a tunnel around the side of the wall allowing the ball to be sent around the back to destroy a large number of blocks; see Supplementary Video 2 for illustration of development of DQN’s performance over the course of training).
的确,在某些游戏中,DQN 能够发现一个相对长期的策略 (例如,Breakout; 代理学习最优策略,即首先在墙的一侧挖一个隧道,让球从后面被发送出去,摧毁大量的砖块;参见补充视频 2,说明 DQN 在训练过程中的性能发展)。
Nevertheless, games demanding more temporally extended planning strategies still constitute a major challenge for all existing agents including DQN (for example, Montezuma’s Revenge).
然而,对于包括 DQN 在内的所有现有代理 ( 如 Montezuma’s Revenge ) 来说,需要更多时序扩展规划策略的游戏仍然是一大挑战。
总结
In this work, we demonstrate that a single architecture can successfully learn control policies in a range of different environments with only very minimal prior knowledge, receiving only the pixels and the game score as inputs, and using the same algorithm, network architecture and hyperparameters on each game, privy only to the inputs a human player would have.
在这项工作中,我们证明了一个单一的架构可以在一系列不同的环境中成功地学习控制策略,只需要非常少的先验知识,只接收像素和游戏分数作为输入,并在每个游戏中使用相同的算法、网络架构和超参数,只知道人类玩家可能拥有的输入。
In contrast to previous work2426, our approach incorporates ‘end-to-end’ reinforcement learning that uses reward to continuously shape representations within the convolutional network towards salient features of the environment that facilitate value estimation.
与之前的工作 24,26 相比,我们的方法结合了 “端到端” 强化学习,它使用奖励来不断地在卷积网络中塑造表征 以获得 所处环境便于价值估计的显著特征。
This principle draws on neurobiological evidence that reward signals during perceptual learning may influence the characteristics of representations within primate visual cortex27,28.
这一原则借鉴了神经生物学证据,即知觉学习过程中的奖励信号可能会影响灵长类动物视觉皮层内表征的特型
Notably, the successful integration of reinforcement learning with deep network architectures was critically dependent on our incorporation of a replay algorithm21-23 involving the storage and representation of recently experienced transitions.
值得注意的是,强化学习与深度网络架构的成功整合在很大程度上取决于我们对回放算法的整合,该算法涉及最近经历的转换的存储和表示。
Convergent evidence suggests that the hippocampus may support the physical realization of such a process in the mammalian brain, with the time-compressed reactivation of recently experienced trajectories during offline periods21,22 (for example, waking rest) providing a putative mechanism by which value functions may be efficiently updated through interactions with the basal ganglia22.
越来越多的证据表明,海马可能支持哺乳动物大脑中这一过程的物理实现,在离线期间 (例如,醒着休息),时间压缩的 最近经历的轨迹的重新激活 提供了一种假定的机制,通过与基底神经节的相互作用,价值函数可能有效地更新。
In the future, it will be important to explore the potential use of biasing the content of experience replay towards salient events, a phenomenon that characterizes empirically observed hippocampal replay, and relates to the notion of ‘prioritized sweeping’30 in reinforcement learning.
在未来,探索将 经验回放的内容偏向突出事件的潜在用途将是很重要的,这是一种以经验观察海马回放为特征的现象,与强化学习中的“优先清扫”概念有关。
Taken together, our work illustrates the power of harnessing state-of-the-art machine learning techniques with biologically inspired mechanisms to create agents that are capable of learning to master a diverse array of challenging tasks.
总之,我们的工作说明了利用最先进的机器学习技术 和 生物学启发机制 来创建能够学习掌握各种具有挑战性任务的代理的力量。
Online Content Methods, along with any additional Extended Data display items and Source Data, are available in the online version of the paper; references unique to these sections appear only in the online paper.
在线内容:
方法,以及任何额外的扩展数据显示项目 和 源数据,都可以在论文的在线版本中获得;这些部分特有的参考文献只出现在在线论文中。
——————————————

参考文献
Supplementary Information is available in the online version of the paper.
Acknowledgements We thank G. Hinton, P. Dayan and M. Bowling for discussions,A. Cain and J. Keene for work on the visuals, K. Keller and P. Rogers for help with the visuals, G. Wayne for comments on an earlier version of the manuscript, and the rest of the DeepMind team for their support, ideas and encouragement.
致谢
我们感谢 G. Hinton, P. Dayan 和 M. Bowling 的讨论。
A. Cain 和 J. Keene 在视觉上的工作,K. Keller 和 P. Rogers 在视觉上的帮助,G. Wayne 对早期版本的手稿的评论,以及 DeepMind 团队的其他成员的支持,想法和鼓励。
Author Contributions V.M., K.K., D.S., J.V., M.G.B., M.R., A.G., D.W., S.L. and D.H. conceptualized the problem and the technical framework. V.M., K.K., A.A.R. and D.S. developed and tested the algorithms. J.V., S.P., C.B., A.A.R., M.G.B… I.A., A.K.F… G.O. and A.S.created the testing platform. K.K., H.K., S.L.and D.H.managed the project. K.K., D.K.,D.H., V.M., D.S., A.G., A.A.R, J.V. and M.G.B. wrote the paper.
作者贡献
V.M., K.K., D.S., J.V., M.G.B., M.R., A.G., D.W., S.L. 和 D.H. 对问题和技术框架进行了概念化。
V.M., K.K., A.A.R. 和D.S. 开发并测试了算法。
J.V., S.P., C.B., A.A.R., M.G.B… I.A., A.K.F… G.O. 和 A.S. 创建了这个测试平台。
K.K., H.K., S.L. 和 D.H. 负责这个项目。
K.K., D.K.,D.H.,V.M., D.S., A.G., A.A.R, J.V. 和 M.G.B. 写论文。
Author Information Reprints and permissions information is available at www.nature.com/reprints. The authors declare no competing financial interests. Readers are welcome to comment on the online version of the paper. Correspondence and requests for materials should be addressed to K.K. (korayk@google.com) or D.H. (demishassabis@google.com).
——————————————
METHODS 方法
预处理
Preprocessing.
Working directly with raw Atari 2600 frames, which are 210 × 160 pixel images with a 128-colour palette, can be demanding in terms of computation and memory requirements.
直接使用原始的 Atari 2600 帧,即 210 × 160 像素的图像和 128 色调色板,在计算和内存需求方面可能会要求很高。
We apply a basic preprocessing step aimed at reducing the input dimensionality and dealing with some artefacts of the Atari 2600 emulator.
我们应用了一个简单的预处理步骤,旨在降低输入维数并处理 Atari 2600 模拟器的一些伪影。
First, to encode a single frame we take the maximum value for each pixel colour value over the frame being encoded and the previous frame.
首先,为了编码单个帧,我们取正在编码的帧和前一帧的每个像素颜色值的最大值。 〔 消除闪烁 〕
This was necessary to remove flickering that is present in games where some objects appear only in even frames while other objects appear only in odd frames, an artefact caused by the limited number of sprites Atari 2600 can display at once.
这对于消除游戏中的闪烁是必要的,即某些对象只出现在偶数帧中,而其他对象只出现在奇数帧中,这是由 Atari 2600 能够同时显示的精灵数量有限所导致的。
Second, we then extract the Y channel, also known as luminance, from the RGB frame and rescale it to 84 × 84.
其次,我们从 RGB 帧中提取 Y 通道,也称为亮度,并将其重新缩放为 84 × 84。
The function ϕ \phi ϕ from algorithm 1 described below applies this preprocessing to the m m m most recent frames and stacks them to produce the input to the Q-function, in which m = 4 m = 4 m=4, although the algorithm is robust to different values of m m m (for example, 3 or 5).
下面描述的算法 1 中的函数 ϕ \phi ϕ 将此预处理应用于 m m m 个最近的帧,并将它们堆叠以生成 Q 函数的输入,其中 m = 4 m = 4 m=4,尽管该算法对不同的 m m m 值(例如,3 或 5)具有鲁棒性。
代码开源
Code availability. The source code can be accessed at https://sites.google.com/a/deepmind.com/dqn for non-commercial uses only.
模型架构
Model architecture.
There are several possible ways of parameterizing Q using a neural network.
使用神经网络参数化 Q 有几种可能的方法。
Because Q maps history-action pairs to scalar estimates of their Q-value, the history and the action have been used as inputs to the neural network by some previous approaches24.26.
由于 Q 将 历史-动作 对 映射到其 Q 值的标量估计,因此历史和动作已被一些先前的方法用作神经网络的输入。
The main drawback of this type of architecture is that a separate forward pass is required to compute the Q-value of each action, resulting in a cost that scales linearly with the number of actions.
这种类型架构的主要缺点是需要单独的前向传递来计算 每个动作的 Q 值,导致成本与动作数量呈线性增长。
We instead use an architecture in which there is a separate output unit for each possible action, and only the state representation is an input to the neural network.
相反,我们使用了一种架构,其中每个可能的动作都有一个单独的输出单元,只有状态表示是神经网络的输入。
The outputs correspond to the predicted Q-values of the individual actions for the input state.
输出对应于输入状态的单个动作的预测 Q 值。
The main advantage of this type of architecture is the ability to compute Q-values for all possible actions in a given state with only a single forward pass through the network.
这种类型的架构的主要优点是能够计算给定状态下所有可能的动作的 Q 值,而只需要在网络 正向传递 一次。
The exact architecture, shown schematically in Fig. 1, is as follows.
准确的架构示意图如图 1 所示。
The input to the neural network consists of an 84 × 84 × 4 image produced by the preprocessing map ϕ \phi ϕ .
神经网络的输入由预处理映射 ϕ \phi ϕ 产生的一张 84 × 84 × 4 的图像组成。
The first hidden layer convolves 32 filters of 8 × 8 with stride 4 with the input image and applies a rectifier nonlinearity31,32.
第一个隐藏层将 32 个 8 × 8、步长为 4 的滤波器与输入图像进行卷积,并应用整流非线性。〔 ReLU:可以有效缓解梯度消失问题,加速收敛过程 〕
The second hidden layer convolves 64 filters of 4×4 with stride 2, again followed by a rectifier nonlinearity.
第二层隐藏层对 64 个滤波器 4×4 进行卷积,步长为 2,之后是一个整流非线性。
This is followed by a third convolutional layer that convolves 64 filters of 3 × 3 with stride 1 followed by a rectifier.
接下来是第三个卷积层,它卷积 64 个 3 × 3 的滤波器,步幅为 1,然后是一个整流器。
The final hidden layer is fully-connected and consists of 512 rectifier units.
最后一个隐藏层是完全连接的,由 512 个整流器单元组成。
The output layer is a fully-connected linear layer with a single output for each valid action.
输出层是一个全连接的线性层,每个有效的动作都有一个输出。
The number of valid actions varied between 4 and 18 on the games we considered.
在我们所考虑的游戏中,有效动作的数量在 4 到 18 个之间。

Figure 1 ∣ | ∣ Schematic illustration of the convolutional neural network.
图 1 ∣ | ∣ 卷积神经网络示意图。
The details of the architecture are explained in the Methods.
架构的细节在方法中解释。
The input to the neural network consists of an 84 × 84 × 4 image produced by the preprocessing map ϕ \phi ϕ, followed by three convolutional layers (note: snaking blue line symbolizes sliding of each filter across input image) and two fully connected layers with a single output for each valid action.
神经网络的输入由预处理映射 ϕ \phi ϕ 生成的 84 × 84 × 4 图像组成,随后是三个卷积层 (注意:蛇形蓝线表示每个滤波器在输入图像上滑动) 和两个全连接层,每个有效动作有一个输出。
Each hidden layer is followed by a rectifier nonlinearity (that is, max ( 0 , x ) \max(0,x) max(0,x) ).
每个隐藏层后面都有一个整流器非线性(即 max ( 0 , x ) \max(0,x) max(0,x) )。〔 ReLU 〕
训练细节
Training details.
We performed experiments on 49 Atari 2600 games where results were available for all other comparable methods1215.
我们在 49 款 Atari 2600 游戏上进行了实验,结果适用于所有其他可比较的方法。
A different network was trained on each game: the same network architecture, learning algorithm and hyperparamleter settings (see Extended Data Table 1) were used across all games, showing that our approach is robust enough to work on a variety of games while incorporating only minimal prior knowledge (see below).
每个游戏都训练了不同的网络:所有游戏都使用了相同的网络架构、学习算法和超参数设置(参见扩展数据表 1),这表明我们的方法足够稳健,可以在只包含最小先验知识的情况下适用于各种游戏。
While we evaluated our agents on unmodified games, we made one change to the reward structure of the games during training only.
当我们在未修改的游戏中评估代理时,我们只在训练期间对游戏的奖励结构进行了一次更改。
As the scale of scores varies greatly from game to game, we clipped all positive rewards at 1 and all negative rewards at -1, leaving 0 rewards unchanged.
由于不同游戏的得分标准 差别很大,所以我们将所有正奖励裁剪为 1,将所有负奖励裁剪为 -1,保留 0 奖励不变。
Clipping the rewards in this manner limits the scale of the error derivatives and makes it easier to use the same learning rate across multiple games.
以这种方式裁剪奖励限制了误差导数的范围,并使其更容易在多个游戏中使用相同的学习率。
At the same time, it could affect the performance of our agent since it cannot differentiate between rewards of different magnitude.
同时,它可能会影响代理的表现,因为它无法区分不同大小的奖励。
For games where there is a life counter, the Atari 2600 emulator also sends the number of lives left in the game, which is then used to mark the end of an episode during training.
对于有生命计数器的游戏,Atari 2600 模拟器也会发送游戏中剩余的生命数,然后在训练期间用于标记一个回合的结束。
In these experiments, we used the RMSProp (see http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf) algorithm with minibatches of size 32.
在这些实验中,我们使用了RMSProp 算法,小批量大小为 32。
The behaviour policy during training was ε \varepsilon ε-greedy with e annealed linearly from 1.0 to 0.1 over the first million frames, and fixed at 0.1 thereafter.
训练期间的行为策略是 ε \varepsilon ε-greedy,在前一百万帧中, ε \varepsilon ε 从 1.0 线性退火到 0.1,之后固定为 0.1。
We trained for a total of 50 million frames (that is, around 38 days of game experience in total) and used a replay memory of 1 million most recent frames.
我们总共训练了 5000 万帧(也就是总共约 38 天的游戏经验),并使用了 100 万最近帧的经验回放。
Following previous approaches to playing Atari 2600 games, we also use a simple frame-skipping technique15.
More precisely, the agent sees and selects actions on every kth frame instead of every frame, and its last action is repeated on skipped frames.
更准确地说,代理在每 k 帧而不是每一帧看到并选择动作,它的最后一个动作在跳过的帧中重复。
Because running the emulator forward for one step requires much less computation than having the agent select an action, this technique allows the agent to play roughly k times more games without significantly increasing the runtime.
We use k =4 for all games.
因为向前运行模拟器一步所需的计算比让代理选择一个动作要少得多,所以这种技术允许代理在不显著增加运行时间的情况下玩大约 k 倍的游戏。
我们对所有游戏都使用 k = 4。
↑ 〔 跳帧周期 k = 4 〕
The values of all the hyperparameters and optimization parameters were selected by performing an informal search on the games Pong, Breakout, Seaquest, Space Invaders and Beam Rider.
所有超参数和优化参数的值都是通过对 Pong, Breakout, Seaquest, Space Invaders 和 Beam Rider 等游戏进行非正式搜索来选择的。
We did not perform a systematic grid search owing to the high computational cost.
由于计算成本高,我们没有进行系统的网格搜索。
These parameters were then held fixed across all other games.
这些参数在所有其他游戏中都是固定的。
The values and descriptions of all hyperparameters are provided in Extended Data Table 1.
所有超参数的值和描述见扩展数据表 1。
Our experimental setup amounts to using the following minimal prior know-ledge: that the input data consisted of visual images (motivating our use of a convolutional deep network), the game-specific score (with no modification), number of actions, although not their correspondences (for example, specification of the up ‘button’) and the life count.
我们的实验设置相当于使用以下最小的先验知识:输入数据包括视觉图像 (激励我们使用卷积深度网络),特定游戏分数 (未修改),动作数量,尽管不是它们的对应关系 (例如,向上“按钮”的规格) 和 生命计数。
评估程序
Evaluation procedure.
The trained agents were evaluated by playing each game 30 times for up to 5 min each time with different initial random conditions (‘noop’; see Extended Data Table 1) and an ε \varepsilon ε-greedy policy with ε \varepsilon ε = 0.05.
通过在不同的初始随机条件 (“noop”;参见扩展数据表 1) 和 ε \varepsilon ε = 0.05 的 ε \varepsilon ε-贪心策略下,每个游戏玩 30 次,每次最多 5 分钟,对训练好的 agent 进行评估。
This procedure is adopted to minimize the possibility of overfitting during evaluation.
采用此程序是为了尽量减少评估过程中过拟合的可能性。
The random agent served as a baseline comparison and chose a random action at 10 Hz which is every sixth frame, repeating its last action on intervening frames.
随机 agent 作为基线比较,每六帧选择一个 10 Hz 的随机动作,在中间帧重复它的最后一个动作。
10 Hz is about the fastest that a human player can select the ‘fire’ button, and setting the random agent to this frequency avoids spurious baseline scores in a handful of the games.
10 Hz 是人类玩家选择“开火”按钮的最快频率,将随机代理设置为这个频率可以避免在一些游戏中出现虚假的基线得分。
We did also assess the performance of a random agent that selected an action at 60 Hz (that is, every frame).
我们还评估了随机代理以 60 Hz(即每帧)的频率选择一个动作的性能。
This had a minimal effect: changing the normalized DQN performance by more than 5% in only six games (Boxing, Breakout, Crazy Climber, Demon Attack, Krull and Robotank), and in all these games DQN outperformed the expert human by a considerable margin.
这只产生了很小的影响:仅在 6 款游戏 (Boxing, Breakout, Crazy Climber, Demon Attack, Krull 和Robotank)中,DQN 的正常表现改变了 5% 以上,而且在所有这些游戏中, DQN 的表现都远远超过了人类专家。
The professional human tester used the same emulator engine as the agents, and played under controlled conditions.
专业的人类测试人员使用与代理相同的模拟器引擎,并在受控条件下进行测试。
The human tester was not allowed to pause, save or reload games.
测试人员不允许暂停、保存或重新加载游戏。
As in the original Atari 2600 environment, the emulator was run at 60 Hz and the audio output was disabled: as such, the sensory input was equated between human player and agents.
在最初的 Atari 2600 环境中,模拟器以 60 Hz 的频率运行,音频输出被禁用:因此,感觉输入在人类玩家和代理之间是相等的。
The human performance is the average reward achieved from around 20 episodes of each game lasting a maximum of 5 min each, following around 2 h of practice playing each game.
人类的表现是在每款游戏中大约 20 个回合的平均奖励,每个回合最多持续 5 分钟,每款游戏练习大约 2 小时。 〔 似乎是普通玩家的数据 〕
算法
Algorithm.
我们考虑 代理agent 在一系列的动作、观察和奖励中 与 环境交互的任务,在本例中是 Atari 模拟器。
在每个时间步,agent 从合法的游戏动作集合 A = { 1 , … , K } {\cal A}=\{1,…,K\} A={1,…,K} 中选择一个动作 a t a_t at。
动作被传递给模拟器并修改其内部状态和游戏分数。
一般来说,环境可能是随机的。
仿真器的内部状态不被代理观察到;相反,代理观察来自模拟器的图像 x t ∈ R d x_t\in {\mathbb R}^d xt∈Rd,它是表示当前屏幕的像素值向量。
此外,它还会获得奖励 r t r_t rt,代表游戏分数的变化。
请注意,一般来说,游戏得分可能取决于之前的整个行动和观察序列;
关于一个动作的反馈可能只有在经过数千个时间步之后才会收到。
由于 agent 只观察当前屏幕,任务是部分可观察的,许多模拟器状态被感知混淆(即仅从当前屏幕 x t x_t xt 不可能完全了解当前情况)。
因此,动作和观察序列 s t = x 1 , a 1 , x 2 , ⋯ , a t − 1 , x t s_t= \textcolor{blue}{x_1},a_1,x_2,\cdots,a_{t-1},\textcolor{blue}{x_t} st=x1,a1,x2,⋯,at−1,xt,是算法的输入,然后算法根据这些序列学习游戏策略。
模拟器中的所有序列都假定在有限数量的时间步下终止。
这种形式产生了一个大但有限的马尔可夫决策过程(Markov decision process, MDP),其中每个序列都是一个不同的状态。
因此,我们可以对 MDPs 应用标准的强化学习方法,只需使用完整序列 s t s_t st 作为时间 t t t 的状态表示。
代理的目标是通过选择能够最大化未来奖励的动作与模拟器进行交互。
我们做一个标准假设,即未来奖励在每个时间步上以 γ \gamma γ 作折扣( γ \gamma γ 自始至终被设定为 0.99),并定义在时间 t t t 的未来折扣回报 R t = ∑ t ′ = t T γ t ′ − t r t ′ R_t=\sum\limits_{t^\prime=t}^T\gamma^{t^\prime-t}r_{t^\prime} Rt=t′=t∑Tγt′−trt′,其中 T T T 是游戏结束的时间步长。
我们将 最优动作价值函数 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a) 定义为在看到某个序列 s s s 然后执行某个动作 a a a 后,通过遵循任何策略可获得的最大回报期望, Q ∗ ( s , a ) = max π E [ R t ∣ s t = s , a t = a , π ] Q^*(s,a) = \max\limits_\pi {\mathbb E}[R_t |s_t =s,a_t = a,π] Q∗(s,a)=πmaxE[Rt∣st=s,at=a,π],其中 π π π 是 映射 序列 到 动作 ( 或 动作分布 )的策略。
最优动作值函数 遵循一个重要的恒等式,即 Bellman 公式。
这是基于以下直觉:如果序列 s ′ s^\prime s′ 的下一个时间步的最优值 Q ∗ ( s ′ , a ′ ) Q^*(s^\prime,a^\prime) Q∗(s′,a′) 对于所有可能的动作 a ′ a^\prime a′ 都是已知的,那么最优策略就是选择 最大化 价值期望 r + γ Q ∗ ( s ′ , a ′ ) r+\gamma Q^*(s',a') r+γQ∗(s′,a′) 的 动作 a ′ a^\prime a′:
~
Q ∗ ( s ′ , a ′ ) = E s ′ [ r + γ max a ′ Q ∗ ( s ′ , a ′ ) ∣ s , a ] Q^*(s^\prime,a^\prime)={\mathbb E}_{s^\prime}\Big[r+\gamma \textcolor{blue}{\max\limits_{a^\prime}}Q^*(s',a')\Big|s,a\Big] Q∗(s′,a′)=Es′[r+γa′maxQ∗(s′,a′) s,a]
许多强化学习算法背后的基本思想是通过使用 Bellman 公式作为迭代更新来估计动作价值函数, Q i + 1 ( s , a ) = E s ′ [ r + γ max a ′ Q i ( s ′ , a ′ ) ∣ s , a ] Q_{i+1}(s,a) ={\mathbb E}_{s^\prime} [r+\gamma \max_{a^\prime} Q_i(s',a')|s,a] Qi+1(s,a)=Es′[r+γmaxa′Qi(s′,a′)∣s,a]。
这种值迭代算法收敛于最优动作价值函数, 当 i → ∞ i\to \infty i→∞ 时, Q → Q ∗ Q→Q^* Q→Q∗。
在实践中,这种基本方法是不切实际的,因为每个序列的动作价值函数是单独估计的,没有任何泛化。
相反,通常使用函数近似器来估计动作价值函数 Q ( s , a ; θ ) = Q ∗ ( s , a ) Q(s,a;θ)= Q^*(s,a) Q(s,a;θ)=Q∗(s,a)。
在强化学习中,这是一个典型的线性函数近似器,但是有时用非线性函数近似器代替,如神经网络。
我们把权重为 θ \theta θ 的神经网络函数近似器称为 Q 网络。
Q 网络可以通过在迭代 i i i 时调整参数 θ i \theta_i θi 来减小 Bellman 公式中的均方误差,其中最优目标值 r + γ max a ′ Q ∗ ( s ′ , a ′ ) r+\gamma \max_{a^\prime}Q^{\textcolor{blue}{*}}(s',a^\prime) r+γmaxa′Q∗(s′,a′) 被替换为近似目标值 y = r + γ max a ′ Q ( s ′ , a ′ ; θ i − ) y=r+\gamma \max_{a^\prime} Q(s',a^\prime\textcolor{blue}{;\theta_i^-}) y=r+γmaxa′Q(s′,a′;θi−),使用之前某个迭代的参数 θ i − \theta_i^- θi−。
这导致损失函数序列 L i ( θ i ) L_i(\theta_i) Li(θi) 在每次迭代 i i i 时发生变化,
~
L i ( θ i ) = E s , a , r [ ( E s ′ [ y ∣ s , a ] − Q ( s , a ; θ i ) ) 2 ] = E s , a , r , s ′ [ ( y − Q ( s , a ; θ i ) ) 2 ] + E s , a , r [ V s ′ [ y ] ] \begin{aligned}L_i(\theta_i)&={\mathbb E}_{s,a,r}\Big[\Big({\mathbb E}_{s^\prime}[y|s,a]-Q(s,a;\theta_i)\Big)^2\Big]\\ &={\mathbb E}_{s,a,r,\textcolor{blue}{s^\prime}}\Big[\Big(\textcolor{blue}{y}-Q(s,a;\theta_i)\Big)^2\Big]\textcolor{blue}{+{\mathbb E}_{s,a,r}\Big[{\mathbb V}_{s^\prime}[y]\Big]}\end{aligned}~~~~~ Li(θi)=Es,a,r[(Es′[y∣s,a]−Q(s,a;θi))2]=Es,a,r,s′[(y−Q(s,a;θi))2]+Es,a,r[Vs′[y]]
- 最后一项是 目标的方差。
注意,目标依赖于网络权重;这与用于监督学习的目标形成对比,后者在学习开始之前是固定的。
在每个优化阶段,我们在优化第 i i i 个损失函数 L i ( θ i ) L_i(\theta_i) Li(θi) 时,保持前一次迭代 θ i − \theta_i^- θi− 的参数不变,从而得到一系列定义良好的优化问题。
最后一项是目标的方差,它不依赖于我们当前正在优化的参数 θ i θ_i θi,因此可以忽略。
损失函数对权重微分,我们得到如下梯度:
~
∇ θ i L ( θ i ) = E s , a , r , s ′ [ ( r + γ max a ′ Q ( s ′ , a ′ ; θ i − ) − Q ( s , a ; θ i ) ) ∇ θ i Q ( s , a ; θ i ) ] \nabla_{\theta_i}L(\theta_i)={\mathbb E}_{s,a,r,s^\prime}\Big[\Big(r+\gamma\max\limits_{a^\prime}Q(s^\prime,a^\prime;\theta_i^-)-Q(s,a;\theta_i)\Big)\nabla_{\theta_i}Q(s,a;\theta_i)\Big] ∇θiL(θi)=Es,a,r,s′[(r+γa′maxQ(s′,a′;θi−)−Q(s,a;θi))∇θiQ(s,a;θi)]
与其计算上述梯度中的全部期望,不如通过随机梯度下降来优化损失函数。
在这个框架中,我们熟悉的 Q-learning 算法可以通过在每个时间步后更新权值,用单个样本替换期望,并设置 θ i − = θ i − 1 \theta_i^-=\theta_{i-1} θi−=θi−1 来恢复。
请注意,该算法是无模型的model-free:它直接使用来自模拟器的样本来解决强化学习任务,而无需显式估计奖励 和 转换动态 P ( r , s ′ ∣ s , a ) P(r,s'|s,a) P(r,s′∣s,a)。
它也是 off-policy异策略的:它学习贪心策略 a = arg max a ′ Q ( s , a ′ ; θ ) a = \arg\max_{a^\prime} Q(s,a';θ) a=argmaxa′Q(s,a′;θ),同时遵循 确保充分探索状态空间的 行为分布。
在实践中,行为分布通常由一个 ε \varepsilon ε-greedy 策略选择,该策略遵循贪心策略的概率为 1 − ε 1 - ε 1−ε ,并以概率 ε \varepsilon ε 随机选择动作。
DQN 的 训练算法
Training algorithm for deep Q-networks.
The full algorithm for training deep Q-networks is presented in Algorithm 1.
算法 1 给出了训练深度 Q 网络的完整算法。
The agent selects and executes actions according to an ε \varepsilon ε-greedy policy based on Q.
agent 根据基于 Q 的 ε \varepsilon ε-greedy 策略选择并执行动作。
Because using histories of arbitrary length as inputs to a neural network can be difficult, our Q-function instead works on a fixed length representation of histories produced by the function ϕ \phi ϕ described above.
因为使用任意长度的历史作为神经网络的输入是很困难的,所以我们的 Q 函数使用由上面描述的函数 ϕ \phi ϕ 产生的固定长度的历史表示。
The algorithm modifies standard online Q-learning in two ways to make it suitable for training large neural networks without diverging.
该算法从两个方面改进了标准的在线 Q-learning,使其适合于训练大型神经网络而不发散。
↓ 【 改进 1:经验回放experience replay 】
首先,我们使用一种称为经验回放experience replay 的技术,在这种技术中,我们将 agent 在每个时间步长的经验 e t = ( s t , a t , r t , s t + 1 ) e_t= (s_t, a_t,r_t,s_{t + 1}) et=(st,at,rt,st+1) 存储在数据集 D t = { e 1 , … , e t } D_t = \{e_1,…,e_t\} Dt={e1,…,et} 中,汇集了许多个回合(其中当遇到终止状态时,回合结束)到一个回放存储器。
在算法的内循环,我们对从存储样本池中随机抽取的经验样本 ( s , a , r , s ′ ) ∼ U ( D ) (s, a,r,s')\sim U(D) (s,a,r,s′)∼U(D) 应用 Q-learning 更新 或 小批量更新。
This approach has several advantages over standard online Q-learning.
与标准的在线 Q-learning 相比,这种方法有几个优点。
First, each step of experience is potentially used in many weight updates, which allows for greater data efficiency.
首先,经验的每一步都可能用于许多权重更新,这允许更高的数据效率。【 优点 1:更高的数据效率 】
Second, learning directly from consecutive samples is inefficient, owing to the strong correlations between the samples; randomizing the samples breaks these correlations and therefore reduces the variance of the updates.
其次,直接从连续样本中学习是低效的,因为样本之间有很强的相关性;随机化样本打破了这些相关性,因此减少了更新的方差。 【 优点 2:减少了更新的方差 】
Third, when learning on-policy the current parameters determine the next data sample that the parameters are trained on.
第三,当以同策略on-policy 的方式学习时,当前参数 确定参数被训练的下一个数据样本。
For example, if the maximizing action is to move left then the training samples will be dominated by samples from the left-hand side; if the maximizing action then switches to the right then the training distribution will also switch.
例如,如果最大化动作是向左移动,那么训练样本将由左侧的样本主导;如果最大化动作切换到右边,那么训练分布也会切换。
It is easy to see how unwanted feedback loops may arise and the parameters could get stuckin a poor local minimum, or even diverge catastrophically
很容易看到不必要的反馈循环是如何产生的,参数可能会陷入一个糟糕的局部最小值,甚至灾难性地发散。
By using experience replay the behaviour distribution is averaged over many of its previous states, smoothing out learning and avoiding oscillations or divergence in the parameters.
通过使用经验回放,行为分布在其先前的许多状态上平均,平滑学习并避免参数的振荡或发散。 【 优点 3:避免参数的振荡或发散 】
Note that when learning by experience replay, it is necessary to learn off-policy (because our current parameters are different to those used to generate the sample), which motivates the choice of Q-learning.
请注意,当通过经验回放学习时,有必要以异策略off-policy的方式学习(因为我们 当前的参数与用于生成样本的参数不同),这促使选择 Q-learning。
In practice, our algorithm only stores the last N experience tuples in the replay memory, and samples uniformly at random from D when performing updates.
在实践中,我们的算法只将最后的 N N N 个 experience 元组存储在 replay memory中,并在执行更新时从 D D D 随机采样。
This approach is in some respects limited because the memory buffer does not differentiate important transitions and always overwrites with recent transitions owing to the finite memory size N.
这种方法在某些方面是有局限性的,因为 内存缓冲区 不区分重要的转换,并且由于有限的内存大小 N N N,总是覆盖最近的转换。
Similarly, the uniform sampling gives equal importance to all transitions in the replay memory.
同样,均匀采样对 replay memory 中的所有转换一视同仁。
A more sophisticated sampling strategy might emphasize transitions from which we can learn the most, similar to prioritized sweeping30.
一个更复杂的采样策略可能会强调我们可以从中学到最多的转换,类似于优先清扫。
↓ 【 改进 2:用一个单独的网络 (即 目标网络 Q ^ \hat Q Q^) 来生成目标 y j y_j yj 】
为了进一步提高我们的神经网络方法的稳定性,对在线 Q-learning 的第二个修改是在 Q-learning 更新中使用一个单独的网络来生成目标 y j y_j yj。
更准确地说,每 C C C 次更新我们克隆网络 Q Q Q 得到一个目标网络 Q ^ \hat Q Q^,用 Q ^ \hat Q Q^ 生成 Q-learning 目标 y j y_j yj,用于对 Q Q Q 更新 C C C 次;与标准的在线 Q-learning 相比,这种修改使算法更加稳定,在标准的在线 Q-learning 中,增加 Q ( s t , a t ) Q(s_t,a_t) Q(st,at) 的更新通常也会增加所有 a a a 的 Q ( s t + 1 , a ) Q(s_{t + 1},a) Q(st+1,a),因此也会增加目标 y j y_j yj,可能导致策略的振荡或发散。
使用一组较旧的参数生成目标会 增加 更新 Q Q Q 的时间 和 更新影响目标 y j y_j yj 的时间 之间的延迟,从而使分散或振荡更不可能发生。
$\sf y$ y ~~~~~~~\sf y y
$\text{y}$ y ~~~\text{y} y
↓ 【 改进 3:裁剪误差项 】
我们还发现将来自更新 r + γ max a ′ Q ( s ′ , a ′ ; θ i − ) − Q ( s , a ; θ i ) r+\gamma \max_{a^\prime} Q(s ',a';\theta_i^-)-Q(s,a;θ_i) r+γmaxa′Q(s′,a′;θi−)−Q(s,a;θi) 的误差项裁剪到 -1 和 1 之间是有益的。
因为绝对值损失函数 ∣ x ∣ |x| ∣x∣ 对所有 x x x 的负值都有导数为 -1,对所有 x x x 的正值都有导数为 1,所以将平方误差裁剪为 -1 和 1 之间对应于对(-1,1)区间以外的误差使用绝对值损失函数。
这种形式的误差裁剪进一步提高了算法的稳定性。
DQN 伪代码
Algorithm 1: deep Q-learning with experience replay

算法: 带 经验回放 的 deep Q-learning
初始化容量为 N N N 的回放存储 D D D 〔 超参数 1:回放存储的 容量 N 〕
用随机权重 θ \theta θ 初始化 动作价值 函数 Q Q Q
用权重 θ − = θ \theta^-=\theta θ−=θ 初始化 目标动作价值函数 Q ^ \hat Q Q^
F o r \bf For For episode = 1,M d o ~\bf do do: 〔 超参数 2:回合数量 M 〕
~~~~~~ 初始化 序列 s 1 = { x 1 } s_1=\{x_1\} s1={x1},预处理序列 ϕ 1 = ϕ ( s 1 ) \phi_1=\phi(s_1)~~~~ ϕ1=ϕ(s1) 【预处理的目的:降低输入维数并处理 Atari 2600 模拟器的一些伪影。】
F o r ~~~~~~\bf For For t = 1 , T t=1, ~T t=1, T d o ~\bf do do: 〔 超参数 3:回合终止的时间步长 阈值 T 〕
~~~~~~~~~~~~ 以概率 ε \varepsilon ε 随机选择动作 a t a_t at
~~~~~~~~~~~~ 否则 a t = arg max a Q ( ϕ ( s t ) , a ; θ ) a_t=\arg\max\limits_aQ(\phi(s_t),a;\theta) at=argamaxQ(ϕ(st),a;θ)
~~~~~~~~~~~~ 在仿真器 执行动作 a t a_t at,观察 奖励 r t r_t rt 和 图像 x t + 1 x_{t+1} xt+1
~~~~~~~~~~~~ 令 s t + 1 = { s t , a t , x t + 1 } s_{t+1}=\{s_t,a_t,x_{t+1}\} st+1={st,at,xt+1},并预处理 ϕ t + 1 = ϕ ( s t + 1 ) \phi_{t+1}=\phi(s_{t+1}) ϕt+1=ϕ(st+1)
~~~~~~~~~~~~ 将 transition ( ϕ t , a t , r t , ϕ t + 1 ) (\phi_t,a_t,r_t,\phi_{t+1}) (ϕt,at,rt,ϕt+1) 存到 D D D
~~~~~~~~~~~~ 从 D D D 中随机抽样 小批次 transitions ( ϕ j , a j , r j , ϕ j + 1 ) (\phi_j,a_j,r_j,\phi_{j+1}) (ϕj,aj,rj,ϕj+1)
~~~~~~~~~~~~ 令 y j = { r j 在第 j + 1 步回合终止 r j + γ max a ′ Q ^ ( ϕ j + 1 , a ′ ; θ − ) 其它 ~~y_j=\begin{cases}r_j &在 第 ~j+1~步回合终止\\ r_j+\gamma\max\limits_{a^\prime}\hat Q(\phi_{j+1}, a^\prime;\theta^-)&其它\end{cases} yj={rjrj+γa′maxQ^(ϕj+1,a′;θ−)在第 j+1 步回合终止其它
~~~~~~~~~~~~ 梯度下降 ( y j − Q ( ϕ j , a j ; θ ) ) 2 \Big(y_j-Q(\phi_j,a_j;\theta)\Big)^2 (yj−Q(ϕj,aj;θ))2,针对网络参数 θ \theta θ
~~~~~~~~~~~~ 每 C C C 步 重置 Q ^ = Q \hat Q=Q Q^=Q 〔 超参数 4:目标网络 的 更新周期 C 〕
E n d F o r ~~~~~~{\bf End ~For} End For
E n d F o r {\bf End ~For} End For
D D D 中数据超过 N N N 后怎么腾位置?删掉 最旧的数据?
——> 文中说了只存储最后 N N N 个数据在 replay memory 中。